前面的章节基本上已经把流水线基本模板都做出来了,现在Jenkinsfile已经都放置在了git上进行统一管理,但是每次新建流水线的时候都要去复制粘贴一份那么长的流水线实在太长了,可读性也不是很好,所以这次将一些流水线中共性的东西抽离到共享库中,以减少流水线中的冗余代码,同时也能增强复用性。
1. 共享库创建
1.1 目录结构
bash
# 这里的目录结构src vars resource是参考官方建立的
tree ops-share-librarya
├── Ansible # Ansible部署脚本
├── Jenkinsfile # 用于存放流水线
├── Readme.md
├── resources # 一般用于存放静态资源文件,这些文件可以在构建或运行时被访问和使用
│ ├── config
│ ├── Readme.md
│ ├── scripts
│ ├── static
│ └── templates
├── src # 业务逻辑一般都在这里编写
│ └── org
│ └── devops
└── vars # 定义全局变量和函数,这些变量和函数可以在不同的 Jenkins Pipeline 中共享和重用。
└── Readme.md1.2 Jenkins引用Git上的共享库资源
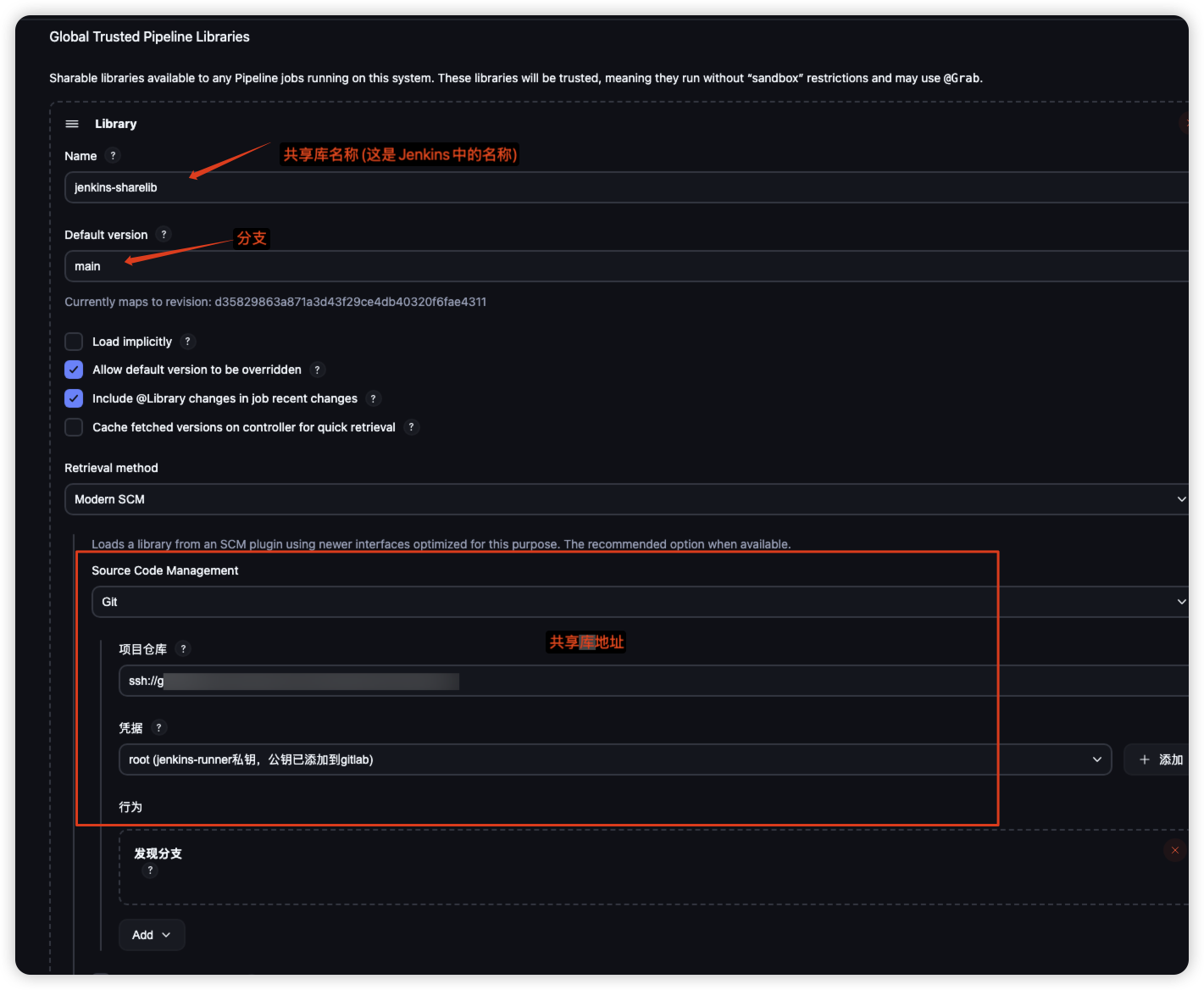
image-20250922105847114
2.定义方法&引用
2.1 直接定义方法并在jenkins中引用
bash
//在代码库中创建一个测试方法
//src/org/devops/test.groovy
package org.devops
def PrintMes(){
println "PrintMes"
}
def PrintError(){
println "PrintError"
}
//JenkinsPipeline中引用
@Library('ops-share-librarya@master') _ //引入共享库
def test = new org.devops.test() //定义个对象并传入变量中
pipeline {
stages {
stage('Check requirement') {
steps {
script {
// 调用org.devops.test()也就是test中的方法
test.PrintMes()
test.PrintError()
}
}
}
}
//流水线运行结果
[Pipeline] echo
13:41:15 PrintMes
[Pipeline] echo
13:41:15 PrintError2.2 定义类并在jenkins中引用
bash
