文章目录
- [Linux RAID 存储技术](#Linux RAID 存储技术)
-
- 环境准备
- [RAID 技术历史](#RAID 技术历史)
- [RAID 实现方式](#RAID 实现方式)
- [RAID 级别](#RAID 级别)
- [管理软 RAID](#管理软 RAID)
Linux RAID 存储技术
参考:来源1
环境准备
虚拟机添加6块20G 硬盘,sdb sdc sdd sde sdf sdg(接口都要和原来一样)
RAID 技术历史
1988 年美国加州大学伯克利分校的 D. A. Patterson 教授等人首次在论文 "A Case of Redundant Array of Inexpensive Disks" 中提出了 RAID 概念 ,即廉价磁盘冗余阵列 ( Redundant Array of Inexpensive Disks )。由于当时大容量磁盘比较昂贵, RAID 的基本思想是将多个容量较小、相对廉价的磁盘进行有机组合,从而以较低的成本获得与昂贵大容量磁盘相当的容量、性能、可靠性 。随着磁盘成本和价格的不断降低 , RAID 可以使用大部分的磁盘, "廉价" 已经毫无意义。因此, RAID 咨询委员会( RAID Advisory Board, RAB )决定用 " 独立 " 替代 " 廉价 " ,于时 RAID 变成了独立磁盘冗余阵列( Redundant Array of Independent Disks )。但这仅仅是名称的变化,实质内容没有改变。
RAID 实现方式
从实现角度看, RAID 主要分为:
- 软 RAID:所有功能均有操作系统和 CPU 来完成,没有独立的 RAID 控制 / 处理芯片和 I/O 处理芯片,效率最低。
- 硬 RAID :配备了专门的 RAID 控制 / 处理芯片和 I/O 处理芯片以及阵列缓冲,不占用 CPU 资源,成本很高。
- 软硬混合 RAID:具备 RAID 控制 / 处理芯片,但缺乏 I/O 处理芯片,需要 CPU 和驱动程序来完成,性能和成本在软 RAID 和硬 RAID 之间。
RAID 级别
RAID 主要利用数据条带、镜像和数据校验技术来获取高性能、可靠性、容错能力和扩展性,根据运用或组合运用这三种技术的策略和架构,可以把 RAID 分为不同的等级,以满足不同数据应用的需求。 D. A. Patterson 等的论文中定义了 RAID1 ~ RAID5 原始 RAID 等级, 1988 年以来又扩展了 RAID0 和 RAID6 。
近年来,存储厂商不断推出诸如 RAID7 、 RAID10/01 、 RAID50 、 RAID53 、 RAID100 等 RAID 等级,但这些并无统一的标准。目前业界公认的标准是 RAID0 ~ RAID5 ,而在实际应用领域中使用最多的 RAID 等级是 RAID0 、 RAID1 、 RAID4 、 RAID5 、 RAID6 和 RAID10。
RAID 每一个等级代表一种实现方法和技术,等级之间并无高低之分。在实际应用中,应当根据用户的数据应用特点,综合考虑可用性、性能和成本来选择合适的 RAID 等级,以及具体的实现方式。
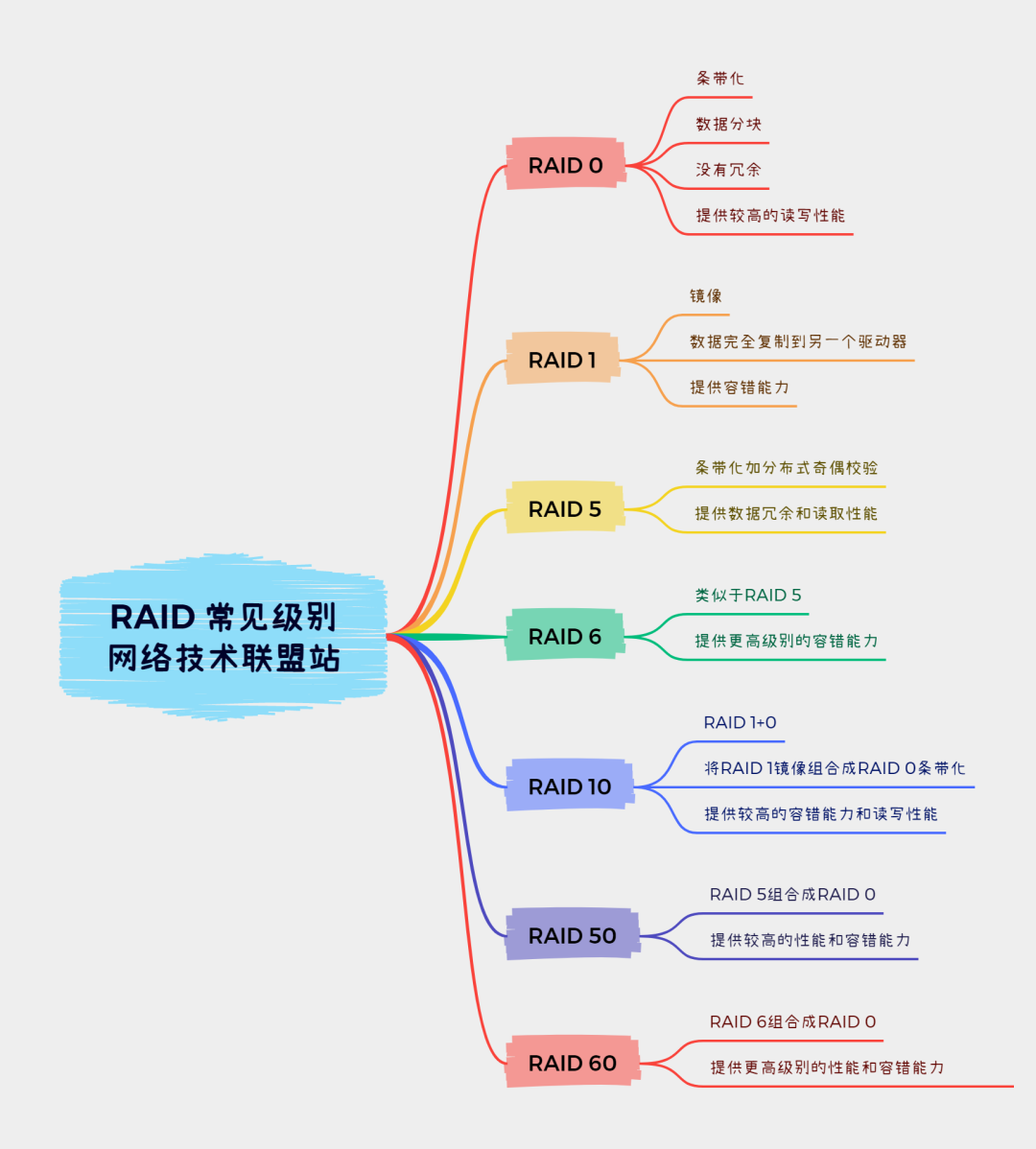
下面我们来详细介绍一下RAID的各个级别。
RAID 0
原理
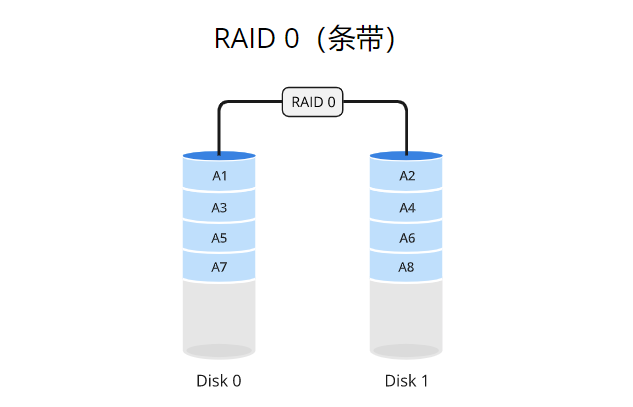
RAID 0使用数据条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,而不进行冗余备份。数据被分成固定大小的块,并依次存储在每个磁盘上。例如,如果有两个驱动器(驱动器A和驱动器B),一块数据的第一个部分存储在驱动器A上,第二个部分存储在驱动器B上,以此类推。这种条带化的方式可以同时从多个驱动器读取或写入数据,从而提高系统的性能。
适用场景
RAID 0适用于需要高性能而不关心数据冗余的场景。以下是几种适合使用RAID 0的场景:
- 视频编辑和处理:在视频编辑中,需要快速读取和写入大量数据。RAID 0可以通过并行读写操作提高数据传输速度,加快视频编辑和处理的速度。
- 大型数据库应用:对于需要频繁访问和查询数据库的应用程序,RAID 0可以提供更快的数据访问速度,加快数据库操作的响应时间。
- 实时流媒体:对于需要实时传输和处理大量数据的流媒体应用,RAID 0可以提供足够的带宽和吞吐量,确保流媒体内容的平滑播放。
优点
RAID 0具有以下优点:
- 高性能:通过数据条带化和并行读写操作,RAID 0可以提供更快的数据传输速度和更高的系统性能。
- 成本效益:相对于其他RAID级别(如RAID 1或RAID 5),RAID 0不需要额外的磁盘用于冗余备份,因此在成本上更具竞争力。
缺点
RAID 0也存在一些缺点:
- 缺乏冗余:由于RAID 0不提供数据冗余,如果任何一个驱动器发生故障,所有数据都可能丢失。因此,RAID 0不适合存储关键数据。
- 可靠性降低:由于没有冗余备份,RAID 0的可靠性相对较低。如果任何一个驱动器发生故障,整个阵列的可用性将受到影响。
RAID 1
原理
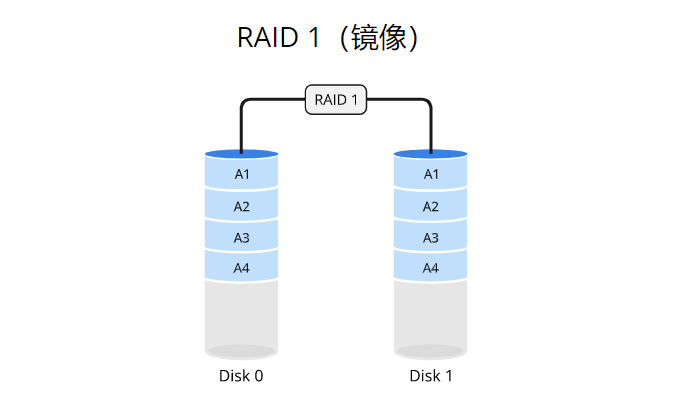
RAID 1使用数据镜像(mirroring)的方式将数据完全复制到两个或多个磁盘驱动器上。当写入数据时,数据同时写入所有驱动器。这样,每个驱动器都具有相同的数据副本,从而实现数据的冗余备份。如果其中一个驱动器发生故障,系统可以继续从剩余的驱动器中读取数据,确保数据的可用性和完整性。
适用场景
RAID 1适用于对数据冗余和高可用性要求较高的场景。以下是几种适合使用RAID 1的场景:
- 关键数据存储:对于关键数据的存储,如企业的财务数据、客户信息等,RAID 1可以提供数据冗余备份,以防止数据丢失。
- 数据库服务器:对于需要高可用性和容错性的数据库服务器,RAID 1可以确保数据的持久性和可用性,即使一个驱动器发生故障,也可以从其他驱动器中读取数据。
- 文件服务器:对于共享文件的服务器,RAID 1可以提供冗余备份,确保文件的可靠性和高可用性。
优点
RAID 1具有以下优点:
- 数据冗余备份:RAID 1通过数据镜像将数据完全复制到多个驱动器上,提供冗余备份,保护数据免受驱动器故障的影响。
- 高可用性:由于数据的冗余备份,即使一个驱动器发生故障,系统仍然可以从其他驱动器中读取数据,保证数据的可用性和连续性。
- 读取性能提升:RAID 1可以通过并行读取数据的方式提升读取性能,从而加快数据访问速度。
缺点
RAID 1也存在一些缺点:
- 成本增加:由于需要额外的磁盘用于数据冗余备份,RAID 1的成本相对较高。需要考虑额外的硬件成本。
- 写入性能略低:由于数据需要同时写入多个驱动器,相对于单个驱动器的写入性能,RAID 1的写入性能可能略低。
RAID 5
原理
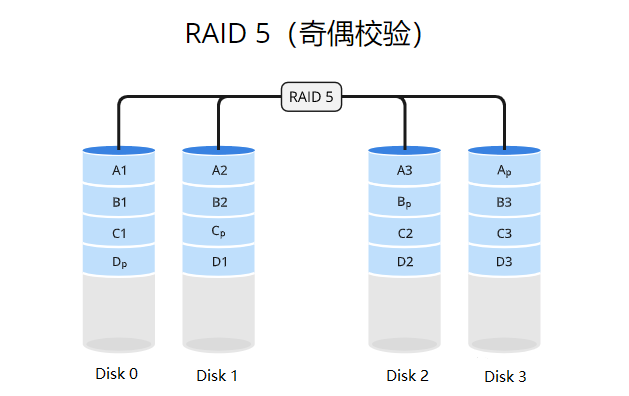
RAID 5使用数据条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,并通过分布式奇偶校验实现数据的冗余备份。数据和奇偶校验信息被组织成数据块,其中奇偶校验信息被分布式存储在不同的驱动器上。当写入数据时,奇偶校验信息也会被更新。如果其中一个驱动器发生故障,系统可以通过重新计算奇偶校验信息来恢复丢失的数据。这种方式可以同时提供性能增强和数据冗余。
适用场景
RAID 5适用于需要性能增强和数据冗余的场景。以下是几种适合使用RAID 5的场景:
- 文件服务器:对于文件服务器,RAID 5可以提供高性能的数据访问和数据冗余备份,确保文件的安全性和可用性。
- 数据库服务器:对于需要高性能和数据冗余的数据库服务器,RAID 5可以提供快速的数据读取和写入,同时保护数据免受驱动器故障的影响。
- 小型企业环境:对于小型企业,RAID 5提供了经济实惠的解决方案,同时提供了性能和数据冗余的好处。
优点
RAID 5具有以下优点:
- 性能增强:通过数据条带化和并行读写操作,RAID 5可以提供较高的数据传输速度和系统性能。
- 数据冗余备份:通过分布式奇偶校验,RAID 5可以提供数据的冗余备份,保护数据免受驱动器故障的影响。
- 成本效益:相对于其他RAID级别(如RAID 1),RAID 5只需要额外一个驱动器用于奇偶校验信息,从而在成本上更具竞争力。
缺点
RAID 5也存在一些缺点:
- 写入性能受限:由于写入数据时需要重新计算奇偶校验信息,相对于读取操作,RAID 5的写入性能较低。
- 驱动器故障期间的数据完整性:如果一个驱动器发生故障,系统在恢复数据时需要进行计算,这可能导致数据访问速度较慢,并且在此期间可能会有数据完整性的风险。
RAID 6
原理
