9 月 1 日,美团正式发布并开源 LongCat-Flash-Chat,它采用了创新性混合专家模型(Mixture-of-Experts, MoE)架构,实现了计算效率与性能的双重优化。
SGLang 团队是业界专注于大模型推理系统优化的技术团队,提供并维护大模型推理的开源框架 SGLang。近期,美团 M17 团队与 SGLang 团队一起合作,共同实现了 LongCat-Flash 模型在 SGLang 上的优化,并产出了一篇技术博客《LongCat-Flash: Deploying Meituan's Agentic Model with SGLang》,文章发表后,得到了很多技术同学的认可,因此我们将原文翻译出来,并添加了一些背景知识,希望更多同学能够从 LongCat-Flash 的系统优化中获益。
1. 引言:美团开源 LongCat-Flash 智能体模型
LongCat-Flash------美团 LongCat 团队开源的创新性混合专家模型(Mixture-of-Experts, MoE)现已在 Hugging Face 平台开源,我们总结了 LongCat-Flash 的一些特性:
- 总参数量达 5600 亿
- 每 Token 激活参数 186 亿-313 亿(平均 270 亿)
- 512 个前馈网络专家 + 256 个零计算专家
- 采用 Shortcut-Connected MoE(ScMoE)实现计算-通信重叠
- 集成多头潜在注意力机制(MLA)
基于多项基准测试,作为非思考型基础模型,LongCat-Flash 仅通过少量参数激活即可达到与主流领先模型相当的性能表现,在智能体任务方面尤为突出。此外,得益于以推理效率为导向的设计理念和架构创新,LongCat-Flash 展现出显著更快的推理速度,使其更适用于复杂且耗时的智能体应用场景。
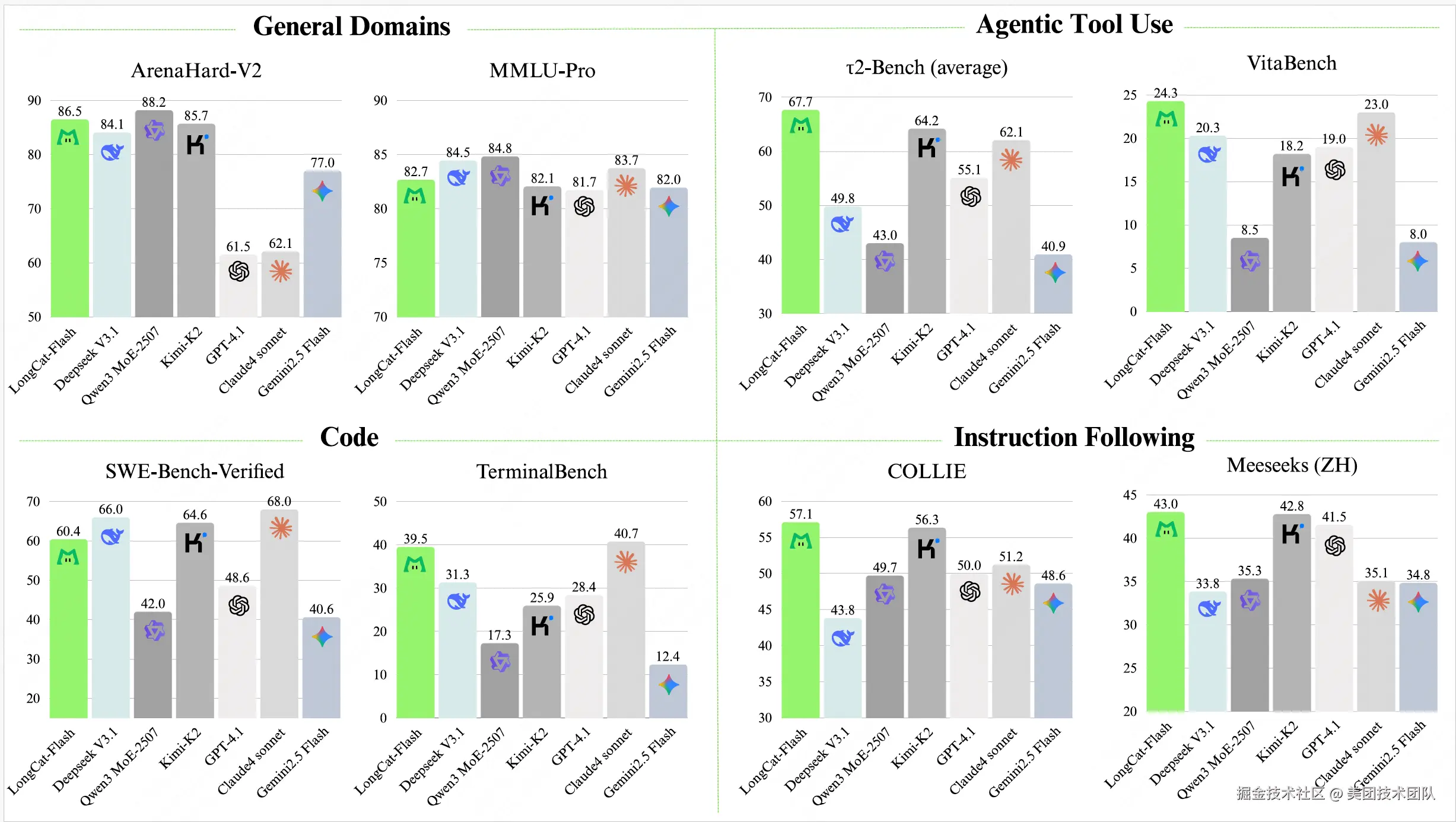
更多内容可以参考我们的技术报告:《LongCat-Flash Technical Report》
2. 为什么模型-系统协同设计很关键?
LongCat-Flash 在面向吞吐和延时的模型-系统的协同设计(Model-System Co-design)方面做了大量工作。这主要是因为我们更多希望 LongCat-Flash 能成为 Agent 场景下可以大规模使用的一个模型。正如我们在技术报告里面所讲,基于 ReACT 模式的智能体系统由于其多轮对话特性,对预填充(Prefill)和解码(Decode)速度都提出了极高的要求,更快的响应速度,给用户端到端的体验会更加明显。为了解决 Prefill 和 Decode 的问题,我们分别设计了零专家机制和 Shortcut-connected MoE 结构来减少计算量和实现结构上的计算-通信重叠。
