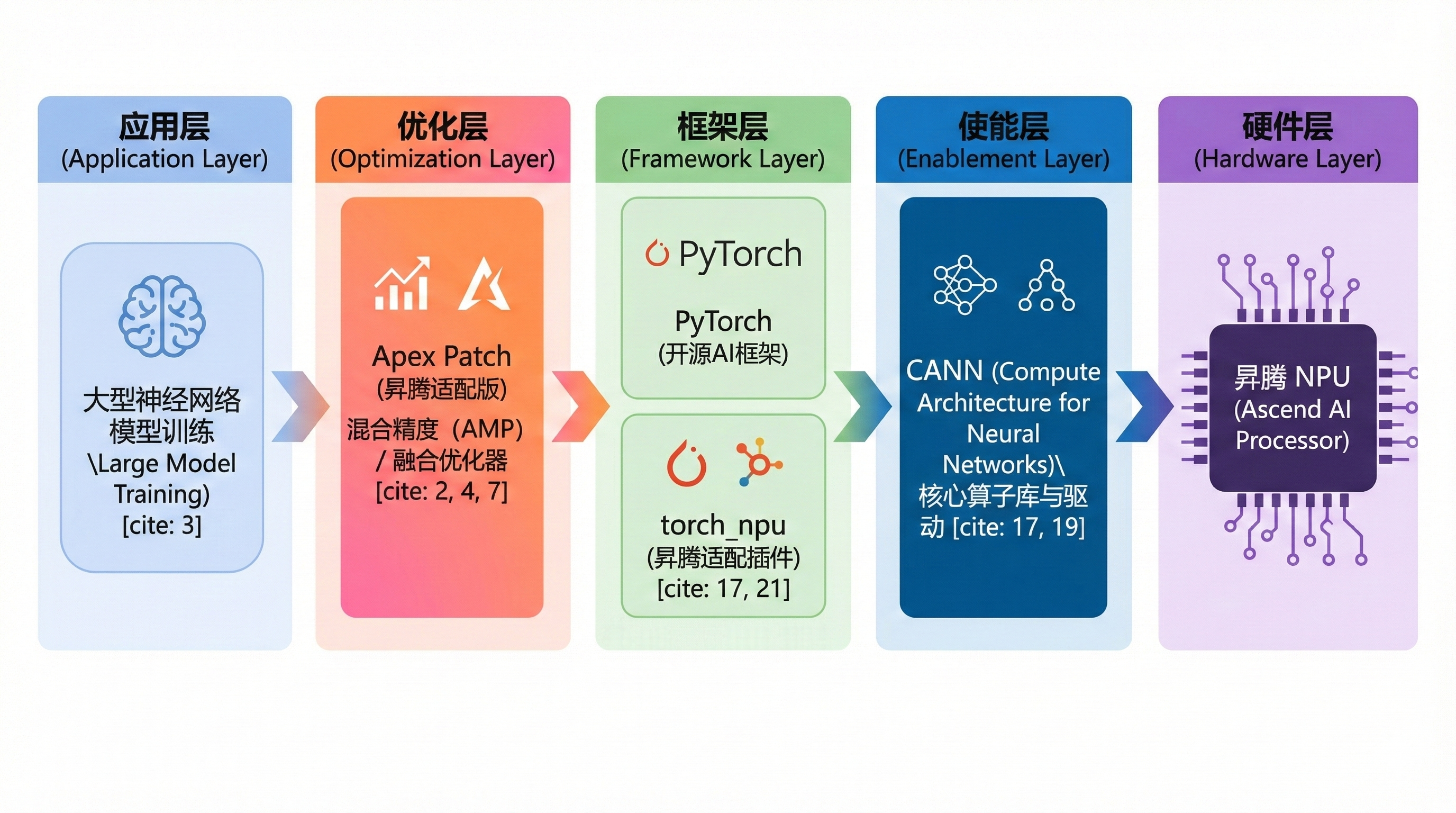
一、为什么需要Apex Patch在昇腾生态中的应用?
