本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发及AI大模型算法学习视频及资料,尽在聚客AI学院。
在人工智能领域,Transformer架构无疑是大模型发展史上最重要的里程碑之一。它不仅构成了当前大模型处理任务的基础架构,更是深入理解现代大模型系统的关键。今天我将通过结合论文原理与PyTorch源码API,深度解析Transformer的设计思路与实现细节。如有遗漏,欢迎交流。
一、整体架构设计
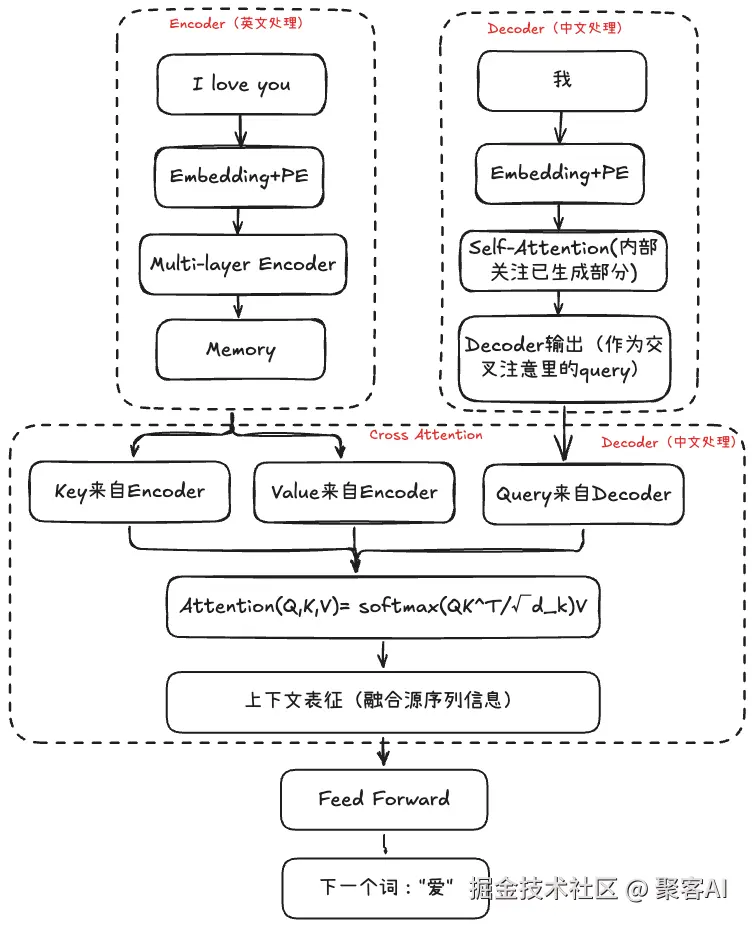
Transformer模型分为两个主要部分:左侧的编码器(Encoder)和右侧的解码器(Decoder)。
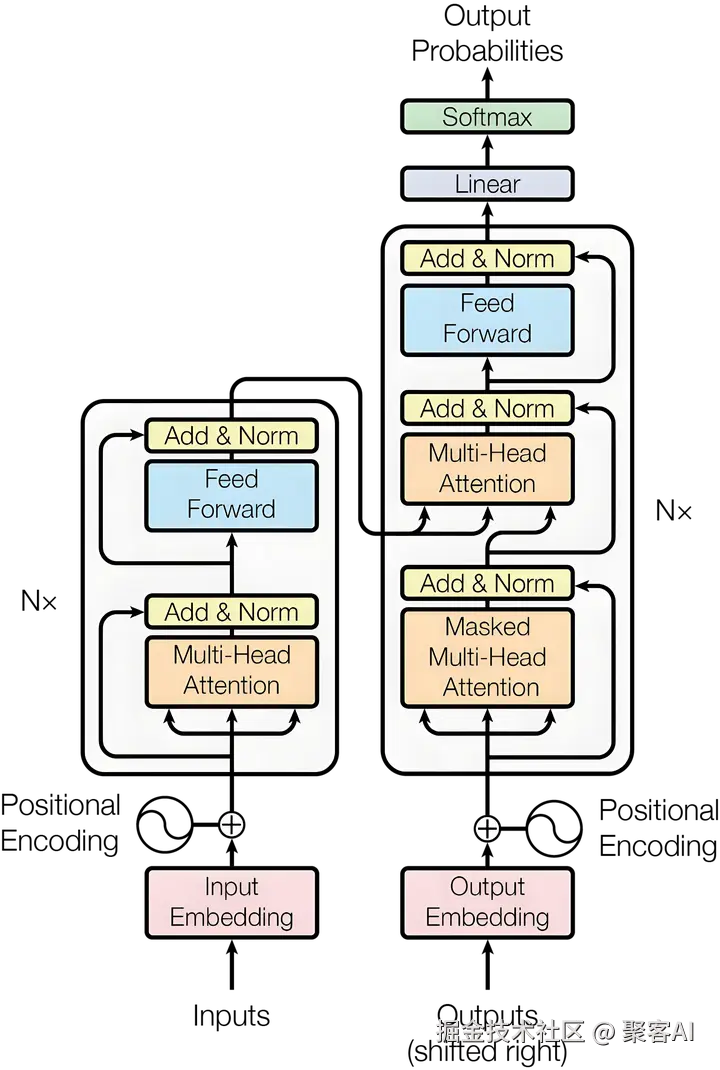
编码器负责接受完整的源序列输入,将其转换为富含语义信息的表示序列。以机器翻译任务为例,编码器的作用类似于深度理解原文的专家,需要充分把握整个句子的含义、语法结构和上下文关系。
解码器承担着更为复杂的任务:它需要同时接受目标序列和编码器输出的表示序列,然后输出词汇/字符的概率分布。这好比翻译专家既要理解原文含义(通过编码器输出),又要根据已翻译内容决定下一个合适的词汇。
二、位置编码机制
Transformer模型本身对位置信息不敏感。例如"我爱你"和"你爱我"这两个句子,在没有位置信息的情况下,模型无法识别它们是语义完全不同的表达。这就像人类失去对词语顺序的感知能力,显然无法正确理解语言。
因此,需要引入带有位置信息的向量,将其添加到每个input embedding上,使不同位置获得不同的表征。这就是Positional Encoding模块的作用。
