
几周前,我们发布了 jina-embeddings-v4 模型的 GGUF 版本,大幅降低了显存占用,提升了运行效率。不过,受限于 llama.cpp 上游版本的运行时,当时的 GGUF 模型只能当作文本向量模型使用而无法支持多模态向量的输出。
为此,我们深入 llama.cpp 与 GGUF 的技术腹地,最终成功打通了整条链路,让在 GGUF 格式里生成多模态向量成为可能。完整的操作指南已在我们的 README 里开源:https://github.com/jina-ai/llama.cpp/tree/master/jina_embeddings
熟悉的朋友可能立刻就要问,llama.cpp 不是本身就支持多模态输入吗?
是的,但关键在于支持的方向。llama.cpp 的研发重心长期围绕大语言模型与文本生成,在多模态向量上完全是空白。
本文将详细解读我们是如何一步步为 llama.cpp 中补全这一能力,同时,我们也会将其性能(包括两个量化版本)与 PyTorch 版的 jina-embeddings-v4,也就是我们后文将反复提及的参考模型,进行全面的性能对比。
理解 Llama.cpp 中的图像输入机制
要理解我们的工作,首先需要了解多模态向量是如何工作的。以 Pytorch 的参考版本为例,模型先让每个图像输入与一个特殊的提示词 (prompt) 配对,比如下面这样:
go
<|im_start|>user\n<|vision_start|><|image_pad|><|vision_end|>Describe the image.<|im_end|>\n随后,模型会像处理流水线一样,一口气地完成三项任务:预处理图像、调用 ViT 组件编码图像信息、最后在一次完整的前向传播中,同步理解整个图文交错的序列。这就有点像我们人眼,从头到尾扫过去,文字和图片就都理解了。
但是 llama.cpp 在处理向量任务时,面临一个核心限制:它的内部管线是分离的,文本和图像必须分头处理,无法在一次运算中同时消化。
为此,我们专门 fork 了 llama.cpp,改造了它的向量处理器,设计了一套分阶段的处理流程,让它能够直接接收 Base64 编码的图像。这一改动,为我们后续实现分步处理多模态内容铺平了道路。
现在,在我们改造后的 llama.cpp 中,我们依然从一个相似的提示词开始,但流程变得更加精巧:
go
<|im_start|>user\n<__image__>Describe the image.<|im_end|>\n整个处理流程被分解为以下五个步骤:
1. 添加视觉边界
首先,llama.cpp 捕捉到 <__image__> 词元,并自动用视觉指令 <|vision_start|> 和 <|vision_end|> 将其包裹起来,形成一个完整的处理单元。组合成类似这样的结构:<|im_start|>user\n<|vision_start|><__image__><|vision_end|>Describe the image.<|im_end|>\n,清晰地界定了图像信息的处理范围。
