近日,香港大学与字节跳动联合推出了一项名为DanceGRPO的创新技术 ,该技术首次将Group Relative Policy Optimization(GRPO)成功应用于多类视觉生成任务,解决了基于强化学习的视觉生成方法在多样化Prompt集上的不稳定性问题。

这项研究为视觉生成领域带来了新的突破,为实现高质量、高一致性的视觉内容生成提供了全新的解决方案。
技术背景:视觉生成的挑战与机遇
当前,视觉生成模型正经历一场技术革命。从文生图到文生视频,再到图生视频,生成模型的能力边界在不断拓展。然而,如何让生成内容更好地符合人类审美偏好,始终是一个关键挑战。
传统的优化方法存在明显局限性:ReFL等方法依赖于可微的奖励模型,在视频生成中效率低下;DPO系列方法只能实现微小的视觉质量改进;而基于RL的方法(如DDPO、DPOK)在扩展到多样化Prompt集时难以稳定优化。
DanceGRPO的技术创新
- 统一的算法框架
DanceGRPO的核心突破在于提供了一个统一的算法框架 ,能够同时适应Diffusion Model和Rectified Flow两种主流生成范式。研究团队通过随机微分方程(SDEs) 重新表述了这两种模型的公式,解决了Rectified Flow中ODE-based采样与马尔科夫决策过程的冲突问题。

- 多任务适配能力
该技术在文生图、文生视频、图生视频三大任务上均表现出色:
- 文生图: 在Stable Diffusion、FLUX等模型上,HPS score从0.239提升至0.365
- 文生视频: 在HunyuanVideo模型上,运动质量相对提升181%
- 图生视频: 在SkyReels-I2V模型上,运动连贯性提升118%

- 智能奖励机制
研究团队创新性地融合了五种奖励模型,共同优化多个质量维度:
- 图像美学质量(HPS-v2.1)
- 图文对齐度(CLIP score)
- 视频美学质量(帧级评估)
- 视频运动质量(物理感知评估)
- 二进制反馈(阈值离散化)
- 关键技术创新
- 共享初始化噪声机制: 解决了视频生成中的Reward Hacking问题,确保训练稳定性
- 自适应时间步选择: 在不影响生成质量的前提下,显著提升训练效率
- Best-of-N推理缩放: 通过选择性采样策略优化训练效率

实验结果与性能表现
实验结果表明,DanceGRPO在多个权威基准测试中均取得了显著提升:
- 文生图实验
- Stable Diffusion 实验
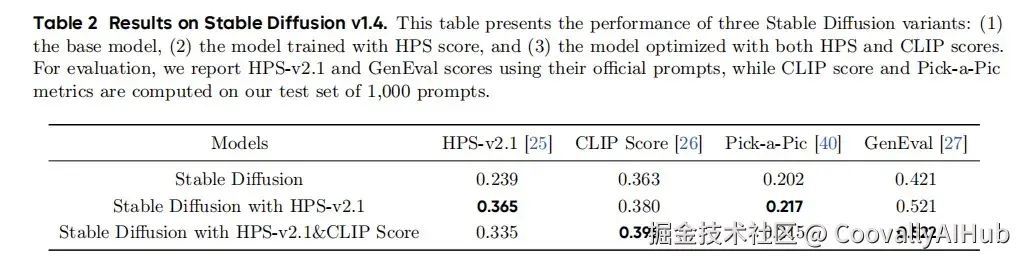
Stable Diffusion v1.4 是一个基于扩散的文生图模型,包括 3 个核心组件:用于去噪的 UNet 架构、用于语义调节的基于 CLIP 的 text encoder 和用于 latent space 建模的 VAE。
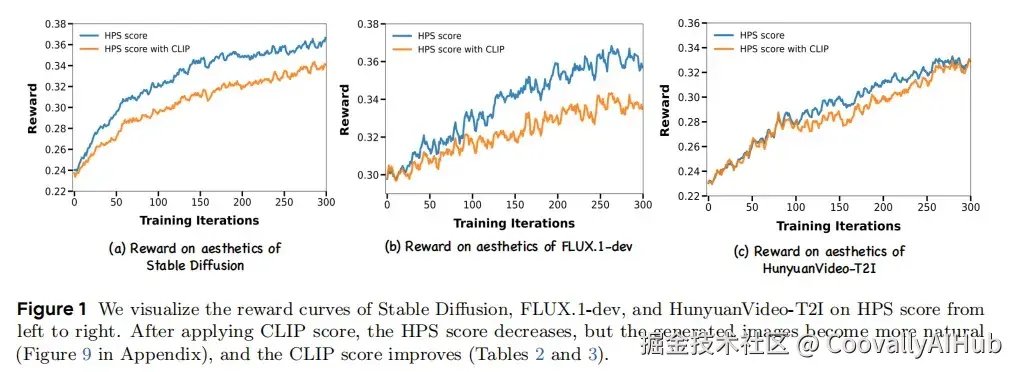
如表2 和图 1-(a) 所示,DanceGRPO 在奖励指标方面取得了显著改进,将 HPS score从 0.239 提高到 0.365,将 CLIP score 从 0.363 提高到 0.395。作者也采用了 Pick-a-Pic 和 GenEval 等指标来评估本文方法。结果证实了本文方法的有效性。
- FLUX 实验
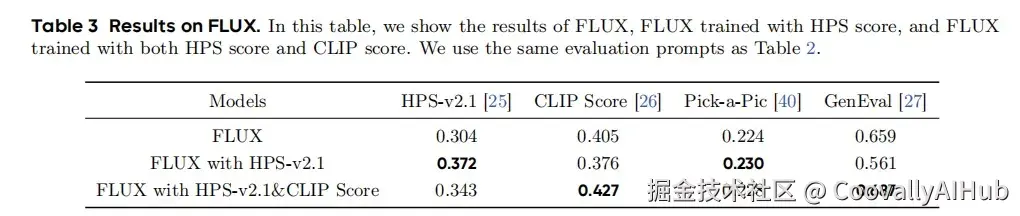
FLUX.1-dev 是一种 Flow-based 的文生图模型,在多个基准测试中推进最先进的技术,架构比 Stable Diffusion 更复杂。为了优化性能,作者集成了两个奖励模型:HPS score 和 CLIP score。如图 1-(b) 和表 3 所示,所提出的训练范式在所有奖励指标上都取得了显著的改进。
- HunyuanVideo-T2I 实验
HunyuanVideo-T2I 是 HunyuanVideo 框架的文生图版本,通过将 latent frame 的数量减少到1 来重新配置。这种修改将原始视频生成模型转换为 Flow-based 的图像生成模型。作者使用公开可用的 HPS-v2.1 模型 (一种人类偏好驱动的视觉质量指标) 进一步优化。如图 1-(c) 所示,这种方法将平均奖励分数从大约 0.23 提高到 0.33,反映了与人类审美偏好更好的对齐。
- 文生视频实验
- HunyuanVideo 实验
与文生图模型相比,优化文生视频模型会带来更大的挑战,主要是由于训练和推理过程中的计算成本提高,收敛速度较慢。
在预训练中,作者采用渐进式策略:初始训练侧重于文生图,然后是低分辨率视频生成,最后是高分辨率视频细化。然而观察表明,仅依靠以图像为中心的优化会导致视频生成得到次优的结果。为了解决这个问题,作者使用的训练视频样本都是 480×480 分辨率合成的,但是可视化时候可以使用更大的分辨率。
此外,构建一个有效的 Video Reward Model 来训练对齐模型也有很大的困难。本文实验评估了几个模型:Videoscore 模型表现出不稳定的奖励分布,使得优化不切实际,而 Visionreward-Video 是一个 29-dimensional metric,产生了语义连贯的奖励,但在各个维度上都存在不准确。
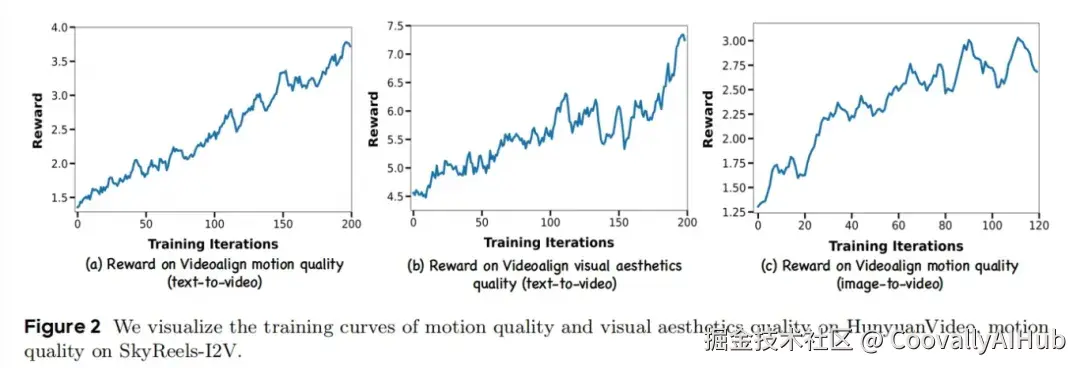
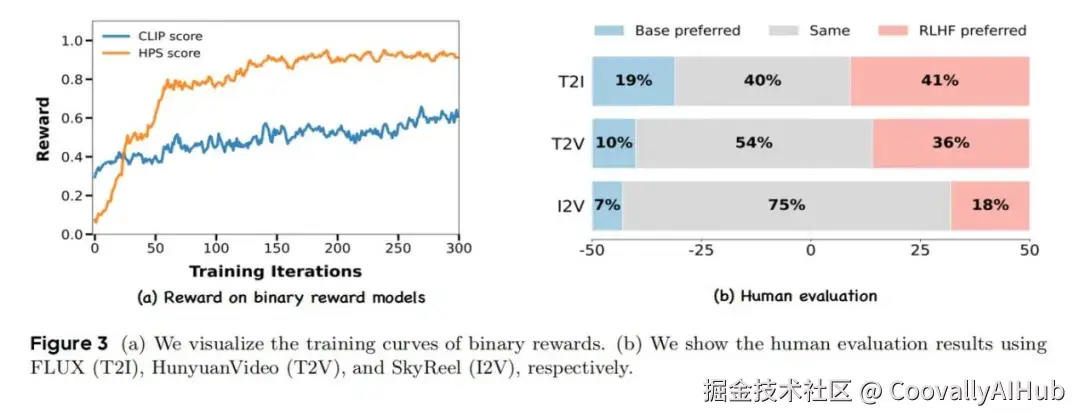
因此,作者采用了 VideoAlign,这是一个多维框架,用于评估视觉美学质量、运动质量和文本-视频对齐 3 个关键方面。值得注意的是,文本-视频对齐维度表现出显著的不稳定性,因此排除在最终分析之外。如表5和图 2-(b) 所示,本文方法在视觉和运动质量指标方面分别获得了 56% 和 181% 的相对改进。

- 图生视频实验
- SkyReels-I2V 实验
SkyReels-I2V 代表了本研究开始时 (截至 2025年2月) 的最先进的开源图生视频模型。SkyReels-I2V 源自 HunyuanVideo 模型,通过将图像 condition 集成到 input 来微调模型。本文的一个核心发现是 I2V 模型只允许优化运动质量,包括运动连贯性和审美动态,这是因为视觉保真度和文本-视频对齐本质上受到输入图像的属性的限制,而不是模型的参数空间。因此,本文的优化方案利用了 VideoAlign Reward Model 中的运动质量 metric,在这个维度上实现了 118% 的相对改进,如图 2-(c) 所示。
- 人工评估
使用内部 Prompt 和参考图像进行评估。对于文生图,在 240 个 Prompt 上评估 FLUX。对于文生视频,在 200 个 Prompt 上评估 HunyuanVideo,对于图生视频,在 200 个 Prompt 上测试 SkyReels-I2V 及其相应的参考图像。结果如图所示,人类始终更喜欢用 RLHF 细化的输出。
技术意义与应用前景
DanceGRPO的推出具有重要的技术意义:
- 首次将Group Relative Policy Optimization(GRPO)成功应用于多模态视觉生成任务;
- 通过统一的随机微分方程框架解决了Diffusion Model与Rectified Flow的范式兼容问题;
- 其多奖励模型协同机制突破了传统RL方法在多样化Prompt集上的稳定性瓶颈;
- 实现了文生图、文生视频、图生视频等多任务性能的全面提升。
这项技术将重塑数字内容生产范式,为短视频创作、游戏开发、电商展示、元宇宙构建等领域提供高效稳定的视觉生成解决方案,显著降低创作门槛与制作成本,推动生成式AI技术从实验室走向规模化产业应用,最终实现"人人皆可创作"的愿景。
论文和源码地址
ruby
论文地址:https://arxiv.org/pdf/2505.07818
代码链接:https://github.com/XueZeyue/DanceGRPOCoovally助力计算机视觉
依托 DanceGRPO 的强大生成能力,开发者能够快速获得覆盖多任务的高质量视觉数据。
在 DanceGRPO 带来算法突破之后,一个现实问题随之而来:如何让这些前沿研究真正用到产业和项目中?
