近日,英伟达与多伦多大学、向量研究所及德克萨斯大学奥斯汀分校的研究团队联合发布了一项名为ViPE(视频姿势引擎) 的突破性技术。

ViPE 旨在解决3D几何感知领域的关键挑战,即如何从复杂的自然视频中高效且精准地提取3D信息。
ViPE解决了什么痛点?
传统上有两种路子:
- SLAM(同时定位与建图): 准确,但经常假设场景静止,一遇到动态物体就抓狂。
- 端到端模型: 靠大数据训练,鲁棒性强,但吃显存太狠,长视频不敢碰。
ViPE聪明地走了条 "中庸之道" :
- 它把SLAM的精确性 + 深度学习的鲁棒性结合了起来。
- 在估计相机运动、相机参数和深度图时,不仅更高效,还能应付动态物体和各种镜头类型(广角、360°全景,甚至自拍视频)。
技术核心与应用
3D几何感知是自动驾驶、虚拟现实(VR)和增强现实(AR) 等多种现代技术的核心。ViPE 创新性地从原始视频中快速获取相机的固有特性、运动信息以及高精度的深度图,为这些空间AI系统提供了可靠的数据基础。
- 关键帧 + 捆绑调整(Bundle Adjustment)
把视频当拼图,挑出 "关键帧" 作为骨架,然后通过数学优化(BA)把这些帧的相机位置、参数和深度关系都算得稳稳当当。相比传统SLAM,它不仅稳,还能适配更复杂的场景。
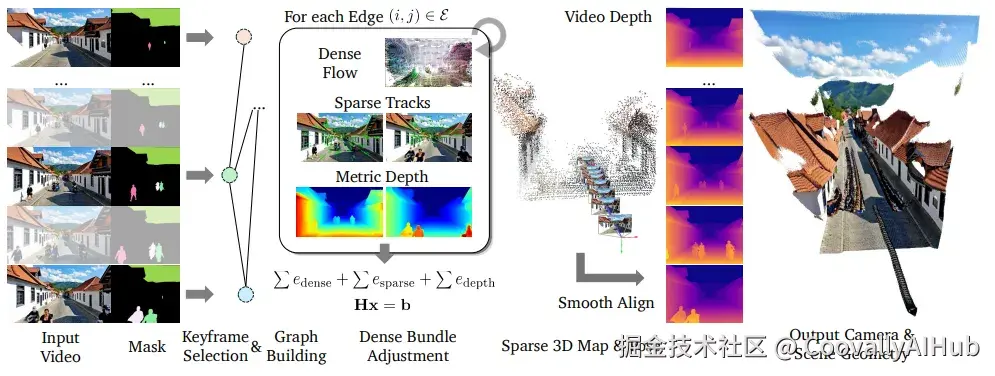
- 双保险:稠密光流 + 稀疏点约束
- 稠密光流: 让AI"盯着像素点挪动",粗略掌握相机怎么动。
- 稀疏点约束: 再用角点检测+Lucas-Kanade追踪器"精修细抠",确保定位不跑偏。
两者结合,就像给相机导航装了 "双GPS" ,既有全局参考,又有局部修正。
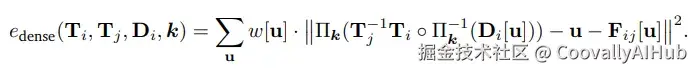
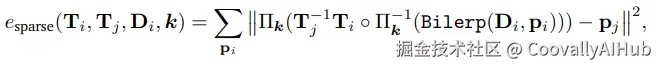
- 深度先验 + 对齐机制
单张图预测深度?容易漂。纯几何优化?容易糊。
ViPE聪明地融合了预训练深度模型的先验,再通过"平滑对齐"机制保证每一帧深度图都能接上,不会出现忽远忽近的突兀效果。这样生成的3D效果更真实、连贯。
- 动态物体剔除
在现实世界里,人、车、狗子都会乱动。ViPE先用分割模型把这些动来动去的部分 "遮掉" ,只盯着背景算几何。这样一来,就不会被路人甲的挥手动作搅乱相机轨迹。
- 多相机模型支持
不管是普通手机的 "针孔相机" 、运动相机的广角,还是360°全景,ViPE都能hold住。甚至可以处理多摄像头rig,把不同镜头拍的内容融合在一起。对于VR/AR、无人机视频,这点特别有用。

- 关键帧填充(Pose Infilling)
不是每一帧都要重计算位姿------非关键帧可以通过和最近关键帧的关系 "补齐" 。这大大节省了算力,还能保证整体轨迹连续。
- 运行速度与实用性
别以为这些优化很耗时,ViPE在一张GPU上就能跑到 3--5 FPS。虽然还达不到实时,但对科研和大规模数据标注来说,已经非常"能打"了。
ViPE 具有强大的适应性,能够处理各种场景和相机类型,包括动态自拍视频、电影镜头、行车记录仪以及针孔、广角和360°全景相机模型。
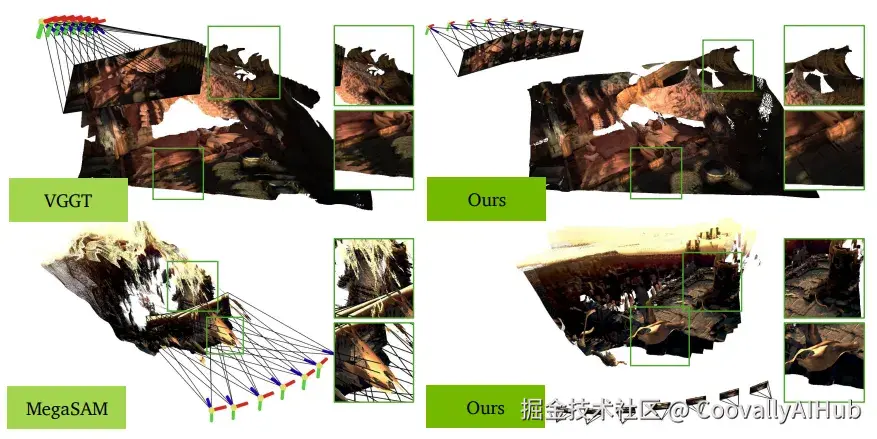
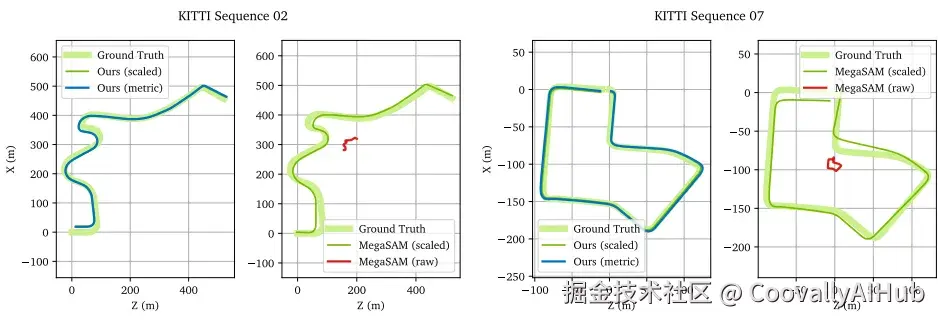
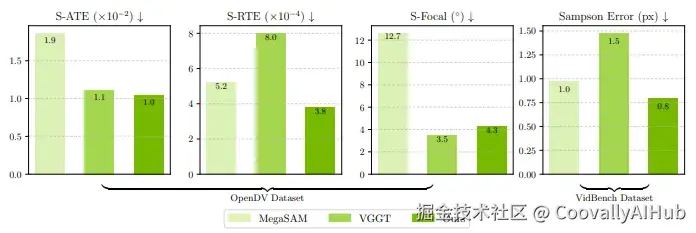
测试结果显示,ViPE 在多个基准测试中的表现均优于现有技术(如 MegaSAM、VGGT 和 MASt3R-SLAM)。它不仅在姿态和内在函数精度方面表现出色,还能在单个GPU上以每秒3到5帧的速度稳定运行,并成功生成了尺度一致的轨迹。
数据集大礼包
为推动空间AI领域的进一步研究,研究团队还顺手放出了三个重磅数据集,全都用ViPE标注过:
- DynPose-100K++: 10万条真实网络视频,重新标注,质量大升级。
- Wild-SDG-1M: 100万条AI生成视频(是的,用扩散模型生成的),共7,800万帧。
- Web360: 2000条360°全景视频,附带相机位姿和深度。
合计接近 9600万帧数据 ------ 对3D视觉研究者来说,这波简直是"宝藏矿区"。
应用前景:不止科研
论文里提到,ViPE已经在不少下游场景派上用场:
- 给生成模型(如Gen3C、Cosmos)提供条件输入,让AI更好地"造世界"。
- 帮助3D重建模型(BTimer等)在各种输入下保持鲁棒。
- 为自动驾驶、机器人导航、AR/VR提供更可靠的数据支持。
所以,ViPE不是"实验室里玩票",而是真正能加速空间智能(Spatial AI) 落地的一把利器。
研究和数据集地址
shell
#研究地址:https://research.nvidia.com/labs/toronto-ai/vipe/
#数据集地址:https://github.com/nv-tlabs/vipe?tab=readme-ov-file#downloading-the-dataset