RAID 6使用数据条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,并通过分布式奇偶校验和双重奇偶校验实现数据的冗余备份。数据和奇偶校验信息被组织成数据块,其中奇偶校验信息被分布式存储在不同的驱动器上,并通过双重奇偶校验提供更高的数据冗余性。当写入数据时,奇偶校验信息也会被更新。如果其中两个驱动器发生故障,系统可以通过重新计算奇偶校验信息来恢复丢失的数据。这种方式可以同时提供性能增强和更高级别的数据冗余。
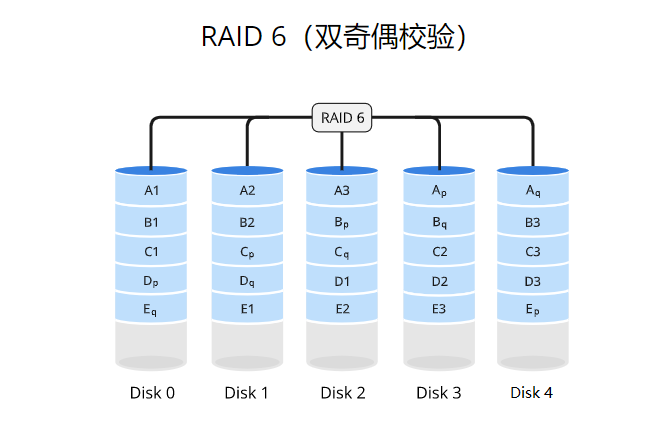
适用场景
RAID 6适用于需要更高级别的数据冗余和性能增强的场景。以下是几种适合使用RAID 6的场景:
- 大容量存储系统:对于需要大容量存储和数据冗余备份的系统,如大型文件服务器或存档系统,RAID 6可以提供更高级别的数据冗余性。
- 长时间运行的应用程序:对于需要长时间运行的关键应用程序,如数据库服务器,RAID 6可以提供更高级别的数据冗余和故障容忍性。
- 虚拟化环境:在虚拟化环境中,需要高性能和更高级别的数据冗余来支持多个虚拟机的运行。RAID 6可以满足这些要求。
优点
RAID 6具有以下优点:
- 更高级别的数据冗余:通过分布式奇偶校验和双重奇偶校验,RAID 6可以提供更高级别的数据冗余性,即使同时发生两个驱动器故障,仍能恢复丢失的数据。
- 性能增强:通过数据条带化和并行读写操作,RAID 6可以提供较高的数据传输速度和系统性能。
缺点
RAID 6也存在一些缺点:
- 写入性能略低:由于数据需要同时写入多个驱动器,并进行双重奇偶校验计算,相对于读取操作,RAID 6的写入性能较低。
- 较高的成本:由于需要额外的磁盘用于奇偶校验信息和更复杂的计算,RAID 6的成本相对较高。需要考虑额外的硬件成本。
RAID 10
原理
RAID 10使用条带化(striping)的方式将数据分散存储在多个磁盘驱动器上,并通过镜像(mirroring)实现数据的冗余备份。数据被分成固定大小的块,并依次存储在不同的驱动器上,类似于RAID 0。然而,每个数据块都会被完全复制到另一个驱动器上,实现数据的冗余备份,类似于RAID 1。这样,RAID 10在提供性能增强的同时,也提供了数据的冗余保护。
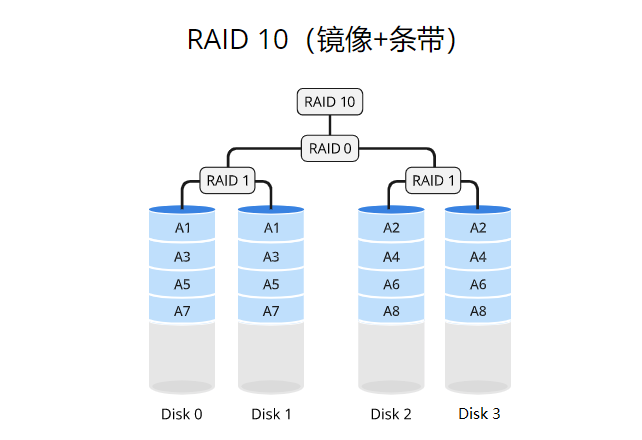
适用场景
RAID 10适用于需要高性能和数据冗余的场景。以下是几种适合使用RAID 10的场景:
- 数据库服务器:对于需要高可用性和性能的数据库服务器,RAID 10可以提供快速的数据读取和写入,同时保护数据免受驱动器故障的影响。
- 虚拟化环境:在虚拟化环境中,需要高性能和数据冗余来支持多个虚拟机的运行。RAID 10可以满足这些要求,提供性能增强和数据保护。
- 关键业务应用:对于关键业务应用,如金融交易系统或在线电子商务平台,RAID 10可以提供高可用性和快速的数据访问,确保业务的连续性和稳定性。
优点
RAID 10具有以下优点:
- 高性能:通过数据条带化和并行读写操作,RAID 10可以提供较高的数据传输速度和系统性能。
- 数据冗余备份:通过数据镜像将数据完全复制到另一个驱动器上,RAID 10提供了数据的冗余备份,保护数据免受驱动器故障的影响。
- 较高的可靠性:由于RAID 10采用镜像的方式进行数据冗余备份,即使一个驱动器发生故障,仍然可以从其他驱动器中读取数据,确保数据的可用性和连续性。
- 快速的故障恢复:在RAID 10中,如果一个驱动器发生故障,系统可以直接从镜像驱动器中恢复数据,而无需进行复杂的计算,从而加快故障恢复的速度。
缺点
RAID 10也存在一些缺点:
- 较高的成本:相对于其他RAID级别,RAID 10需要更多的驱动器用于数据镜像,从而增加了硬件成本。
- 低效的空间利用:由于RAID 10的数据镜像特性,有效的存储容量只等于所有驱动器中一半的容量,因此空间利用率较低。
RAID 50
原理
RAID 50使用条带化(striping)的方式将数据分散存储在多个RAID 5组中,并通过RAID 0的条带化方式对这些RAID 5组进行条带化。每个RAID 5组由多个磁盘驱动器组成,并使用分布式奇偶校验来提供数据冗余备份。RAID 0则通过将数据划分为固定大小的块,并将这些块依次存储在多个驱动器上,提供了更高的性能。这样,RAID 50既提供了数据冗余备份,又提供了性能增强。
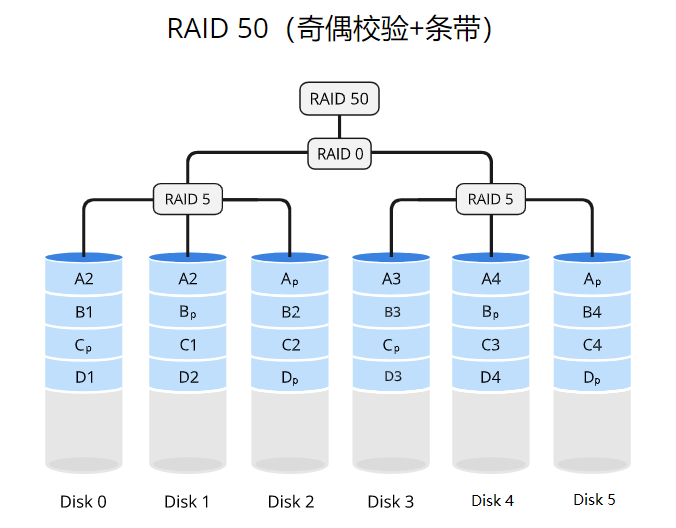
适用场景
RAID 50适用于需要高性能和更高级别的数据冗余的场景。以下是几种适合使用RAID 50的场景:
- 大规模数据存储:对于需要大规模数据存储和数据冗余备份的系统,如视频编辑、数据分析或大型数据库,RAID 50可以提供高性能和较高级别的数据冗余性。