现在AI模型越来越大,训练它们需要大量计算资源和时间。从亿级参数到万亿级,训练时间可能从几天拖到几个月,这不光靠硬件,还得靠软件优化。混合精度训练是个常用方法,能加速过程而不太影响精度。NVIDIA的Apex库在这方面做得好,它用自动混合精度(AMP)技术,在计算重的部分用FP16加速矩阵操作,在需要稳定的地方用FP32,这样能把训练速度提高1.5-2倍甚至更多。
但原版Apex是为NVIDIA GPU设计的,没针对华为的昇腾NPU优化。昇腾NPU是华为Atlas AI处理器的核心,专为AI计算设计,并行能力强、功耗低,但要发挥潜力得有专属软件支持。华为的Apex Patch项目改了原始Apex的代码,让它兼容昇腾NPU。这不只是移植,还加了梯度融合 (Gradient Fusion) 和融合优化器等NPU专有技术,通过减少内存访问和合并调用来进一步提速。
代码仓库地址: https://gitcode.com/Ascend/apex
二、获取Apex Patch源码:从仓库克隆开始
安装Apex Patch先得拿到源码。华为把适配版Apex放在gitcode仓库里,这是基于NVIDIA原版的branch,保持了兼容性,还加了昇腾的优化。用Git克隆,能确保你用上最新稳定的版本,避免版本问题。
获取命令如下:
bash
git clone -b master https://gitcode.com/Ascend/apex.git
cd apex/这里,-b master指定克隆主分支,确保获取稳定版本。克隆后,进入apex目录准备后续操作。
Git是版本控制系统的标杆。如果你是Git新手,建议先安装Git(Ubuntu下用sudo apt install git,CentOS用yum install git)。克隆过程中,如果网络不稳定或防火墙问题,可能遇到连接超时。这时,可以尝试使用镜像仓库,或者通过VPN加速访问gitcode.com。
