✨作者主页 :IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
系统介绍
本系统是一个基于大数据技术栈的客户购物订单数据分析与可视化系统,采用Hadoop分布式存储和Spark大数据处理引擎作为核心架构,通过Python/Java语言开发支持,结合Django/Spring Boot后端框架,为电商企业提供全方位的数据分析解决方案。系统以MySQL作为主要数据存储,运用HDFS进行海量数据存储,通过Spark SQL、Pandas、NumPy等技术对客户购物行为进行深度挖掘和分析。前端采用Vue+ElementUI构建现代化管理界面,结合Echarts图表库实现数据可视化展示,支持产品盈利分析、交叉销售分析、客户价值分析、销售市场分布分析、运营绩效分析等多维度业务分析功能。系统能够处理大规模订单数据,通过RFM模型进行客户分层,运用关联规则挖掘算法发现商品间的潜在关联关系,为企业制定精准营销策略、优化产品组合、提升客户价值提供科学的数据支撑和决策依据。
选题背景
随着电子商务行业的迅猛发展,企业每日产生的交易数据呈现爆炸式增长态势,传统的数据处理方式已难以满足海量订单数据的实时分析需求。企业在日常经营过程中积累了大量包含客户信息、商品详情、交易记录、地域分布等多维度的业务数据,这些数据蕴含着丰富的商业价值和市场洞察。然而许多企业缺乏有效的数据分析工具和技术手段,导致宝贵的数据资源无法得到充分利用,管理层难以基于数据做出科学的业务决策。现有的传统数据库和单机分析工具在面对TB级甚至PB级的数据量时表现出明显的性能瓶颈,无法支撑企业对实时数据洞察的迫切需求,这促使企业亟需引入大数据技术来构建高效的数据分析平台。
选题意义
本课题的研究意义主要体现在为企业构建了一套完整的大数据分析解决方案,能够帮助管理层从海量的历史交易数据中挖掘出有价值的商业信息。通过对客户购买行为的深度分析,企业可以更精准地识别高价值客户群体,制定个性化的营销策略,从而提高客户满意度和忠诚度。系统提供的产品关联性分析功能使企业能够发现商品间的潜在销售机会,优化商品搭配和库存配置,提升交叉销售效果。区域市场分析功能为企业的市场拓展和资源配置提供了科学依据,帮助企业识别潜力市场和优化销售渠道布局。从技术角度而言,本系统将理论知识与实践应用相结合,验证了Hadoop和Spark等大数据技术在实际业务场景中的应用效果,为相关领域的研究提供了参考案例。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的客户购物订单数据分析与可视化系统界面展示:
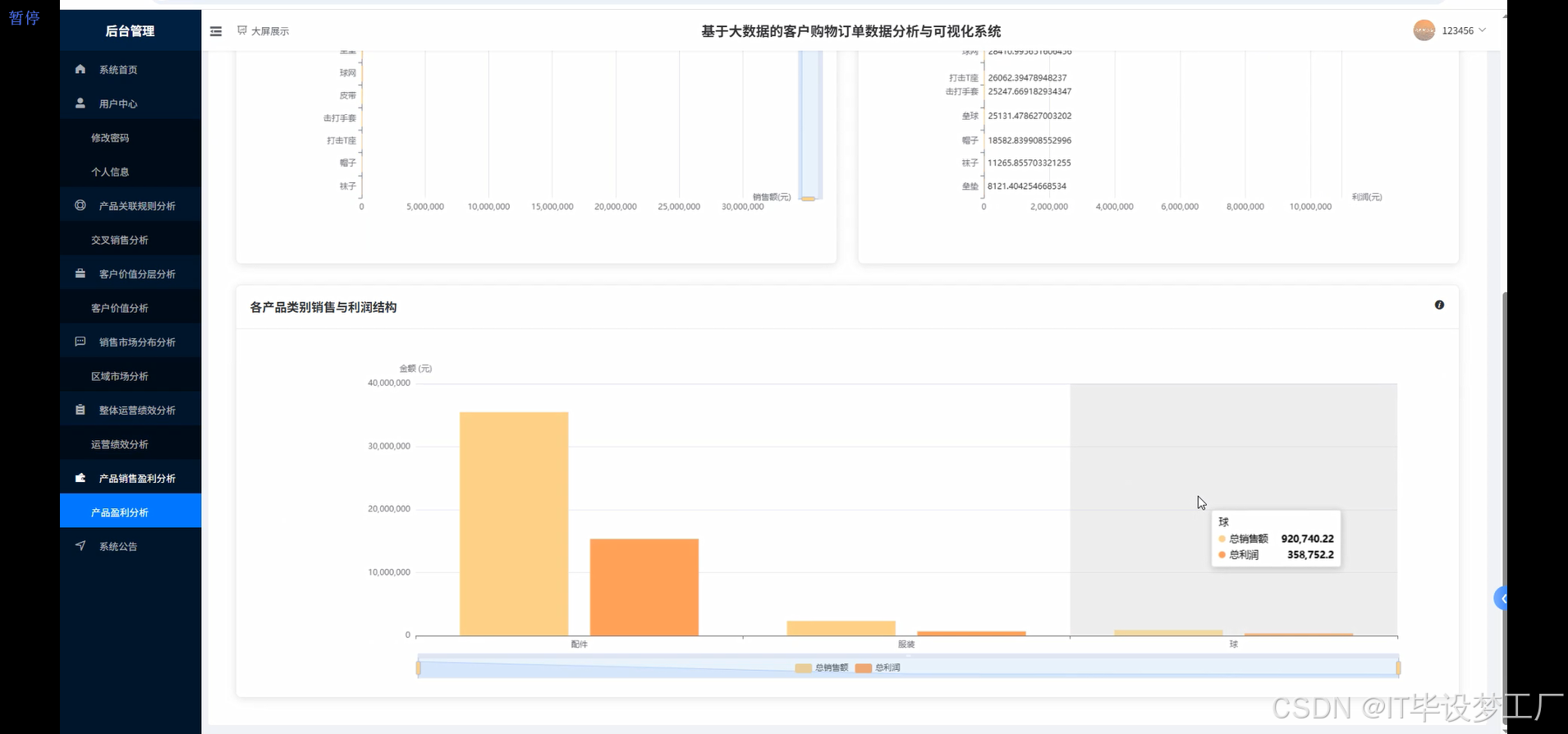
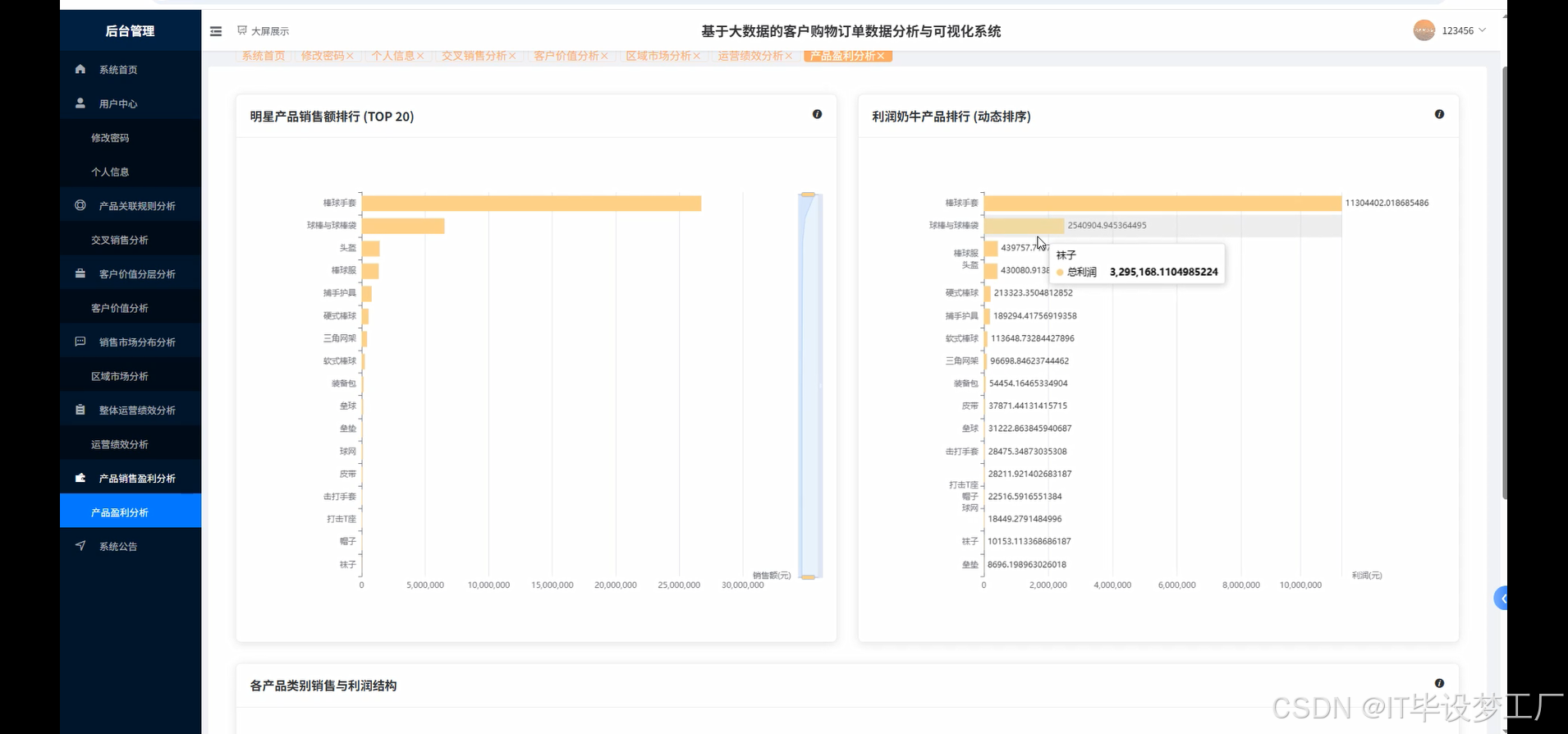
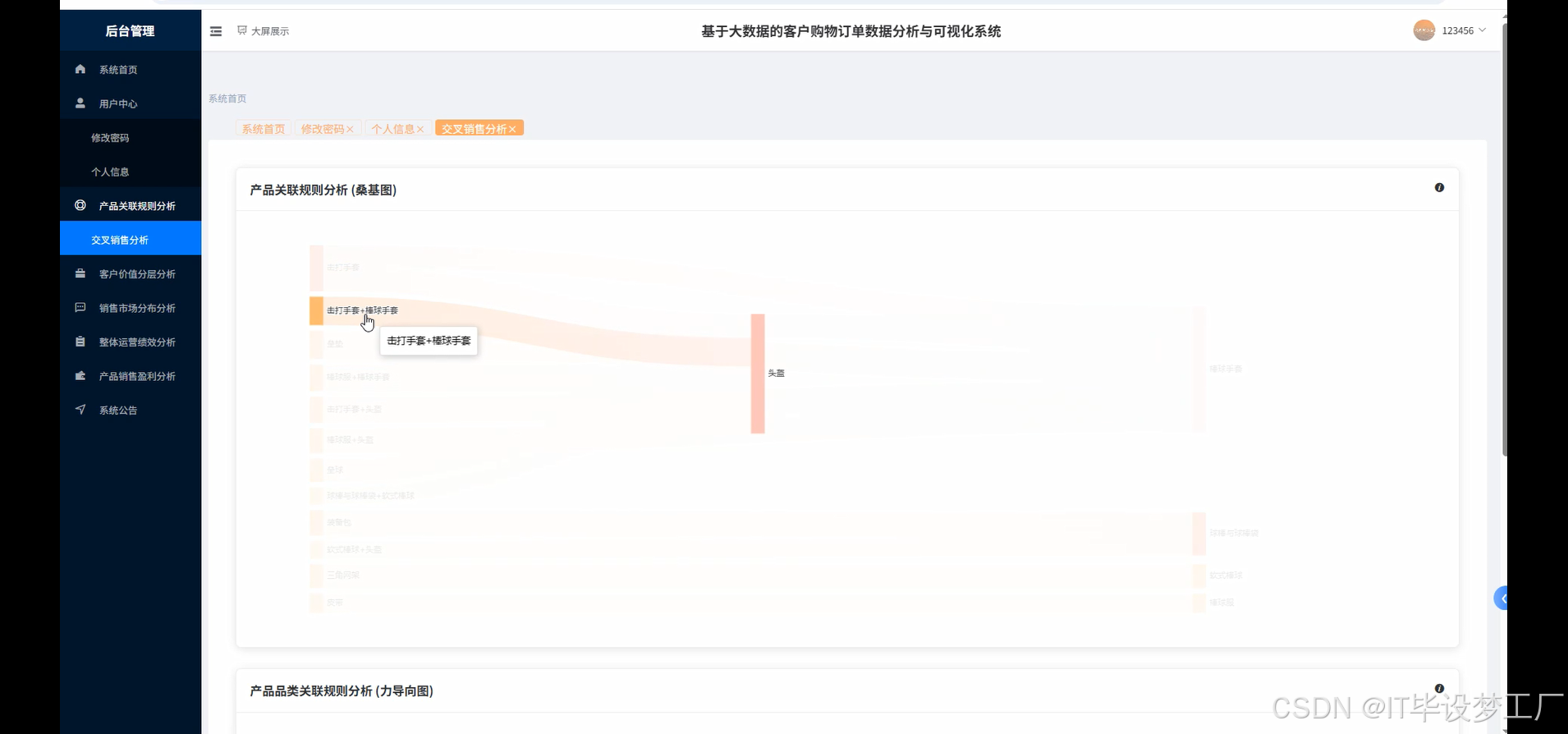

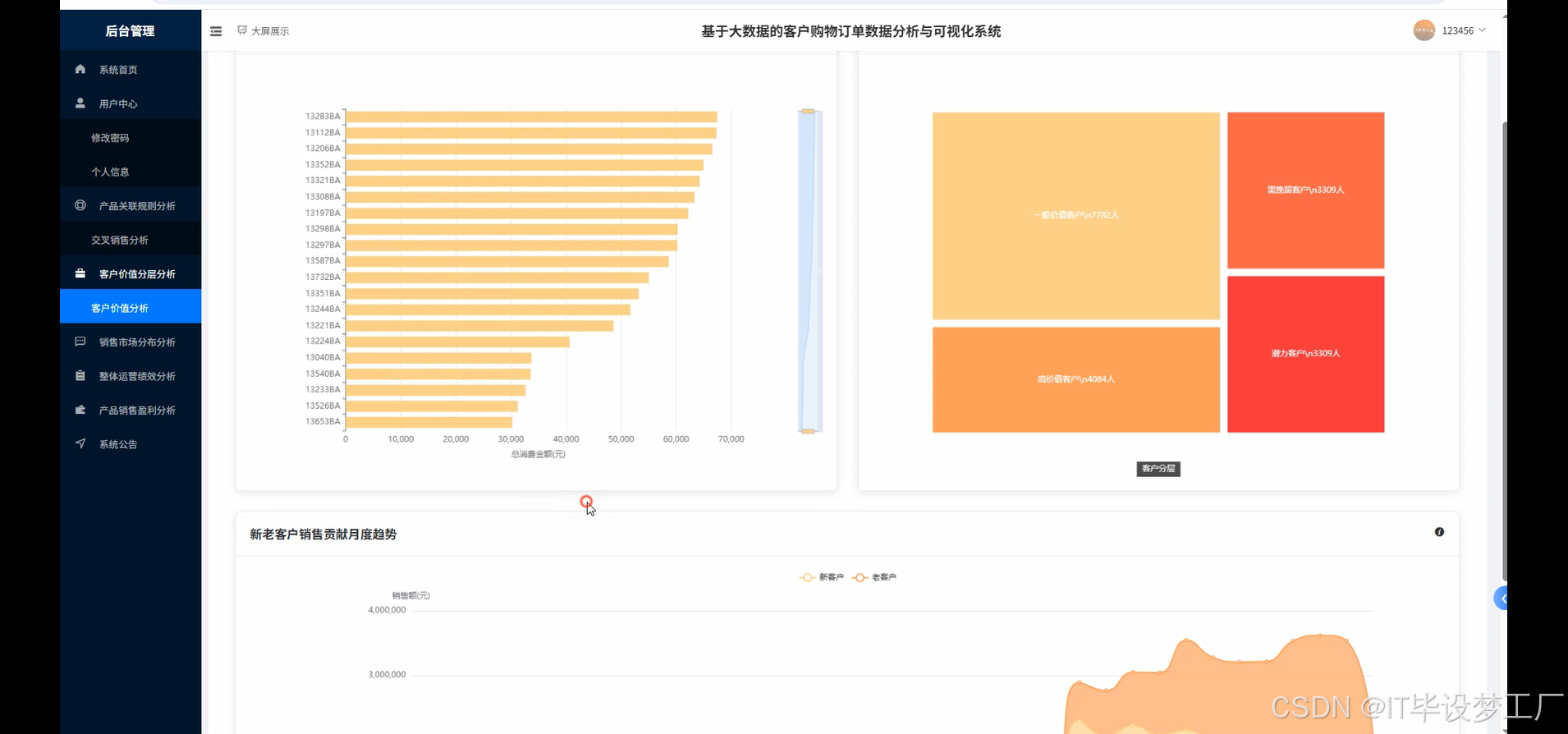
