点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年09月15日更新到: Java-124 深入浅出 MySQL Seata框架详解:分布式事务的四种模式与核心架构 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
章节内容
上节我们完成了如下的内容:
- Spark Streaming 基础概述
- Spark Streaming 架构概念
- 编程模型
- 优点缺点概括
- 与 Kafka 集成

基础概念
Spark Streaming 支持多种基础数据源,这些数据源可以满足不同场景下的实时数据处理需求。以下是各类数据源的详细介绍:
-
文件系统(File System)
- 支持的文件系统类型:
- HDFS(Hadoop Distributed File System)
- S3(Amazon Simple Storage Service)
- 本地文件系统(Local File System)
- 工作方式:
- 持续监控指定目录中的新文件
- 当检测到新文件时,自动读取并处理
- 支持的文件格式包括文本、JSON、CSV等
- 典型应用场景:
- 批量日志文件处理
- 周期性生成的报表文件分析
- 需要与现有文件处理流程集成的场景
- 支持的文件系统类型:
-
Socket 数据流(Socket Stream)
-
实现机制:
- 通过TCP套接字建立连接
- 监听指定端口接收文本数据
-
使用方法示例:
bash# 使用Netcat发送数据 nc -lk 9999 -
特点:
- 简单易用,适合快速原型开发
- 缺乏可靠性保证,不适合生产环境
-
应用场景:
- 开发测试环境
- 简单的实时数据展示
-
-
Kafka集成
- 两种集成方式:
- 基于Receiver的方式:
- 使用Kafka高级消费者API
- 通过WAL(Write Ahead Log)保证数据可靠性
- 直接方式(Direct):
- 使用Kafka简单消费者API
- 定期查询Kafka中的最新偏移量
- 提供精确一次语义(exactly-once)处理保证
- 基于Receiver的方式:
- 最新版本推荐使用Spark-Kafka direct API
- 典型应用:
- 实时点击流分析
- 实时推荐系统
- 复杂事件处理
- 两种集成方式:
-
Flume集成
-
两种集成方式:
- Push模式:Flume将数据推送到Spark Streaming
- Poll模式:Spark Streaming从Flume拉取数据
-
特点:
- 高可靠性
- 适合日志收集场景
-
配置示例:
properties# Flume配置示例 agent.sinks.spark-sink.type = org.apache.spark.streaming.flume.sink.SparkSink agent.sinks.spark-sink.hostname = localhost agent.sinks.spark-sink.port = 9999
-
-
Kinesis集成
- 关键特性:
- 自动扩展能力
- 高吞吐量
- 低延迟
- 配置参数:
- 流名称
- 端点URL
- 访问密钥
- 检查点间隔
- 适用场景:
- AWS生态系统中的实时分析
- IoT设备数据处理
- 关键特性:
-
自定义数据源
- 实现方式:
- 继承Receiver类:
- 实现onStart()和onStop()方法
- 自定义数据接收逻辑
- 使用Direct DStream API:
- 更细粒度的控制
- 更好的性能
- 继承Receiver类:
- 应用场景:
- 特殊协议的数据源
- 专有系统的集成
- 需要特殊处理逻辑的数据源
- 实现方式:
每种数据源都有其特定的配置参数和调优选项,在实际应用中需要根据具体需求选择合适的集成方式,并进行必要的性能优化。对于生产环境,建议优先考虑Kafka、Kinesis等具备高可靠性和扩展性的数据源。

引入依赖
我们使用的话,需要引入依赖:
xml
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>${spark.version}</version>
</dependency>文件数据流
基础概念
通过 textFileStreama 方法进行读取 HDFS 兼容的文件系统文件 Spark Streaming 将会监控 directory 目录,并不断处理移动进来的文件
- 不支持嵌套目录
- 文件需要有相同的数据格式
- 文件进入 Directory 的方式需要通过移动或者重命名来实现
- 一旦文件移动进目录,则不能再修改,即便修改了也不会读取新数据
- 文件流不需要接收器(Receiver),不需要单独分配CPU核
编写代码
scala
package icu.wzk
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object FileDStream {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf()
.setAppName("FileDStream")
.setMaster("local[*]")
// 时间间隔
val ssc = new StreamingContext(conf, Seconds(5))
// 本地文件,也可以使用 HDFS 文件
val lines = ssc.textFileStream("goodtbl.java")
