文章目录
- 一、LangChain
- 二、LLMs和ChatModels
-
-
- [1、LLMs(Large Language Models)](#1、LLMs(Large Language Models))
- 2、ChatModels(聊天模型)
- 3、核心区别对比
-
- 三、本地使用大模型
-
-
- [1.本地部署 LLMs 集成 LangChain](#1.本地部署 LLMs 集成 LangChain)
- [2.本地部署 ChatModels 集成 LangChain](#2.本地部署 ChatModels 集成 LangChain)
- [3.使用 API](#3.使用 API)
-
- [3.1 通过 API 使用 LLMs(LangChain 集成)](#3.1 通过 API 使用 LLMs(LangChain 集成))
- [3.2 通过 API 使用 ChatModels(LangChain 集成)](#3.2 通过 API 使用 ChatModels(LangChain 集成))
- [3.3 常用方法详解](#3.3 常用方法详解)
- [1. `invoke(messages, **kwargs)`:基础同步调用](#1.
invoke(messages, **kwargs):基础同步调用) - [2. `stream(messages, **kwargs)`:同步流式输出](#2.
stream(messages, **kwargs):同步流式输出) - [3. `generate(messages_list,** kwargs)`:同步批量处理](#3.
generate(messages_list,** kwargs):同步批量处理) - [4. 异步方法:`ainvoke`、`astream`、`agenerate`](#4. 异步方法:
ainvoke、astream、agenerate) - [5. predict()](#5. predict())
- [6. predict_messages()](#6. predict_messages())
- [7. batch()](#7. batch())
-
- 四、提示词prompt
- 五、输出解析器
-
-
- 常见输出解析器类型及用法
- [1. 列表解析器(`CommaSeparatedListOutputParser`)](#1. 列表解析器(
CommaSeparatedListOutputParser)) - [2. 时间解析器(`DatetimeOutputParser`)](#2. 时间解析器(
DatetimeOutputParser)) - [3. 枚举解析器(`EnumOutputParser`)](#3. 枚举解析器(
EnumOutputParser)) - [4. 结构化解析器(`StructuredOutputParser`)](#4. 结构化解析器(
StructuredOutputParser)) - [5. Pydantic 解析器(`PydanticOutputParser`)](#5. Pydantic 解析器(
PydanticOutputParser)) - [6. 自动修复解析器(`OutputFixingParser`)](#6. 自动修复解析器(
OutputFixingParser)) - [7. 重试解析器(`RetryOutputParser`)](#7. 重试解析器(
RetryOutputParser))
-
- 六、链
-
-
- [1. 链的核心价值](#1. 链的核心价值)
- [2. 内置链(Built-in Chains)](#2. 内置链(Built-in Chains))
-
- [2.1 `LLMChain`:最基础的链(核心)](#2.1
LLMChain:最基础的链(核心)) - [2.2 `SequentialChain`:顺序执行多链](#2.2
SequentialChain:顺序执行多链) - [2.3 `SimpleSequentialChain`:简化的顺序链](#2.3
SimpleSequentialChain:简化的顺序链) - 2.3`RetrievalQA`:检索增强问答链
- 其他常用内置链
- [2.1 `LLMChain`:最基础的链(核心)](#2.1
- [3. 自定义链(Custom Chains)](#3. 自定义链(Custom Chains))
-
一、LangChain
LangChain是一个开源框架,用于构建基于大语言模型(LLM)的应用程序。简单来说,它就像连接大语言模型与外部世界的"桥梁"。
正如知识库中所述:
"LangChain是一个用于开发由语言模型驱动的应用程序的框架。"
LangChain的核心价值在于:它让语言模型不仅能回答通用问题,还能从你的私有数据中提取信息,并根据这些信息执行具体操作。例如,让聊天机器人不仅能回答"你好",还能"查看我的订单"、"发送邮件"或"分析我的销售数据"。
大模型虽然强大,但存在一个关键局限:
"大模型擅长在常规上下文对提示做出响应,但在未接受过训练的特定领域却很吃力。比如大模型可以估算出计算机成本问题。但是,它无法列出贵公司销售的特定计算机型号的价格。"
LangChain正是为解决这个问题而生。它通过以下方式提升LLM应用的实用价值:
- 数据连接:将LLM连接到你的数据库、PDF文件或其他数据源
