一、前 言
本文核心介绍,为何业界会有这样的说法?------ "MySQL单表存储数据量最好别超过千万级别"
当然这里是有前提条件的,也是我们最常使用到的:
- InnoDB存储引擎;
- 使用的是默认索引数据结构------B+树;
- 正常普通表数据(列数量控制在几个到一二十个,普通字段类型及长度)。
接下来咱们就探究一下原因,逐步揭开答案。
二、MySQL是如何存储数据的?
核心结构:B+树 + 16KB数据页
这里如下,建一张普通表user:
sql
CREATE TABLE `user` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT COMMENT '主键',
`name` varchar(100) NOT NULL DEFAULT '' COMMENT '名字',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
PRIMARY KEY (`id`),
KEY `idx_age` (`age`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;数据页(Page)
介绍
InnoDB存储的最小单位,固定为16KB 。每页存储表数据(行记录)、索引、元信息等。数据加载到内存时以页为单位,减少磁盘I/O次数。
页的结构
假设我们有这么一张user数据表。其中id是唯一主键 。这看起来的一行行数据,为了方便,我们后面就叫它们record 吧。这张表看起来就跟个excel表格一样。excel的数据在硬盘上是一个xx.excel的文件。而上面user表数据,在硬盘上其实也是类似,放在了user.ibd 文件下。含义是user表的innodb data文件,又叫表空间 。虽然在数据表里,它们看起来是挨在一起的。但实际上在user.ibd里他们被分成很多小份的数据页,每份大小16k。类似于下面这样。
