📚大模型框架系列文章
知识管理与 RAG 框架全景:从 LlamaIndex 到多框架集成
随着大模型在企业场景中广泛应用,Serverless 架构因其按需弹性伸缩、免运维管理和成本优化的特点,成为大模型落地的理想选择。在 Serverless 环境中,可以实现大模型推理的高并发处理,同时降低资源浪费和运维成本。
本篇文章将系统介绍Serverless 架构与大模型框架的结合方式、高性能推理与动态扩缩容实践和多模型协作与知识增强生成(RAG)在 Serverless 下的应用。
所有相关源码示例、流程图、模型配置与知识库构建技巧,我也将持续更新在Github:LLMHub,欢迎关注收藏!
希望大家带着下面的问题来学习,我会在文末给出答案:
- Serverless 架构如何支撑大模型推理?
- 如何在 Serverless 环境下实现高性能和弹性伸缩?
- Serverless 下的多模型协作与 RAG 实践有哪些经验?
1. Serverless 架构概述
Serverless 是一种无需管理服务器的计算模式,云厂商按需分配计算资源。关键特点:
- 按需计费:只为实际使用的计算量付费
- 弹性伸缩:自动根据请求量扩展实例
- 免运维管理:无需关注底层服务器部署与监控
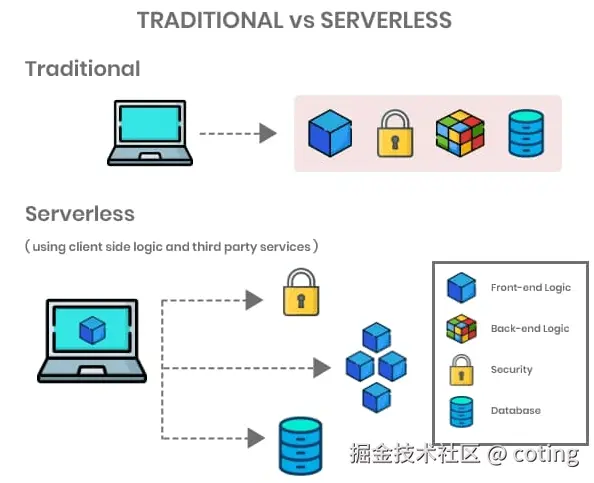
在大模型落地中,Serverless 可以:
- 将推理任务拆分为独立函数
- 弹性调度 GPU/CPU 资源
- 与微服务架构结合,实现多模型协作
2. Serverless 大模型框架落地
以 vLLM + LangChain + 向量数据库 为例,实现 Serverless 架构下的高性能推理。
2.1 函数化推理
将每个模型调用封装为一个 Serverless 函数(Function-as-a-Service,FaaS)。
示例代码(Python + AWS Lambda):
python
# lambda_function.py
import json
from vllm import LLM, SamplingParams
# 每个推理请求触发 Lambda 函数,实现按需弹性计算。
llm = LLM(model="huggingface/gpt-j-6B")
def lambda_handler(event, context):
prompt = event.get("prompt", "")
result = llm.generate([prompt], sampling_params=SamplingParams(max_output_tokens=100))
return {
"statusCode": 200,
"body": json.dumps({"text": result[0].text})
}2.2 弹性伸缩与高并发
Serverless 平台(如 AWS Lambda、Azure Functions、FunctionGraph)自动根据请求量扩容,无需人工干预。
- 批量处理:多个请求合并为批次,提高 GPU 利用率
- 异步触发:支持消息队列(SQS、Kafka)异步调度
- 冷启动优化:预热实例或使用容器复用策略
示例代码(异步批量处理):
python
import asyncio
from vllm import LLM, SamplingParams
# 异步批量执行充分利用弹性资源,同时降低延迟。
model = LLM(model="huggingface/gpt-j-6B")
prompts = ["Hello!", "How are you?", "Tell me a joke."]
async def async_generate(prompt):
return await model.agenerate([prompt], sampling_params=SamplingParams(max_output_tokens=50))
results = asyncio.run(asyncio.gather(*(async_generate(p) for p in prompts)))
for res in results:
print(res[0].text)2.3 多模型协作与路由
在 Serverless 下,可通过 LangChain Agent 动态路由不同模型处理任务:
- 高优先级或复杂任务分配大模型
- 简单任务分配轻量模型
- 同时支持检索增强生成(RAG)
示例代码(多模型路由):
python
from langchain.agents import initialize_agent, Tool
from langchain.llms import OpenAI
# Serverless 下,每个工具可独立部署,支持高并发和多模型协作。
# 定义不同模型工具
tools = [
Tool(name="LargeModel", func=lambda q: OpenAI(model_name="text-davinci-003")(q), description="Complex tasks"),
Tool(name="SmallModel", func=lambda q: OpenAI(model_name="gpt-3.5-turbo")(q), description="Simple tasks")
]
agent = initialize_agent(tools, llm=None, agent="zero-shot-react-description", verbose=True)
# 动态路由任务
agent.run("Explain quantum physics in simple terms")
agent.run("Write a funny joke")2.4 知识增强生成(RAG)实践
Serverless 架构结合 LlamaIndex 或 Haystack,实现向量数据库检索增强生成:
- 用户请求触发函数
- 检索向量数据库返回相关文档
- 生成函数结合上下文输出答案
示例代码(Serverless + RAG):
python
from llama_index import GPTVectorStoreIndex, SimpleDirectoryReader
from langchain.llms import OpenAI
# Serverless + RAG 实现知识增强生成,保证生成内容准确、实时。
# 构建向量索引
documents = SimpleDirectoryReader("docs/").load_data()
index = GPTVectorStoreIndex.from_documents(documents)
def handler(event, context):
query = event.get("query")
context_text = index.query(query).response
llm = OpenAI()
answer = llm(f"Answer using context: {context_text}\nQuestion: {query}")
return {"answer": answer}3. Serverless 架构下的优化策略
- 延迟优化:异步执行、批量推理、冷启动预热
- 吞吐量提升:多函数并行、流水线化推理、异构硬件调度
- 成本控制:按需计费、轻量模型优先、动态资源调度
结合这些策略,Serverless 架构可实现高并发、低延迟和成本可控的大模型应用。
最后,我们回答文章开头的问题
- Serverless 架构如何支撑大模型推理?
将模型调用封装为函数(FaaS),平台按需分配计算资源,实现弹性伸缩和高并发。 - 如何在 Serverless 环境下实现高性能?
通过异步批量处理、多模型并行、流水线化推理以及硬件异构调度。 - Serverless 下多模型协作与 RAG 实践有哪些经验?
利用 LangChain Agent 动态路由任务,结合向量数据库实现知识增强生成,实现高吞吐量和低延迟。
关于深度学习和大模型相关的知识和前沿技术更新,请关注公众号 coting!
以上内容参考 LangChain、vLLM、LlamaIndex 以及 Serverless 平台文档,如有侵权请联系删除。