//在代码库中创建一个Utils测试类
//src/org/devops/Utils.groovy
package org.devops
class Utils {
//静态方法可以在pipeline引入后直接用类名+方法直接调用 全局为一
static def createVersionStaticId(buildId) {
return "${new Date().format('yyyyMMddHHmmss')}_${buildId}"
}
//普通方法在pipeline中引用后需要创建对象进行引用new ,不同的对象拥有自己的状态
def createVersionId(buildId) {
return "${new Date().format('yyyyMMddHHmmss')}_${buildId}"
}
}
//JenkinsPipeline中引用
@Library('ops-share-librarya@master') _ //引入共享库
import org.devops.Utils //导入测试类
pipeline {
stages {
stage('Check requirement') {
steps {
script {
//调用静态方法,注意静态方法是可以直接通过类名+方法的方式来进行调用的
//def version = Utils.createVersionStaticId(env.BUILD_ID.toString())
def version = Utils.createVersionStaticId(env.BUILD_ID)
echo "Generated version: ${version}"
//-----------------------------------------------
//调用普通方法 ,必须要先创建实例才能使用
def utils = new org.devops.Utils() // 创建 Utils 类的实例 utils
//def instanceVersionId = utils.createVersionId(env.BUILD_ID.toString())
def instanceVersionId = utils.createVersionId(env.BUILD_ID) //调用示例,传入参数来生成ID
echo "Instance Version ID: ${instanceVersionId}"
}
}
}
}
// 引用后的输出
[Pipeline] echo
14:07:53 Generated version: 20250922140753_33
[Pipeline] echo