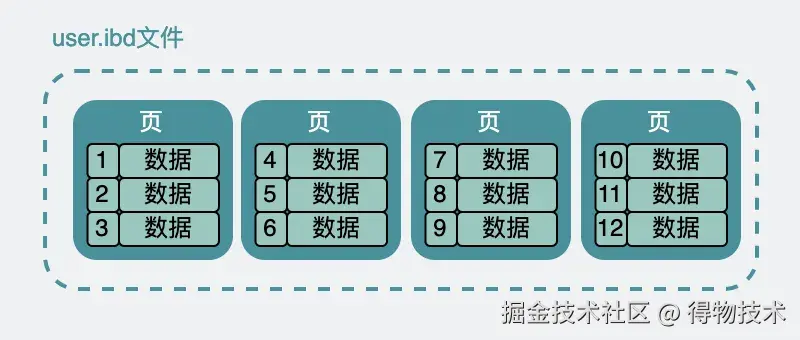
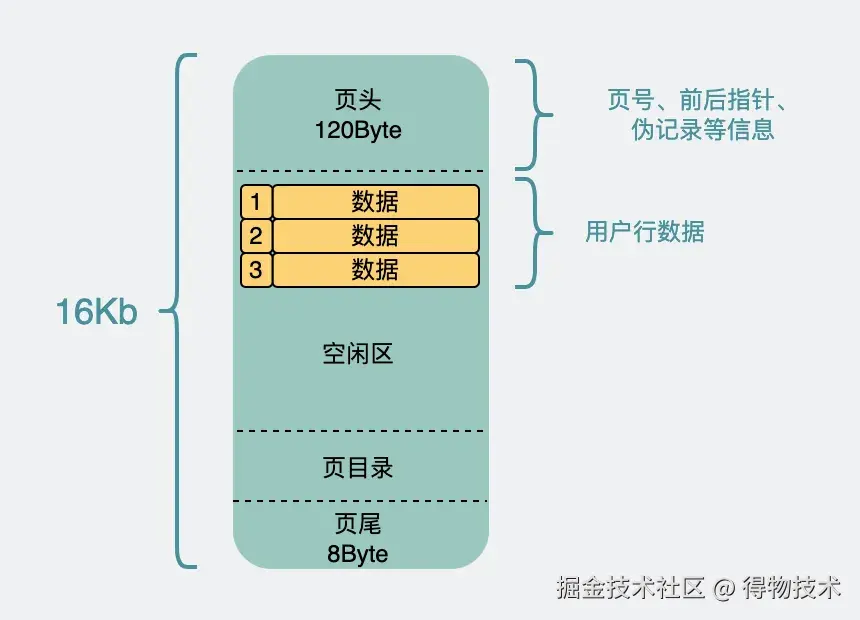
ibd文件内部有大量的页,我们把视角聚焦一下,放到页上面。整个页16k,不大,但record这么多,一页肯定放不下,所以会分开放到很多页里。并且这16k,也不可能全用来放record对吧。因为record们被分成好多份,放到好多页里了,为了唯一标识具体是哪一页,那就需要引入页号 (其实是一个表空间的地址偏移量)。同时为了把这些数据页给关联起来,于是引入了前后指针 ,用于指向前后的页。这些都被加到了页头 里。页是需要读写的,16k说小也不小,写一半电源线被拔了也是有可能发生的,所以为了保证数据页的正确性,还引入了校验码。这个被加到了页尾 。那剩下的空间,才是用来放我们的record的。而record如果行数特别多的话,进入到页内时挨个遍历,效率也不太行,所以为这些数据生成了一个页目录 ,具体实现细节不重要。只需要知道,它可以通过二分查找 的方式将查找效率从O(n) 变成O(lgn) 。
从页到索引---B+树索引
如果想查一条record,我们可以把表空间里每一页都捞出来(全表扫描),再把里面的record捞出来挨个判断是不是我们要找的。行数量小的时候,这么操作也没啥问题。行数量大了,性能就慢了 ,于是为了加速搜索,我们可以在每个数据页里选出主键id最小 的record,而且只需要它们的主键id和所在页的页号 。