在设计位置编码时,遵循三个重要假设:
- 确定性原则:每个位置的编码应该是确定的数字,不同序列中相同位置的编码必须一致。如果采用等分设计方法,将序列在0~1之间做均匀划分,那么序列长度不同时每个位置上的编码也会不同,这将违反确定性原则。
- 相对关系一致性:不同句子中,任意两个位置之间的相对距离关系应该保持一致。这一设计目的是让模型学习通用的语言关系,例如"修饰词位于被修饰词前一个位置"这种通用模式。
- 泛化能力:位置编码需要能够推广到训练时未见过的更长序列。即使测试集中的句子长度超过训练时的最大长度,模型仍能通过位置编码进行处理。
基于这些假设,Transformer采用正弦和余弦函数的组合来表征绝对位置信息:
- 向量维度为偶数:PE(pos, 2i) = sin(pos/10000^(2i/d_model))
- 向量维度为奇数:PE(pos, 2i+1) = cos(pos/10000^(2i/d_model))
这种设计的关键优势在于:pe(pos+k)可以表示为pe(k)的线性组合(利用三角函数公式sin(A+B)=sin(A)cos(B)+cos(A)sin(B))。这意味着即使测试集中出现pos+k这种未见过的位置,也可以表示为训练集中已见过位置的线性组合,从而保证了对长句子的推广能力。
关于位置信息在深层网络中可能丢失的担忧,通过残差连接机制得到解决。假设有N层神经网络,输入x₀包含位置编码,那么:
第1层: x₁ = x₀ + F₁(x₀)
第2层: x₂ = x₁ + F₂(x₁) = x₀ + F₁(x₀) + F₂(x₁)
...
第N层: xₙ = x₀ + Σᵢ₌₁ⁿ Fᵢ(xᵢ₋₁)
初始位置信息x₀始终存在于每一层的输出中,确保了位置信息不会随网络深度增加而消失。
三、PyTorch实现解析
PyTorch中的Transformer实现位于/pytorch/torch/nn/modules/transformer.py,本文基于v2.5.1版本进行分析。
PyTorch定义了顶层的Transformer类,可通过torch.nn.Transformer调用:
ini
transformer_model = nn.Transformer(d_model=512, nhead=8, num_encoder_layers=6)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)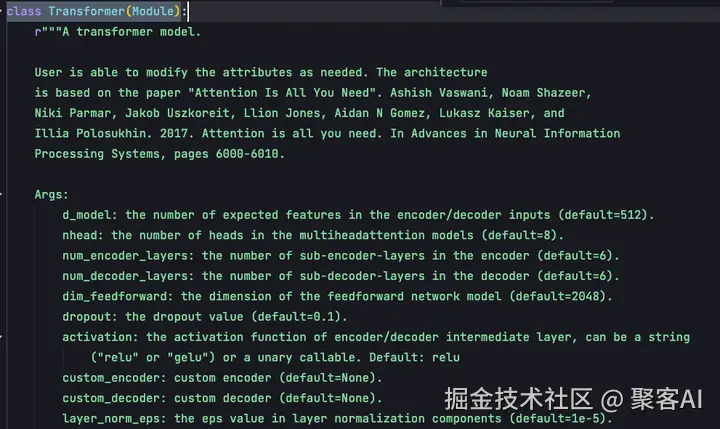
在Transformer的__init__函数中,包含5个核心参数:
- d_model:整个Transformer的特征维度,原论文设置为512。这一维度需要足够大以承载丰富语义信息,同时不能过大导致计算复杂度过高。
- nhead:Multi-head attention的头数。多头设计使模型能够捕捉更多位置与位置之间的关系。
- num_encoder_layers:编码器encoder的block数量,每个block包含多头自注意力机制和前馈神经网络,默认6个。
- num_decoder_layers:解码器decoder的block数量,每个block包含多头自注意力机制、交叉注意力机制以及前馈神经网络。
- dim_feedforward:前馈神经网络层中间的特征维度,默认2048。Multihead attention输出首先映射到2048维特征空间,再映射回512维空间,以保证输出维度与输入一致,便于残差连接。
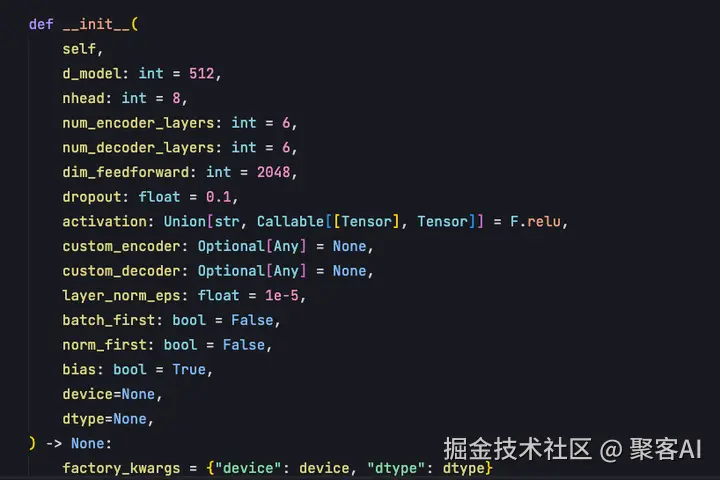
init函数的作用是实例化模块,首先实例化encoder模块。
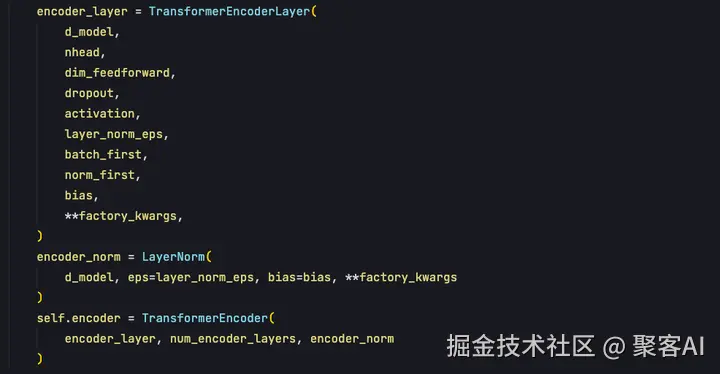
encoder通过TransformerEncoder类实现实例化,需要传入encoder_layer参数。TransformerEncoderLayer类实现了Multihead self attention的调用、残差连接、层归一化、全连接网络,这些组件共同构成一个encoder_layer。
解码器部分同样需要传入decodeLayer参数,该layer包含自注意力机制、交叉注意力机制以及前馈神经网络。

总体而言,Transformer源码由四个核心class构成:
- TransformerEncoderLayer:单个编码层的实现
- TransformerEncoder:编码层的串联组织
- TransformerDecoderLayer:单个解码层的实现
- TransformerDecoder:解码层的串联组织
在forward函数中,Transformer的计算流程清晰明确:
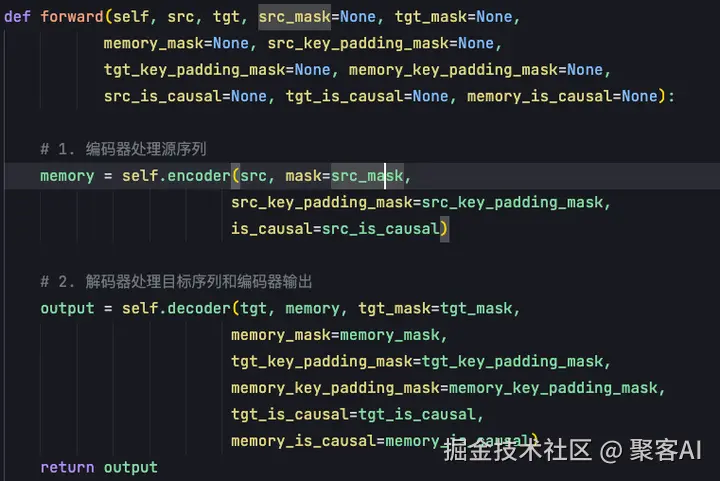
编码器输入源句子及padding_mask。编码器中的注意力机制不需要因果掩码,但需要处理样本长度差异。训练时序列长度不一致,短样本的后续位置无效,通过softmax中将无效位置值转为负无穷,使这些位置概率归零。
解码器输入包括:目标句子target、编码器输出memory、目标掩码target mask和内存掩码memory mask。target mask是考虑因果关系的上三角矩阵,确保输出每次只根据当前预测词汇左侧的所有词汇进行预测,而不使用右侧词汇信息。
Transformer本质上是自回归的解码过程,非并行预测输出,而是每次预测一个输出,通过不断解码预测完整目标句子。
四、编码器实现细节
单个编码器的实现集中在TransformerEncoderLayer类中。在__init__函数中,需要实例化四个关键组件:
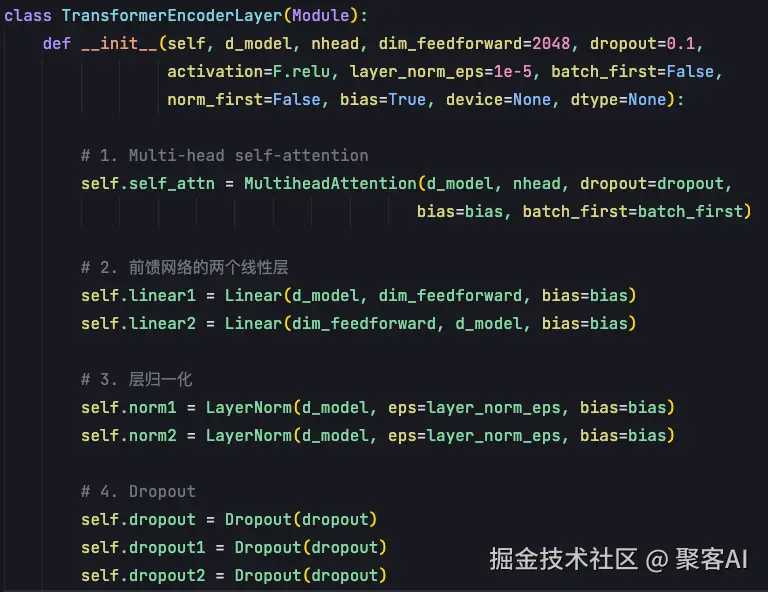
init函数参数与transformer中一致:d_model为512维特征维度,nhead为多头注意力头数。
多头设计目的是让模型捕捉更多位置间关系。多头分为多组query、key和value,每组独立计算attention上下文向量,最后拼接这些向量并通过FFN得到最终输出。原始512维embedding分为8个头后,每个头向量维度变为64。每个头独立计算注意力后,得到8个64维输出向量,通过拼接操作重新组合成512维向量,再经输出线性变换层得到最终512维输出。
dim_feedforward是前馈神经网络FFN的维度,设置两个全连接层实现从512到2048再到512的变换。前馈神经网络对每个位置独立建模,不同位置参数共享,类似于1×1的pointwise卷积,对图像中每个像素位置的特征向量独立进行变换。参数共享旨在让模型学会"如何处理特征"的通用能力,而非"如何处理第x个位置特征"的特定能力。
FFN实现embedding相同位置不同维度间的融合,注意力机制负责位置间信息交流。
init函数中实例化的组件包括:
- Multi-head attention模块
- FFN前馈神经网络中的两个Linear层
- 层归一化layer norm
- Dropout模块,提高网络泛化能力
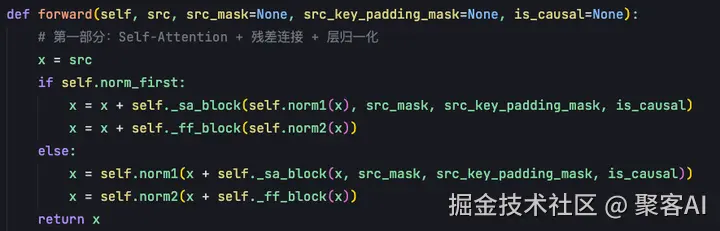
forward函数中,编码器层的调用流程为:首先通过self attention block得到表征,加上残差连接后经层归一化处理;然后将输出送入feed forward block,经过每个位置独立的全连接层,再次加上残差连接后经层归一化得到最终输出。
原始论文设计采用后归一化方式。
TransformerEncoder类的作用是将多个编码器层串联起来,将上一层输出作为下一层输入,经多层处理得到最终编码器输出。
init函数主要传入两个参数:encoder_layer(TransformerEncoderLayer实例)和num_layers(transformer encoder层数)。
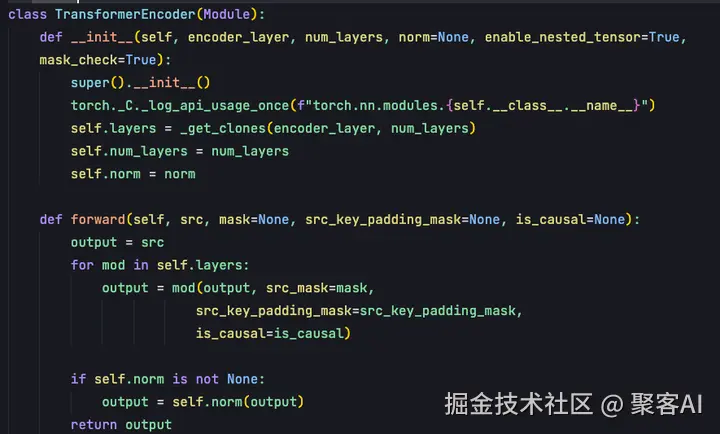
五、解码器实现细节
解码器实现比编码器更复杂,包含三个子模块,需要处理更多交互。
在TransformerDecoderLayer中,需要实例化三套组件(自注意力+交叉注意力+前馈神经网络):
init参数中,d_model表示模型特征大小(默认512),nhead为解码器多头自注意力机制头数,dim_feedforward为解码器中FFN前馈神经网络维度。
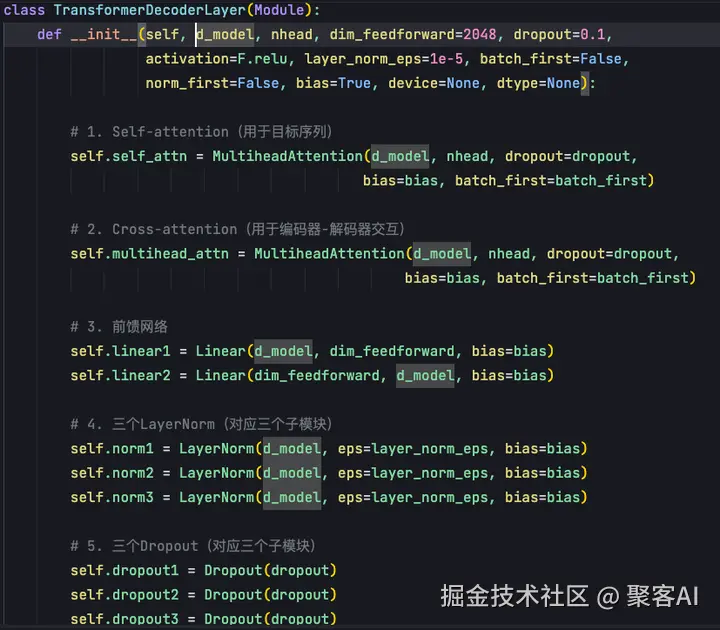
解码器与编码器的不同之处在于需要实例化两个Multihead attention模块:
- 自注意力机制:处理解码器输入序列(目标句子embedding)的自身表征
- 交叉注意力机制:建立解码器多头注意力输出与编码器输出状态的关联性,跨越encoder和decoder两个不同序列
同样,解码器实现两个Linear层,将交叉自注意力机制输出投射到2048维空间后再降维至512维。由于解码器有三个模块,需要实现3个归一化和3个dropout层。
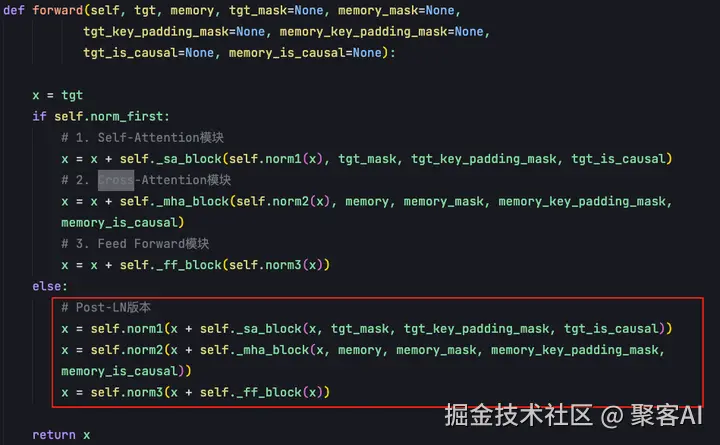
解码器的forward函数体现三个模块的协同工作:
- 目标句子序列x和target mask输入到self._sa_block,对目标句子做自注意力计算,结果经残差网络和层归一化
- 上一模块输出与编码器输出memory进行交叉注意力计算,新表征经残差网络和归一化输出
- 上一模块输出送入FFN前馈神经网络,再次经残差网络和归一化得到解码器最终输出
_sa_block和_mha_block均调用Multihead attention,但query、key、value来源不同。
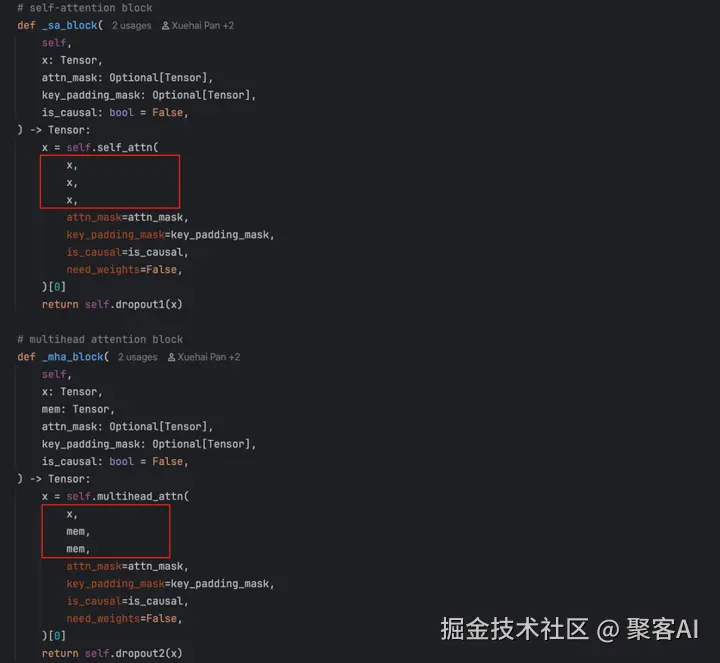
自注意力机制中query、key、value均来自目标序列,计算自身相关性。交叉注意力机制中,query来自解码器输出,key和value来自编码器输出(memory)。
多个DecoderLayer构成TransformerDecoder,实现方式与TransformerEncoder类似。
六、注意力机制核心
PyTorch的实际实现进行了更多优化,但核心思想与论文版本一致:

直观理解,attention函数建立query与key-value对之间的连接,最终产生输出。以百度搜索为例:搜索词条为query,数据库中的词条信息为key,具体内容为value。通过query,百度返回搜索结果,这就是注意力机制基于query和key+value计算上下文的过程。