- Prefill:传统大模型推理的预填充(Prefill)环节,主要受计算量和通信量影响,而具体到 MoE 模型的时候,通信量主要受平均选择的专家数量影响。在 LongCat-Flash 的设计中,我们发现并非每个 Token 都需要同等规模的激活参数。基于这一观察,我们设计了零专家机制(Zero Computation Experts),采用动态激活机制,针对一些不重要的 Token,采用更少的激活来完成计算,由此将每 Token 激活参数量控制在 186 亿至 313 亿之间(平均 270 亿,激活 8 个 experts),这对于降低预填充计算量至关重要。
- Decode:对于解码(Decode)阶段,MoE 模型的高稀疏性(experts 总数和 per token 激活 experts 数的比值)需要更大的 batch 来提升 GEMM(矩阵乘法)的计算密度。比如,按照 Roofline 模型,H800 上的稠密(Dense)矩阵乘法运算,要达到计算约束(compute bound)区间,需要输入规模达到 500 以上。但是如果是类似于 DeepSeekV3 这样的 MoE 模型(256 个 expert,每个 token 激活 8 个 expert),则需要输入规模达到 500*256/8 = 16000。由于 KV cache 的显存开销与输入规模成正比,所以为了提高输入的规模,部署上往往采用更大的并发度(也就是大规模专家并行部署),将参数分散到更多的 GPU 卡上,释放出来更多的显存给 KV Cache 存储。但大规模部署时的多机通信会成为新的瓶颈。由此,计算/通信重叠成为提升推理性能的关键。DeepSeekV3/SGLang 提出的 TBO(Two Batch Overlap,双批次重叠)通过不同 Batch 间的通信和计算做重叠降低了延迟,但在小批量或单请求场景下会失效。吞吐(大 Batch)和延迟(小 Batch)本质上是冲突的目标,在线业务往往需要在二者间做折衷。LongCat-Flash 为了解决这一冲突,采用 ScMoE 架构来实现吞吐与延迟的双重优化。基于这套架构,我们可以采用 SBO(Single Batch Overlap),在小批量请求或者单请求场景依然能够取得延时收益。此外,ScMoE 的另一优势在于:Dense 分支的 FFN 上的节点内张量并行通信(通过 NVLink)可完全与节点间专家并行通信(通过 RDMA)重叠,实现 intra-node 通信和 inter-node 通信的 overlap,从而最大化网络利用率。
模型-系统的协同设计使得我们可以突破吞吐和延时这一对冲突目标的限制,同时在两个维度上取得显著收益。
3. 我们的解决方案:SGLang + PD 分离 + SBO 调度 + 大规模 EP 部署
