苹果新品发售的热度尚未消退,大众仍在热议新一代手机的硬件升级。然而在AI功能方面,苹果依然未能带来颠覆性的应用,尤其在国内市场,Apple Intelligence 的落地仍显得遥遥无期。
加之近期苹果AI团队与硬件部门接连出现人才流失,整体形势对苹果而言似乎并不乐观。
尽管苹果在大模型领域屡屡受挫,但有一个容易被忽略的事实:计算机视觉一直是苹果的传统强项。在构建视觉相关的大模型时,研究者面临一个显著瓶颈:视觉模态涵盖图像、视频和三维数据,它们具有不同的数据维度与表征方式,导致研究过程中往往需要分别处理,使得视觉模型被割裂为三个相对独立的领域,难以实现视觉认知的统一与泛化。
相比之下,大语言模型已借助统一的处理方案展现出强大的跨任务泛化能力。而当前视觉AI的发展仍呈割裂状态,不同任务与模态依赖专门化模型,其处理器通常仅针对高保真重建或语义理解中的单一目标优化,鲜有兼顾两者。
针对这一核心问题,Apple研究团队提出了ATOKEN(A Unified Tokenizer for Vision) ,首次实现了对所有主要视觉模态的统一处理,并在重建质量与语义理解之间取得了平衡。这一进展标志着我们在构建通用、强泛化能力的视觉表征方面迈出了关键一步。
ATOKEN
本文提出ATOKEN ------ 一种通用视觉处理器,在图像、视频和3D领域同时实现高保真重建与丰富语义理解。模型通过渐进式编码学习统一表征:语义嵌入用于理解任务,低维连续潜在表征用于生成任务,量化后的离散表征则支持多样化应用。如图1所示,该设计为无缝处理全视觉模态理解与生成任务的新一代多模态系统奠定基础。

核心贡献总结如下:
- 首款跨模态与任务的统一视觉处理器: 首个在图像、视频和3D资产上同时实现高保真重建与语义理解的处理器,支持连续/离散表征的统一框架