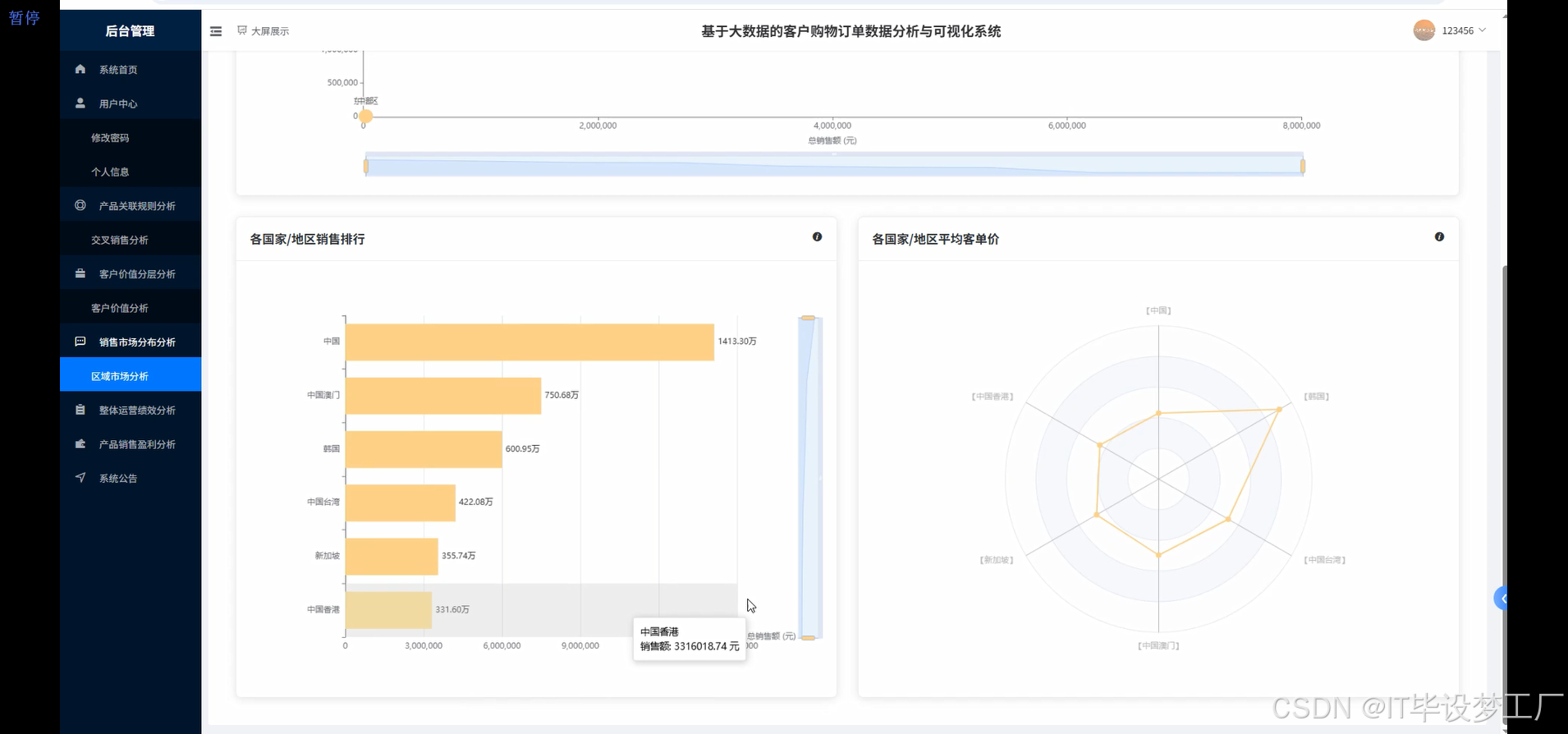
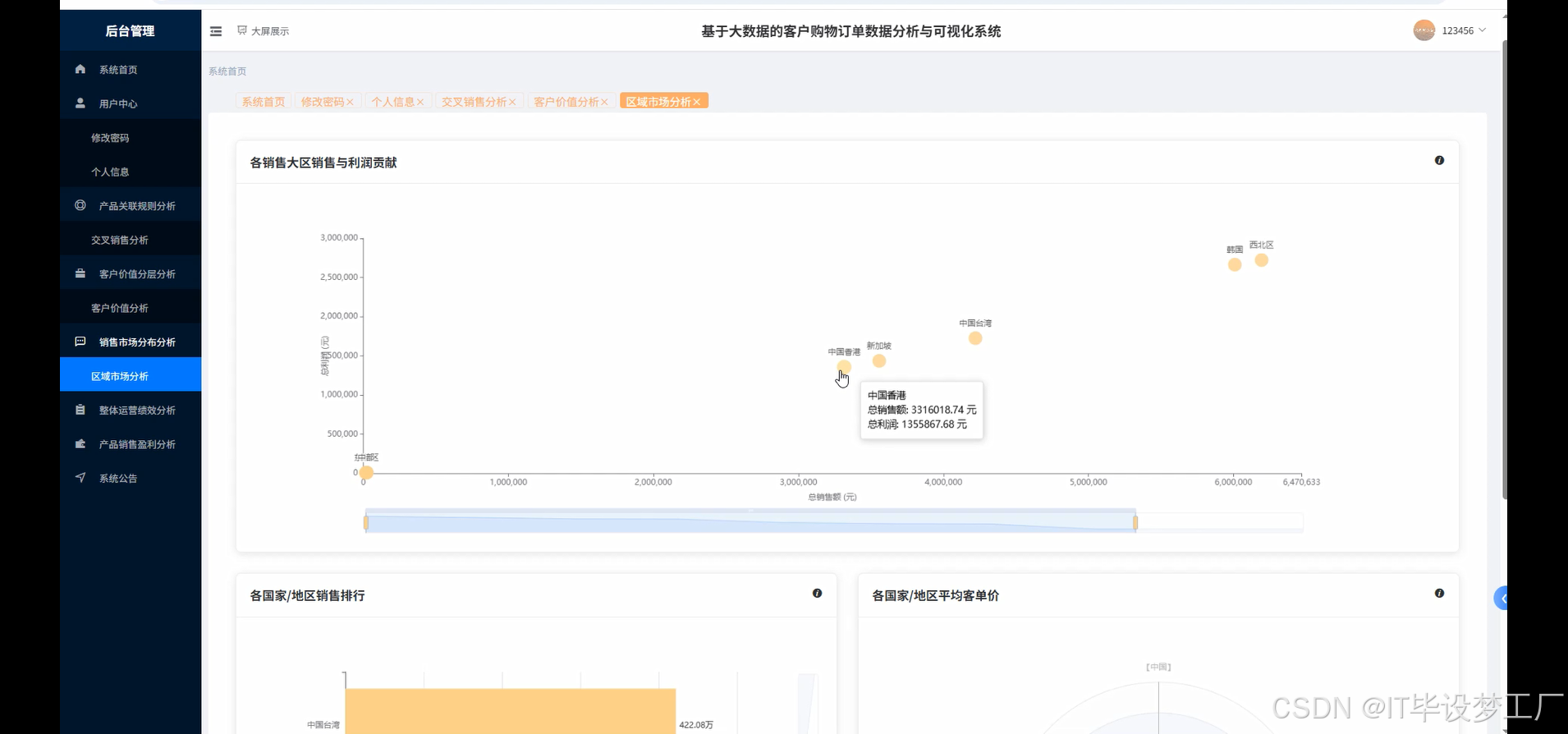
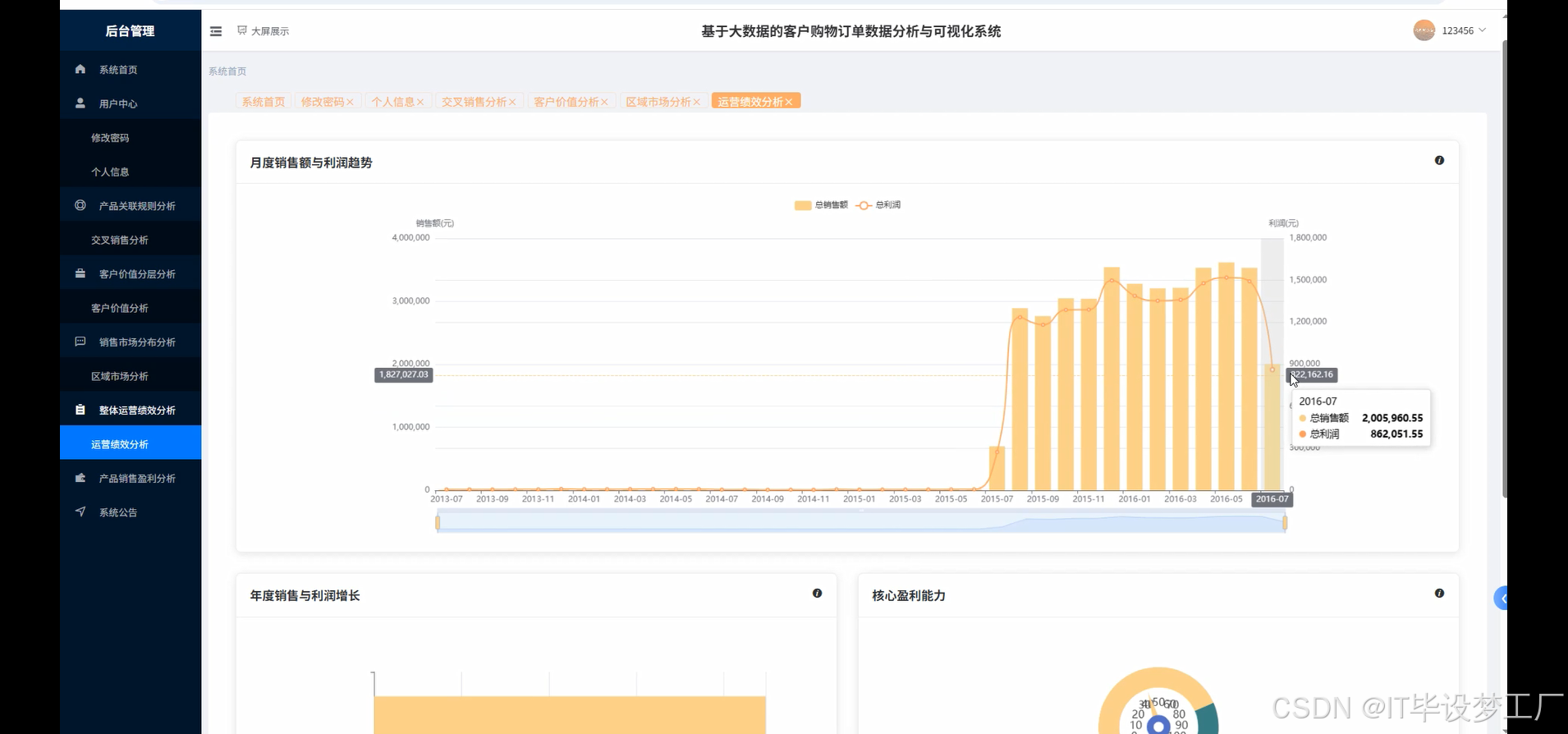
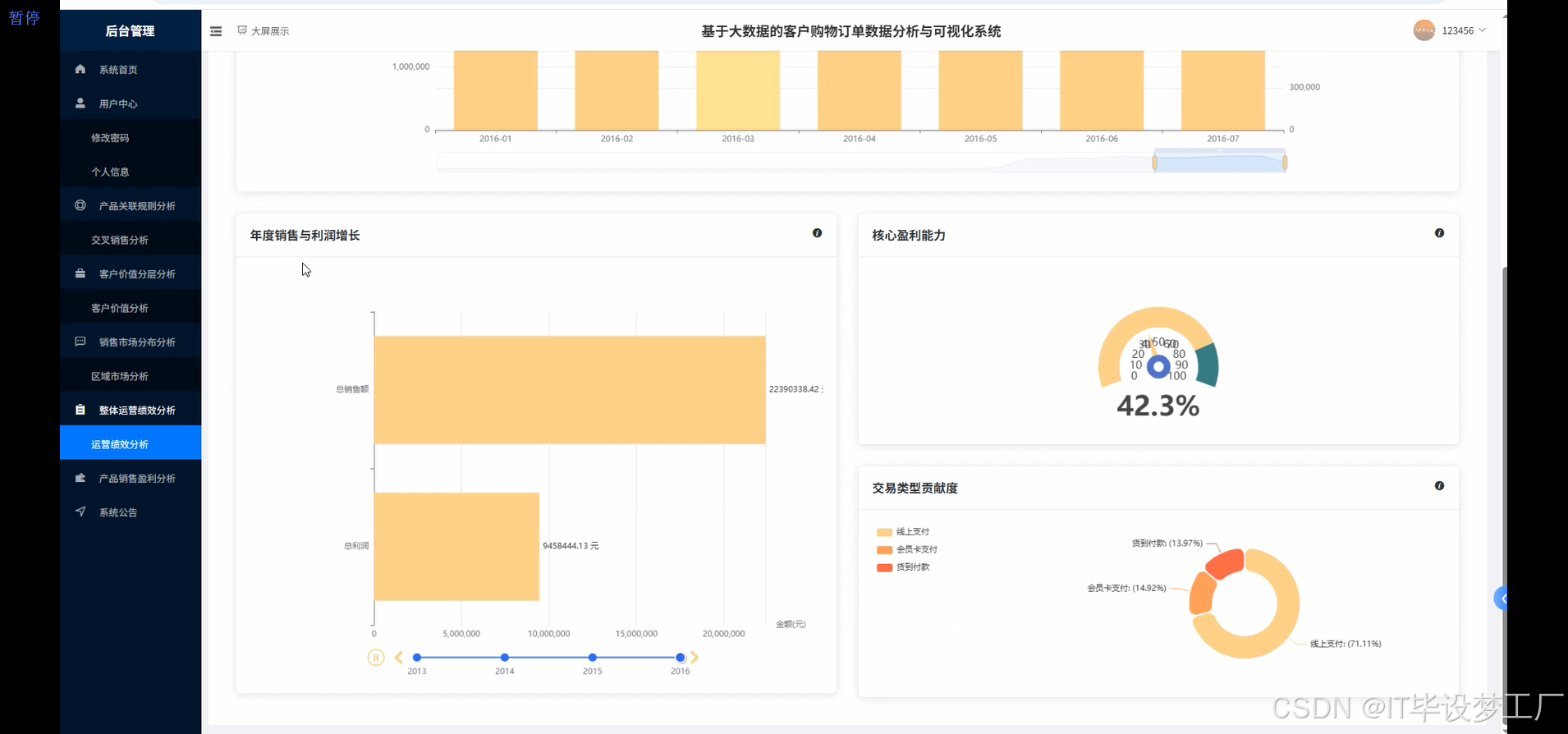
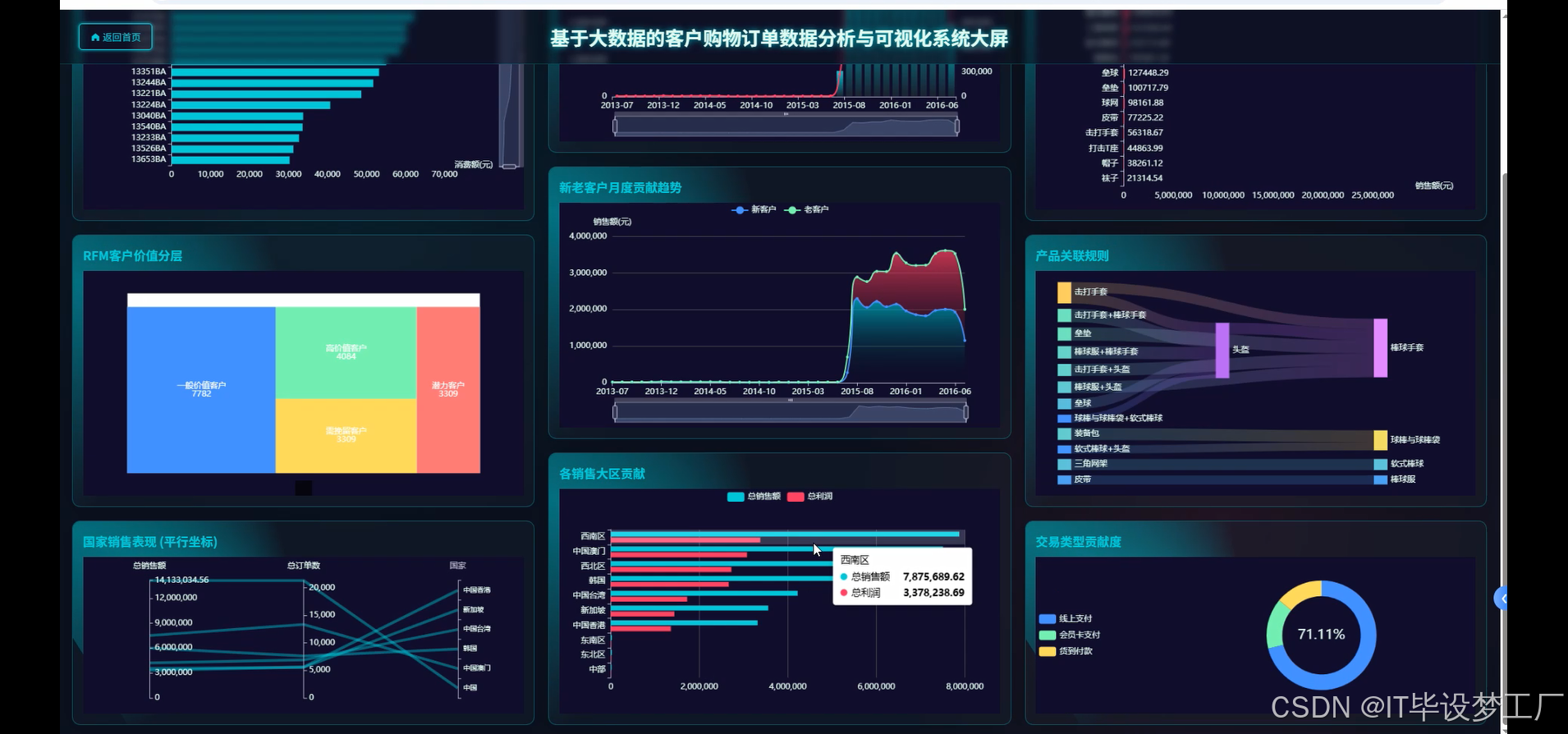
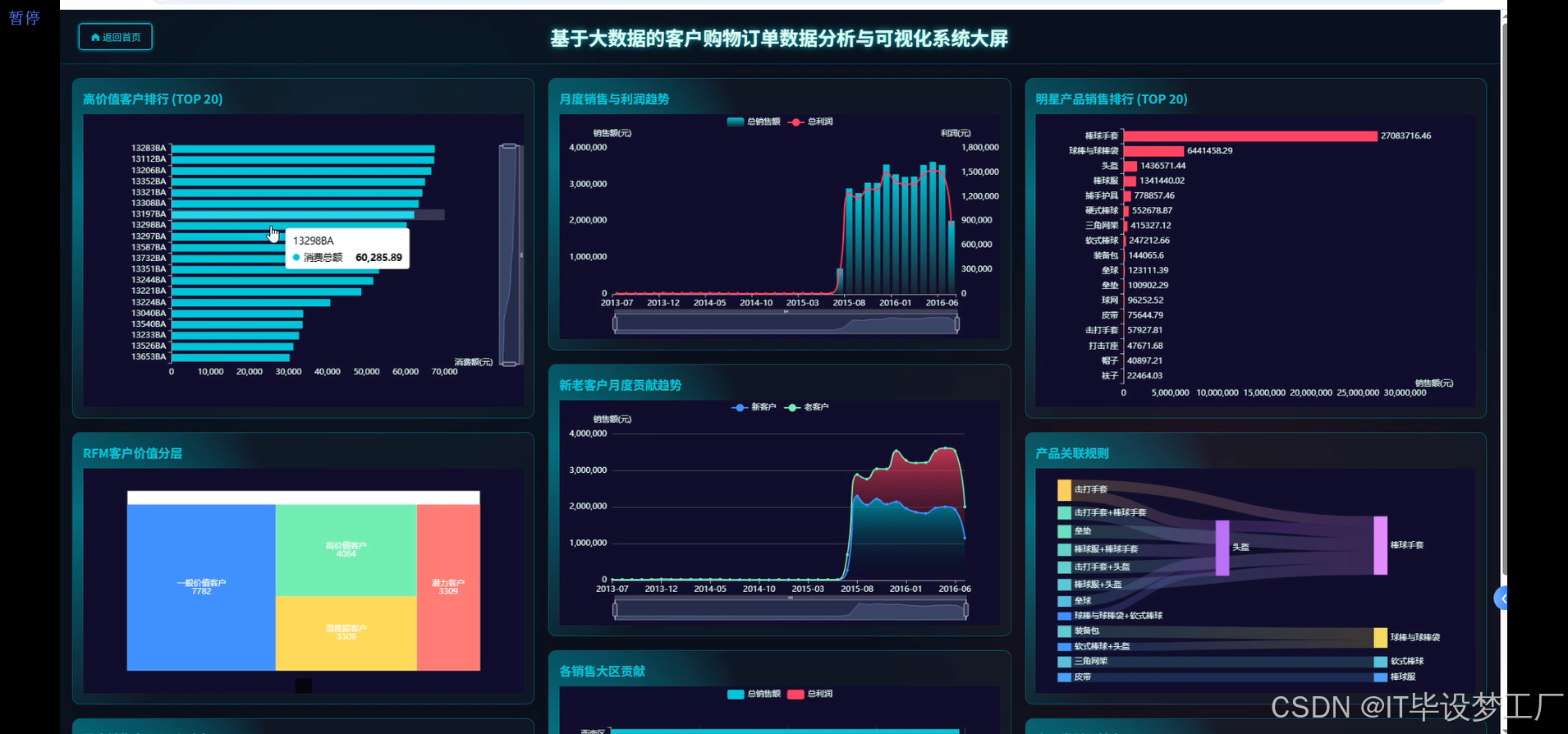
四、部分代码设计
- 项目实战-代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
from pyspark.ml.fpm import FPGrowth
import pandas as pd
import numpy as np
from datetime import datetime, timedelta
from django.http import JsonResponse
from django.views import View
import json
spark = SparkSession.builder.appName("CustomerOrderAnalysis").config("spark.sql.adaptive.enabled", "true").config("spark.sql.adaptive.coalescePartitions.enabled", "true").getOrCreate()
class CustomerValueAnalysis(View):
def post(self, request):
data = json.loads(request.body)
start_date = data.get('start_date', '2015-01-01')
end_date = data.get('end_date', '2016-12-31')
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/order_db").option("dbtable", "order_data").option("user", "root").option("password", "password").load()
df_filtered = df.filter((col("订单日期") >= start_date) & (col("订单日期") <= end_date))
current_date = datetime.now()
df_with_recency = df_filtered.withColumn("days_since_last_order", datediff(lit(current_date), to_date(col("订单日期"), "yyyy/M/d")))
customer_metrics = df_with_recency.groupBy("客户ID").agg(