传统做法往往需要研究者或开发者:
- 搭建复杂的本地环境(依赖管理、算力配置、分布式训练);
- 手动修改训练脚本来适配不同的奖励函数、采样机制;
- 重复跑实验,才能对比出最优的参数组合。
这不仅耗时耗力,还极大抬高了技术落地的门槛。
而 Coovally 无代码平台 正好切入了这一痛点:
- 快速生成视觉任务数据集
借助 DanceGRPO 的生成能力,用户可以在 Coovally 平台上扩充图像数据集,例如用于电商展示、短视频训练、工业检测仿真等场景。
- 无代码训练与调优
平台内置可视化操作界面,支持直接调用前沿开源模型(如 YOLO 系列等),无需写复杂代码,就能完成训练、验证和推理。
** **
**
- 降低算力与部署门槛
用户不必购买昂贵 GPU 服务器,在 Coovally 的在线环境中就能完成大规模实验,这对中小企业和独立开发者尤其友好。
!!点击下方链接,立即体验Coovally!!
平台链接: www.coovally.com
Coovally平台还可以直接查看"实验日志"。提供直观的可视化训练界面,清晰设置参数,监控训练过程(Loss, mAP等指标实时可视化)。
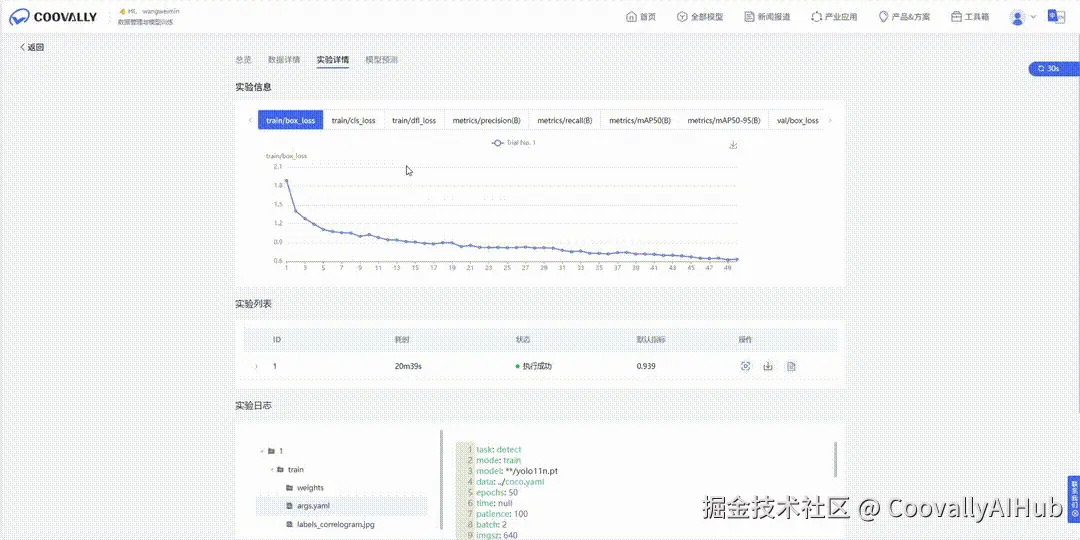
无论你是算法新手还是资深工程师,Coovally以极简操作与强大生态,助你跳过技术鸿沟,专注创新与落地。访问官网,开启你的零代码AI开发之旅!
结语
DanceGRPO代表了视觉生成与强化学习结合领域的重要进展,其统一的算法框架、出色的多任务性能以及创新的奖励机制,为未来视觉生成技术的发展指明了方向。随着技术的不断完善和应用场景的拓展,我们有理由期待更多基于此类技术的创新应用出现。
这项研究不仅展示了学术机构与企业的合作价值,更体现了多学科交叉融合在推动技术进步中的重要作用。视觉生成技术的未来,令人期待。