- 图形渲染和动画制作:在图形渲染和动画制作领域,需要高性能的存储系统来处理大型文件和复杂的渲染任务。RAID 50可以满足这些要求,提供快速的数据读取和写入速度。
- 虚拟化环境:在虚拟化环境中,需要高性能和更高级别的数据冗余来支持多个虚拟机的运行。RAID 50可以满足这些要求,提供性能增强和数据保护。
优点
RAID 50具有以下优点:
- 高性能:通过数据条带化和并行读写操作,RAID 50可以提供较高的数据传输速度和系统性能。
- 更高级别的数据冗余:由于采用了多个RAID 5组的方式,RAID 50提供了更高级别的数据冗余备份,即使同时发生多个驱动器故障,仍能恢复丢失的数据。
缺点
RAID 50也存在一些缺点:
- 较高的成本:由于需要更多的驱动器用于数据条带化和数据冗余备份,RAID 50的硬件成本相对较高。
- 配置和管理复杂性:由于涉及多个RAID 5组和驱动器,RAID 50的配置和管理相对复杂,需要更多的注意和维护。
RAID 60
原理
RAID 60采用条带化(striping)的方式将数据分散存储在多个RAID 6组中,并通过RAID 0的条带化方式对这些RAID 6组进行条带化。每个RAID 6组由多个磁盘驱动器组成,并使用分布式奇偶校验来提供数据的冗余备份。RAID 0则通过将数据划分为固定大小的块,并将这些块依次存储在多个驱动器上,提供了更高的性能。这样,RAID 60既提供了更高级别的数据冗余备份,又提供了性能增强。
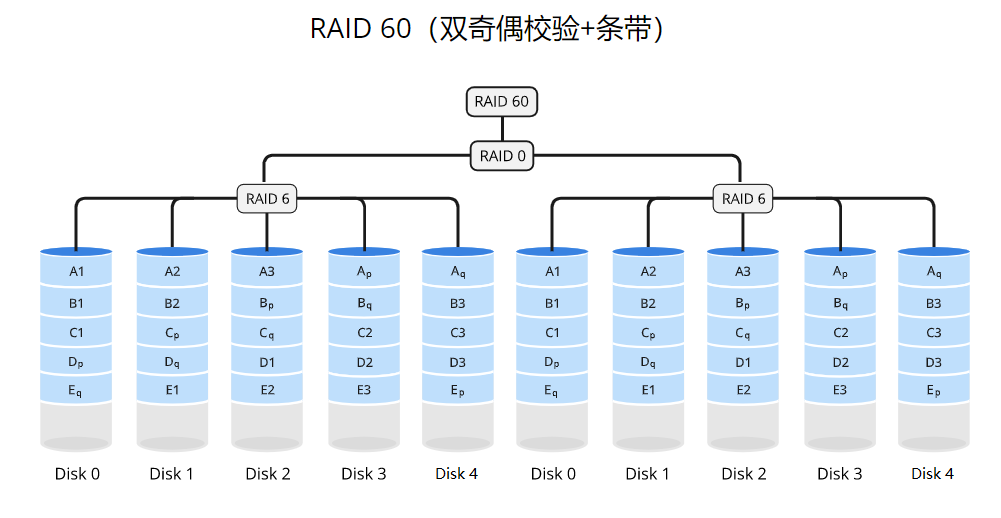
适用场景
RAID 60适用于需要更高级别的数据冗余和更高性能的场景。以下是几种适合使用RAID 60的场景:
- 大型数据库系统:对于大型数据库系统,需要高可用性、高性能和更高级别的数据冗余来确保数据的完整性和可靠性。RAID 60可以提供这些要求。
- 大规模数据分析:在大规模数据分析领域,需要高性能的存储系统来处理大量数据的读取和写入。RAID 60可以满足这些要求,提供较高的数据传输速度和系统性能。
- 视频流****媒体处理:对于视频流媒体处理应用,需要快速的数据读取和写入,以确保流畅的视频播放和高质量的媒体处理。RAID 60可以满足这些要求。
优点
RAID 60具有以下优点:
- 更高级别的数据冗余:由于采用了多个RAID 6组的方式,RAID 60提供了更高级别的数据冗余备份,即使同时发生多个驱动器故障,仍能恢复丢失的数据。
- 高性能:通过数据条带化和并行读写操作,RAID 60可以提供较高的数据传输速度和系统性能。
缺点
RAID 60也存在一些缺点:
- 较高的成本:由于需要更多的驱动器用于数据条带化和数据冗余备份,RAID 60的硬件成本相对较高。
- 配置和管理复杂性:由于涉及多个RAID 6组和驱动器,RAID 60的配置和管理相对复杂,需要更多的注意和维护。
RAID 级别总结
| RAID级别 | 最小磁盘数 | 容错能力 | 磁盘空间开销 | 读取速度 | 写入速度 | 硬件成本 |
|---|---|---|---|---|---|---|
| RAID 0 | 2 | 无 | 0% | 高 | 高 | 低 |
| RAID 1 | 2 | 单个磁盘 | 50% | 高 | 低 | 中 |
| RAID 5 | 3 | 单个磁盘 | 1 / N | 中 | 低 | 中 |
| RAID 6 | 4 | 两个磁盘 | 2 / N | 中 | 低 | 高 |
| RAID 10 | 4 | 多个磁盘 | 50% | 高 | 中 | 高 |
| RAID 50 | 6 | 单个磁盘 | 1 / N | 高 | 中 | 高 |
| RAID 60 | 8 | 多个磁盘 | 50% | 高 | 中 | 高 |
管理软 RAID
RHEL 提供多磁盘和设备管理 (mdadm) 程序实用程序来创建和管理软件RAID。
管理RAID0
创建RAID0
bash
# 创建一个包含2个块设备的raid0设备/dev/md0
[root@server ~ 16:28:04]# mdadm --create /dev/md0 --level 0 --raid-device 2 /dev/sd{b,c}
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md0 started.查看RAID
bash