- 行动执行:让LLM不仅能回答问题,还能执行具体操作(如发送邮件、调用API)
- 上下文管理:处理长文本分割、对话历史维护等复杂场景
LangChain的核心组件
LangChain框架由六大核心组件构成,它们共同构成了LLM应用的"骨架":
-
Models(模型):提供统一接口调用不同LLM(如ChatGPT、Claude、通义千问等)
pythonfrom langchain_community.llms import Tongyi llm = Tongyi() -
Prompts(提示词):模板化管理提示词,支持动态变量注入
pythonfrom langchain.prompts import PromptTemplate prompt = PromptTemplate( input_variables=["product"], template="为{product}写3个广告标语:" ) -
Chains(链):将多个步骤组合成工作流
pythonfrom langchain.chains import LLMChain chain = LLMChain(llm=llm, prompt=prompt) -
Agents(代理):让LLM自主选择工具完成任务
pythonfrom langchain.agents import initialize_agent agent = initialize_agent(tools, llm, agent="zero-shot-react-description") -
Memory(记忆):维护对话历史或应用状态
pythonfrom langchain.memory import ConversationBufferMemory memory = ConversationBufferMemory() -
Indexes(索引):集成外部数据供LLM查询
pythonfrom langchain.indexes import VectorstoreIndexCreator index = VectorstoreIndexCreator().from_loaders([loader])
二、LLMs和ChatModels
在 LangChain 中,LLMs和ChatModels是两种核心的模型封装接口,分别对应不同类型的语言模型,适用于不同的场景。
1、LLMs(Large Language Models)
LLMs是 LangChain 对基础大语言模型的封装,这类模型的设计初衷是处理通用文本生成任务,接口更贴近原始的大语言模型(如 GPT-3、LLaMA、PaLM 等)。
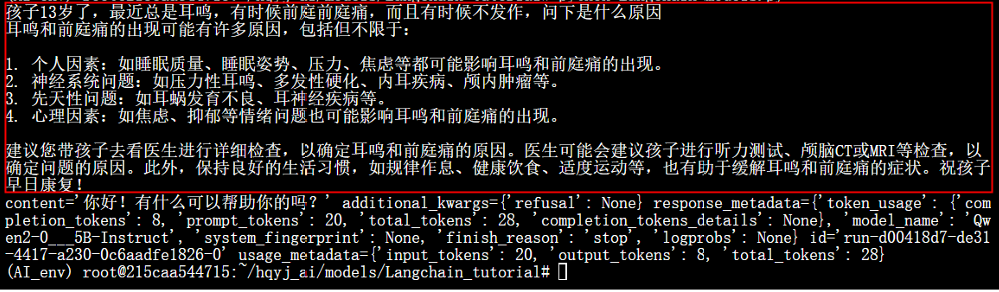
核心特点:
- 输入格式 :接受纯文本字符串(str) 作为输入。例如:
"请写一篇关于人工智能的短文" - 输出格式 :返回纯文本字符串(str) 作为输出。例如:
"人工智能是一门研究如何使机器模拟人类智能的学科..." - 设计用途 :适用于单轮文本生成任务,如文本补全、摘要、翻译、创作等,不直接支持多轮对话的上下文管理。
- 上下文处理 :如果需要多轮对话,需手动将历史对话拼接成一个长文本字符串传入(例如:
"用户:你好\nAI:你好!\n用户:今天天气如何\nAI:")。 - 典型模型 :OpenAI 的
text-davinci-003、Anthropic 的Claude Instant、开源的LLaMA 2(基础版)等。
2、ChatModels(聊天模型)
ChatModels是 LangChain 对对话式大语言模型 的封装,这类模型专为多轮对话设计,接口更贴合对话场景(如 GPT-3.5-turbo、GPT-4、Claude 2 等)。以消息列表作为输入并返回消息。
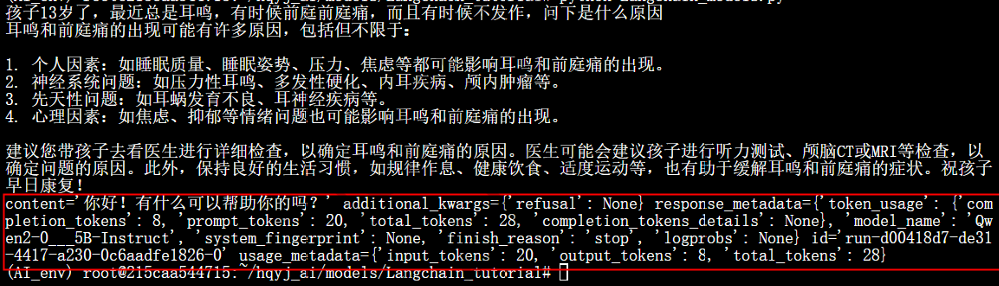
核心特点:
-
输入格式 :接受消息列表(list of Message objects) 作为输入。消息对象包含角色(role) 和内容(content),常见角色有:
HumanMessage:人类用户的输入AIMessage:AI 的回复(用于上下文)SystemMessage:系统提示(定义 AI 的行为)
例如:
pythonfrom langchain.schema import HumanMessage, SystemMessage messages = [ SystemMessage(content="你是一个友好的助手"), HumanMessage(content="你好,今天天气怎么样?") ] -
输出格式 :返回ChatMessage 对象 (通常是
AIMessage),包含 AI 的回复内容。例如:AIMessage(content="今天天气晴朗,温度25℃") -
设计用途 :专为多轮对话场景优化,内置支持上下文管理,无需手动拼接历史对话。
-
上下文处理 :通过消息列表自然维护对话历史,每轮对话只需在列表中添加新的
HumanMessage,模型会自动理解上下文。 -
典型模型 :OpenAI 的
gpt-3.5-turbo、gpt-4,Anthropic 的Claude 2,Google 的Gemini-Pro等。
3、核心区别对比
| 维度 | LLMs | ChatModels |
|---|---|---|