组成新的record ,放入到一个新生成的一个数据页中,这个新数据页跟之前的页结构没啥区别,而且大小还是16k 。但为了跟之前的数据页进行区分。数据页里加入了页层级(page level) 的信息,从0开始往上算。于是页与页之间就有了上下层级的概念,就像下面这样。
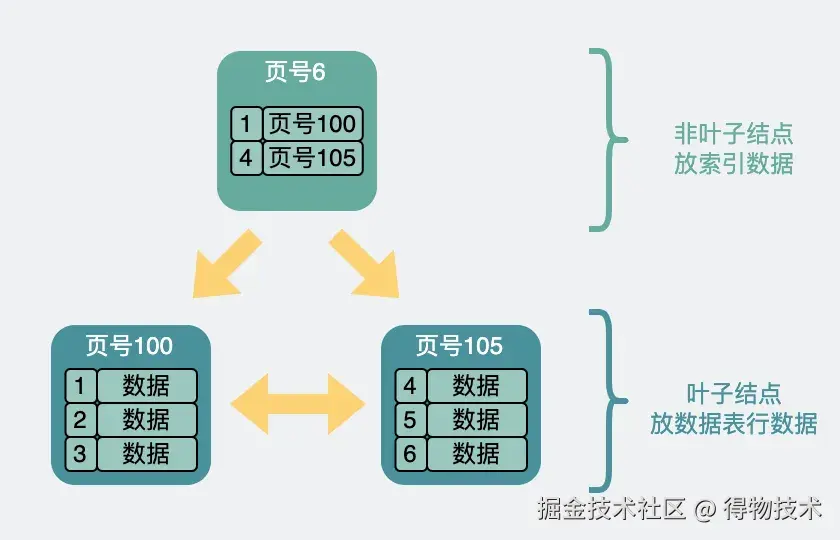
突然页跟页之间看起来就像是一棵倒过来的树了。也就是我们常说的B+ 树索引。最下面那一层,page level 为0 ,也就是所谓的叶子结点 ,其余都叫非叶子结点。上面展示的是两层的树,如果数据变多了,我们还可以再通过类似的方法,再往上构建一层。就成了三层的树。
- 聚簇索引:数据按主键组织成一棵B+树。叶子节点存储完整行数据 ,非叶子节点存储主键值+指向子页的指针(类似目录)。
- 二级索引:叶子节点存储主键值,查询时需回表(根据主键回聚簇索引查数据)。
- 行格式 :如COMPACT格式,行数据包含事务ID、回滚指针、列值等信息。行大小影响单页存储的行数。
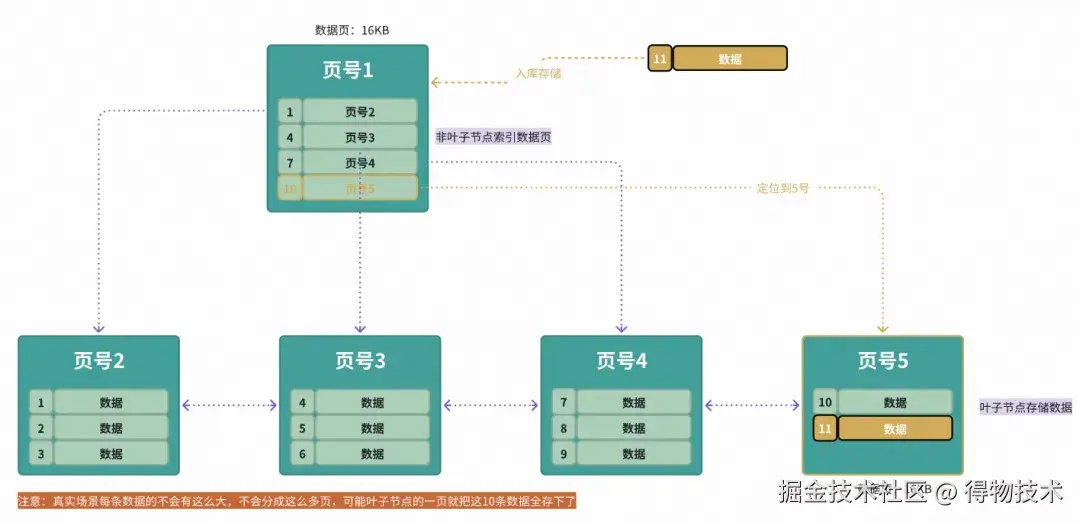
存入数据如下
比如表数据已存在id为1-10的数据存储,简单比方如下:
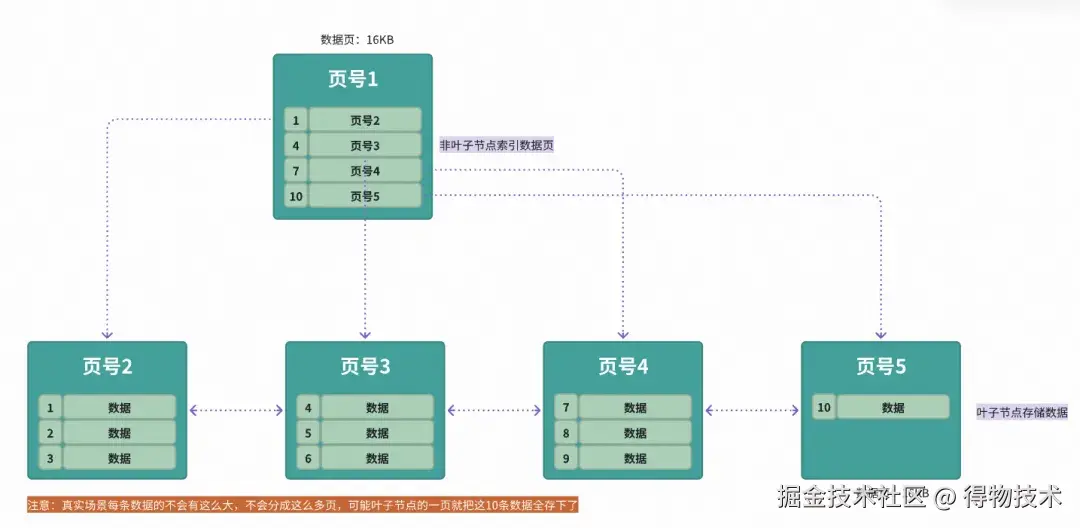
然后需要插入id=11的数据:
- 加载1号数据页入内存,分析判定;
- id=11的数据大于id=10,那么锁定页号5,判定5号页是否还可以存下数据11;
- 可以存下,将id=11的数据写入到5号页中。
关键原理总结
所有数据通过B+树有序组织,数据存储在数据页上,页与页之间以双向链表连接,非叶子节点提供快速定位路径,叶子节点存储实际的数据。
三、MySQL是如何查询到数据的?