2. 转换内部信号
紧接着,当分词器处理这段加好词元的提示词时,会将 <__image__> 这个特殊词元转换为内部信号 -1,用以告知模型:序列中包含一张图像,需要调用视觉模块(ViT)进行预编码。
3. 处理前置文本
现在,LLM 先处理 <__image__> 之前的所有文本词元(即 <|im_start|>user\n<|vision_start|>),LLM 将对这部分文本的理解,以计算状态的形式注入 KVCache。
4. 编码图像并关联上下文
随后 ViT 负责将原始图像编码成一系列 LLM 能够理解的图像词元。随后,LLM 立即对这些新生成的图像词元进行解码。在解码过程中,注意力机制借助 KVCache,把图像信息与前文语境关联起来。但请注意,此时 LLM 的视野是受限的,它只能看到过去(前文),无法预知未来(即 <|vision_end|> 之后的文本)。
5. 处理后置文本并融会贯通
最后,LLM 解码剩余的文本词元(即 <|end_vision|>Describe the image.<|im_end|>\n)。至此,借助 KVCache,注意力层终于可以贯通全局,同时关注到序列中所有的文本和图像信息,形成对整个图文序列的最终理解。
下图直观地展示了这一系列环环相扣的向量推理过程,包括图像编码和图文词元的解码步骤:
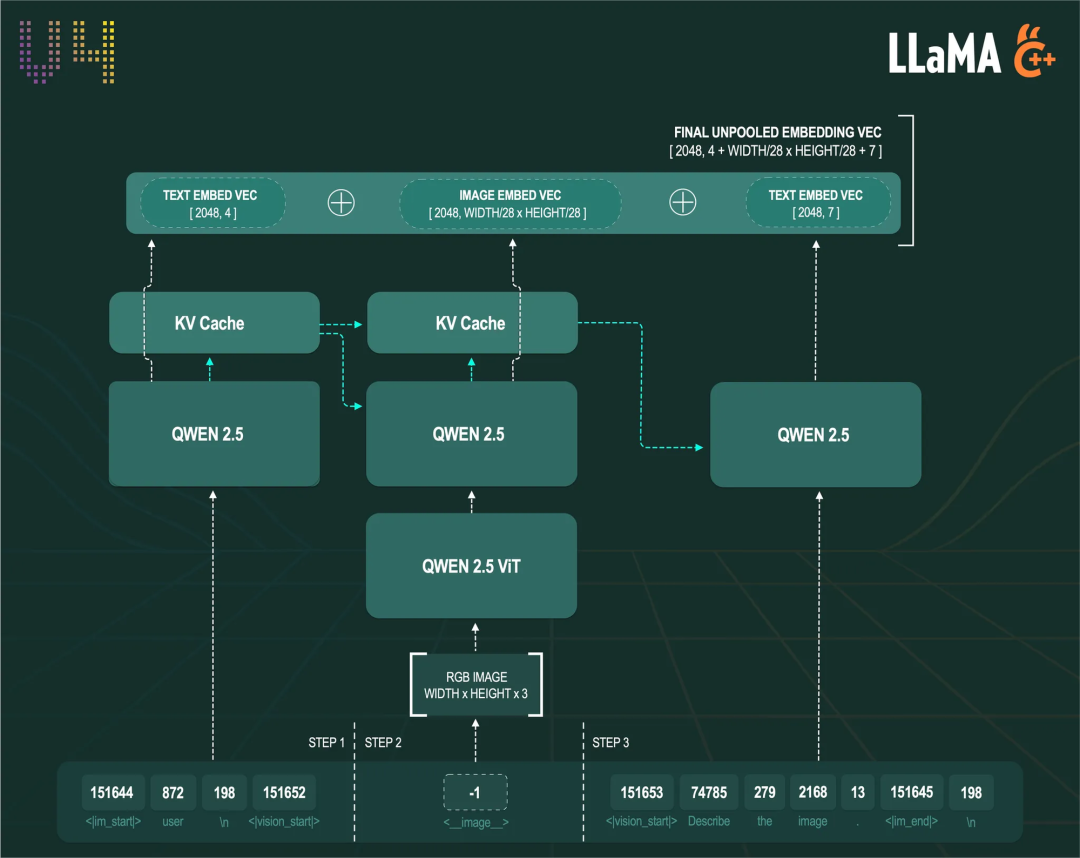
jina-embeddings-v4 llama.cpp 版本的向量推理流程
对图像词元的注意力机制
由于注意力机制的工作方式,上述的多步处理流程可能会给某些模型带来问题。我们先简单回顾一下模型中常见的几种注意力类型:
-
因果注意力 (Causal attention):这种机制严格遵守时间顺序,它天生就是向后看的。在处理位置
k的词元时,注意力机制只关注之前位置[0:k-1]的词元。像是读一本书,读到第 k 页时,只能回顾前面 0 到 k-1 页的内容。 -
非因果注意力 (Non-causal attention) 这种机制则拥有全局视野,在处理位置
k的词元时,注意力机制会关注序列中所有位置[0:n]的词元。好比看一幅画,在观察任意一个细节时,都能同时看到整幅画的全貌。
下图清晰地展示了在处理第二个步骤中的img_tok_n时,两种注意力机制分别会关注哪些词元:
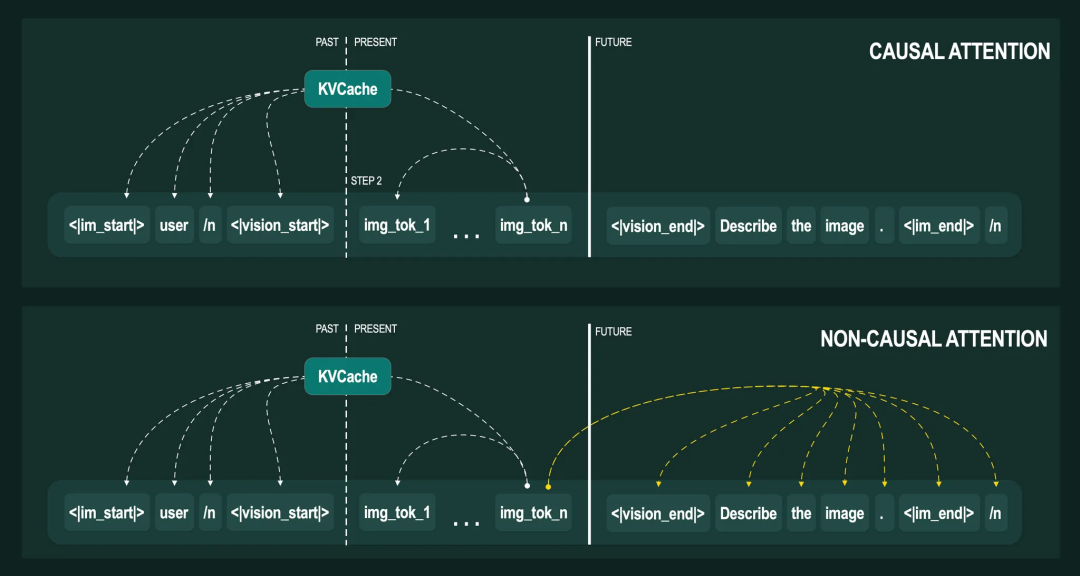 因果注意力与非因果注意力的对比
因果注意力与非因果注意力的对比
现在,让我们在模型处理图像的瞬间按下暂停键,看看当它处理到第 n 个图像词元(img_tok_n)时,内部是什么状态:
-
历史信息:所有先前的文本词元(
<|im_start|>、user、\n、<|vision_start|>)均已处理完毕,并存入了KVCache。 -
当前任务:所有图像词元(从
img_tok_1到img_tok_n),正在作为当前序列被逐一处理。 -
未来信息:所有后续的文本词元(
<|vision_end|>、Describe等)还静静地躺在队列中,等待处理。