3.1 PD 分离
为实现预填充(Prefilling)与解码(Decoding)阶段的独立优化,我们采用了 PD 分离(PD-Disaggregated)架构。基于 SGLang 的 PD 分离方案,我们开发了自己的创新解决方案,其核心特性是分层传输(Layer-wise Transmission),该设计在高 QPS 负载场景下显著降低了首包时间(TTFT)。
3.2 SBO
SBO(Single Batch Overlap)是一种采用模块级重叠(Module-Level)的四阶段流水线执行架构,旨在充分释放 LongCat-Flash 的性能潜力。与 TBO 不同的是,SBO 通过将通信开销隐藏于单个批次内实现优化:
- 阶段 1:独立执行,因为多头潜在注意力(MLA)的输出是后续阶段的输入基础。
- 阶段 2:all-to-all 分发与密集 FFN 和 Attn 0(QKV 投影)并行执行。这种重叠至关重要,由于通信开销过大,我们专门将注意力计算过程进行了拆分。
- 阶段 3:独立执行 MoE GEMM。该阶段延迟将受益于宽专家并行(EP)的部署策略。
- 阶段 4:Attn 1(核心注意力+输出投影)和密集 FFN 与 all-to-all 合并操作重叠执行。
这种设计有效缓解了通信瓶颈:① 所有重叠操作在单批次内完成,实现吞吐量提升与延迟降低的双重收益;② 通过计算/通信流水化,确保 LongCat-Flash 的高效推理。其核心价值在于突破传统方案中吞吐量与延迟不可兼得的困境,特别适合实时性要求高的智能体应用场景。
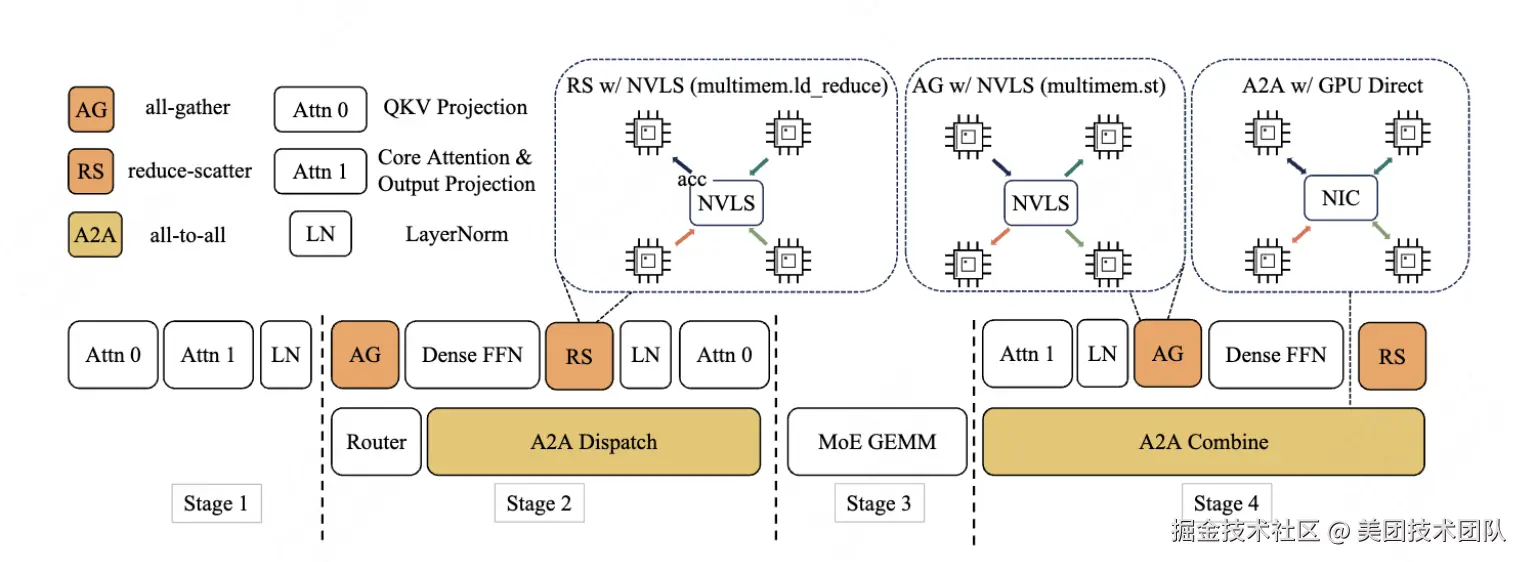
3.3 大规模专家并行部署
为什么要做大规模专家并行部署?一是因为前文所述,需要释放更多显存来给 KV cache 存储;二是因为增大 EP 并发数,可以降低 MoE 环节的计算耗时。
-
降低 KV Cache:LongCat-Flash 采用了 MLA 结构来压缩 KV Cache,单 Token 的 KV Cache 大小是:(512+64)*2*28*2 = 64.5KB。假设输入的长度是 5K,则平均每条请求的 KV Cache 大小是:64.5KB * 5000 = 323MB,MoE 部分的参数大小是:541GB(FP8 存储)。如果 H800-80GB 做 EP16 部署,则单卡的 MoE 参数是:33.8GB,参数占了单卡存储的 42.2%,考虑到 CudaGraph 的显存开销、通信的 buffer 开销、Dense 分支的参数开销,留给 KV Cache 的空间就不大,batch 就没法打高。如果做 EP128 部署,则单卡的 MoE 参数是:541/128 = 4.2GB,只占单卡显存的 5.3%,更多的空间可以释放给 KV cache。也可以看出来,在 EP128 基础上,进一步增加 EP 数,显存方面的收益已经不显著了。
