作者:来自 Elastic Carlos_D

使用 ES|QL 的向量搜索
今天我们来介绍 ES|QL 中最令人兴奋的新增功能之一:对 dense vector 字段的原生支持,以及用于搜索它们的函数:KNN 函数和向量相似度函数。如果你对向量搜索感兴趣,但觉得 Query DSL 语法有点吓人,那么 ES|QL 将会成为你新的好朋友。
为什么在向量搜索中使用 ES|QL?
ES|QL 是 Elasticsearch 的未来 ------ 它允许你通过一系列处理步骤来执行查询。将向量搜索加入 ES|QL,可以让你对使用向量进行语义查询的方式拥有更专业的控制能力,通过微调搜索方法(使用 KNN 的近似最近邻搜索,或使用向量相似度函数的精确搜索)。
设置我们的实验环境
让我们创建一个简单的索引,包含一个 dense_vector 字段,用来存储一些产品向量。我们会保持最小化 ------ 只使用 3 个维度 ------ 这样我们可以更容易理解这些向量。
PUT products-vectors
{
"mappings": {
"properties": {
"name": {
"type": "text"
},
"category": {
"type": "keyword"
},
"embedding": {
"type": "dense_vector",
"dims": 3,
"similarity": "cosine"
}
}
}
}这里的关键设置是 similarity: cosine参数(用于衡量向量相似度 ------ 其他选项包括 l2_norm 和 dot_product)。
现在让我们添加一些示例产品及其 "embeddings":
POST products-vectors/_bulk
{"index": {"_id": "1"}}
{"name": "Warm Winter Jacket", "category": "clothing", "embedding": [0.9, 0.1, 0.2]}
{"index": {"_id": "2"}}
{"name": "Summer Beach Shorts", "category": "clothing", "embedding": [0.1, 0.9, 0.3]}
{"index": {"_id": "3"}}
{"name": "Cozy Wool Sweater", "category": "clothing", "embedding": [0.85, 0.15, 0.25]}
{"index": {"_id": "4"}}
{"name": "Running Sneakers", "category": "footwear", "embedding": [0.4, 0.5, 0.8]}
{"index": {"_id": "5"}}
{"name": "Hiking Boots", "category": "footwear", "embedding": [0.6, 0.3, 0.7]}你可以使用 ES|QL 来检索你的数据,包括向量 embeddings:
FROM products-vectors在这个简单示例中,我们假设第一个维度大致表示 "warmth",第二个表示 "summer vibes",第三个表示 "outdoor activity"。像 E5 或 OpenAI 这样的模型生成的真实 embeddings 会有数百个维度,但原理是一样的。
使用 KNN 函数进行搜索
ES|QL 的 KNN 函数可以对向量执行近似的 k-nearest neighbor 搜索:
FROM products-vectors METADATA _score
| WHERE KNN(embedding, [0.88, 0.12, 0.22])
| KEEP name, category, _score
| SORT _score DESC
| LIMIT 3
POST _query?format=txt
{
"query": """
FROM products-vectors METADATA _score
| WHERE KNN(embedding, [0.88, 0.12, 0.22])
| KEEP name, category, _score
| SORT _score DESC
| LIMIT 3
"""
}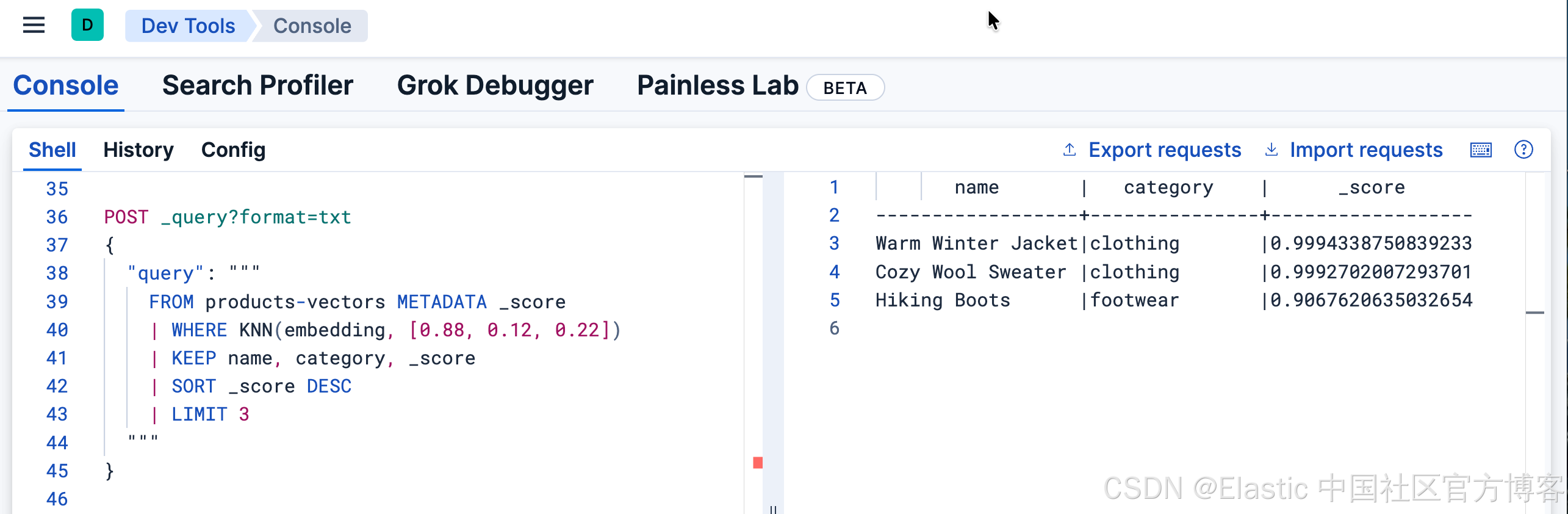
拆解说明:
- METADATA _score ------ 我们需要它来获取来自 KNN 函数的评分
- KNN(embedding, 0.88, 0.12, 0.22) ------ 查找与查询向量最接近的邻居
- 查询向量 0.88, 0.12, 0.22 表示偏 "warm"(第一个维度较高)
结果是?偏暖的服装商品会排到最前面。
| name | category | _score |
|---|---|---|
| Warm Winter Jacket | clothing | 0.9994338750839233 |
| Cozy Wool Sweater | clothing | 0.9992702007293701 |
| Hiking Boots | footwear | 0.9067620635032654 |
结合 KNN 与过滤条件
ES|QL 的一大强项是可以非常自然地将向量搜索与传统过滤条件结合起来:
FROM products-vectors
METADATA _score
| WHERE category == "clothing" AND KNN(embedding, [0.88, 0.12, 0.22])
| KEEP name, _score
| SORT _score DESC
| LIMIT 3
POST _query?format=txt
{
"query": """
FROM products-vectors
METADATA _score
| WHERE category == "clothing" AND KNN(embedding, [0.88, 0.12, 0.22])
| KEEP name, _score
| SORT _score DESC
| LIMIT 3
"""
}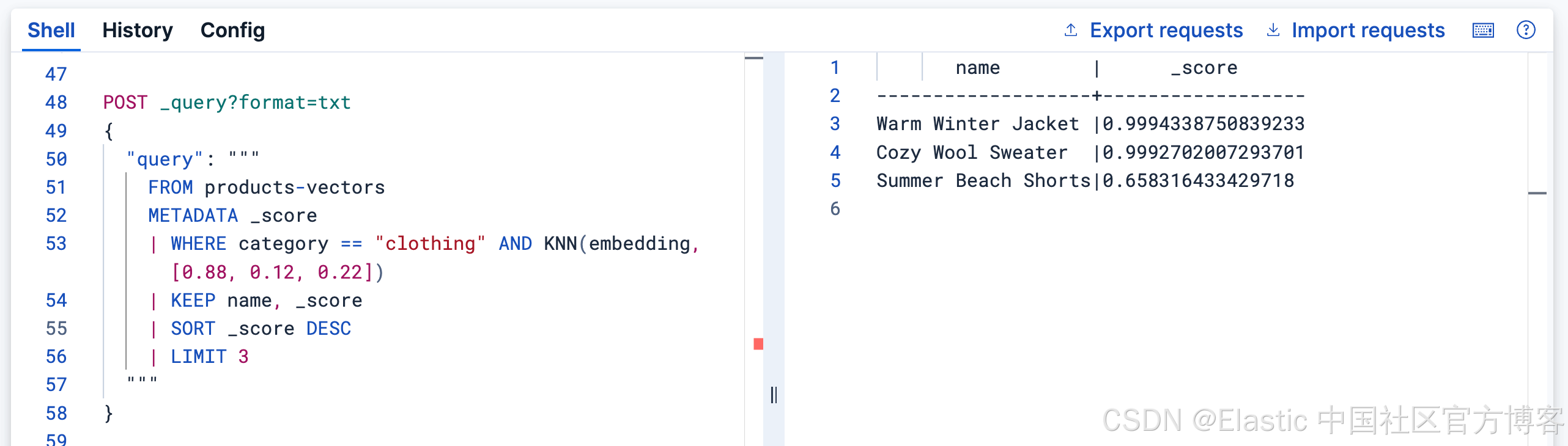
这会在执行 KNN 搜索前先应用过滤条件 ------ 既高效又易读!