在这里,两种注意力机制的根本矛盾就出现了:
对于因果注意力而言,一切都顺理成章。在处理img_tok_n 时,模型只考虑之前的词元,而这些词元的状态都已完备地保存在 KVCache 中,模型可以直接调用。因此,我们的分步处理流程对它来说畅通无阻。
但对于非因果注意力,它的设计原则要求它必须能同时看到序列里过去、现在和未来的所有词元。但在我们的流程中,未来的文本词元(<|vision_end|>、Describe 等)此刻尚未被处理,模型无法获取这些信息。这等于直接破坏了它的工作前提,导致整个流程必然会因信息不完整而中断。
幸运的是,我们的 jina-embeddings-v4 模型,其内部恰好采用的是因果注意力机制。这使得我们的多步处理方案得以完美兼容,顺利运行。但对于其他采用不同注意力机制的模型,此方案则可能不适用。
至于最终的向量生成,模型会输出序列中每一个输入词元所对应的最终隐藏状态 (final hidden state)。当前,像池化 (Pooling) 和归一化 (Normalization) 这类用于生成最终句向量的收尾工作,我们暂时放在 Python 端执行,但未来稍加开发,便可将它们也整合到 llama.cpp 内部。
我们进行的修复工作
当我们在 llama.cpp 服务器上为 Embeddings Endpoint 打通了图像输入功能后,我们满怀期待地启动了基准测试。然而,测试结果却给了我们当头一棒:它与参考模型的输出存在着巨大差异。
我们立刻怀疑问题出在 llama.cpp 对 ViT 的实现上。ViT 是 Qwen2.5-VL 模型中的视觉核心,它负责将图像编码成图像块向量(一种大语言模型能够理解的密集向量表示),以便后续的 Qwen2.5 LLM 进行处理。如果这个编码过程出了岔子,那么后续的一切就会谬以千里。
下面的数据直观地展示了两者输出的 ViT 结果有多么不同:
go
=== vit_out reference === Shape: [1008, 1280]
Logging patch 0, dimensions 0-9
Patch 0: -0.375000 -0.250000 -4.281250 -5.968750 2.953125 -8.125000 8.625000 -9.250000 8.937500 -0.332031 ... (dims 10-1279)
... (patches 1-1007 not shown)
go
=== vit_out llama.cpp === Shape: [1280, 1008, 1, 1]
Logging patch 0, dimensions 0-9
Patch 0: -2.998136 -2.226554 0.233671 -7.486460 0.596918 -12.889042 8.904849 -8.6
... (patches 1-1007 not shown)可以看出,两者的数值差异巨大,甚至连数据结构(Shape)都完全不同,这印证了我们的初步猜想。但严谨的工程需要刨根问底:问题仅仅出在 ViT 身上吗?