上面我们已经介绍了MySQL中使用页存储数据,以及B+树索引数据的结构,那现在我们就可以通过这样一棵B+树加速查询。
**举个例子:select ***
from table where id = 5
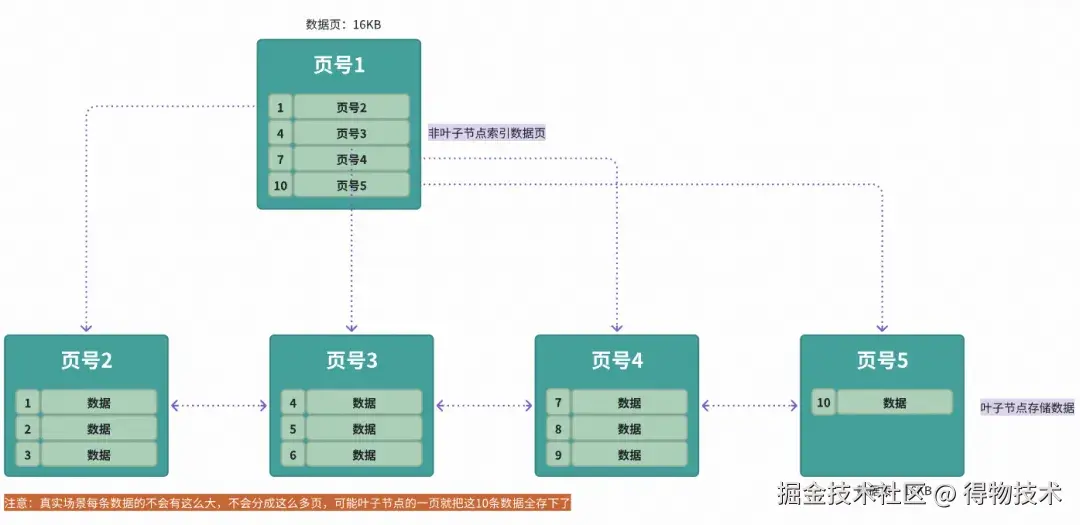
比方说我们想要查找行数据5。会先从顶层页的record们入手。record里包含了主键id和页号(页地址) 。
如下图所示,左边2号页最小id是1,向右3号页最小id是4,然后4号页最小是7,最后5号页最小是10。
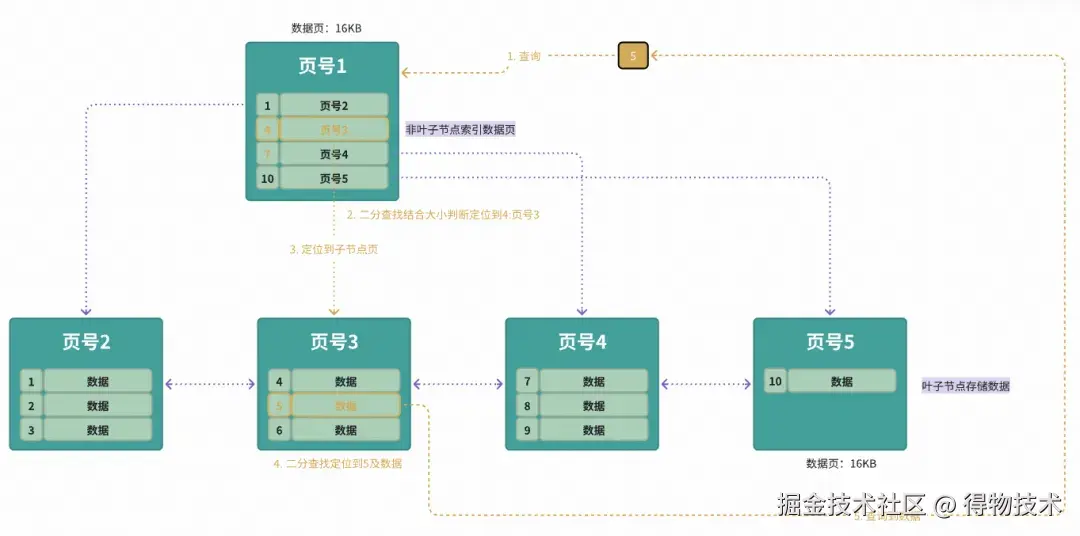
那id=5的数据如果存在,5大于4小于7,那必定在3号页里面 。于是顺着的record的页地址就到了3号数据页里,于是加载3号数据页到内存。在数据页里找到id=5的数据行,完成查询。
另外需要注意的是,上面的页的页号并不是连续的,它们在磁盘里也不一定是挨在一起的。这个过程中查询了2个页(1号跟3号),如果这三个页都在磁盘中(没有被提前加载到内存中),那么最多 需要经历两次磁盘IO查询,它们才能被加载到内存中。(如果考虑1号如果是root常驻内存,那么需要磁盘IO一次即可定位到)。
查询步骤总结
以聚簇索引搜索为例(假设id是主键):
- 从根页开始搜索 :
加载根页(常驻内存)到Buffer Pool,根据指针找到下一层节点。
- 逐层定位叶子节点 :