| name | category | _score |
|---|---|---|
| Warm Winter Jacket | clothing | 0.9994338750839233 |
| Cozy Wool Sweater | clothing | 0.9992702007293701 |
| Summer Beach Shorts | clothing | 0.658316433429718 |
通过可选参数进行微调
KNN 函数接受额外的命名参数,以便提供更多控制:
FROM products-vectors METADATA _score
| WHERE KNN(embedding, [0.1, 0.85, 0.3], {"boost": 1.5, "min_candidates": 50, "rescore_oversample": 3, "similarity": 0.0001})
| KEEP name, _score
| SORT _score DESC
POST _query?format=txt
{
"query": """
FROM products-vectors METADATA _score
| WHERE KNN(embedding, [0.1, 0.85, 0.3], {"boost": 1.5, "min_candidates": 50, "rescore_oversample": 3, "similarity": 0.0001})
| LIMIT 2
| KEEP name, _score
| SORT _score DESC
"""
}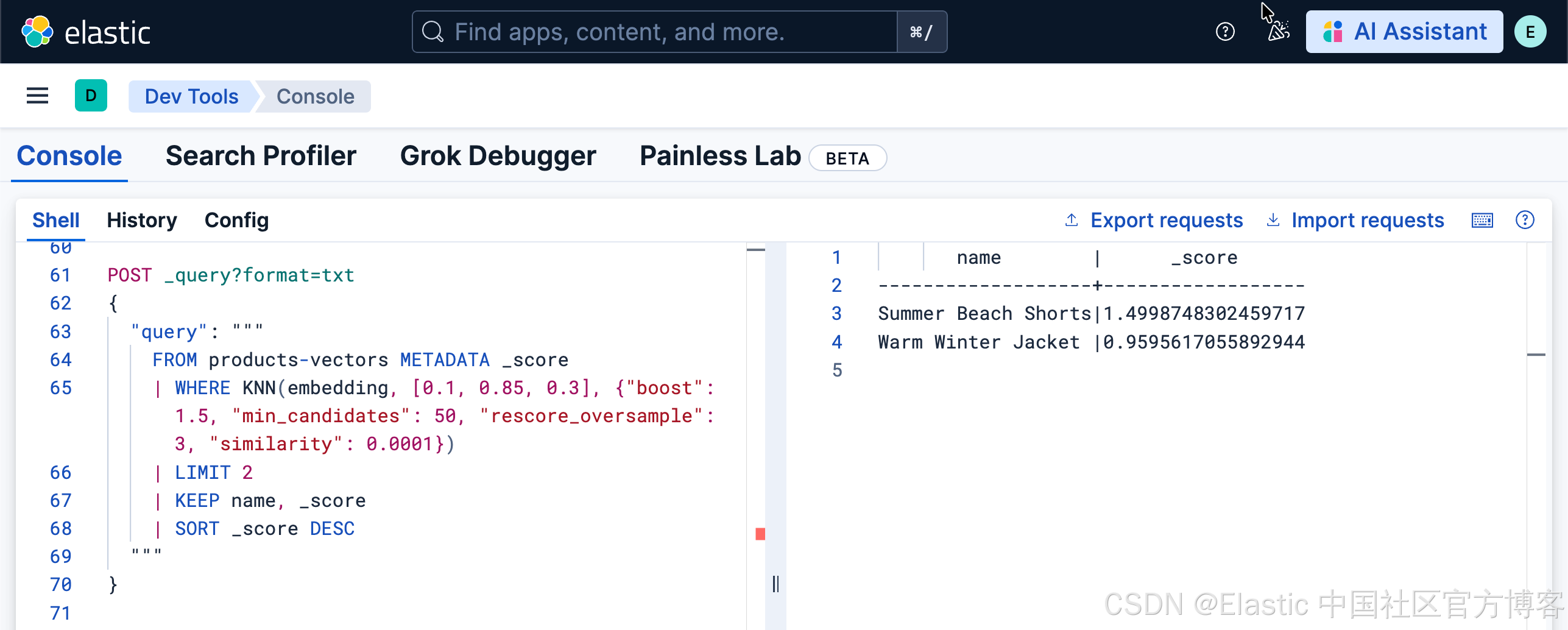
允许的参数有:
- k:返回的邻居数量(可由 LIMIT 隐式指定)
- boost:分数乘数(默认值:1.0)
- min_candidates:每个 shard 要考虑的最小候选数(值越高 = 更准确但更慢)
- similarity:考虑结果的最小相似度
- visit_percentage:在使用 bbq_disk 进行 kNN 搜索时,每个 shard 要探索的向量百分比
- rescore_oversample:在近似 kNN 搜索中,将指定的过采样因子应用于 k
使用向量相似度函数进行搜索
KNN 非常适合大规模向量搜索,其优势之一在于它是近似的 ------ 意味着它会尽力找到足够好的结果,但不会检查每一个可能的结果。这让 KNN 性能很高,因为它无需对所有文档逐一与查询比较。
如果我们真的想检查所有结果(因为我们已经对结果进行了过滤,或者文档数量本身不多),可以使用向量相似度函数来计算查询与每个元素之间的向量相似度:
FROM products-vectors
| EVAL my_score = V_COSINE(embedding, [0.1, 0.85, 0.3]) + 1.0
| KEEP name, my_score
| SORT my_score DESC
POST _query?format=txt
{
"query": """
FROM products-vectors
| EVAL my_score = V_COSINE(embedding, [0.1, 0.85, 0.3]) + 1.0
| KEEP name, my_score
| SORT my_score DESC
"""
}注意 :V_COSINE 在目前的版本 9.2 中还不可见。
向量相似度函数允许你对向量进行自定义评分,并执行精确的最近邻计算。
额外功能:TEXT_EMBEDDING 函数
如果你配置了推理端点,可以实时生成 embeddings:
FROM products-vectors
METADATA _score
| WHERE KNN(embedding, TEXT_EMBEDDING("cozy winter wear", "my-embedding-model"))
| KEEP name, _score
| SORT _score DESC
| LIMIT 3
POST _query?format=txt
{
"query": """
FROM products-vectors
METADATA _score
| WHERE KNN(embedding, TEXT_EMBEDDING("cozy winter wear", "my-embedding-model"))
| KEEP name, _score
| SORT _score DESC
| LIMIT 3
"""
}注意 :TEXT_EMBEDDING 在目前的 9.2 版本中还不可见。
无需预先计算查询向量------ES|QL 会在查询时内联处理!
总结
ES|QL 的向量搜索功能为语义搜索提供了完整控制。现在可以调整如何为查询获取最近邻,或计算自定义分数,这都得益于 ES|QL 对 dense_vector 字段类型的支持、KNN 搜索函数以及向量相似度函数。
无论你是在构建推荐系统、语义搜索引擎,还是只是探索向量数据,KNN、过滤条件和聚合的组合都使 ES|QL 成为一个强大的选择。
原文:https://discuss.elastic.co/t/dec-18th-2025-en-using-es-ql-with-dense-vector-fields/384024