如果遇到SSL证书错误(如自签名证书)这类问题,可以临时关闭Git证书验证:
bash
git config --global http.sslVerify "false"这虽然方便,但从安全角度看,不推荐长期使用。更好的方式是配置正确的CA证书,或者使用企业级代理。扩展到实际场景中,如果你是在云环境(如华为云ModelArts)中操作,记得检查实例的网络设置,确保能访问外部仓库。
为什么用gitcode而非GitHub?因为昇腾生态偏本土,gitcode国内访问快,还有专属优化。开源多样性嘛,原版Apex在GitHub(https://github.com/NVIDIA/apex),昇腾版在gitcode上打了Patch,支持NPU。
三、编译Apex Patch:依赖准备与构建过程
编译是安装Apex Patch的关键。文档强调,在编译前必须安装配套软件栈,包括CANN(Compute Architecture for Neural Networks,华为的AI计算框架)、PyTorch、torch_npu(昇腾PyTorch插件)和Python。这些是昇腾NPU的基础,确保Apex能正常跑。
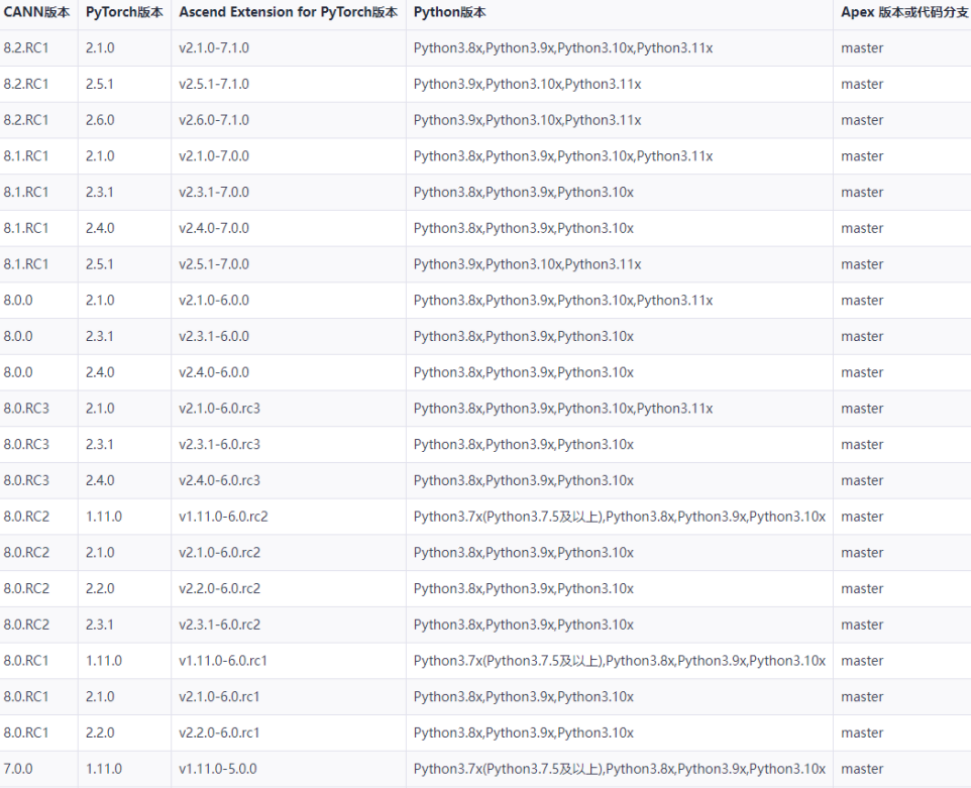
上面的图显示了推荐版本匹配。比如CANN 8.x配PyTorch 2.x和对应torch_npu。安装细节不细说,查华为官方文档(https://support.huaweicloud.com/ascend/)。简单来说:
- 安装CANN:下载Ascend-cann-toolkit包,通过
run脚本安装。 - 安装PyTorch:使用pip安装昇腾版PyTorch(