在非叶子节点页(存储主键+指针)中二分查找 ,定位id=5所在范围的子页(如页A)。
重复此过程,直到叶子节点页。
- 叶子节点二分查找 :
在叶子页内通过主键二分查找定位到行记录,返回完整数据。
I/O次数分析 :
- 树高为3时:根页 + 中间页 + 叶子页 = 3次磁盘I/O (若页不在内存中)。
- B+树矮胖特性 :3层即可支撑千万级数据(接下来分析),是高效查询的基础。
四、2000万这个上限值如何算出来的?
在我们清楚了MySQL是如何存储及查询数据后,那么2000万这个数值又是如何得来的呢?超过2000万比如存储一亿数据会如何?
B+树承载的记录数量
从上面的结构里可以看出B+树的最末级叶子结点 里放了record数据。而非叶子结点里则放了用来加速查询的索引数据。也就是说同样一个16k的页,非叶子节点里每一条数据都指向一个新的页,而新的页有两种可能。
- 如果是末级叶子节点的话,那么里面放的就是一行行record数据。
- 如果是非叶子节点,那么就会循环继续指向新的数据页。
假设
- 非叶子节点内指向其他内存页的指针数量为x(非叶子节点指针扇出值)
- 叶子节点内能容纳的record数量为y(叶子节点单页行数)
- B+树的层数为z(树高)
那这棵B+树放的行数据总量等于 (x ^ (z-1)) * y。
核心公式:单表最大行数 = 非叶节点扇出指针数 ^ (树高-1) × 单页行数
非叶子节点指针扇出值---x 怎么算?