- 稀疏4D表征与纯Transformer架构: 通过时空块嵌入与4D旋转位置编码构建统一4D潜在空间,各模态自然占据相应子空间,支持原生分辨率与时序处理
- 无对抗训练实现稳定优化: 结合感知损失与Gram矩阵损失,无需对抗训练即达到顶尖重建质量,攻克基于Transformer的视觉处理器训练稳定性难题
- 跨模态渐进式训练课程: 四阶段训练策略在保持强性能的同时实现稳定学习,添加视频/3D能力后图像重建质量仍保持提升
- 下游应用的全方位实证验证: ATOKEN在所有模态取得竞争性表现,支持从多模态大语言模型到图生3D的多样化应用,验证其作为通用视觉基石的有效性
实验结果
- 图像处理
我们通过重建质量(表4)和语义理解(表5)基准,将ATOKEN的图像能力与专用处理器进行比较。
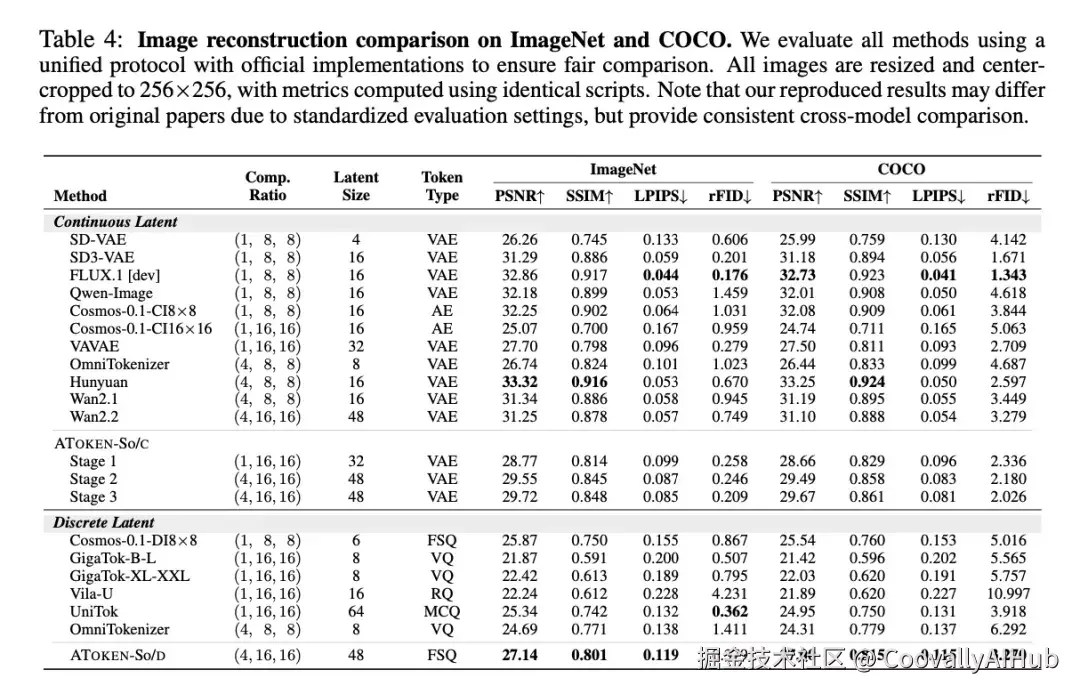
重建性能: 在标准化评估协议下,我们观察到多模态训练增强而非损害了图像重建。ATOKEN-So/C在16×16压缩下达到0.209 rFID,并随训练阶段逐步提升,通过多模态扩展获得了19%的提升。
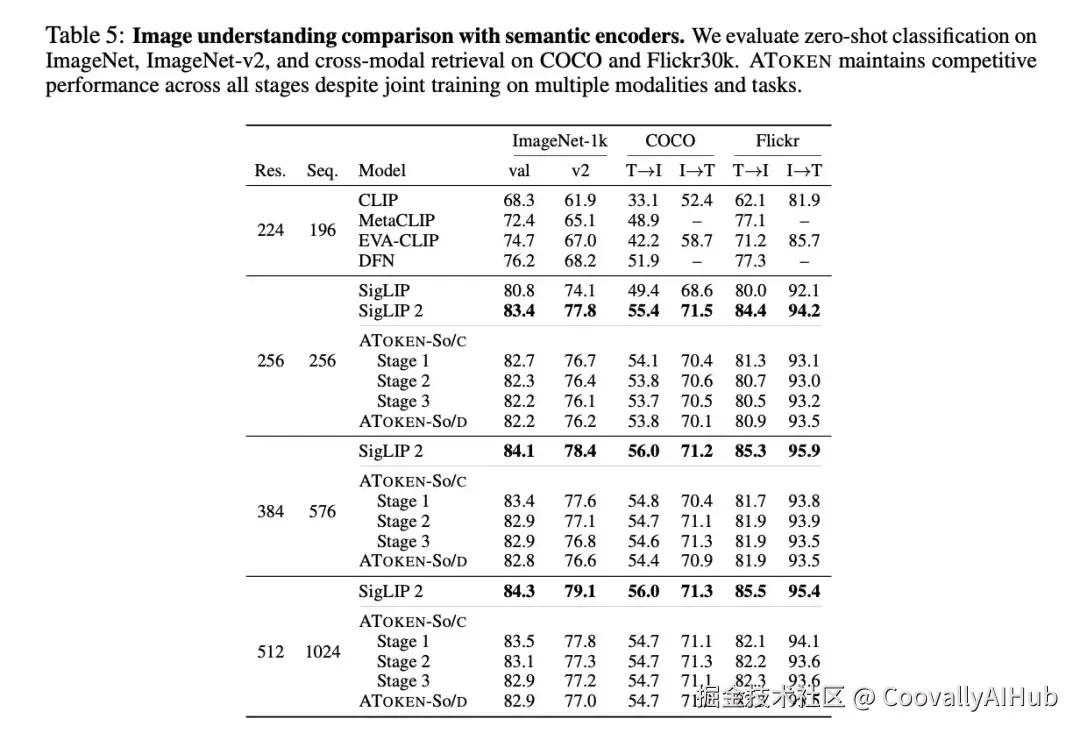
语义理解: 尽管ATOKEN需要平衡三种模态的理解与重建,但仍达到了82.2%的ImageNet准确率------与仅理解的SigLIP2(83.4%)仅差1.2%。

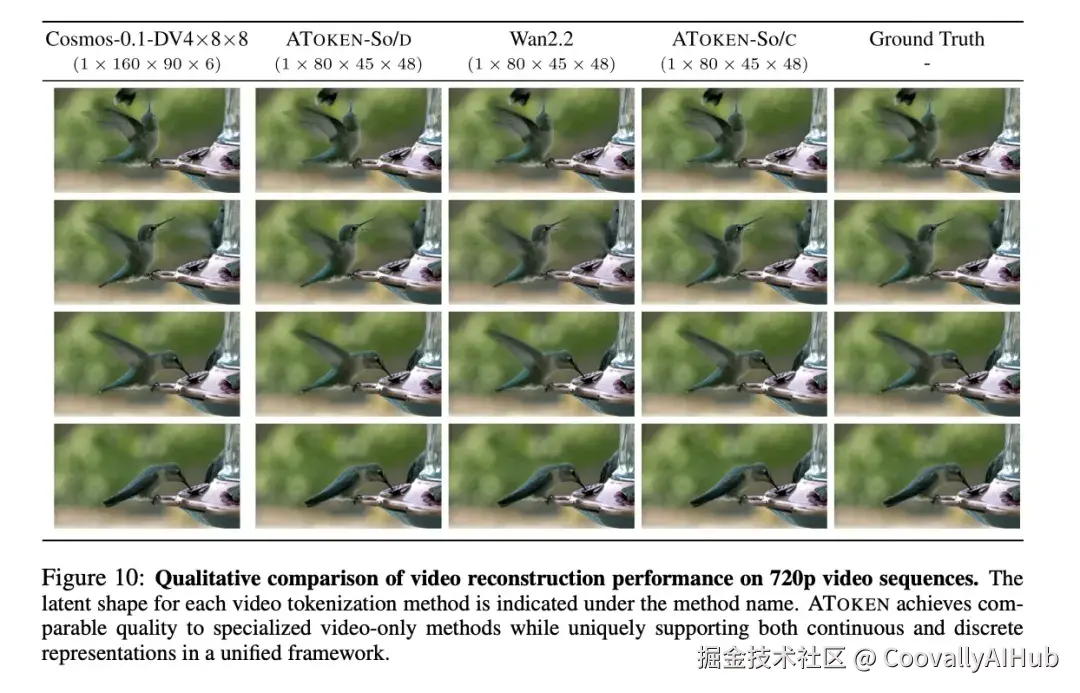
- 视频处理
我们通过重建质量和语义理解基准评估ATOKEN的视频能力,展示了有竞争力的性能,并独特地支持多模态的连续和离散表征。