注意力计算结果是对Value的加权求和,权重基于Query和Key的相似度计算。先计算Query与每个Key的相似度,经Softmax归一化得到权重,再将权重与对应Value加权求和。
Transformer采用"Scaled Dot-Product Attention",公式中QK相乘后除以√d_k,目的是使Softmax输入分布更稳定,方差更小。
注意力计算由Q、K、V三个向量构成。首先进行query和key的矩阵相乘(单样本为向量内积,批量为矩阵相乘),然后除以√d_K进行缩放,得到每个位置上的内积结果后进行归一化处理。Softmax输出结果总和为1,每个值在0-1之间,表示概率分布。将此概率与每个位置value加权求和,得到attention输出。
Multi-head self attention同时计算多个自注意力机制,将每个结果拼接后得到最终输出。
代码实现中,注意力计算输入包括query、key和value。
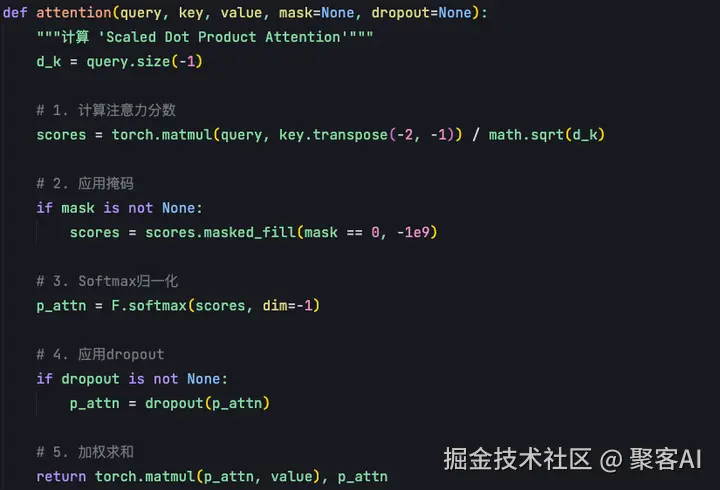
首先将q与k的转置进行矩阵相乘,得到向量后添加mask。mask将等于0的位置填充为极小的负数(负无穷),经Softmax归一化后概率变为0,使不重要位置概率赋值为0。得到注意力概率分布后,与value进行加权求和,得到自注意力机制输出。多头注意力将多个单头输出拼接为最终输出。
在Transformer中,不同注意力机制的QKV来源和映射方式不同:
- 编码器层:QKV均由word embedding加position encoding后,通过三个独立线性映射得到
- 解码器自注意力层:同样由目标句子embedding加position encoding后,经三个独立线性映射得到QKV
- 交叉注意力层:query来自解码器输出的线性映射,key和value分别来自编码器输出memory的两个不同映射
本期拓展知识点:
那么,你知道在大语言模型中,Transformer与专家混合模型之间的区别吗?感兴趣的粉丝朋友可以查阅我之前整理的技术文档:《Transformer与专家混合模型的比较》
好了,本次的分享也花了不少时间去整理,如果对你有所帮助,记得给个小红心,我们下期见。