| 输入格式 | 纯文本字符串(str) | 消息列表(Message 对象) |
| 输出格式 | 纯文本字符串(str) | ChatMessage 对象 |
| 多轮对话支持 | 需手动拼接历史对话 | 内置支持(通过消息列表维护) |
| 适用场景 | 单轮文本生成(摘要、翻译等) | 多轮对话(聊天、客服、问答等) |
| 模型示例 | text-davinci-003、基础 LLaMA | gpt-3.5-turbo、Claude 2 |
三、本地使用大模型
1.本地部署 LLMs 集成 LangChain
py
from langchain.llms.base import LLM
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
model = AutoModelForCausalLM.from_pretrained( "./deepseek").to(device)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("./deepseek")
# 实现自定义LLM类
class CustomLLM(LLM):
def _call(self, prompt: str, stop: str = None) -> str:
# 将输入的prompt转换成模型输入格式
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# 生成输出
outputs = model.generate(**inputs, max_length=100)
# 解码输出:outputs[0]为模型生成的文本 skip_special_tokens=True为跳过特殊字符
generated_text=tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
@property
def _identifying_params(self):
# 模型参数:模型名或者路径
return {"model_path":model.config.name_or_path}
@property
def _llm_type(self):
# LLM类型
return "custom"
# 使用模型
local_llm=CustomLLM()
result=local_llm("你好")
print(result)2.本地部署 ChatModels 集成 LangChain
py
from langchain.llms.base import LLM
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = "cuda" if torch.cuda.is_available() else "cpu"
# 加载模型
model = AutoModelForCausalLM.from_pretrained( "./deepseek").to(device)
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained("./deepseek")
# 实现自定义LLM类
class CustomChatLLM(LLM):
def _call(self, prompt: str, stop: str = None) -> str:
# 消息封装
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt},
]
text=tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
"""
<|im_start|>system
You are a helpful assistant.<|im_end|>
<|im_start|>user
你好<|im_end|>
<|im_start|>assistant
"""
# 将输入的prompt转换成模型输入格式
inputs = tokenizer([text], return_tensors="pt").to(device)
# 生成输出
outputs = model.generate(**inputs, max_length=100)
# 解码输出:outputs[0]为模型生成的文本 skip_special_tokens=True为跳过特殊字符
generated_text=tokenizer.decode(outputs[0], skip_special_tokens=True)
return generated_text
@property
def _identifying_params(self):
# 模型参数:模型名或者路径
return {"model_path":model.config.name_or_path}
@property
def _llm_type(self):
# LLM类型
return "custom"
# 使用模型
local_llm=CustomChatLLM()
result=local_llm("你好")
print(result)3.使用 API
API 调用方式无需本地部署模型,通过 LangChain 提供的官方集成类即可快速使用。
