本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。
一、前言
有没有遇到过这样的场景?
当你向大模型提问一些内部技术细节或特定领域的问题时,比如:
- "Zebra中间件(公司自研)如何使用?"
- "上海市2025年警务技术类人民警察的报名条件是什么?"
大模型一本正经地给出了看似合理、实则完全错误的答案。这就是所谓的「模型幻觉」。当大模型面对非公开、个性化或训练数据之外的知识时,常常会"编造"答案------不知道的就靠猜。
二、为什么模型会「胡说八道」?
简单来说,大模型博览群书,它学习过海量公共知识,但对你的私人知识一无所知,例如:
- 你公司的内部文档
- 你的个人笔记和日记
- 你的私有代码库
这些内容并不在 DeepSeek、OpenAI 等模型的训练数据中。因此,当你提出这类问题时,模型只能靠"推测"来回应------这正是幻觉的根源。
三、如何解决模型幻觉问题?
解决幻觉问题通常有两种方式:
- 微调模型(Fine-tuning):让模型重新学习你的知识
- RAG技术:在不改变模型的情况下增强知识
微调可以解决模型幻觉问题,但部署并微调一个大模型,对企业和个人来说成本非常高,如果退而求其次,微调一个小一点的模型,大概率效果又不好。
四、什么是RAG
RAG(Retrieval Augmented Generation)的核心流程分为三步:
- 检索(Retrieval):当用户提问时,系统会从外部的知识库中检索出跟用户输入相关的内容