-
降低 MoE 环节的计算耗时:如技术报告和图 2 所指出,在 SBO 中,单个 layer 的计算耗时由四个环节组成:attention 计算 + all-to-all dispatch 通信 + MoE 计算 + all-to-all combine 通信。其中 attention 计算和 all-to-all dispatch/combine 通信都无法通过增加分布式节点来降低,只有 MoE 计算可以。所以,在达到 MoE 计算的算力瓶颈之前,扩大 EP 规模会减少 MoE 计算时间。
大规模专家并行部署,结合 SBO 调度,LongCat-Flash 在 EP128 的时候可以达到10ms 的 TPOT,同时单卡800 tokens/s 的吞吐。此外,与 SGLang 的实现类似,我们采用 DeepEP 实现大规模专家的分布式通信,也在 DeepEP 基础上实现了零专家无需通信的本地计算机制,显著降低了通信开销。
3.4 其他优化
-
多步重叠调度器:为提升 GPU 利用率,SGLang 采用单步重叠式调度器,将 CPU 的调度开销隐藏在模型 Decode 的 GPU kernel 耗时中。然而,LongCat-Flash 前向传播的耗时比较低,导致 GPU kernel 的耗时无法掩盖 CPU 的调度开销,为此我们实现多步重叠调度器,在单次调度迭代中启动多个前向传播 kernel,通过将 CPU 调度与同步操作隐藏于 GPU 计算过程,确保 GPU 一直处于 busy 状态。
-
投机推理 :在投机推理的优化上,借鉴 MagicDec [1],我们首先对投机推理的收益进行的理论分析,其理论收益: TTTavgSD=Ω(γ,α)1(TTγ⋅TD+TTTv(γ))。 TavgSD 表示在投机推理情况下的平均 decode 耗时, TT 表示 Target model 的耗时。其他各项含义参考下文的说明。针对这个公式,我们拆解成三部分分别优化:
- Ω(γ,α):表示在步长 γ 的情况下,接收率为 α 时的平均接收长度。为了提高这个数据,我们采用了 MTP 作为投机推理的草稿模型。
- TTγ⋅TD: TD 表示草稿模型的执行耗时, TT 表示 Target model 的执行耗时,这个比值越低越好。因此,我们采用了单个 Dense 层而非 MoE 作为 MTP 的结构,在保证接收率基本持平的情况下,大幅降低草稿模型的前向耗时( TD)。而轻量级的草稿模型又会导致 Verify Kernel 与 Draft forward Kernel 的调度引入了显著开销。为此,我们采用 TVD 融合策略,将目标前向传播(Target model forward)、验证(Verify kernel)和草稿前向传播(Draft model forward)融合为单个 CUDA Graph。