pip install torch -f https://pytorch.whl)。 - 安装torch_npu:类似,从华为镜像源安装。
准备好后,执行编译命令:
bash
bash scripts/build.sh --python=3.11参数--python=3.11指定Python版本,根据你的环境调整(如3.8或3.9)。这是一个必选参数,确保编译的wheel包与你的Python兼容。
编译过程本质上是构建C++扩展和Python绑定。脚本会自动拉取原始Apex、应用Patch,然后使用setup.py构建。输出在apex/dist目录下,通常是.whl文件,如apex-0.1+ascend-3.11-aarch64.whl。
四、编译过程常见错误及解决方案:一步步排查
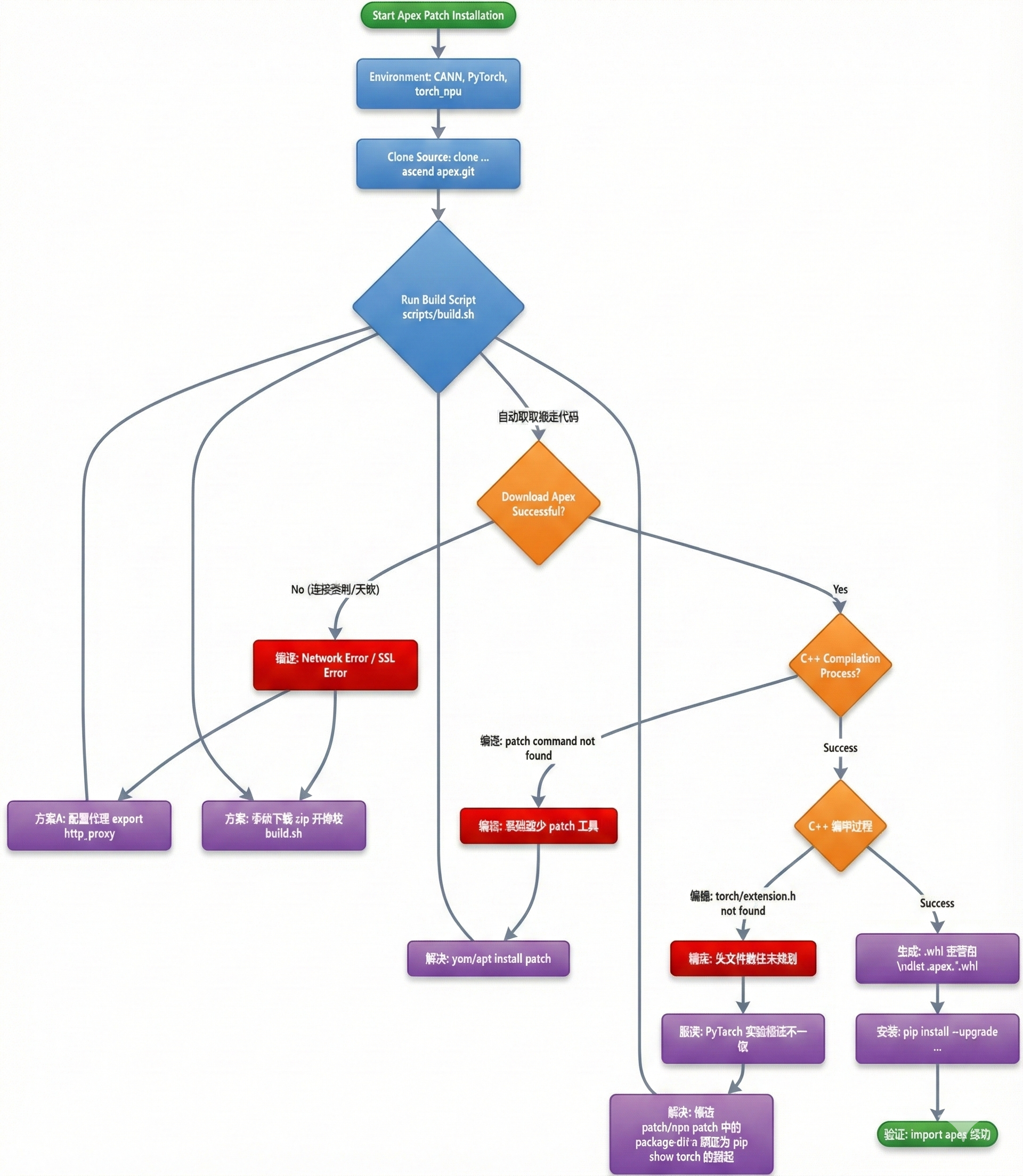
4.1 原始Apex下载失败
(1)问题表现:脚本拉GitHub上的原Apex时卡住或失败。
(2)原因:网络受限,如防火墙或代理问题。
(3)解决方案(二选一):
- 方案一:配置网络代理 ,例如
export http_proxy=http://your-proxy:port和export https_proxy=https://your-proxy:port,再重跑脚本。 - 方案二:手动下载 原始Apex(从https://github.com/NVIDIA/apex/archive/refs/heads/master.zip下载),解压,然后改
scripts/build.sh脚本,注释掉下载那行(通常git clone或wgetm命令行)。图里标了位置。

为了预防此问题,可以预先镜像GitHub仓库到本地Git服务器。在企业环境中,网络问题常见,建议使用CI/CD工具如Jenkins自动化构建。
4.2 line 110: patch: command not found
