原文链接:https://arxiv.org/pdf/2502.05370v1
在混合专家(MoE)架构中,初始阶段涉及输入样本通过GateNet进行多分类的鉴别过程,目的是确定最适合处理输入的专家模型。这个步骤被称为"experts selection",也是整个MoE模型的核心理念,学术界通常将其描述为稀疏性激活。随后,被选中(激活)的专家模型负责处理输入样本,进而生成最终的预测结果。
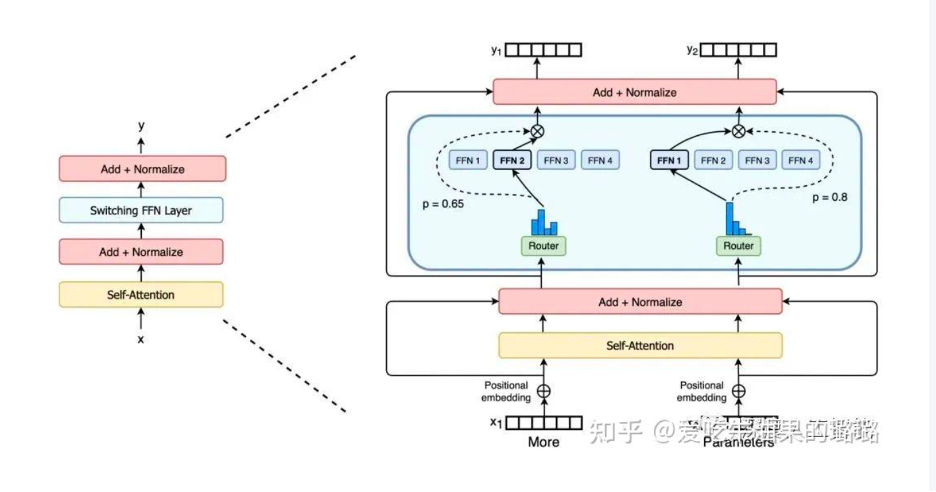
所以MOE有高效性的特点:由于只有少数专家模型被激活,大部分模型处于未激活状态,混合专家模型具有很高的稀疏性。这种稀疏性带来了计算效率的提升,因为只有特定的专家模型对当前输入进行处理,减少了计算的开销。
但是MOE也同样有问题:那些不参与推理的模型仍然在GPU中待命,这样就导致GPU的memory不堪重负。所以就提出了experts offload。
由于是MOE所以一些模型其实是不激活的,那么,就可以把这些模型offload到CPU上,这样就是可以节约GPU的储存和带宽。这个就叫做experts offload.
但是现有的很多experts offload方法都没有很好的提升模型时延,或者仍然有大量内存占用的问题。主要原因是他们做的不够细,模型没有很好的被分门别类,导致真正需要使用的expert被错误的放到了CPU上,在使用expert的时候需要重新加载的时间。
粗颗粒度的offloading solution是基于request level的,这样的话就是由多个iteration组成的。而细颗粒度则是iteration level的。但是实验表明,粗颗粒度的expert heatmap被激活的更加均匀(熵更大)而且随着iteration的增加,expert被激活的就是更加均匀。
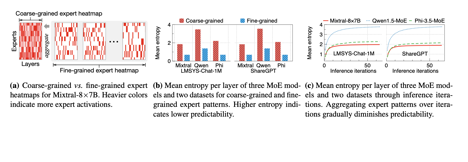
fMoE提出了expert-map,记录iteration级别输入的内容以及调取模型的情况,然后根据这张expert-map来决定experts offload。
fMoE的整体架构:
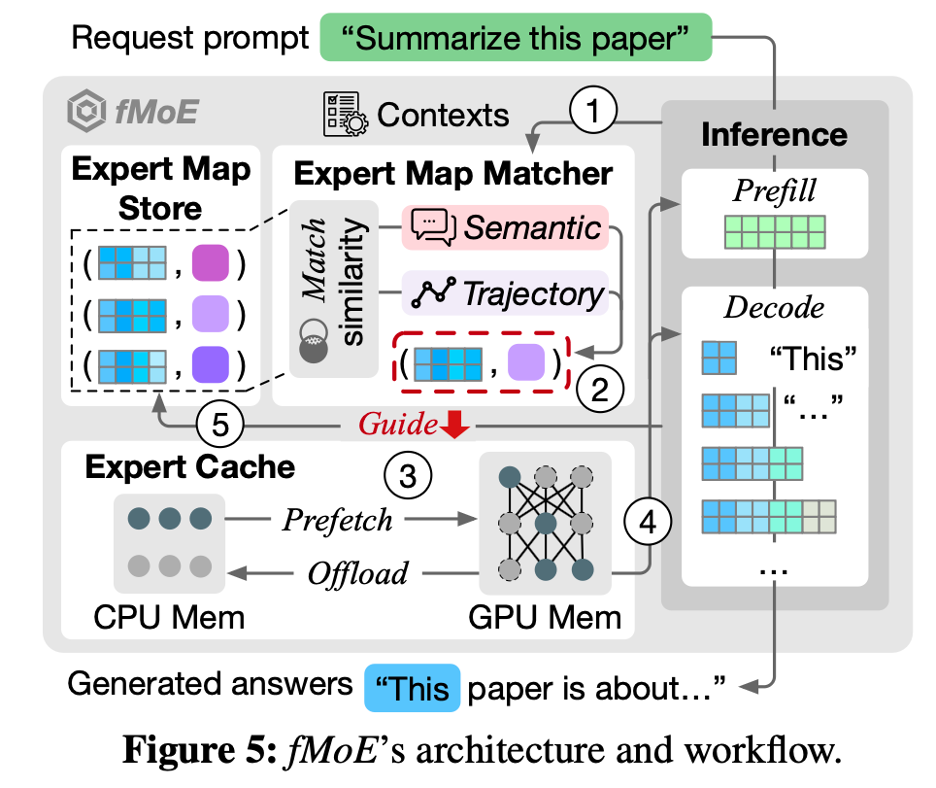
问题
- 这个fMoE是在训练阶段用呢,还是推理阶段用呢?
推理阶段用,因为模型不能有变化 - Expert map macher 和expert cache怎么保证比推理更快的呢?
要提前几层预测出来expert的使用情况
整片文章使用了启发解的方式去semantic和trajectory与历史记录的相似性(用cosine similarity),然后选择和历史semantic、trajectory相近的expert去prefetch
LLM中的trajectory是指啥?In this paper, "trajectory" is defined as the collection of probability distributions over experts observed through layers.
大概的意思是,由历史的iteration的内容来推断当前iteration的内容。但是,每个iteration有很多layers, 所以存在semantic和trajectory两种方式。但这两个score咋整合呢???