为了精准定位问题,我们设计了一个隔离实验:我们尝试在 Python 环境中预先计算出图像词元,拿着这份由参考模型生成的标准答案,直接喂给 llama.cpp 的 Qwen2.5 大语言模型部分去解码。
我们原本预期,绕过了 llama.cpp 的 ViT 之后,最终的向量会与参考模型高度吻合。然而,结果再次出乎我们的意料,差异依然存在。这说明,问题比我们想象得更深,除了 ViT,LLM 的处理环节中也有问题。
修复 1:修正因果注意力掩码
既然 LLM 的处理环节也存在问题,我们继续深挖,将目光锁定在最有可能导致数据差异的注意力层。经过细致排查,我们终于揪出了问题的根源:在处理图像词元时,注意力层所使用的因果注意力掩码计算有误。
让我们回到之前的示例序列里,看看错误是如何发生的。当模型处理图像词元时,内部的序列会展开成这个样子:
go
<|im_start|>user\n<|vision_start|> img_tok_1 img_tok_2 ... img_tok_last <|vision_end|>Describe the image.<|im_end|>\n⚠️ 说明:在当前的处理流程里,无论是文本 <|im_start|>、user 还是图像词元 img_tok_1、img_tok_2,它们都已是向量化的密集表示,不是原始的文本字符。为了让解释更简单,我们才沿用了这种序列的写法。
因果注意力的核心原则是"严格遵守时间顺序"。因此,按照设计,当模型解码第二个图像词元 img_tok_2 时,它的注意力只应该关注到所有在此之前出现过的词元,即:
go
<|im_start|>user\n<|vision_start|> img_tok_1然而,注意力掩码中的一个错误,却导致机制关注了整个图像序列,它的视野变成了这样:
go
<|im_start|>user\n<|vision_start|> img_tok_1 img_tok_2 ... img_tok_last这样就彻底破坏了因果依赖关系,导致计算结果出现严重偏差。
我们修复了这个掩码错误,强制注意力机制回归到严格的因果顺序上。修复之后,我们再次进行了那个隔离实验,将参考模型 ViT 输出的"标准答案"喂给 llama.cpp 的 LLM 部分。
这一次,结果终于与我们的预期一致:llama.cpp 生成的向量与参考模型的向量高度匹配,误差被控制在了极小的范围内。至此,我们确认已成功修复了 LLM 处理环节的漏洞。
修复 2:优化图像处理与图像块向量
攻克了 LLM 的难题后,我们回过头来,全力解决 ViT 编码器的差异问题。我们追溯了问题的源头,发现数值从预处理阶段一开始就出现了偏差。并且在初始的图像分块 (patch-creation) 步骤中表现得尤为突出。在这个步骤中,参考模型和 llama.cpp 都会把原始的图像分割成多个图像块(patches),再通过卷积层进行编码。
下面的数据对比说明了,在 ViT 进行处理之前,两者生成的原始图像块就已大相径庭:
go
=== raw_patches reference === Shape: [1008, 1176]
Logging patches 0-4, dimensions 0-9
Patch 0: 0.484375 0.484375 0.500000 0.500000 0.470703 0.470703 0.470703 0.484375 0.470703 0.484375 ... (dims 10-1175)
... (patches 1-1007 not shown)
go
=== raw_patches llama.cpp === Shape: [1176, 1008, 1, 1]
Logging patches 0-4, dimensions 0-9
Patch 0: 0.455895 0.455895 0.455895 0.455895 0.455895 0.455895 0.470494 0.470494 0.470494 0.470494 ... (dims 10-1175)
... (patches 1-1007 not shown)深入探究后我们发现,两种实现走了完全不同的技术路线:
-
参考模型:运用一系列重塑(reshape)操作对像素进行分组,然后调用单个 conv3d (三维卷积) 层来统一编码。
-
llama.cpp 模型:通过两个 conv2d (二维卷积) 层的堆叠来创建和编码图像块。
与其深入调试 llama.cpp 复杂的双层 conv2d 实现,我们选择了一条更直接的路径:精确复刻参考模型的操作,从根源上统一两者行为。
然而,复刻也没那么顺利。我们很快遇到了第一个障碍:参考模型生成像素块时,需要进行复杂的 reshape 和 transpose (转置)操作,这要求张量支持高达 9 个维度。而 llama.cpp 的底层张量库 ggml 无法支持这个操作。