min("days_since_last_order").alias("recency"),
count("订单日期").alias("frequency"),
sum("销售金额").alias("monetary")
)
r_quartiles = customer_metrics.approxQuantile("recency", [0.25, 0.5, 0.75], 0.01)
f_quartiles = customer_metrics.approxQuantile("frequency", [0.25, 0.5, 0.75], 0.01)
m_quartiles = customer_metrics.approxQuantile("monetary", [0.25, 0.5, 0.75], 0.01)
def get_rfm_score(recency, frequency, monetary):
r_score = 4 if recency <= r_quartiles[0] else 3 if recency <= r_quartiles[1] else 2 if recency <= r_quartiles[2] else 1
f_score = 4 if frequency >= f_quartiles[2] else 3 if frequency >= f_quartiles[1] else 2 if frequency >= f_quartiles[0] else 1
m_score = 4 if monetary >= m_quartiles[2] else 3 if monetary >= m_quartiles[1] else 2 if monetary >= m_quartiles[0] else 1
return r_score * 100 + f_score * 10 + m_score
get_rfm_score_udf = udf(get_rfm_score, IntegerType())
customer_rfm = customer_metrics.withColumn("rfm_score", get_rfm_score_udf(col("recency"), col("frequency"), col("monetary")))
def categorize_customer(rfm_score):
if rfm_score >= 444: return "高价值客户"
elif rfm_score >= 344: return "重要保持客户"
elif rfm_score >= 244: return "重要发展客户"
elif rfm_score >= 144: return "重要挽留客户"
else: return "一般维持客户"
categorize_udf = udf(categorize_customer, StringType())