我们回去看数据页的结构。
非叶子节点里主要放索引查询相关的数据,放的是主键和指向页号。
- 主键假设是bigint(8Byte),而页号在源码里叫FIL_PAGE_OFFSET(4Byte),那么非叶子节点里的一条数据是12Byte左右。
- 整个数据页16k, 页头页尾那部分数据全加起来大概128Byte,加上页目录毛估占1k吧。那剩下的15k除以12Byte,等于1280,也就是可以指向x=1280页。
我们常说的二叉树指的是一个结点可以发散出两个新的结点。m叉树一个节点能指向m个新的结点。这个指向新节点的操作就叫扇出(fanout) 。而上面的B+树,它能指向1280个新的节点,恐怖如斯,可以说扇出非常高了。
单页行数---y的计算
叶子节点和非叶子节点的数据结构是一样的,所以也假设剩下15kb可以发挥。
叶子节点里放的是真正的行数据。假设一条行数据1kb,所以一页里能放y=15行。
行总数计算
回到 (x ^ (z-1)) * y 这个公式。
已知x=1280,y=15。
假设B+树是两层,那z=2。则是(1280 ^ (2-1)) * 15 ≈ 2w
假设B+树是三层 ,那z=3。则是 (1280 ^ (3-1)) * 15 ≈ 2.5kw
这个2.5kw,就是我们常说的单表建议最大行数2kw的由来。 毕竟再加一层,数据就大得有点离谱了。三层数据页对应最多三次磁盘IO,也比较合理。
- 临界点 :当行数突破约2000万时,树高可能从3层变为4层:
- 树高=4时:最大行数 ≈ 1280^3 × 15 结果已超过百亿(远大于2000万)
- 性能断崖 :树高从3→4,查询I/O次数从3次增至4次 (多一次磁盘寻址),尤其在回表查询、高并发、深分页时性能骤降。
行数超一亿就慢了吗?
上面假设单行数据用了1kb,所以一个数据页能放个15行数据。
如果我单行数据用不了这么多,比如只用了250byte。那么单个数据页能放60行数据。
那同样是三层B+树,单表支持的行数就是 (1280 ^ (3-1)) * 60 ≈ 1个亿。
你看我一个亿的数据,其实也就三层B+树,在这个B+树里要查到某行数据,最多也是三次磁盘IO。所以并不慢。
B树承载的记录数量
我们都知道,现在MySQL的索引都是B+树,而有一种树,跟B+树很像,叫B树,也叫B-树。
它跟B+树最大的区别在于,B+树只在末级叶子结点处放数据表行数据,而B树则会在叶子和非叶子结点上都放。
于是,B树的结构就类似这样:
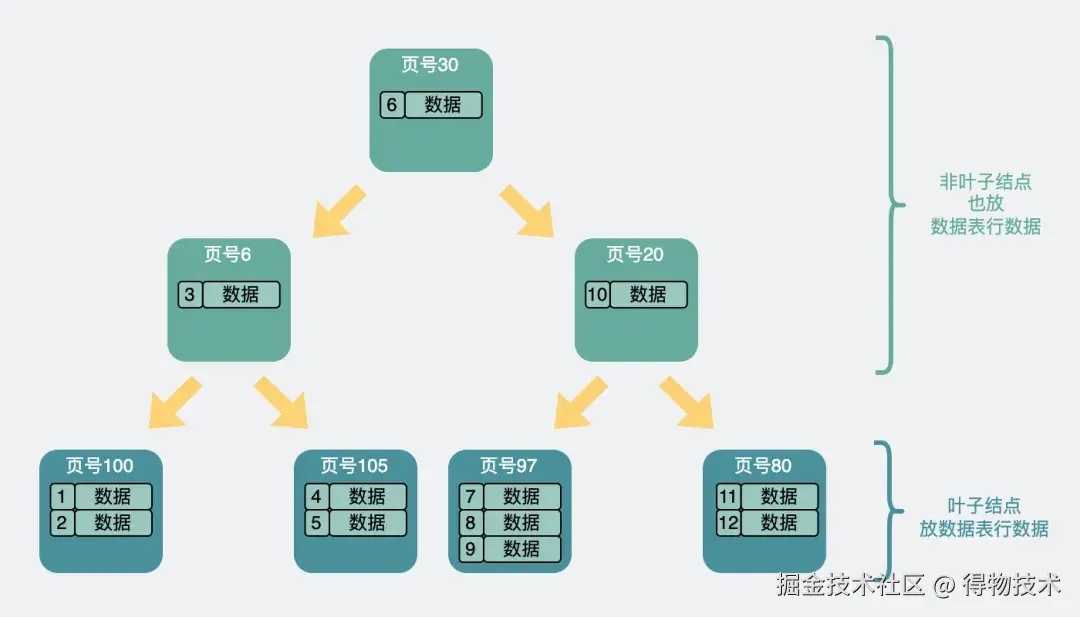
B树将行数据都存在非叶子节点上,假设每个数据页还是16kb,掐头去尾每页剩15kb,并且一条数据表行数据还是占1kb,就算不考虑各种页指针的情况下,也只能放个15条数据。数据页扇出明显变少了。
计算可承载的总行数的公式也变成了一个等比数列。