为了绕开这个限制,我们设计了一个巧妙的变通方案:将图像分块这一步剥离出来,用一个独立的 Python 服务来完成,然后通过 HTTP 将预处理好的图像块发送给 llama.cpp 服务器。
但第二个障碍又接踵而至:ggml 同样不支持 conv3d 层。通过分析参考模型中 conv3d 层的配置,我们发现了一个关键突破口:
go
kernel_size = [
2, # temporal_patch_size,
14, # patch_size
14# patch_size
]
proj = nn.Conv3d(
3, # in_channels
1152, # embed_dim,
kernel_size=kernel_size,
stride=kernel_size,
bias=False
)可以看到,stride (步长)和 kernel_size(卷积核大小)是相同的,这就意味着,我们可以直接将 conv3d 层的输入和权重都展平,然后执行一个简单的矩阵乘法操作来替代它。
为了实现这一步,我们兵分两路:
1. 改造模型转换脚本
先是修改了 llama.cpp 中的模型转换脚本 (convert_hf_to_gguf.py),让它在导出模型时,额外生成一份展平后的 conv3d 权重,专为矩阵乘法准备。
go
if 'patch_embed.proj.weight' in name:
c1, c2, kt, kh, kw = data_torch.shape
# 注意:脚本的这部分也会导出该层的其他版本
# 此处仅展示相关部分
# 用于矩阵乘法的扁平化权重:行主序 [输出维度, 输入维度*kT*kH*kW] = [向量维度, 1176]
W_flat = data_torch.contiguous().view(c1, -1)
outputs.append(("v.patch_embd.weight_flat", W_flat))2. 修改 llama.cpp 计算图
接着,我们修改了 llama.cpp 中构建 Qwen2.5-VL ViT 计算图的核心代码,增加了一个条件分支:如果输入的是我们预处理好的图像块,就绕开原有的 conv2d 路径,转而执行我们准备好的矩阵乘法操作。
go
ggml_tensor * build_inp_raw_precomputed() {
ggml_tensor * inp_raw = ggml_new_tensor_2d(
ctx0,
GGML_TYPE_F32,
img.p_dim,
img.npx * img.npy
);
ggml_set_name(inp_raw, "inp_raw");
ggml_set_input(inp_raw);
return inp_raw;
}
ggml_cgraph * build_qwen2vl() {
// 注意:此处仅展示我们为使用预先排列好的图像词块而添加的代码
constbool uses_precomputed_image = img.is_precomputed;
ggml_tensor * inp = nullptr;
if (uses_precomputed_image) {
ggml_tensor * inp_raw = build_inp_raw_precomputed();
cb(inp_raw, "inp_raw", -1);
inp = ggml_mul_mat(ctx0, model.patch_embeddings_flat, inp_raw);
} else {
// 常规的 2x conv2d 路径
}
// 其余代码
}经过这一系列改造,我们终于扫清了所有障碍。最终,图像向量与参考模型的误差成功控制在了 2% 以内,这在下一节的评估数据中得到了充分验证。
性能评估
完成上述修改后,我们使用 MTEB 基准测试在 ViDoRe 任务上,对我们修复后的 llama.cpp 模型,和参考模型进行了评估。为了考察其在资源受限环境下的表现,我们还引入了两个不同级别的量化版本一同参评。相关的复现脚本与说明,均已在我们的 llama.cpp 分支中开源。
🔗:https://github.com/jina-ai/llama.cpp/tree/master/jina_embeddings
| 任务 | 参考模型 | llama.cpp (F16) | llama.cpp (Q4_K_M) | llama.cpp (IQ4_XS) |
|---|---|---|---|---|
| VidoreArxivQARetrieval | 83.55 | 85.00 | 84.38 | 84.34 |
| VidoreDocVQARetrieval | 50.53 | 52.02 | 51.93 | 51.57 |
| VidoreInfoVQARetrieval | 87.77 | 87.31 | 87.61 | 87.28 |
| VidoreShiftProjectRetrieval | 84.07 | 82.25 | 82.56 | 81.73 |