customer_segments = customer_rfm.withColumn("customer_segment", categorize_udf(col("rfm_score")))
result_df = customer_segments.groupBy("customer_segment").agg(count("客户ID").alias("customer_count"), avg("monetary").alias("avg_monetary")).orderBy(desc("avg_monetary"))
result_pandas = result_df.toPandas()
top_customers = customer_segments.orderBy(desc("monetary")).limit(20).select("客户ID", "recency", "frequency", "monetary", "customer_segment").toPandas()
return JsonResponse({'status': 'success', 'customer_segments': result_pandas.to_dict('records'), 'top_customers': top_customers.to_dict('records')})
class CrossSalesAnalysis(View):
def post(self, request):
data = json.loads(request.body)
min_support = data.get('min_support', 0.01)
min_confidence = data.get('min_confidence', 0.5)
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/order_db").option("dbtable", "order_data").option("user", "root").option("password", "password").load()
transaction_data = df.groupBy("客户ID", "订单日期").agg(collect_list("产品名称").alias("items"))
fp_growth = FPGrowth(itemsCol="items", minSupport=min_support, minConfidence=min_confidence)
model = fp_growth.fit(transaction_data)
frequent_itemsets = model.freqItemsets.filter(size(col("items")) >= 2).orderBy(desc("freq")).limit(50)
association_rules = model.associationRules.orderBy(desc("confidence")).limit(100)