14:07:53 Instance Version ID: 20250922140753_333.实际案例
上一章中我们在流水线中定义了Nexus的上传操作,这里我们就以这个操作来展现下共享库的好处
3.1 创建上传方法
bash
package org.devops
def NexusUpload(){
// 使用之前生成的 version 变量
nexusArtifactUploader artifacts: [
[
artifactId: 'basejar', // 替换为您的 artifactId
classifier: '',
file: 'target/spring-boot-3-hello-world-1.0.0-SNAPSHOT.jar', // 替换为您的文件路径
type: 'jar' // 根据您的文件类型进行修改
],
[
artifactId: 'basejar', // 同样的 artifactId,或根据需要修改
classifier: 'pom',
file: 'pom.xml', // 指向您的 pom.xml 文件
type: 'pom' // 文件类型为 pom
]
],
//文件file类型有jar,pom,war,zip,tar.gz
credentialsId: 'Nexus3-DevOps',
groupId: 'top.xxx',
nexusUrl: 'registryv.xxx.top',
nexusVersion: 'nexus3',
protocol: 'https',
repository: 'DevopsArtifact',
version: "v8"
}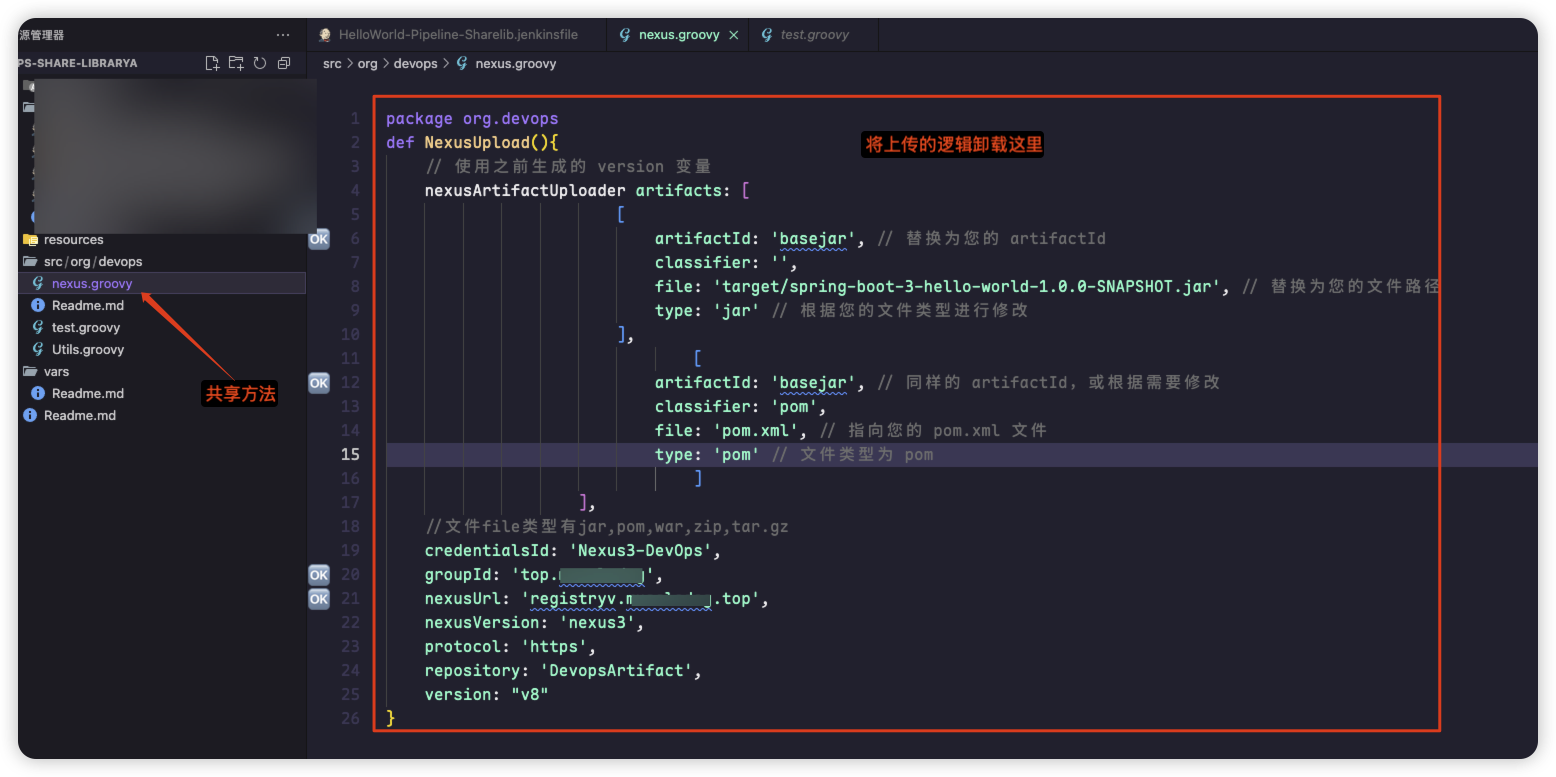
image-20250922182654605
3.2 Pipeline中引用方法
bash
#!groovy
@Library('ops-share-librarya@master') _
def createVersion() {
// 创建了一个方法createVersion()
// 定义一个时间戳+构建ID作为版本号,为tag使用
return new Date().format('yyyyMMddHHmmss') + "_${env.BUILD_ID}"
}
pipeline {
//省略......
stages {
//省略......
//调用方法
stage('Upload to Nexus') {
steps {
script {
def nexustest = new org.devops.nexus()
nexustest.NexusUpload()
}
}
}
}
post {
//省略......