val words = lines.flatMap(_.split("\\s+"))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
// 打印信息
wordCounts.print()
ssc.start()
ssc.awaitTermination()
}
}代码解析
- object FileDStream: 定义了一个名为 FileDStream 的单例对象,包含 main 方法,这是 Scala 中的入口点,相当于 Java 的 public static void main 方法。
- Logger.getLogger("org").setLevel(Level.ERROR): 这行代码将日志级别设置为 ERROR,以减少控制台输出的日志信息,只显示错误级别的信息。这通常是为了避免不必要的日志干扰核心的输出。
- val conf = new SparkConf(): 创建一个 SparkConf 对象,包含了应用程序的配置信息。
- setAppName("FileDStream"): 设置应用程序的名称为 "FileDStream"。这个名称会在 Spark Web UI 中显示,用于识别应用。
- setMaster("local*"): 设置 Spark 的运行模式为本地模式(local*),这意味着应用程序将在本地运行,并使用所有可用的 CPU 核心。
- val ssc = new StreamingContext(conf, Seconds(5)): 创建一个 StreamingContext 对象,负责管理 Spark Streaming 应用程序的上下文。Seconds(5) 指定了微批处理的时间间隔为 5 秒,也就是每 5 秒钟会处理一次数据。
- val words = lines.flatMap(_.split("\s+")): 对每一行文本内容进行处理,使用空格或其他空白字符(\s+)进行分割,将每行文本拆分成单词。flatMap 操作会将结果展开为一个包含所有单词的 DStream。
- val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _): 通过 map 操作将每个单词映射为 (word, 1) 形式的键值对,然后使用 reduceByKey 按键(即单词)进行聚合,计算每个单词的出现次数。
- wordCounts.print(): 将计算结果打印到控制台,每 5 秒钟输出一次当前批次中每个单词的计数结果。
- ssc.start(): 启动 Spark Streaming 的计算,这会使得 Spark 开始监听数据源并开始处理数据流。
- ssc.awaitTermination(): 阻塞当前线程,等待流计算结束,通常是等待手动停止应用程序。这个方法会让程序保持运行,直到手动终止或遇到异常。
运行结果