product_correlation = df.alias("a").join(df.alias("b"), (col("a.客户ID") == col("b.客户ID")) & (col("a.订单日期") == col("b.订单日期")) & (col("a.产品名称") != col("b.产品名称"))).select(col("a.产品名称").alias("product_a"), col("b.产品名称").alias("product_b"))
correlation_counts = product_correlation.groupBy("product_a", "product_b").count().filter(col("count") >= 10).orderBy(desc("count"))
category_correlation = df.alias("a").join(df.alias("b"), (col("a.客户ID") == col("b.客户ID")) & (col("a.订单日期") == col("b.订单日期")) & (col("a.产品类别") != col("b.产品类别"))).select(col("a.产品类别").alias("category_a"), col("b.产品类别").alias("category_b"))
category_counts = category_correlation.groupBy("category_a", "category_b").count().filter(col("count") >= 20).orderBy(desc("count"))
total_transactions = transaction_data.count()
itemsets_with_support = frequent_itemsets.withColumn("support_percent", round((col("freq") / total_transactions) * 100, 2))
rules_with_metrics = association_rules.withColumn("confidence_percent", round(col("confidence") * 100, 2)).withColumn("lift_value", round(col("lift"), 2))
cross_sell_opportunities = rules_with_metrics.filter((col("confidence") >= min_confidence) & (col("lift") >= 1.2)).select("antecedent", "consequent", "confidence_percent", "lift_value").orderBy(desc("lift_value"))
result_data = {