}
}
image-20250922183313387
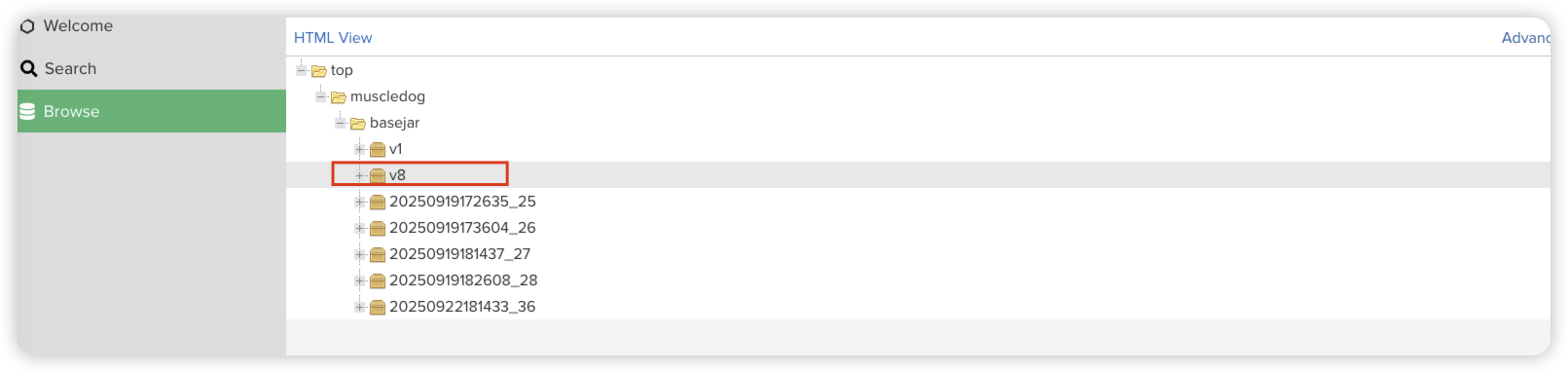
image-20250922183935203
3.3 流水线引用方法前后对比
通过对比可以看出,将流水线中一些公用的操作,抽出来作为一个方法可以减少很多不必要的重复过程,同时也能增加其他流水线的组件过程。
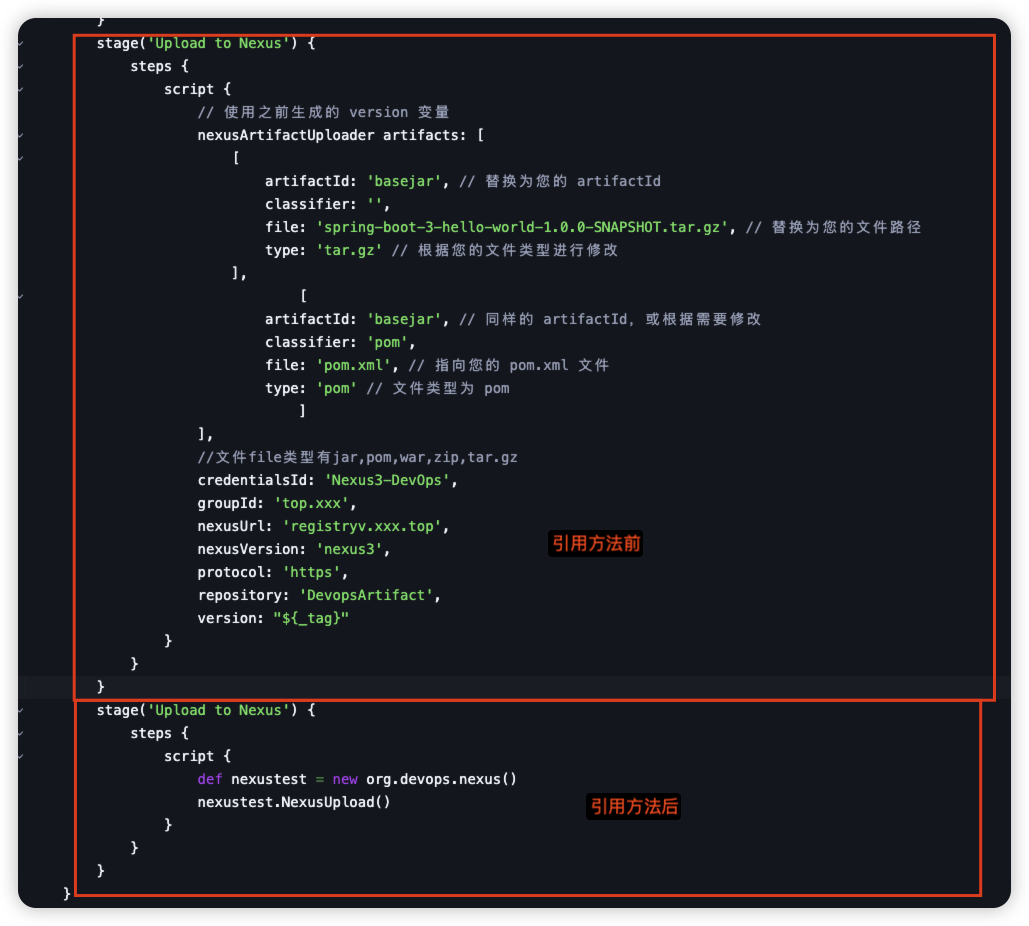
image-20250922183615676
重点说一下,这里只是展示下定义方法的好处,能够抽离一些通用的步骤作为方法,在后面的流水线中引用,减少重复编写,现在展示的里面很多的值都是固定的,如果你是要进行生产上的部署还是要有很多参数要改为变量的方式,同时你的方法可能也会需要各种传参。