- 增强(Augmented):系统将检索到的信息与用户的输入结合,扩展模型的上下文,然后再传给生成模型(如DeepSeek、ChatGPT)
- 生成(Generation):生成模型基于增强后的输入生成最终的回答,由于这一回答参考了知识库中的内容,因此更加准确。
五、Embedding:为什么需要Embedding模型?
Embedding的作用是将自然语言转化为机器可以理解的高维向量,并通过这一过程捕获到文本背后的语义信息,进而理解不同文本之间的相似度关系。
在RAG执行检索流程时,
① 通过Embedding模型,对知识库文件进行解析,生成一个高维向量;
② 同时通过Embedding模型,对用户提问进行处理,生成一个高维向量;
③ 拿用户的提问去匹配本地知识库,系统利用某些相似度度量(如余弦相似度 cosin similarity)去判断相似度。
比如,"汉语"和"英语" Embedding后,会映射到非常相近的向量空间中;深度学习会被映射到比较远的向量空间中。
六、实战搭建:DeepSeek + RAGFlow构建个人知识库
- DeepSeek:国产大模型,性能强劲
- RAGFlow:基于深度文档理解的RAG引擎,开源且易用
📌 搭建步骤:
- 准备知识文档
- 年度旅行日记(Markdown)
- 个人技术笔记(PDF)
- 项目文档(Word)
-
部署 RAGFlow(基于docker) RAGFlow 提供详细 GitHub文档(github.com/infiniflow/...):