# 查看 raid 概要信息
[root@server ~ 16:38:38]# cat /proc/mdstat
Personalities : [raid0]
md0 : active raid0 sdc[1] sdb[0]
41908224 blocks super 1.2 512k chunks
unused devices: <none>
## 查看 raid 设备详细信息(优先选择这种)
[root@server ~ 16:39:10]# mdadm --detail /dev/md0
/dev/md0:
Version : 1.2
Creation Time : Mon Sep 22 16:38:38 2025
Raid Level : raid0
Array Size : 41908224 (39.97 GiB 42.91 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Mon Sep 22 16:38:38 2025
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Chunk Size : 512K
Consistency Policy : none
Name : server.dcr.cloud:0 (local to host server.dcr.cloud)
UUID : a8ea1ad6:9a21262e:fafba484:9c3829e9
Events : 0
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
[root@server ~ 16:39:43]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 100G 0 disk
├─sda1 8:1 0 1G 0 part /boot
└─sda2 8:2 0 99G 0 part
├─centos-root 253:0 0 50G 0 lvm /
├─centos-swap 253:1 0 2G 0 lvm [SWAP]
└─centos-home 253:2 0 47G 0 lvm /home
sdb 8:16 0 20G 0 disk
└─md0 9:0 0 40G 0 raid0
sdc 8:32 0 20G 0 disk
└─md0 9:0 0 40G 0 raid0
sdd 8:48 0 20G 0 disk
sde 8:64 0 20G 0 disk
sdf 8:80 0 20G 0 disk
sdg 8:96 0 20G 0 disk
sr0 11:0 1 4.4G 0 rom
[root@server ~ 16:40:10]# lsblk /dev/md0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md0 9:0 0 40G 0 raid0 需要关注的属性:
- Raid Level : raid0
- State : clean
- Chunk Size : 512K
- 设备清单
bash
[root@server ~ 16:39:59]# lsblk /dev/md0
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md0 9:0 0 40G 0 raid0格式化和挂载
bash
[root@server ~ 16:40:34]# mkfs.xfs /dev/md0
meta-data=/dev/md0 isize=512 agcount=16, agsize=654720 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=10475520, imaxpct=25
= sunit=128 swidth=256 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=5120, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@server ~ 16:41:18]# mkdir /data
[root@server ~ 16:41:40]# mkdir /data/raid0
[root@server ~ 16:41:42]# mount /dev/md0 /data/raid0
[root@server ~ 16:42:22]# df -h /data/raid0