- TTTv(γ): Tv(γ) 是验证(Verify) γ 个 Token 时,一次 forward 的耗时。当 γ 较长时,为了降低这个耗时,我们引入了 C2T [2] 的机制,在验证前提前过滤一些明显不会被接收的 Token,减少 Verify 的开销。
4. 性能表现
基于以上优化,LongCat-Flash 可以取得比同尺寸模型、甚至更小尺寸模型都显著优异的性能表现,以公版 H800 每小时 14 元人民币(2 美元)计算,在输出速度达到 100 tokens/s(TPOT = 10ms)的 SLO 下,输出成本价仅为每百万 Token 5 元。
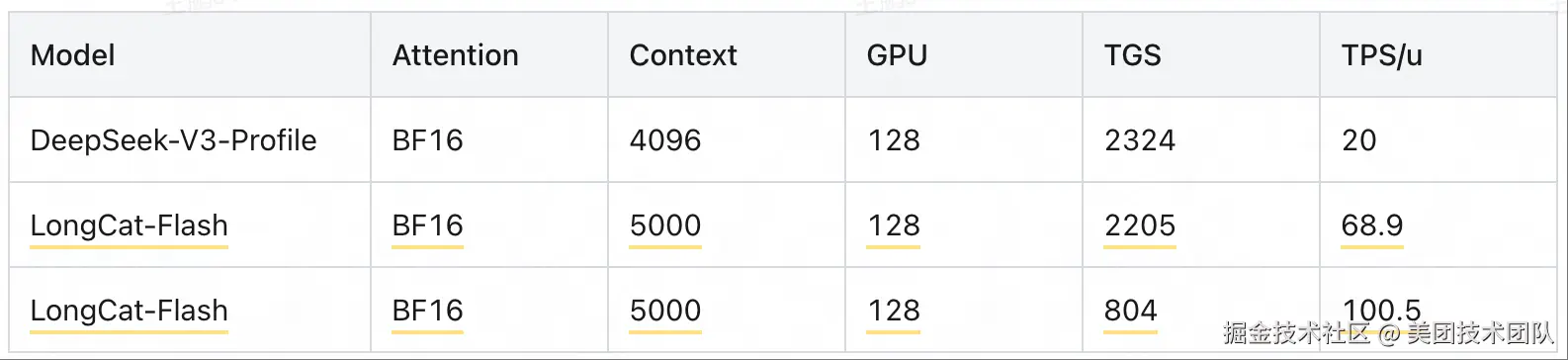
备注:不同的 SLO 有不同的成本。比如 68.9 tok/s 的生成速度,对应的吞吐是 2205 token/g/s;100.5 tok/s 的生成速度,对应的吞吐是 804 token/g/s。
5. 使用 SGLang 部署的方法
我们推荐使用 SGLang 部署 LongCat-Flash。通过与 SGLang 社区的深度协作,该模型在 SGLang 框架上实现首发即兼容。由于其 5600 亿参数(560B)的规模,LongCat-Flash 在 FP8 格式下需要至少单节点 8xH20-141G GPU 来加载模型权重,BF16 权重则需要至少双节点 16xH800-80G GPU。具体启动配置如下所示。
安装 SGLang
css
pip install --upgrade pip
pip install uv
uv pip install "sglang[all]>=0.5.1.post3"单机部署(8xH20-141G)
该模型可通过张量并行(Tensor Parallelism)与专家并行(Expert Parallelism)的组合方案在单节点上部署。
css
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat-FP8 \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 8多机部署(16xH800-80G)
在多节点部署方案中,当前采用张量并行(Tensor Parallelism)与专家并行(Expert Parallelism)的组合架构,未来将扩展其他并行策略。请将$NODE_RANK和$MASTER_IP替换为实际集群环境对应的配置值。
css
python3 -m sglang.launch_server \
--model meituan-longcat/LongCat-Flash-Chat \