15 + 15^2 +15^3 + ... + 15^z
其中z还是层数的意思。
为了能放2kw左右的数据,需要z>=6 。也就是树需要有6层,查一次要访问6个页。假设这6个页并不连续,为了查询其中一条数据,最坏情况需要进行6次磁盘IO。
而B+树同样情况下放2kw数据左右,查一次最多是3次磁盘IO。
磁盘IO越多则越慢,这两者在性能上差距略大。
为此,B+树比B树更适合成为MySQL的索引。
五、总结:生死博弈的核心
B+树叶子和非叶子结点的数据页都是16k,且数据结构一致,区别在于叶子节点放的是真实的行数据,而非叶子结点放的是主键和下一个页的地址。
B+树一般有两到三层,由于其高扇出,三层就能支持2kw以上的数据,且一次查询最多1~3次磁盘IO,性能也还行。
存储同样量级的数据,B树比B+树层级更高,因此磁盘IO也更多,所以B+树更适合成为MySQL索引。
索引结构不会影响单表最大行数,2kw也只是推荐值,超过了这个值可能会导致B+树层级更高,影响查询性能。
单表最大值还受主键大小和磁盘大小限制。
16KB页与B+树的平衡 :页大小限制了单页行数和指针数,B+树通过多阶平衡确保低树高。
2000万不是绝对 :若行小于1KB(如只存ID),上限可到5000万+;若行较大(如含大字段),可能500万就性能下降。
优化建议:
- 控制单行大小(避免TEXT/BLOB直接入表)。
- 分库分表:单表接近千万级时提前规划。
- 冷热分离:历史数据归档。
本质:通过页大小和B+树结构,MySQL在磁盘I/O和内存效率之间取得平衡。超出平衡点时,性能从"平缓下降"变为"断崖下跌"。
六、拓展问题
为啥设计单页大小16k?
MySQL索引采用的是B+树数据结构,每个叶子节点(叶子块)存储一个索引条目的信息。而MySQL使用的是页式存储(Paged storage)技术,将磁盘上的数据划分为一个个固定大小的页面,每个页面包含若干个索引条目。
为了提高索引查询效率和降低磁盘I/O的频率,MySQL设置了16KB的单页大小。这是因为在MySQL中:
- 内存大小限制:MySQL的索引需要放在内存中进行查询,如果页面过大,将导致索引无法完全加载到内存中,从而影响查询效率。
- 磁盘I/O限制: 当需要查询一个索引时,MySQL需要把相关的页面加载到内存中进行处理,如果页面过大,将增加磁盘I/O的开销,降低查询效率。
- 索引效率限制:在B+树数据结构中,每个叶子节点存储着一个索引条目,因此如果每个页面能够存放更多索引条目,就可以减少B+树结构的深度,从而提高索引查询效率。
综上所述,MySQL索引单页大小设置为16KB可以兼顾内存大小、磁盘I/O和索引查询效率等多方面因素,是一种比较优化的方案。需要注意的是,对于某些特殊的应用场景,可能需要根据实际情况对单页大小进行调整。
字符串怎么做索引?