| VidoreSyntheticDocQAAIRetrieval | 97.52 | 96.71 | 97.28 | 97.15 |
| VidoreSyntheticDocQAEnergyRetrieval | 91.22 | 90.34 | 90.47 | 90.30 |
| VidoreSyntheticDocQAGovernmentReportsRetrieval | 91.61 | 93.84 | 93.47 | 94.47 |
| VidoreSyntheticDocQAHealthcareIndustryRetrieval | 95.42 | 96.08 | 95.67 | 96.05 |
| VidoreTabfquadRetrieval | 94.52 | 94.94 | 94.83 | 94.72 |
| VidoreTatdqaRetrieval | 65.52 | 64.85 | 64.63 | 64.76 |
| 平均分 | 84.17 | 84.33 | 84.28 | 84.23 |
从上表的结果可以看出,从平均分来看,llama.cpp 的各个版本,包括经过大幅压缩的量化模型,都与参考模型旗鼓相当,性能几乎没有折损。这有力地证明了我们的修复工作取得了成功。
为了进一步深挖两者之间可能存在的细微差异,我们还选取了来自不同领域、不同分辨率的图像,将两者输出的图像块向量(在池化与归一化之前)进行逐一对比,并将其间的余弦距离绘制成了热力图。
图中,颜色越红的区域,就代表两者在该图像块上的认知差异越大。

jina-embeddings-v4 技术报告页面,左:372×526 分辨率,右:2481×3508 分辨率  Jina AI 网站截图,左:594×428 分辨率,右:1982×1428 分辨率
Jina AI 网站截图,左:594×428 分辨率,右:1982×1428 分辨率  东京涩谷夜景,左:383×255 分辨率,右:5472×3649 分辨率
东京涩谷夜景,左:383×255 分辨率,右:5472×3649 分辨率
我们希望通过这种可视化的方式,揪出任何潜在的、系统性的算法缺陷,但热力图上并没有出现指向任何特定模式的异常。
我们唯一观察到的趋势是,随着图像分辨率的提升,存在微小差异的图像块数量会相应增多。
我们推断,不是 Qwen2.5-VL(jina-embeddings-v4 的骨干模型)的实现本身存在问题,很可能只是因为后端实现的细微不同,例如底层计算库、硬件加速或浮点运算精度上的差异。
尽管 llama.cpp 模型生成的向量与参考模型存在极其微小的差异,但基准测试的结果也证明了,这些差异在实际应用中几乎不影响最终的性能表现。
综上,我们成功地使 llama.cpp 模型在性能上和参考模型高度对齐,同时证明了向量层面的微小差异在下游任务中可以忽略不计。
待解决的问题
虽然我们取得了显著进展,但在 llama.cpp 中实现多模态向量还有很多值得做的,我们规划了几个关键的后续改进方向:
-
端到端量化:将视觉编码器纳入量化范畴 :目前,我们的
llama.cpp仅支持对大语言模型进行量化。为了实现更好的扩展性,下一步的关键就是将量化技术同样应用于视觉编码器,实现端到端的低资源部署。 -
将视觉编码器分离为独立服务:视觉编码器的工作模式(采用非因果注意力)决定了它必须在一次前向传播中处理完单张图像,无法利用连续批处理,限制了吞吐量。我们计划将其解耦为一个独立的微服务。这样一来,就可以将来自不同源的多张图像批量组合在一起,通过动态批处理一次前向传播完成所有编码。这虽然会增加显存需求,但能大幅提升图像编码的整体吞吐量。更重要的是,架构解耦将允许视觉和语言模块根据负载独立扩展,为生产环境部署提供了极大的灵活性。
-
支持多向量输出 :本文中,我们只处理了单向量输出。但为了充分发挥
jina-embeddings-v4的能力,我们还希望启用多向量输出,模型将能捕捉更丰富的语义层次,从而在处理复杂视觉任务时,实现准确性的显著提升。而且这些向量只需在基础模型之上增加一个线性层即可生成,因此实现起来相对容易。
结论
本次工作中,我们成功地在 llama.cpp 中集成了高性能的多模态向量功能,其表现在一系列基准测试中,已能与 PyTorch 参考模型并驾齐驱。
我们通过精准定位并修复注意力掩码与图像分块处理中的核心缺陷,从根本上消除了主要的性能偏差。实验证明,即便是经过大幅压缩的量化版本,也能在消耗更少资源的同时,维持高度可比的准确率。对于在高分辨率图像上残留的微小数值差异,我们将其归因于后端实现的细微不同,而非核心算法问题。
展望未来,通过将量化技术延伸至视觉编码器、以独立服务实现批处理,并支持多向量输出,我们将能进一步提升 llama.cpp 在多模态任务上的效率与精度。这些改进环环相扣,将共同推动该方案变得更具扩展性,更好地服务于真实世界的复杂应用场景。