--trust-remote-code \
--attention-backend flashinfer \
--enable-ep-moe \
--tp 16 \
--nnodes 2 \
--node-rank $NODE_RANK \
--dist-init-addr $MASTER_IP:5000使用 MTP 的方法
要启用 SGLang 的多令牌预测(MTP)功能,需在启动命令中添加以下参数
css
--speculative-draft-model-path meituan-longcat/LongCat-Flash-Chat \
--speculative-algorithm NEXTN \
--speculative-num-draft-tokens 2 \
--speculative-num-steps 1 \
--speculative-eagle-topk 16. 总结
通过结合 SGLang、PD 分离架构、大规模专家并行(EP)和 SBO 等关键技术,我们实现了 LongCat-Flash 的超低成本与极速生成能力。该模型的高效推理还得益于 SGLang 团队、MoonCake 团队、NVIDIA trt-llm 及其他开源社区的技术贡献。未来我们将与 SGLang 团队深度合作,逐步将基于 SGLang 的优化方案回馈至开源社区,共同推动生态发展。
注释
1 MagicDec:Sadhukhan, Ranajoy, et al. "Magicdec: Breaking the latency-throughput tradeoff for long context generation with speculative decoding." arXiv preprint arXiv: 2408.11049 (2024).
2 C2T:Huo, Feiye, et al. "C2T: A Classifier-Based Tree Construction Method in Speculative Decoding." arXiv preprint arXiv: 2502.13652 (2025).
阅读更多
| 关注「美团技术团队」微信公众号,在公众号菜单栏对话框回复【2024年货】、【2023年货】、【2022年货】、【2021年货】、【2020年货】、【2019年货】、【2018年货】、【2017年货】等关键词,可查看美团技术团队历年技术文章合集。

| 本文系美团技术团队出品,著作权归属美团。欢迎出于分享和交流等非商业目的转载或使用本文内容,敬请注明"内容转载自美团技术团队"。本文未经许可,不得进行商业性转载或者使用。任何商用行为,请发送邮件至 tech@meituan.com 申请授权。