本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,放在智泊AI。
在大语言模型(LLM)火热的今天,RAG(检索增强生成) 系统几乎成了标配:
- 你提问,模型先去知识库里 召回一堆候选文档;
- 然后再结合这些文档生成答案。
听起来很完美对吧?但问题是------ 召回的候选文档质量参差不齐,真正相关的往往只有少数几个。
这时候就需要一个关键角色登场了: ✨ Rerank(重排序)模型。
它的任务就是:从一堆候选文档里,精准挑出与 query 最相关的内容,并排到前面。
📌 为什么 RAG 需要 Rerank?
想象一下:
- 用户问:"ChatGPT 是什么时候发布的?"
- 检索模块给你返回十几篇文章:有的在讲 GPT-3,有的在讲 GPT-4,有的甚至提 OpenAI 的创始人八卦......
如果没有 Rerank,模型可能胡乱引用,最后回答走偏。 而有了 Rerank,系统就能把 真正相关的文档排在前面,让生成结果更精准。
🛠️ Rerank 的三种训练方式
既然 Rerank 这么重要,那么问题来了:它该怎么训练? 这里有三大经典方法:Pointwise、Pairwise、Listwise。
1️⃣ Pointwise:像打分系统一样
- 输入:一个 (query, doc) 对。
- 目标:预测相关性分数,和标注对齐。
- 适合场景:入门、标注简单,先把相关和不相关区分开。
✅ 简单易上手 ❌ 没直接优化排序
2️⃣ Pairwise:像 PK 一样
- 输入:同一 query 下的 (doc⁺, doc⁻)。
- 目标:保证 doc⁺ 的分数高于 doc⁻。
- 适合场景:希望模型学会相对顺序。
✅ 更贴近排序 ❌ 只能学局部对比,不保证全局最优
3️⃣ Listwise:像裁判排名一样
- 输入:query + 一组候选文档。
- 目标:优化整个列表的顺序,直接对齐 NDCG/MAP 等指标。
- 适合场景:追求效果、排序指标要求高的应用。
✅ 效果最好,对准任务指标 ❌ 训练复杂,标注和计算成本高
📊 三种方式对比
| 方法 | 输入形式 | 优点 | 缺点 |
|---|---|---|---|
| Pointwise | (query, doc) | 简单,标注易得 | 排序效果有限 |
| Pairwise | (query, doc⁺, doc⁻) | 更贴近排序 | 只保证局部正确 |
| Listwise | (query, doc1, doc2,...) | 效果最佳 | 成本高、实现复杂 |
🎯 总结:在 RAG 系统里怎么选?
- 如果是 快速验证原型:Pointwise 足够。
- 如果想 提高检索精准度:Pairwise 是更稳的选择。
- 如果是 线上大规模高要求应用(搜索、推荐、问答):Listwise 才是终极解法。
一句话: 👉 Pointwise 上手快,Pairwise 更实用,Listwise 效果最好。
学习
我把大模型路线分成L1到L4四个阶段,这份大模型路线大纲已经导出整理打包了,放在智泊AI。
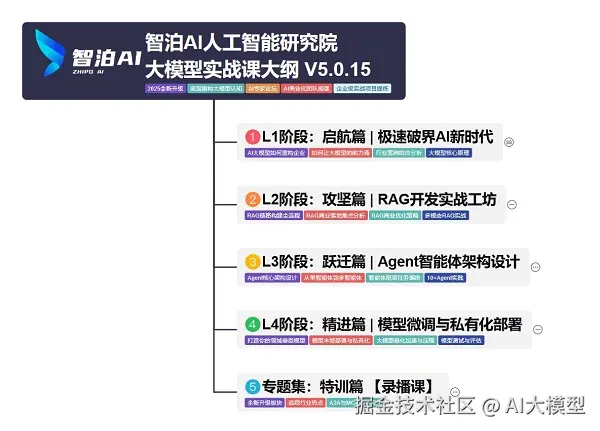
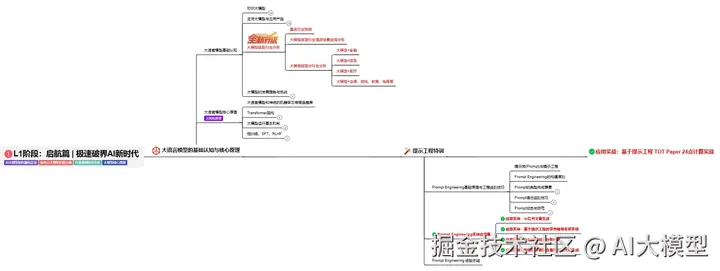
L1阶段:启航篇丨极速破界AI新时代
L1阶段:了解大模型的基础知识,以及大模型在各个行业的应用和分析,学习理解大模型的核心原理、关键技术以及大模型应用场景。
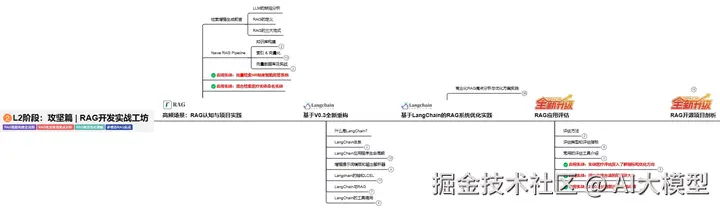
L2阶段:攻坚篇丨RAG开发实战工坊
L2阶段:AI大模型RAG应用开发工程,主要学习RAG检索增强生成:包括Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
L3阶段:跃迁篇丨Agent智能体架构设计
L3阶段:大模型Agent应用架构进阶实现,主要学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造Agent智能体。
L4阶段:精进篇丨模型微调与私有化部署
L4阶段:大模型的微调和私有化部署,更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调,并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。

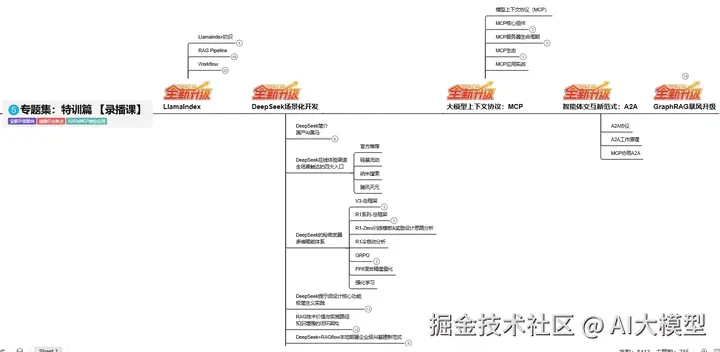
L5阶段:专题集丨特训篇