文件系统 容量 已用 可用 已用% 挂载点
/dev/md0 40G 33M 40G 1% /data/raid0
#验证挂载点是否能使用
[root@server ~ 16:42:40]# cp /etc/ho* /data/raid0
[root@server ~ 16:43:05]# ls /data/raid0
host.conf hostname hosts hosts.allow hosts.deny删除RAID
bash
#取消挂载点
[root@server ~ 16:43:11]# umount /dev/md0
#停止RAID阵列,将删除阵列
[root@server ~ 16:44:12]# mdadm --stop /dev/md0
mdadm: stopped /dev/md0
#清除原先设备上的 md superblock
[root@server ~ 16:44:42]# mdadm --zero-superblock /dev/sd{b,c}补充说明
-
raid0 条带不能增加新成员盘。
bash[root@server ~ 16:43:42]# mdadm /dev/md0 --add /dev/sdd mdadm: add new device failed for /dev/sdd as 2: Invalid argument -
raid0 条带不能强制故障成员盘。
bash[root@server ~ 16:43:56]# mdadm /dev/md0 --fail /dev/sdc mdadm: Cannot remove /dev/sdc from /dev/md0, array will be failed.
管理 RAID1
创建 RAID
bash
# 创建一个包含2个块设备的raid1设备/dev/md1
[root@server ~ 16:47:14]# mdadm --create /dev/md1 --level 1 --raid-devices 2 /dev/sd{b,c}
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store '/boot' on this device please ensure that
your boot-loader understands md/v1.x metadata, or use
--metadata=0.90
Continue creating array? yes
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md1 started.查看RAID
bash
[root@server ~ 16:47:49]# mdadm --detail /dev/md1
/dev/md1:
Version : 1.2
Creation Time : Mon Sep 22 16:47:48 2025
Raid Level : raid1
Array Size : 20954112 (19.98 GiB 21.46 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 2
Total Devices : 2
Persistence : Superblock is persistent
Update Time : Mon Sep 22 16:48:27 2025
State : clean, resyncing
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Resync Status : 38% complete
Name : server.dcr.cloud:1 (local to host server.dcr.cloud)
UUID : 1edfdbbe:2fe6a3f5:d6268b6b:b9a408c2
Events : 6
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
[root@server ~ 16:48:29]# mkfs.xfs /dev/md1
mkfs.xfs: /dev/md1 appears to contain an existing filesystem (xfs).
mkfs.xfs: Use the -f option to force overwrite.