'frequent_itemsets': itemsets_with_support.limit(30).toPandas().to_dict('records'),
'association_rules': rules_with_metrics.limit(50).toPandas().to_dict('records'),
'cross_sell_opportunities': cross_sell_opportunities.limit(20).toPandas().to_dict('records'),
'product_correlations': correlation_counts.limit(30).toPandas().to_dict('records'),
'category_correlations': category_counts.limit(20).toPandas().to_dict('records')
}
return JsonResponse({'status': 'success', 'analysis_results': result_data})
class RegionalSalesAnalysis(View):
def post(self, request):
data = json.loads(request.body)
analysis_type = data.get('analysis_type', 'region')
time_period = data.get('time_period', 'monthly')
df = spark.read.format("jdbc").option("url", "jdbc:mysql://localhost:3306/order_db").option("dbtable", "order_data").option("user", "root").option("password", "password").load()
df_processed = df.withColumn("order_month", date_format(to_date(col("订单日期"), "yyyy/M/d"), "yyyy-MM")).withColumn("order_year", year(to_date(col("订单日期"), "yyyy/M/d")))
if analysis_type == 'region':
regional_performance = df_processed.groupBy("销售大区", "国家").agg(
sum("销售金额").alias("total_sales"),
sum("利润").alias("total_profit"),
count("客户ID").alias("order_count"),
countDistinct("客户ID").alias("unique_customers"),
avg("销售金额").alias("avg_order_value")