(1)问题表现:显示命令未找到。
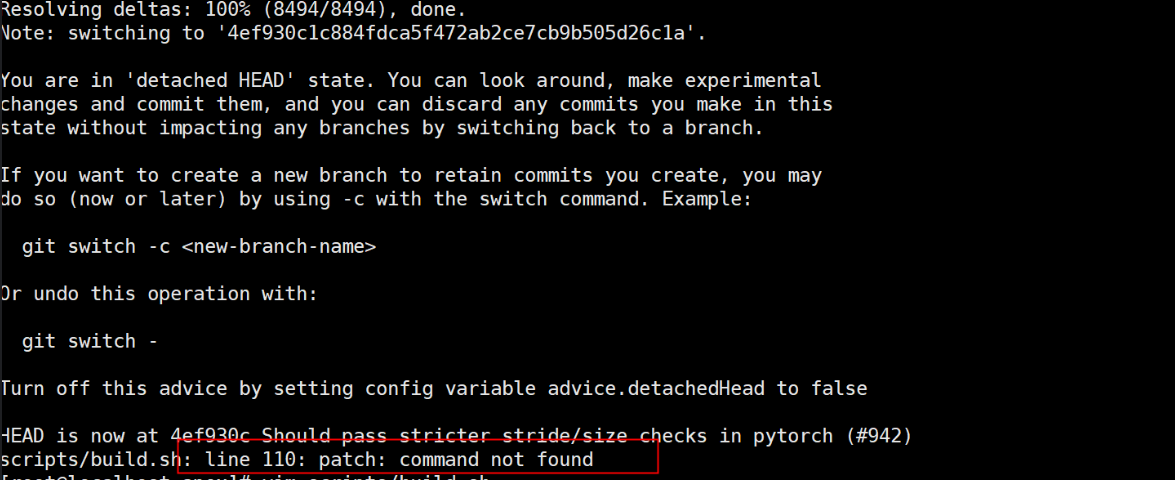
(2)原因:系统缺少patch工具,这是GNU Patch,用于应用补丁文件。
(3)解决方案:
- Ubuntu:
sudo apt-get install patch - openEuler(华为常用系统):
sudo dnf install patch
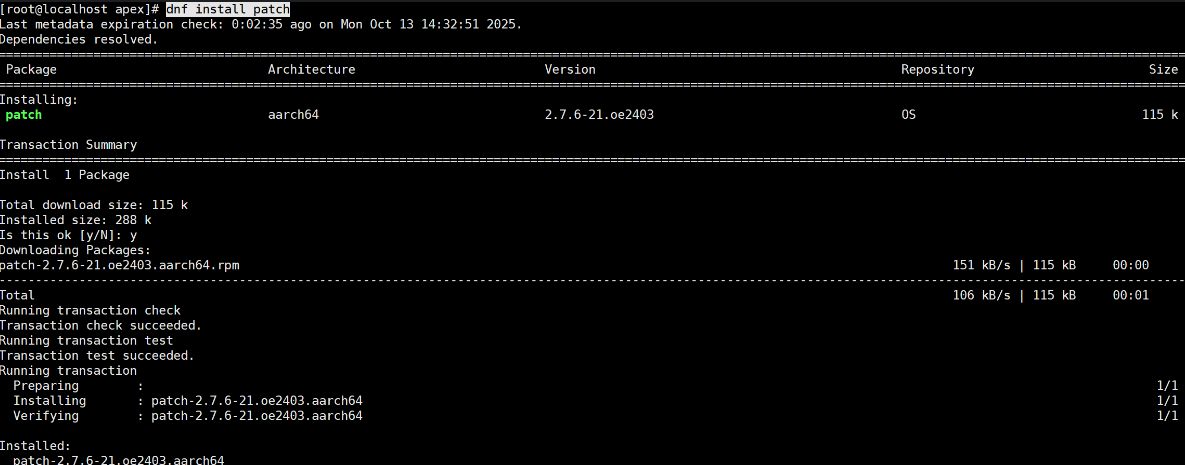
上图展示了安装后的成功界面。
4.3 fatal error: torch/extension.h: No such file or directory
(1)问题表现:头文件未找到。

(2)原因:编译路径硬编码为/usr/lib,但你的PyTorch安装在其他路径(如site-packages)。
(3)解决方案:
- 查找PyTorch路径:pip show torch,文档示例输出Location: /usr/local/lib64/python3.11/site-packages。下图展示了命令输出。
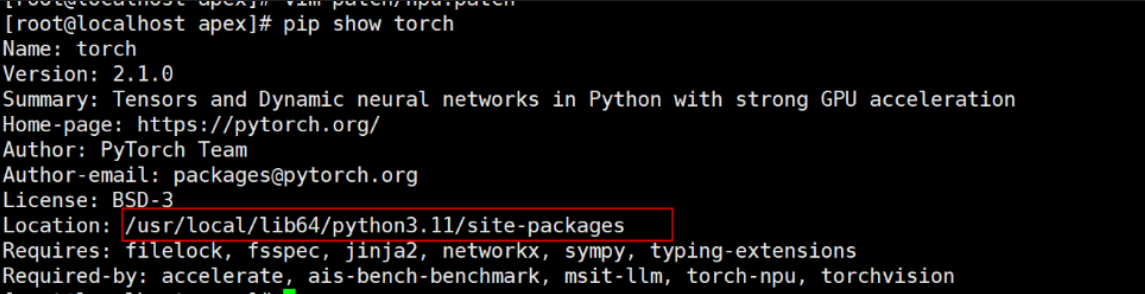
- 修改patch/npu.patch文件,第2649行,将package_dir手工指定为上述路径。使用vim patch/npu.patch编辑。下图指明了修改位置。
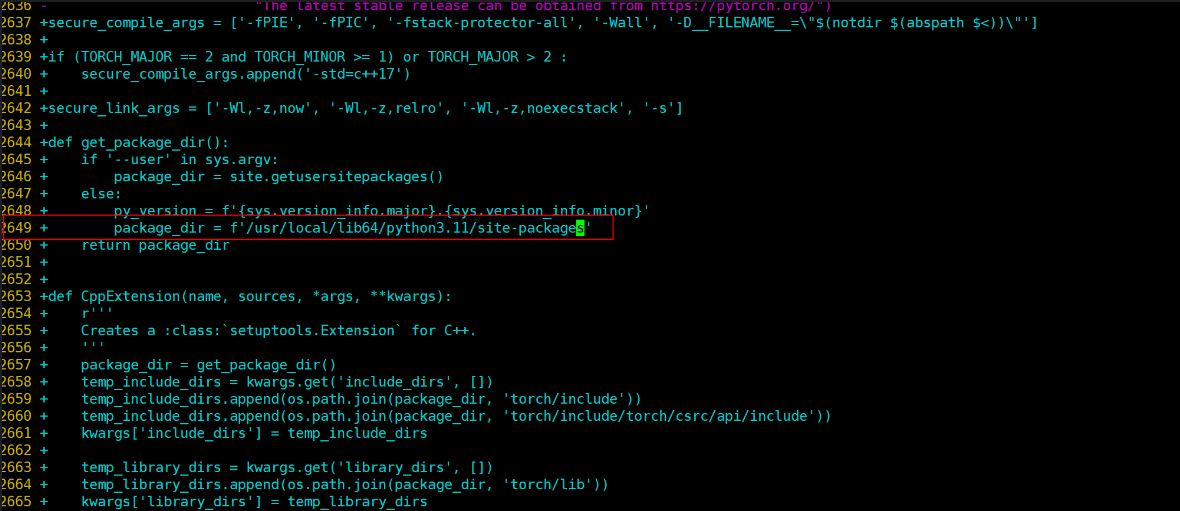
这反映了路径依赖问题。在虚拟环境中常见,建议使用venv隔离环境。其他可能原因:PyTorch版本不匹配,确保与CANN兼容(参考华为版本矩阵)。如果路径复杂,可以用符号链接(symlink)临时解决,但不推荐长期使用。
除了文档列出的错误,扩展一些其他常见问题:
- 内存不足:编译大型扩展时,需至少8GB RAM。如果OOM(Out of Memory),增加swap空间或用更高配置机器。
- 依赖版本冲突:如PyTorch与CANN不匹配,导致符号未定义。解决方案:严格遵循文档版本图。
- 权限问题:非root用户编译时,需确保写权限。用sudo或虚拟环境避免。
通过这些排查,编译成功率可达95%以上。
五、安装Apex Patch:集成到Python环境
编译后,进入apex/dist目录,安装生成的wheel包。
文档命令:
bash
cd apex/dist/
pip3 uninstall apex # 如果已安装,先卸载旧版
pip3 install --upgrade apex-0.1+ascend-{version}.whl # {version}为Python版本+CPU架构,如3.11-aarch64--upgrade确保覆盖旧依赖。wheel包匹配当前环境,避免ABI不兼容。
安装后验证:
python
import apex
print(apex.__version__)如果输出版本号(如0.1+ascend),安装成功。
其中,wheel包是Python的二进制分发格式,安装快于源码。多人协作时,分享wheel包到私有PyPI服务器。在生产环境中,用requirements.txt锁定版本:apex @ file:///path/to/apex-0.1+ascend-3.11.whl。
六、总结与避坑心得
通过这个指南,从为什么用Apex Patch到安装和问题排查,我们基本掌握了流程。整个过程其实最容易卡在环境依赖版本不匹配和编译时的路径设置上。作为开发者,装好Apex不只是步骤,还能帮你加速AI训练。从原理到实际,试试看。昇腾NPU在兴起,Apex Patch能帮大忙,赶紧克隆仓库上手吧!
注明:昇腾PAE案例库对本文写作亦有帮助。