[root@server ~ 16:49:08]# mkfs.xfs -f /dev/md1
meta-data=/dev/md1 isize=512 agcount=4, agsize=1309632 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=5238528, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=2560, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0需要关注的属性:
- Raid Level : raid1
- State : clean, resyncing,正在同步。
- Consistency Policy : resync
- Resync Status : 33% complete,同步进度。
- 设备清单
bash
[root@server ~ 16:47:49]# lsblk /dev/md1
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md1 9:1 0 20G 0 raid1格式化和挂载
等待同步完成:直到同步进度达到100%,然后进行格式化和挂载。
bash
[root@server ~ 16:49:17]# mkdir /data/raid1
[root@server ~ 16:49:43]# mount /dev/md1 /data/raid1
[root@server ~ 16:50:03]# df -h /data/raid1
文件系统 容量 已用 可用 已用% 挂载点
/dev/md1 20G 33M 20G 1% /data/raid1
[root@server ~ 16:50:15]# cp /etc/ho* /data/raid1
[root@server ~ 16:50:36]# ls /data/raid1
host.conf hostname hosts hosts.allow hosts.deny增加热备盘
bash
[root@server ~ 16:50:40]# mdadm /dev/md1 --add /dev/sdd
mdadm: added /dev/sdd
[root@server ~ 16:51:17]# mdadm --detail /dev/md1 | tail -n 15
Working Devices : 3
Failed Devices : 0
Spare Devices : 1
Consistency Policy : resync
Name : server.dcr.cloud:1 (local to host server.dcr.cloud)
UUID : 1edfdbbe:2fe6a3f5:d6268b6b:b9a408c2
Events : 20
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
2 8 48 - spare /dev/sdd
# /dev/sdd的状态为spare(备用)模拟故障
bash
# 强制成员盘故障
[root@server ~ 16:51:59]# mdadm /dev/md1 --fail /dev/sdc
mdadm: set /dev/sdc faulty in /dev/md1
[root@server ~ 16:52:42]# mdadm --detail /dev/md1 | tail -n 15
Spare Devices : 1
Consistency Policy : resync
Rebuild Status : 3% complete
#正在同步进度为3%
Name : server.dcr.cloud:1 (local to host server.dcr.cloud)
UUID : 1edfdbbe:2fe6a3f5:d6268b6b:b9a408c2
Events : 22
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
2 8 48 1 spare rebuilding /dev/sdd
1 8 32 - faulty /dev/sdc
[root@server ~ 16:52:45]# ls /data/raid1
host.conf hostname hosts hosts.allow hosts.deny
#依然可以正常访问删除故障磁盘
bash
[root@server ~ 16:53:13]# mdadm /dev/md1 --remove /dev/sdc
mdadm: hot removed /dev/sdc from /dev/md1
[root@server ~ 16:54:49]# mdadm --detail /dev/md1 | tail -n 15
State : clean
Active Devices : 2
Working Devices : 2
Failed Devices : 0
Spare Devices : 0
Consistency Policy : resync
Name : server.dcr.cloud:1 (local to host server.dcr.cloud)
UUID : 1edfdbbe:2fe6a3f5:d6268b6b:b9a408c2
Events : 42
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
2 8 48 1 active sync /dev/sdd删除 RAID
bash
[root@server ~ 16:54:52]# umount /dev/md1
[root@server ~ 16:55:20]# mdadm --stop /dev/md1
mdadm: stopped /dev/md1
#新加的和删除的也要清空
[root@server ~ 16:55:37]# mdadm --zero-superblock /dev/md{b..d}
mdadm: Couldn't open /dev/mdb for write - not zeroing
mdadm: Couldn't open /dev/mdc for write - not zeroing
mdadm: Couldn't open /dev/mdd for write - not zeroing补充说明
RAID1的设计初衷是数据冗余和可靠性,而不是为了增加存储容量。因此,即使添加了新的硬盘并进行了扩容操作,由于RAID1的工作方式,其总容量是不会增加的。
管理 RAID5
创建 RAID
bash
# 创建一个包含4个块设备的raid5设备/dev/md2
[root@server ~ 16:56:34]# mdadm --create /dev/md5 --level 5 --raid-devices 4
/dev/sd{b..e}
mdadm: /dev/sdb appears to be part of a raid array:
level=raid1 devices=2 ctime=Mon Sep 22 16:47:48 2025
mdadm: /dev/sdc appears to be part of a raid array:
level=raid1 devices=2 ctime=Mon Sep 22 16:47:48 2025
mdadm: /dev/sdd appears to be part of a raid array:
level=raid1 devices=2 ctime=Mon Sep 22 16:47:48 2025
Continue creating array? yes
mdadm: Defaulting to version 1.2 metadata
mdadm: array /dev/md5 started.查看 RAID
bash
[root@server ~ 16:59:51]# mdadm --detail /dev/md5
/dev/md5:
Version : 1.2
Creation Time : Mon Sep 22 16:58:49 2025
Raid Level : raid5
Array Size : 62862336 (59.95 GiB 64.37 GB)
Used Dev Size : 20954112 (19.98 GiB 21.46 GB)
Raid Devices : 4
Total Devices : 4
Persistence : Superblock is persistent
Update Time : Mon Sep 22 17:00:05 2025
State : clean, degraded, recovering
Active Devices : 3
Working Devices : 4
Failed Devices : 0
Spare Devices : 1
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 54% complete
Name : server.dcr.cloud:5 (local to host server.dcr.cloud)
UUID : 91e10d6b:8d78d311:b0bc142c:1099eb7f
Events : 13
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sdd
4 8 64 3 spare rebuilding /dev/sde需要关注的属性:
- Raid Level : raid5
- State : clean, resyncing,正在同步。
- Consistency Policy : resync
- Resync Status : 17% complete,同步进度。
- 设备清单
bash
[root@centos7 ~]# lsblk /dev/md5
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md5 9:5 0 60G 0 raid5 /data/raid5格式化和挂载
注意:格式化前,等待 raid 构建完成。
bash
[root@server ~ 16:58:49]# mkfs.xfs /dev/md5
mkfs.xfs: /dev/md5 appears to contain an existing filesystem (xfs).
mkfs.xfs: Use the -f option to force overwrite.