).withColumn("profit_margin", round((col("total_profit") / col("total_sales")) * 100, 2))
top_regions = regional_performance.orderBy(desc("total_sales")).limit(20)
region_growth = df_processed.groupBy("销售大区", "order_year").agg(sum("销售金额").alias("yearly_sales")).withColumn("prev_year_sales", lag("yearly_sales").over(Window.partitionBy("销售大区").orderBy("order_year"))).withColumn("growth_rate", round(((col("yearly_sales") - col("prev_year_sales")) / col("prev_year_sales")) * 100, 2)).filter(col("growth_rate").isNotNull())
elif analysis_type == 'country':
country_performance = df_processed.groupBy("国家").agg(
sum("销售金额").alias("total_sales"),
sum("利润").alias("total_profit"),
count("客户ID").alias("order_count"),
countDistinct("客户ID").alias("unique_customers"),
avg("销售金额").alias("avg_order_value")
).withColumn("profit_margin", round((col("total_profit") / col("total_sales")) * 100, 2))
top_countries = country_performance.orderBy(desc("total_sales")).limit(15)
seasonal_trends = df_processed.groupBy("order_month").agg(
sum("销售金额").alias("monthly_sales"),
sum("利润").alias("monthly_profit"),
count("客户ID").alias("monthly_orders")
).orderBy("order_month")
market_share = df_processed.groupBy("销售大区").agg(sum("销售金额").alias("region_sales"))
total_sales = df_processed.agg(sum("销售金额").alias("total")).collect()[0]["total"]