重建性能: 在DAVIS和TokenBench上评估。ATOKEN-So/C在DAVIS上达到33.11 PSNR,在 TokenBench上达到36.07 PSNR,接近专用视频模型。
语义理解: 在MSRVTT和MSVD上评估零样本视频-文本检索。ATOKEN在MSRVTT上达到40.2% R@1,在MSVD上达到53.5%,尽管主要优化三种模态的重建,仍保持了合理的语义对齐。
- 3D资产处理
我们在Toys4k上评估ATOKEN的3D重建和语义理解能力。对于重建,ATOKEN-So/C达到28.28 PSNR和0.062 LPIPS,超越了专用的Trellis-SLAT基线。这表明我们的统一4D表征有效捕捉了几何结构,无需专用3D架构。对于语义理解,ATOKEN-So/C在Toys4k上达到90.9%的零样本分类准确率。

下游结果则全面验证了ATOKEN作为统一视觉处理器的有效性和通用性。核心结论是:一个单一的ATOKEN模型,无需针对特定任务进行修改,就能作为多种下游理解与生成任务的强大基石,且性能具有竞争力。
总结
ATOKEN在多种模态和任务上的有效性预示着新的机遇:视觉处理化可以实现曾彻底改变语言建模的同一性。我们的单一框架在图像、视频和3D资产上同时实现了高保真重建和语义理解。这种集成通过结合我们的稀疏4D表征、基于Transformer的架构、无对抗训练策略和渐进式多模态课程得以实现。由于计算资源有限,我们仅在独立的下游任务上测试了ATOKEN。构建能够展示ATOKEN全部潜力的全面全能模型,仍是未来的工作。展望未来,ATOKEN为视觉基础模型开辟了道路,使其能够遵循语言建模的发展轨迹,迈向真正的通用化。我们希望这项工作能为基于统一视觉处理化的下一代多模态AI系统指明方向。