#没有等同步完成
#可以使用-f强制执行
[root@server ~ 16:59:04]# mkfs.xfs -f /dev/md5
meta-data=/dev/md5 isize=512 agcount=16, agsize=982144 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0, sparse=0
data = bsize=4096 blocks=15714304, imaxpct=25
= sunit=128 swidth=384 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal log bsize=4096 blocks=7680, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@server ~ 16:59:10]# mkdir /data/raid5
[root@server ~ 16:59:25]# mount /dev/md5 /data/raid5
[root@server ~ 17:00:12]# df -h /dev/md5
文件系统 容量 已用 可用 已用% 挂载点
/dev/md5 60G 33M 60G 1% /data/raid5
[root@server ~ 17:00:44]# cp /etc/ho* /data/raid5
[root@server ~ 17:01:12]# ls /data/raid5
host.conf hostname hosts hosts.allow hosts.deny增加热备盘
bash
# RAID5 阵列增加一个块热备盘
[root@server ~ 17:01:15]# mdadm /dev/md5 --add /dev/sdf
mdadm: added /dev/sdf
[root@server ~ 17:01:58]# mdadm --detail /dev/md5 | tail -n 17
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : server.dcr.cloud:5 (local to host server.dcr.cloud)
UUID : 91e10d6b:8d78d311:b0bc142c:1099eb7f
Events : 25
Number Major Minor RaidDevice State
0 8 16 0 active sync /dev/sdb
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sdd
4 8 64 3 active sync /dev/sde
5 8 80 - spare /dev/sdf模拟故障
bash
# 模拟磁盘故障,手动标记/dev/sdb为fail
[root@server ~ 17:02:42]# mdadm /dev/md5 --fail /dev/sdb
mdadm: set /dev/sdb faulty in /dev/md5
[root@server ~ 17:03:29]# mdadm --detail /dev/md5 | tail -n 17
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 3% complete
Name : server.dcr.cloud:5 (local to host server.dcr.cloud)
UUID : 91e10d6b:8d78d311:b0bc142c:1099eb7f
Events : 27
Number Major Minor RaidDevice State
5 8 80 0 spare rebuilding /dev/sdf
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sdd
4 8 64 3 active sync /dev/sde
0 8 16 - faulty /dev/sdb
#依然可以访问
[root@server ~ 17:03:35]# ls /data/raid5
host.conf hostname hosts hosts.allow hosts.deny删除故障磁盘
bash
[root@server ~ 17:03:58]# mdadm /dev/md5 --remove /dev/sdb
mdadm: hot removed /dev/sdb from /dev/md5
[root@server ~ 17:04:35]# mdadm --detail /dev/md5 | tail -n 17
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Rebuild Status : 47% complete
Name : server.dcr.cloud:5 (local to host server.dcr.cloud)
UUID : 91e10d6b:8d78d311:b0bc142c:1099eb7f
Events : 35
Number Major Minor RaidDevice State
5 8 80 0 spare rebuilding /dev/sdf
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sdd
4 8 64 3 active sync /dev/sde扩容 RAID
对于raid5,只能扩容,不能减容。
注意:阵列只有在正常状态下,才能扩容,降级及重构时不允许扩容。
bash
#先增加热备盘
[root@server ~ 17:04:41]# mdadm /dev/md5 --add /dev/sdb /dev/sdg
mdadm: added /dev/sdb
mdadm: added /dev/sdg
[root@server ~ 17:07:47]# mdadm --detail /dev/md5 | tail -n 17
Layout : left-symmetric
Chunk Size : 512K
Consistency Policy : resync
Name : server.dcr.cloud:5 (local to host server.dcr.cloud)
UUID : 91e10d6b:8d78d311:b0bc142c:1099eb7f
Events : 47
Number Major Minor RaidDevice State
5 8 80 0 active sync /dev/sdf
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sdd
4 8 64 3 active sync /dev/sde
6 8 16 - spare /dev/sdb
7 8 96 - spare /dev/sdg
# 设置成员数量为5,-G是grow(扩展 )
[root@server ~ 17:08:14]# mdadm -G /dev/md5 --raid-devices 5
[root@server ~ 17:08:55]# mdadm --detail /dev/md5 | tail -n 17
Consistency Policy : resync
Reshape Status : 1% complete
Delta Devices : 1, (4->5)
Name : server.dcr.cloud:5 (local to host server.dcr.cloud)
UUID : 91e10d6b:8d78d311:b0bc142c:1099eb7f
Events : 70
Number Major Minor RaidDevice State
5 8 80 0 active sync /dev/sdf
1 8 32 1 active sync /dev/sdc
2 8 48 2 active sync /dev/sdd
4 8 64 3 active sync /dev/sde
7 8 96 4 active sync /dev/sdg
6 8 16 - spare /dev/sdb
# 确认 raid 容量:增加了20G
[root@server ~ 17:08:57]# lsblk /dev/md5
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md5 9:5 0 60G 0 raid5 /data/raid5
#等待一会
[root@server ~ 17:09:21]# lsblk /dev/md5
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
md5 9:5 0 80G 0 raid5 /data/raid5
# 扩展文件系统
[root@server ~ 17:13:24]# xfs_growfs /data/raid5
meta-data=/dev/md5 isize=512 agcount=16, agsize=982144 blks
= sectsz=512 attr=2, projid32bit=1
= crc=1 finobt=0 spinodes=0
data = bsize=4096 blocks=15714304, imaxpct=25
= sunit=128 swidth=384 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=1
log =internal bsize=4096 blocks=7680, version=2
= sectsz=512 sunit=8 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 15714304 to 20954112
[root@server ~ 17:14:01]# df -h /dev/md5
文件系统 容量 已用 可用 已用% 挂载点
/dev/md5 80G 34M 80G 1% /data/raid5删除 RAID
bash
#卸载
[root@server ~ 17:14:17]# umount /data/raid5
# stop RAID 阵列,将删除阵列
[root@server ~ 17:14:35]# mdadm --stop /dev/md5
mdadm: stopped /dev/md5
# 清除原先设备上的 md superblock
[root@server ~ 17:14:52]# mdadm --zero-superblock /dev/sd{b..g}