① 下载RAGFlow源代码
shell$ git clone https://github.com/infiniflow/ragflow.git② 配置自带 Embedding 模型的RAGFlow image tag
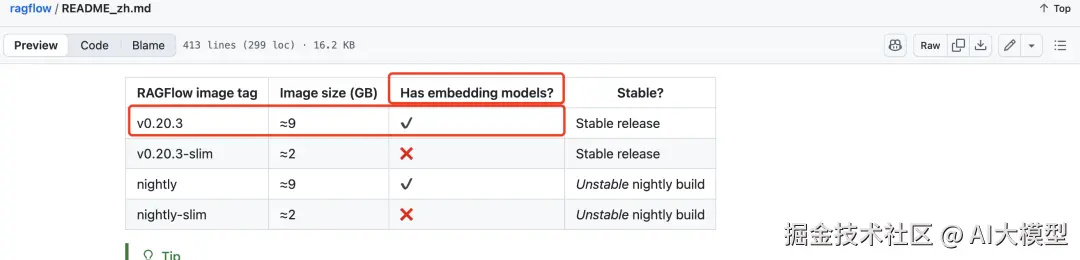
RAGFlow 提供了两种版本选择:一种内置了 embedding 模型,另一种则不内置。
如果本地有可用 embedding 模型,建议选择不内置模型的版本以节省资源;若本地没有可用模型,只需在配置文件(ragflow/docker/.envi)中指定使用内置模型版本即可。
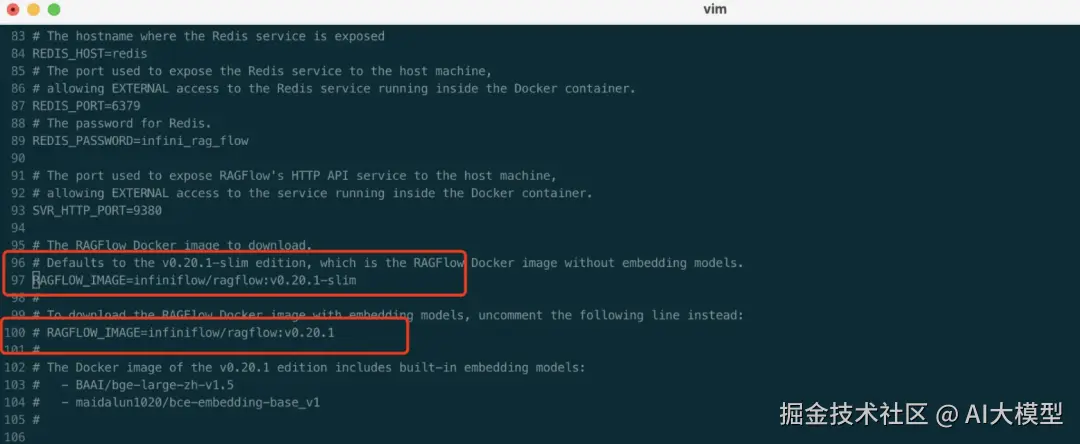
③进入 docker 文件夹,利用提前编译好的 Docker 镜像启动服务器:
shell$cd ragflow/docker首次启动拉镜像的时间有点长,
可以看到,RAGFlow 需要ES、Redis等环境,文档解析后需要存储,docker 的集装箱环境帮我们省去了繁琐的环境配置。

启动成功

-
访问与配置
-
访问 http://localhost:80(默认端口80,首次登录先注册)
-
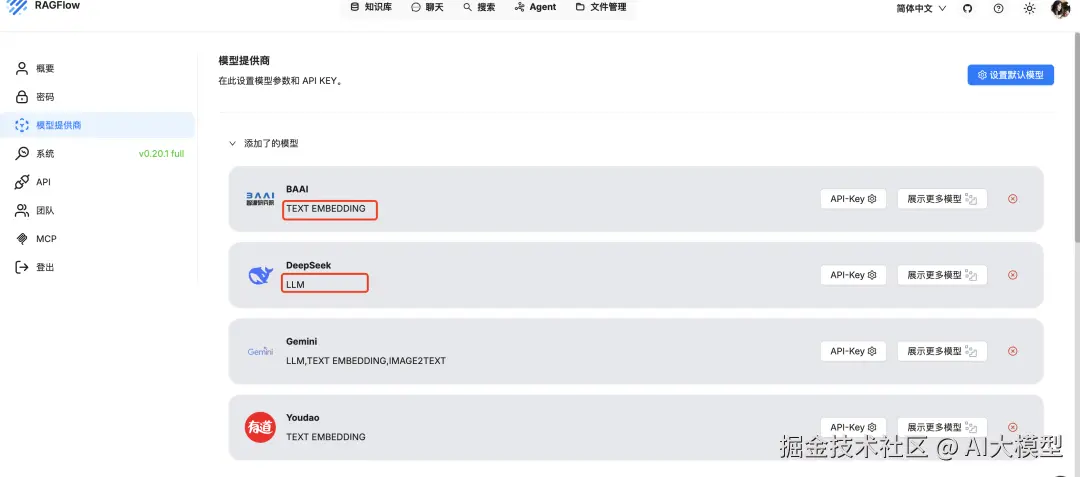
在设置中配置 Chat 模型(如 DeepSeek API 或本地 Ollama)和 Embedding 模型(RAGFlow自带)。
- 创建知识库与上传文档
-