market_share_with_percent = market_share.withColumn("market_share_percent", round((col("region_sales") / total_sales) * 100, 2)).orderBy(desc("market_share_percent"))
customer_penetration = df_processed.groupBy("国家").agg(
countDistinct("客户ID").alias("unique_customers"),
count("客户ID").alias("total_orders")
).withColumn("orders_per_customer", round(col("total_orders") / col("unique_customers"), 2)).orderBy(desc("orders_per_customer"))
result_data = {
'regional_performance': top_regions.toPandas().to_dict('records') if analysis_type == 'region' else [],
'country_performance': top_countries.toPandas().to_dict('records') if analysis_type == 'country' else [],
'seasonal_trends': seasonal_trends.toPandas().to_dict('records'),
'market_share': market_share_with_percent.toPandas().to_dict('records'),
'customer_penetration': customer_penetration.toPandas().to_dict('records'),
'region_growth': region_growth.toPandas().to_dict('records') if analysis_type == 'region' else []
}
return JsonResponse({'status': 'success', 'regional_analysis': result_data})五、系统视频
- 基于大数据的客户购物订单数据分析与可视化系统项目视频:
大数据毕业设计选题推荐-基于大数据的客户购物订单数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的客户购物订单数据分析与可视化系统-Hadoop-Spark-数据可视化-BigData
想看其他类型的计算机毕业设计作品也可以和我说~谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