在MySQL中,可以通过B+树索引结构对字符串类型的列进行排序。具体来说,当使用B+树索引进行排序时,MySQL会根据字符串的字典序(Lexicographic Order)进行排序。
字典序是指将字符串中的每个字符依次比较,直到找到不同的字符为止。如果两个字符串在相同的位置上具有不同的字符,则以这两个字符的ASCII码值比较大小,并按照升序或降序排列。例如,字符串"abc"和"def"比较大小时,先比较'a'和'd'的ASCII码,因为'd'的ASCII码大于'a',所以"def"大于"abc"。
需要注意的是,如果对长字符串进行排序,可能会影响索引查询的性能,因此可以考虑使用前缀索引或全文索引来优化。同时,在实际开发中,还需要注意选择适当的字符集和排序规则,以确保排序结果正确和稳定。
中文字符串怎么做索引?
中文字符串排序在MySQL中可以使用多种方式,最常见的有以下两种:
- 按拼音排序:对于中文字符串,可以按照拼音进行排序。可以使用拼音排序插件,如pinyin或zhuyin插件,来实现中文字符串按照拼音进行排序。这些插件会将中文字符串转换为拼音或注音后,再进行排序。
例如,先安装pinyin插件:
arduino
INSTALL PLUGIN pinyin SONAME 'ha_pinyin.so';然后创建对应的索引并按拼音排序:
sql
CREATE INDEX idx_name_pinyin ON mytable(name) USING BTREE WITH PARSER pinyin;
SELECT * FROM mytable ORDER BY name COLLATE pinyin;- 按Unicode码点排序:可以使用UTF-8字符集,并选择utf8mb4_unicode_ci排序规则,在使用此排序规则时,MySQL会按照Unicode码点进行排序,适合于较为通用的中文字符串排序需求。
例如:
sql
CREATE INDEX idx_name_unicode ON mytable(name) USING BTREE;
SELECT * FROM mytable ORDER BY name COLLATE utf8mb4_unicode_ci;需要注意的是,不同的排序方式可能会对性能产生影响,因此需要根据具体需求选择合适的排序方式,并进行必要的测试和验证。同时,在进行中文字符串排序时,还需要考虑到中文字符的复杂性,例如同音字、繁简体等问题,以确保排序结果正确和稳定。
索引字段的长度有限制吗?
在MySQL中,索引的长度通常是由三个因素决定的:数据类型、字符集和存储引擎。不同的数据类型、字符集和存储引擎所支持的最大索引长度也有所不同。
一般情况下,索引的长度不应该超过存储引擎所支持的最大索引长度。在InnoDB存储引擎中,单个索引所能包含的最大字节数为767个字节(前缀索引除外)。如果索引的长度超过了最大长度,则会导致创建索引失败。因此,在设计表结构时,需要根据索引列的数据类型和字符集等因素,合理设置索引长度,以充分利用索引的优势。
对于字符串类型的索引,还需要注意以下几点:
- 对于UTF-8字符集,每个字符占用1-4个字节,因此索引长度需要根据实际情况进行计算。例如,一个VARCHAR(255)类型的列在utf8mb4字符集下的最大长度为255*4=1020个字节。
- 可以使用前缀索引来减少索引的大小,提高索引查询效率。在创建前缀索引时需要指定前缀长度。例如,可以在创建索引时使用name(10)来指定name列的前10个字符作为索引。
- 在使用全文索引对字符串进行搜索时,MySQL会将文本内容分割成单个词汇后建立倒排索引。在建立索引时需要考虑到中英文分词的问题,以确保全文索引的准确性和查询效率。
综上所述,索引的长度需要根据数据类型、字符集和存储引擎等多个因素进行综合考虑,并合理设置索引长度,以提高索引查询效率和利用率。
往期回顾
-
0基础带你精通Java对象序列化--以Hessian为例|得物技术
-
前端日志回捞系统的性能优化实践|得物技术
-
得物灵犀搜索推荐词分发平台演进3.0
-
R8疑难杂症分析实战:外联优化设计缺陷引起的崩溃|得物技术
-
可扩展系统设计的黄金法则与Go语言实践|得物技术
文 / 太空
关注得物技术,每周更新技术干货
要是觉得文章对你有帮助的话,欢迎评论转发点赞~
未经得物技术许可严禁转载,否则依法追究法律责任。