【备注:使用 local*,可能会存在问题。】 【如果给虚拟机配置的CPU数为1,使用 local* 也会只启动一个线程,该线程用于 Receiver Task,此时没有资源处理接受到达的数据。】 【现象:程序正常执行,不会打印时间戳,屏幕上也不会有其他有消息信息】
Socket数据流
编写代码
Spark Streaming 可以通过Socket端口监听并接受数据,然后进行相应处理: 打开一个新的命令窗口,启动 nc 程序。(在Flink中也这么用过)
shell
# 如果没有的话 你需要安装一下
nc -lk 9999编写运行的代码:
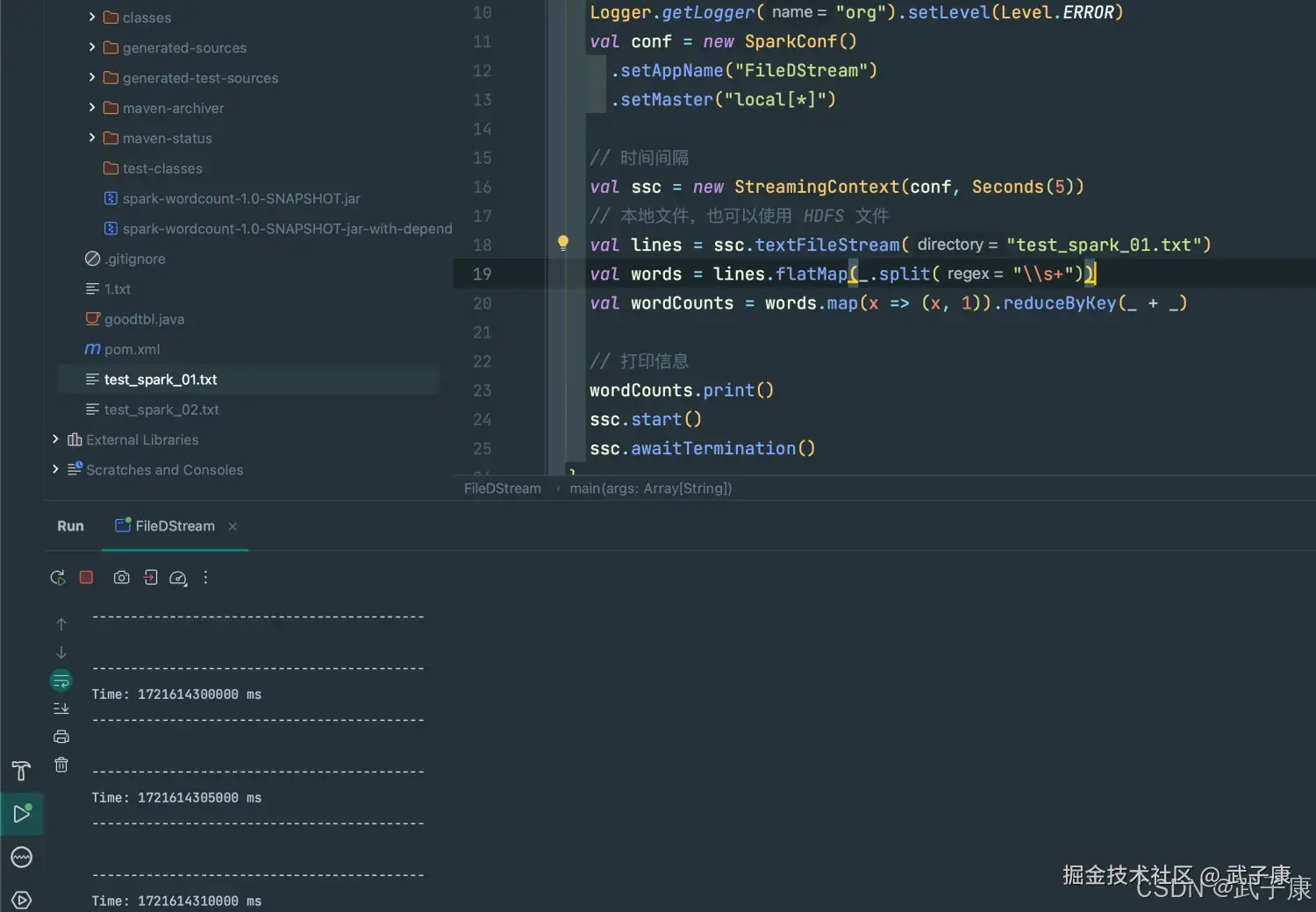
scala
package icu.wzk
import org.apache.log4j.{Level, Logger}
import org.apachea.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
object SocketDStream {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.ERROR)
val conf = new SparkConf()
.setAppName("SocketStream")
.setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(1));
val lines = ssc.socketTextStream("0.0.0.0", 9999)
val words = lines.flatMap(_.split("\\s+"))
val wordCount = words.map(x => (x.trim, 1)).reduceByKey(_ + _)
wordCount.print()
ssc.start()
ssc.awaitTermination()
}
}随后可以在nc窗口中随意输入一些单词,监听窗口会自动获取单词数据流信息,在监听窗口每X秒就会打印出词频的统计信息,可以在屏幕是上出现结果。
运行结果
【备注:使用 local*,可能会存在问题。】 【如果给虚拟机配置的CPU数为1,使用 local* 也会只启动一个线程,该线程用于 Receiver Task,此时没有资源处理接受到达的数据。】 【现象:程序正常执行,不会打印时间戳,屏幕上也不会有其他有消息信息】
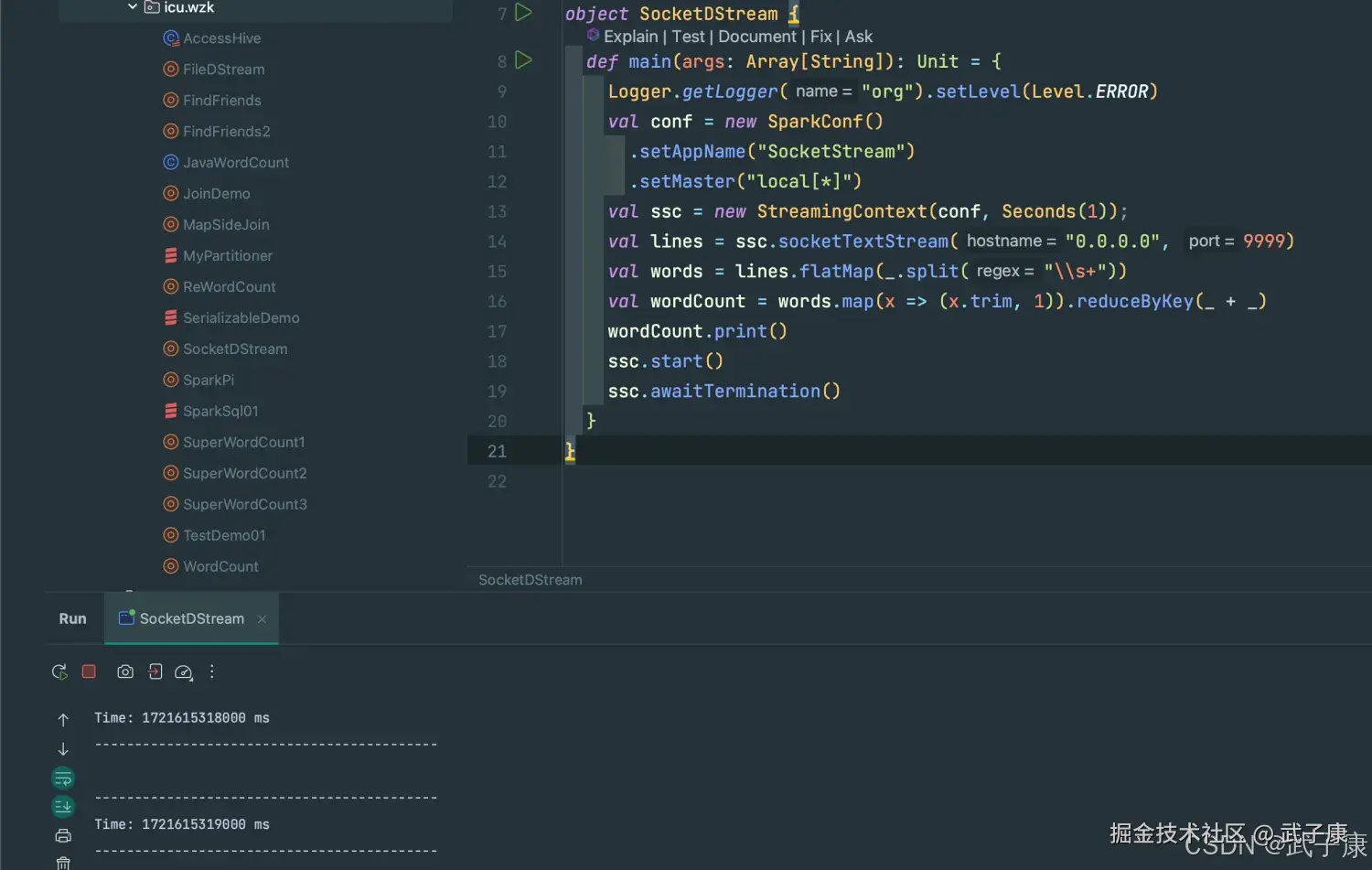 此时,从控制台启动后,输入内容
此时,从控制台启动后,输入内容 
RDD队列流
基础概念
调用 Spark Streaming应用程序的时候,可使用 streamingContext.queueStream(queueOfRDD)创建基于RDD队列的DStream 备注:
- oneAtTime:缺省为true,一次处理一个RDD,设为False,一次处理全部RDD
- RDD队列流可以使用 local1
- 涉及到同时出队和入队操作,所以要做同步
每秒创建一个RDD(RDD存放1-100的整数),Streaming每隔1秒就对数据进行处理,计算RDD中数据除10取余的个数。
队列流优点
- 适用于测试和开发:RDD 队列流主要用于开发和调试阶段,它允许你在没有真实数据源的情况下测试 Spark Streaming 应用程序。
- RDD 队列:你可以创建一个包含 RDD 的队列(Queue),Spark Streaming 会从这个队列中逐一获取 RDD,并将其作为数据流的一部分进行处理。
- 灵活性:由于是手动创建的 RDD 队列,因此你可以完全控制数据的内容、数量以及生成的速度,从而测试各种场景下的应用表现。
编写代码
编写代码如下:
scala
package icu.wzk
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.{Seconds, StreamingContext}
import scala.collection.mutable.Queue
object RDDQueueDStream {
def main(args: Array[String]): Unit = {
Logger.getLogger("org").setLevel(Level.WARN)
val sparkConf = new SparkConf()
.setAppName("RDDQueueStream")
.setMaster("local[*]")
val ssc = new StreamingContext(sparkConf, Seconds(1))
val rddQueue = new Queue[RDD[Int]]()
val queueStream = ssc.queueStream(rddQueue)
val mappedStream = queueStream.map(r => (r % 10, 1))
val reducedStream = mappedStream.reduceByKey(_ + _)
reducedStream.print()
ssc.start()
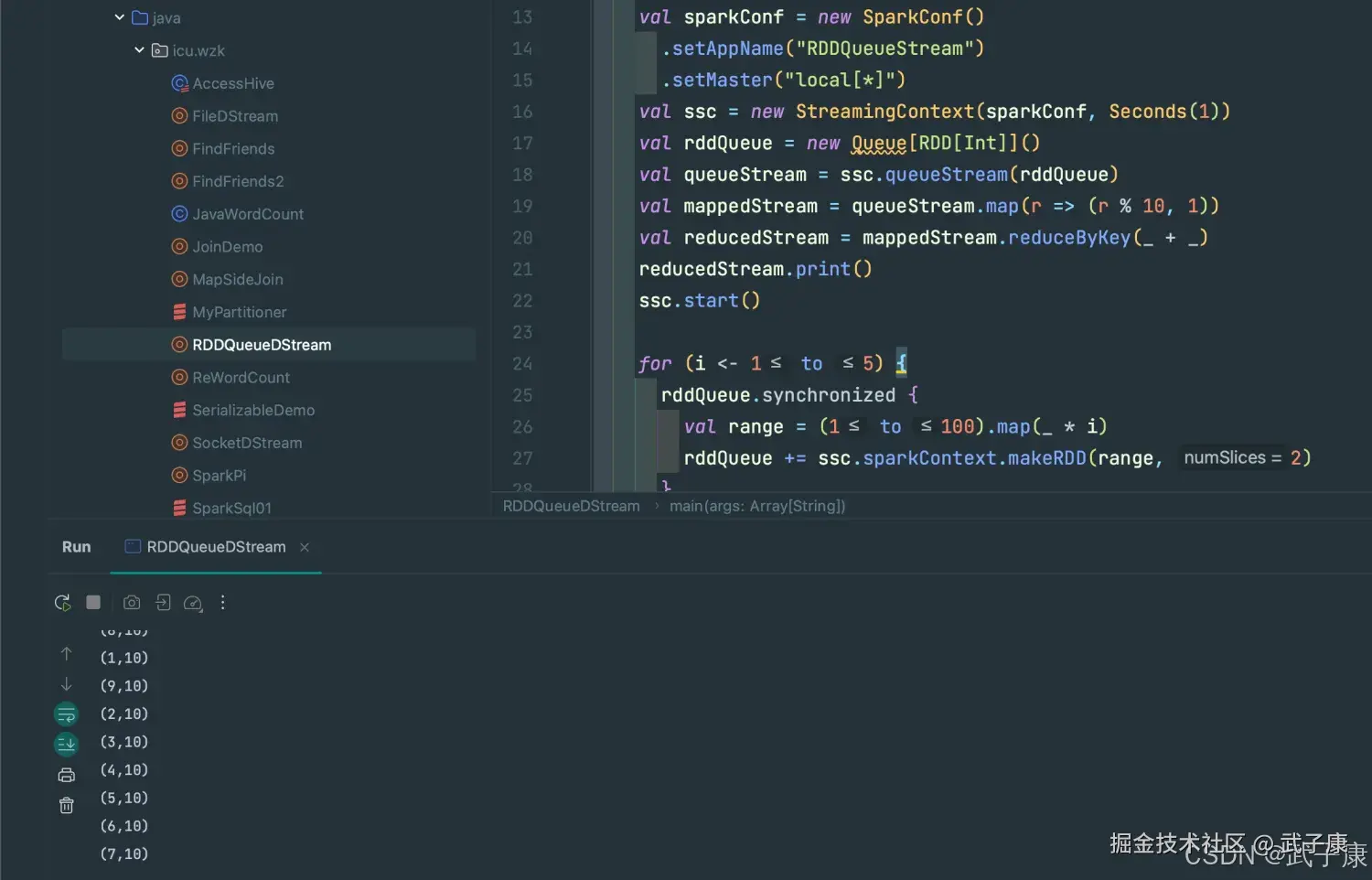
for (i <- 1 to 5) {
rddQueue.synchronized {
val range = (1 to 100).map(_ * i)
rddQueue += ssc.sparkContext.makeRDD(range, 2)
}
Thread.sleep(2000)
}
ssc.stop()
}
}运行结果
运行结果如图所示: