作者介绍:简历上没有一个精通的运维工程师。请点击上方的蓝色《运维小路》关注我,下面的思维导图也是预计更新的内容和当前进度(不定时更新)。
中间件,我给它的定义就是为了实现某系业务功能依赖的软件,包括如下部分:
Web服务器
代理服务器
ZooKeeper
Kafka
RabbitMQ
Hadoop HDFS(本章节)
1. HDFS 写数据流程
当客户端需要向HDFS写入数据时,会经历以下步骤:
1.1 客户端请求写入文件
-
客户端调用
FileSystem.create()方法,向NameNode发起创建文件的请求。 -
NameNode检查目标文件是否存在,以及客户端是否有写入权限。
-
如果文件已存在或权限不足,则抛出异常。
-
如果检查通过,NameNode在元数据中创建文件记录(此时文件大小为0)。
1.2 NameNode分配DataNode
- NameNode根据副本放置策略(默认3副本)选择一组DataNode,用于存储数据块。
-
第一副本:优先写入客户端所在的节点(若客户端不在集群,则随机选一个)。
-
第二副本:放在与第一副本不同机架的节点上(提高容错能力)。
-
第三副本:放在与第二副本相同机架的另一个节点上(平衡存储和网络开销)。
- NameNode返回一个DataNode列表(按距离排序,如:DN1、DN2、DN3)给客户端。
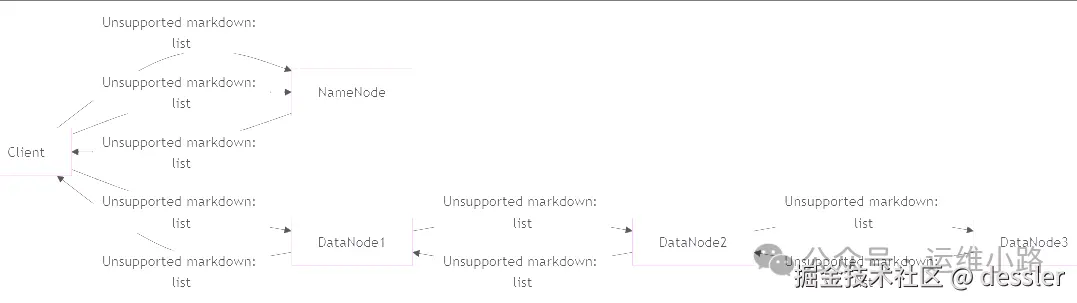
1.3 建立数据写入管道(Pipeline)
-
客户端与第一个DataNode(DN1)建立连接,DN1再连接DN2,DN2连接DN3,形成数据写入管道(Pipeline)。
-
数据以**数据包(Packet,默认64KB)**的形式传输,并缓存在客户端的内存中。
1.4 数据分块传输与ACK确认
- 客户端开始发送数据包:
-
数据包先发送到DN1,DN1存储后转发给DN2,DN2再转发给DN3。
-
每个DataNode存储数据后,会向上游节点发送ACK确认。
-
当客户端收到所有DataNode的ACK后,才认为该数据包写入成功。
- 当一个数据块(默认128MB)写满后,DataNode会向NameNode汇报块信息(Block Report),并等待新的写入指令。
1.5 关闭写入流
-
客户端完成所有数据写入后,调用
close()方法关闭流。 -
NameNode确认文件写入完成,更新元数据(如文件大小、块信息等)。
2. HDFS 读数据流程
当客户端需要从HDFS读取数据时,流程如下:
2.1 客户端请求读取文件
-
客户端调用
FileSystem.open()方法,向NameNode请求读取文件。 -
NameNode检查文件是否存在,并返回:
-
文件元数据(如块列表、副本位置)。
-
每个数据块所在的DataNode地址(按网络拓扑排序,优先返回最近的节点)。
2.2 客户端直接连接DataNode读取数据
-
客户端根据NameNode返回的DataNode列表,选择最近的DataNode建立连接。
-
DataNode将数据块以数据包(Packet)形式传输给客户端。
-
客户端按顺序读取所有数据块,并在本地合并成完整文件。
2.3 容错机制(读取失败时)
-
如果某个DataNode读取失败,客户端会自动尝试从其他副本读取。
-
如果所有副本均不可用,客户端会向NameNode报告,NameNode可能触发数据恢复机制。
运维小路
一个不会开发的运维!一个要学开发的运维!一个学不会开发的运维!欢迎大家骚扰的运维!
关注微信公众号《运维小路》获取更多内容。