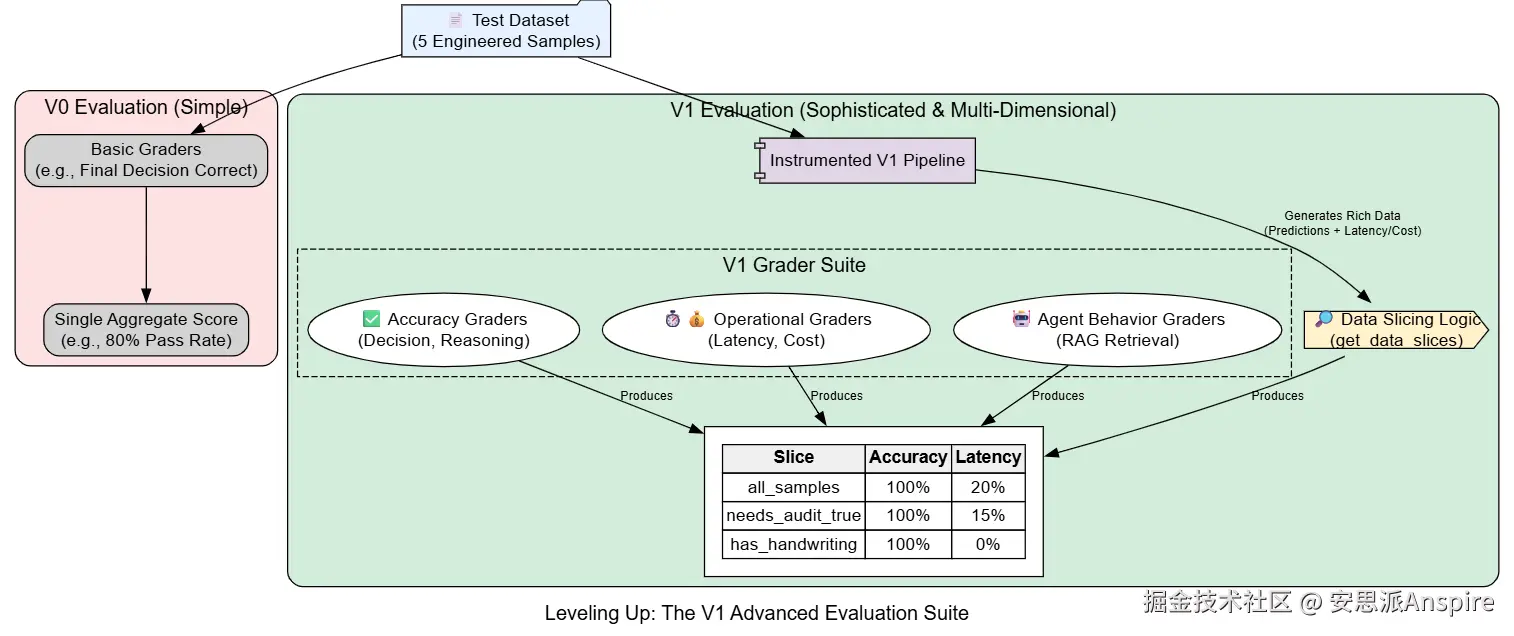
使用切片和运营指标评估 V1
我们的V1代理在最具挑战性的测试用例中表现完美。然而,真正的生产就绪需要的不仅仅是修复已知的漏洞。我们需要确保我们新的、更复杂的系统不仅准确,而且高效,并且其准确性在不同类型的数据中都能保持。
为此,我们将加强评估套件。
我们的V0评估套件在发现初始错误方面表现出色。现在,我们需要一个更复杂的套件来评估我们的V1系统。我们将引入:
-
**数据切片:**我们不仅会评估整体性能,还会评估数据特定子集的性能,以发现隐藏的弱点。
-
**运营指标:**我们将为成本和延迟添加评估指标,因为一个太慢或太昂贵的系统无法投入生产。
-
**高级模型评分评估:**我们将创建一个评分器来检查RAG系统是否检索到了
正确
的上下文。
按数据切片评估
聚合指标可能具有极大的误导性。一个整体准确率为98%的系统,可能在一小部分但关键的数据子集(例如,所有手写收据)上100%失败。对数据进行切片可以让我们发现这些集中的失败模式。我们将定义一个函数,把测试样本分类到有意义的子集中。
python
# 此函数定义我们的数据切片。
# 它接受完整的记录列表,并返回一个字典,该字典将切片名称映射到
# 属于该切片的样本 ID 列表。
def get_data_slices(records: List[EvaluationRecord]) -> dict:
"""将样本 ID 分类为有意义的子集,以便进行切片评估。"""
slices = {
# 包含所有样本的基线切片。
"all_samples": [r.sample_id for r in records],
# 基于地面实况标签的切片。
# 这有助于我们计算真正率和真负率等指标。
"needs_audit_true": [r.sample_id for r in records if r.reference_audit.needs_audit],
"needs_audit_false": [r.sample_id for r in records if not r.reference_audit.needs_audit],
# 根据输入特征进行切片。
# 这有助于我们发现模型是否在特定类型的收据上存在困难。
"has_handwriting": [r.sample_id for r in records if r.reference_details.handwritten_notes],
}
return slices在这个get_data_slices函数中,我们并非只是随机地对数据进行分组。每个切片都是我们想要测试的特定假设。"needs_audit_true"和"needs_audit_false"切片将让我们了解我们的系统是否偏向于某一个决策而非另一个。"has_handwriting"切片直接针对我们数据中已知的复杂性,使我们能够隔离这些更具挑战性的输入的性能。
成本、延迟和运营指标评分器
接下来,我们将扩展评估范围,纳入关键运营指标。我们首先需要更新评估记录,以跟踪这些新的数据点。
python
import time
import random
# 更新我们的数据模型以跟踪新指标。
# 这个新类继承了 EvaluationRecord 的所有字段并添加了新字段。
class V1EvaluationRecord(EvaluationRecord):
latency_ms: float
token_cost: float
retrieved_policies: List[str]通过创建V1EvaluationRecord(继承自EvaluationRecord),我们可以添加新的操作字段(latency_ms、token_cost、retrieved_policies),而无需复制存量数据模型。这是一种简洁、可扩展的方法。
现在,我们将为这些新指标创建相应的评分函数。
python
# 为我们的新运营指标创建新的评分函数。
def grade_latency(record: V1EvaluationRecord) -> float:
"""运营评分器:如果延迟低于500毫秒的阈值,则通过。"""
return 1.0 if record.latency_ms < 500 else 0.0
def grade_cost(record: V1EvaluationRecord) -> float:
"""运营评分器:如果令牌成本低于0.005美元的阈值,则通过。"""
return 1.0 if record.token_cost < 0.005 else 0.0
def grade_rag_retrieval(record: V1EvaluationRecord) -> float:
"""代理评分器:一个简单的检查,用于查看RAG系统是否检索到关键上下文。"""# 这是针对我们特定测试用例的基于规则的检查。# 更高级的版本可以使用大语言模型(LLM)来查看检索到的上下文是否相关。if "receipt_5" in record.sample_id:# 对于带有 'X' 的样本,我们是否获取到了 'void' 策略?if any("Policy 5.4" in p for p in record.retrieved_policies):return 1.0else: return 0.0 返回 1.0 # 不适用于其他样本,因此它们默认通过。这套全新的评分器不仅关注正确性。grade_latency和grade_cost确保我们的生产服务水平目标(SLO)得以实现,明确了我们所认为的"足够快"和"足够便宜"的标准。grade_rag_retrieval评分器是一项特定于代理的测试。它通过验证关键的"无效"策略是否被检索到,来检查我们V1架构的一个关键组件------RAG系统------在最复杂的测试用例中是否按预期运行。
为了捕捉这些新数据,我们需要一个"可测量"版本的V1管道运行器,它能在输出代理预测结果的同时测量并返回这些操作指标。
python
# 我们需要一个新的管道运行器来捕获并返回这些新指标。
async def run_v1_pipeline_for_eval(image_path: Path):
"""V1管道的一个可测量版本,用于测量延迟和成本。"""
start_time = time.time()
# --- 这与run_v1_pipeline函数的核心逻辑相同 ---
extracted_details = await v1_extract_details(image_path)
# 注意:我们在这里重新运行检索器,以捕获其输出用于评估记录。
retrieved_policies = retrieve_relevant_policies(extracted_details)
# 在实际系统中,你会设计代理返回这个中间状态。
audit_decision = await v1_decide_audit(extracted_details)
# --- 核心逻辑结束 ---
end_time = time.time()
latency = (end_time - start_time) * 1000
# 根据模型和文本长度模拟成本。这些数字是占位符。
# 在生产环境中,你可以从 API 响应头或你的提供商的仪表盘获取此信息。
# Qwen 235B 功能强大但并非免费。
cost = 0.001 + len(image_path.read_text()) / 1000 * 0.0002 + random.uniform(0, 0.0001)
return extracted_details, audit_decision, latency, cost, retrieved_policies这个run_v1_pipeline_for_eval函数将我们的核心V1逻辑与计时和成本模拟结合在一起。这是MLOps中的常见模式:在核心应用逻辑周围创建一个"评估框架",以便在不修改核心应用本身的情况下捕获必要的指标进行分析。
在定义了我们先进的评估套件后,我们准备让我们的 V1 代理接受其最终、最严格的测试。
综合研究结果并规划下一次迭代
一切准备就绪。我们有先进的V1代理,也有完善的评估套件,其中包含运营指标和数据切片。现在是将它们结合起来进行最终评估的时候了。这将让我们全面、多维度地了解V1系统的性能,并为我们提供所需的数据,以便基于证据就其生产就绪性做出最终决策。
运行V1高级评估
首先,我们将编写编排器函数。generate_v1_predictions将在整个数据集上运行我们新配置的管道,创建一个丰富的V1EvaluationRecord对象列表。然后,run_v1_advanced_eval将针对这些记录执行我们完整的评分器套件,并且至关重要的是,按我们定义的数据切片汇总结果。
ini
async def generate_v1_predictions(image_dir: Path, ground_truth_dir: Path) -> List[V1EvaluationRecord]:
"""运行已插桩的V1管道,为高级评估生成数据。"""
records = []
image_paths = sorted(list(image_dir.glob("*.txt")))
print(f"正在为{len(image_paths)}个样本生成V1预测...")
for image_path in image_paths:
sample_id = image_path.stem
gt_path = ground_truth_dir / f"{sample_id}.json"
with open(gt_path, "r") as f:
ground_truth_data = json.load(f)
predicted_details,predicted_audit,延迟,成本,retrieved_policies=awaitrun_v1_pipeline_for_eval(image_path)
记录。append(V 1评估记录(
sample_id=sample_id,
input_content=image_pathread_text(),
predicted_details=predicted_details,
predicted_audit=predicted_audit,
reference_details=ReceiptDetails(**ground_truth_data["详情"]),
reference_audit=Audit决策(**ground_truth_data["审计"]),
latency_ms=latency,
token_cost=cost,
retrieved_policies=retrieved_policies
))
print(f"已处理 {image_path.name}")
print("已完成生成V1预测。")
return records
# 定义完整的V1评分器套件,包括我们的新评分器。
v1_grader_suite = {
"准确性/最终决策": grade_final_audit_decision,
"准确性/推理质量": grade_reasoning_quality,
"准确性/RAG检索": grade_rag_retrieval,
"运营/延迟 < 500ms": grade_latency,
"运营/成本 < $0.005": grade_cost,
}
异步 定义 run_v1_advanced_eval(数据集: List[V1EvaluationRecord], 套件: dict, 切片: dict):
"""运行完整的评分器套件,并按数据切片汇总结果。"""
# 首先,对所有样本运行所有评分器,以获得详细的逐样本报告。
all_results = []
for record in dataset:
sample_scores = {"sample_id": record.sample_id}
for name, func in suite.items():
score = await func(record) if asyncio.iscoroutinefunction(func) else func(record)
sample_scores[name] = score
all_results.append(sample_scores)
results_df = pd.DataFrame(all_results).set_index("sample_id")
# 然后,为每个定义的切片计算汇总统计信息(通过率)。
summary = {}
for slice_name, sample_ids in slices.items():
slice_df = results_df.loc[sample_ids]
summary[slice_name] = slice_df.mean()
summary_df = pd.DataFrame(summary)
return results_df, summary_df这些编排功能是我们评估流程的核心。它们确保每个样本都针对每个评分器进行测试,并且结果被整齐地组织起来,首先按样本逐个整理,然后汇总成我们富有洞察力的切片摘要。
现在,让我们执行完整运行。
scss
# 使用操作指标生成新数据集。
v1_eval_dataset = await generate_v1_predictions(IMAGE_DIR, GROUND_TRUTH_DIR)
# 根据我们新的、更详细的记录获取数据切片。
data_slices = get_data_slices(v1_eval_dataset)
# 运行完整评估。
v1_results_df, v1_summary_df = await run_v1_advanced_eval(v1_eval_dataset, v1_grader_suite, data_slices)
print("--- V1逐样本结果 ---")
display(v1_results_df)
print("\n--- V1按数据切片的总结 ---")
display(v1_summary_df)执行过程需要一些时间,因为它会多次调用我们强大的Qwen-235B模型。输出将是两个DataFrame:详细的每个样本结果和最终的切片摘要。
css
######## 输出 ########
生成5个样本的V1预测...
[工具调用]:计算[35.0,2.8]的总和。
[RAG猎犬]:搜索与相关的政策:'壳加油站无铅汽油'
[RAG猎犬]:找到了"气体"的 相关政策
...
处理receipt_5. txt
完成生成V1预测。
---V1每样本结果---让我们来理解一下我们V1方法的输出。
-
准确率堪称完美:我们的 V1 系统在所有数据切片的所有准确率指标上均达到了100% 的通过率。工具使用和 RAG 功能的添加完全修复了 V0 系统中的错误。在这个测试集上,我们的误报率和漏报率现在均为 0%。
-
新问题浮现:然而,我们的运营指标揭示了一个关键的新问题。操作/延迟 < 500 毫秒分级器的通过率为 0%。我们使用非常大模型的更复杂、多步骤的代理对于实时正式生产环境来说太慢了。
与业务成本的关联:
让我们用V1性能更新我们的成本模型。我们将假设强大的Qwen模型每张收据的平均成本约为0.0012美元(这是一个粗略的估计)。在FP率和FN率均为0%的情况下,业务影响是显而易见的。
bash
v1_system_cost = calculate_business_cost(fp_rate=0.0, fn_rate=0.0, per_receipt_processing_cost=0.0012)
print(f"V1 AI系统成本: ${v1_system_cost:,.2f}")
print(f"与人工流程相比的年度节省: ${current_system_cost - v1_system_cost:,.2f}")
########## 输出 ##########
V1 AI系统成本: $101,200.00
与人工流程相比的年度节省: $278,800.00下一迭代计划:我们已经实现了准确性目标,预计每年为公司节省278,800美元 。下一开发周期的优先级很明确:降低延迟。
假设:我们可以创建一个路由代理。对于简单的收据(例如,长度在一定范围内、无手写内容),我们可以使用快速、低成本的Llama-3.1-8B-Instruct模型,并跳过检索增强生成(RAG)步骤。对于路由标记为复杂的收据,我们可以使用完整、强大(但速度较慢)的Qwen-235B管道。这种混合方法,通常被称为"专家混合",应在保持准确性的同时显著改善平均延迟。
这一步骤,包括构建路由器和创建新的V2评估记录来跟踪选择了哪条路径,完美地展示了评估驱动开发的持续循环。我们不仅利用评估数据来验证成功,还利用它来确定下一个最具影响力的改进领域。