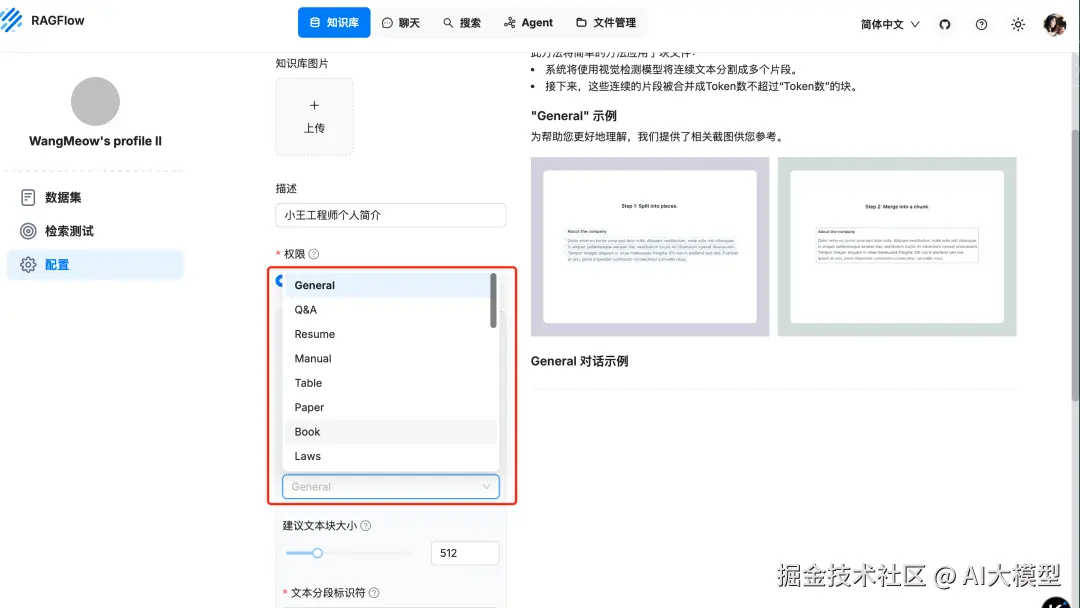
新建知识库,解析方法建议选"General",还可以选择专门解析书籍、简历、论文的其他模式
-
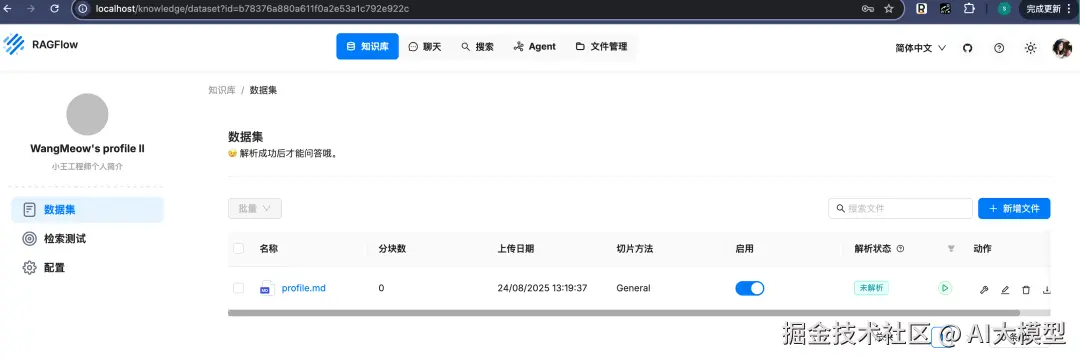
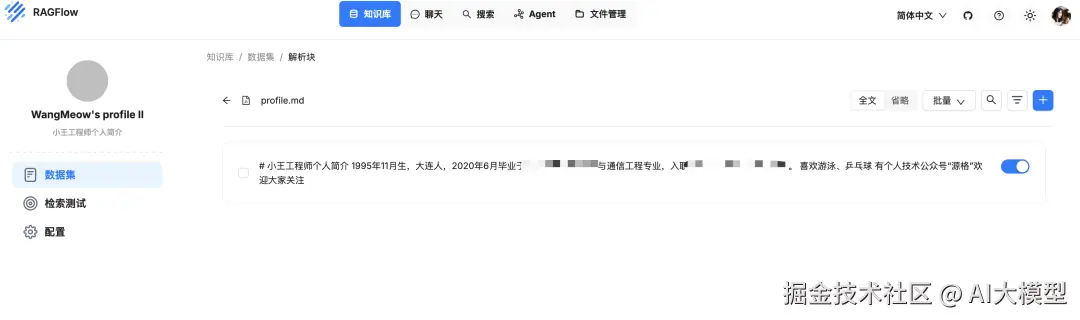
上传文档后点击"解析",Embedding 模型将自动提取文本块
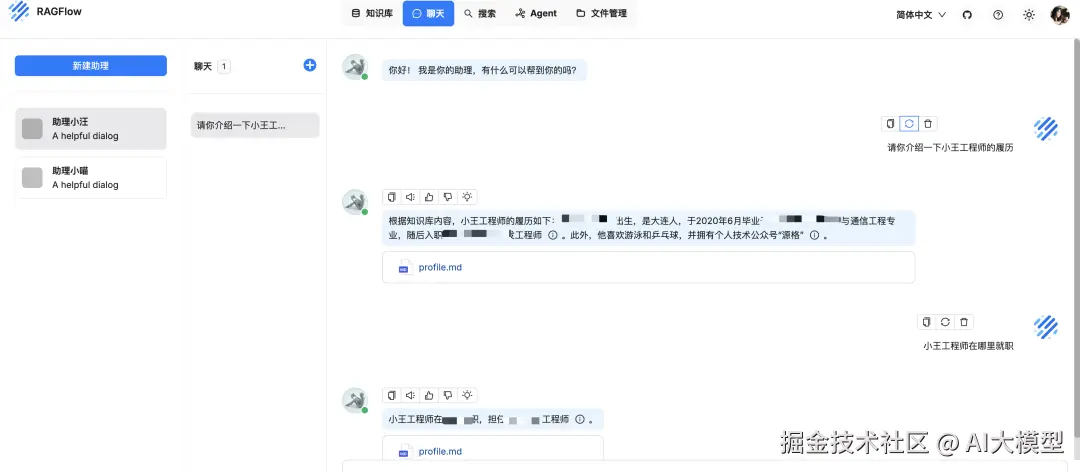
- 提问测试
-
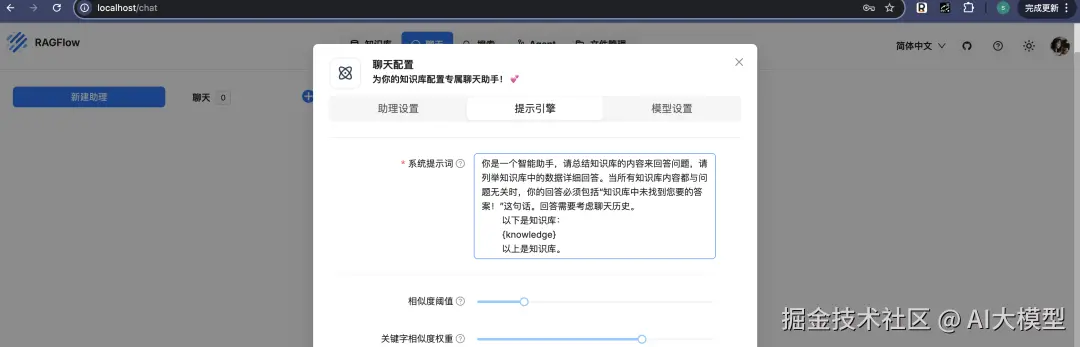
关联知识库并设置 System Prompt
-
现在你可以提问了!模型将基于你的文档返回准确答案
七、温馨提示 & 常见问题
✅ 建议 Docker 内存至少 12GB、Swap 建议 2GB
✅ 若操作卡顿或失败,可查看日志:
vbscript
docker logs -f ragflow-server✨ 总结
使用 DeepSeek + RAGFlow,你可以在不到一小时内(如果顺利的话)搭建起一个真正"懂你"的个人知识库助手。无需训练大模型,也能高效、低成本地解决幻觉问题。
如果你也希望大模型能真正理解你的"私有知识",不妨试试这个方案!
学习资源推荐
如果你想更深入地学习大模型,以下是一些非常有价值的学习资源,这些资源将帮助你从不同角度学习大模型,提升你的实践能力。
本文较长,建议点赞收藏。更多AI大模型应用开发学习视频及资料,在智泊AI。