3.1 通过 API 使用 LLMs(LangChain 集成)
py
from langchain.llms import OpenAI
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import os
# 1. 配置API密钥(建议使用环境变量)
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
# 2. 初始化LLM实例
api_llm = OpenAI(
model_name="text-davinci-003", # 模型名称
temperature=0.7, # 生成随机性(0-1)
max_tokens=300, # 最大生成token数
top_p=1.0, # 核采样参数
frequency_penalty=0.0, # 重复生成惩罚
presence_penalty=0.0, # 新主题引入惩罚
streaming=True, # 启用流式输出
callbacks=[StreamingStdOutCallbackHandler()] # 流式回调
)
# 3. 单轮文本生成
print("===== 单轮生成 =====")
prompt = "用三句话解释什么是机器学习"
print(f"Prompt: {prompt}")
print("Response: ", end="")
api_llm(prompt) # 流式输出会直接打印
print("\n")
# 4. 批量生成
print("===== 批量生成 =====")
prompts = [
"推荐一本入门级Python书籍",
"推荐一本入门级机器学习书籍"
]
results = api_llm.generate(prompts)
for i, result in enumerate(results.generations):
print(f"Prompt {i+1}: {prompts[i]}")
print(f"Response: {result[0].text}\n")3.2 通过 API 使用 ChatModels(LangChain 集成)
py
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
SystemMessage,
HumanMessage,
AIMessage
)
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
import os
# 1. 配置API密钥
os.environ["OPENAI_API_KEY"] = "your-api-key-here"
# 2. 初始化ChatModel
chat_api = ChatOpenAI(
model_name="gpt-3.5-turbo",
temperature=0.7,
max_tokens=300,
streaming=True,
callbacks=[StreamingStdOutCallbackHandler()]
)
# 3. 多轮对话示例
print("===== 多轮对话 =====")
# 维护对话历史
messages = [
SystemMessage(content="你是一个编程助手,用简洁的语言回答技术问题")
]
# 第一轮对话
user_input1 = "什么是异步编程?"
messages.append(HumanMessage(content=user_input1))
print(f"用户: {user_input1}")
print("AI: ", end="")
response1 = chat_api(messages)
messages.append(AIMessage(content=response1.content))
print("\n")
# 第二轮对话(依赖上下文)
user_input2 = "它和同步编程有什么主要区别?"
messages.append(HumanMessage(content=user_input2))
print(f"用户: {user_input2}")
print("AI: ", end="")
response2 = chat_api(messages)
messages.append(AIMessage(content=response2.content))
print("\n")
# 4. 批量对话生成
print("===== 批量对话 =====")
batch_messages = [
[
SystemMessage(content="你是一个翻译助手"),
HumanMessage(content="将'我爱编程'翻译成英文")
],
[
SystemMessage(content="你是一个翻译助手"),
HumanMessage(content="将'我喜欢用Python'翻译成英文")
]
]
results = chat_api.generate(batch_messages)
for i, result in enumerate(results.generations):
print(f"任务 {i+1} 结果: {result[0].message.content}")3.3 常用方法详解
1. invoke(messages, **kwargs):基础同步调用
功能:接收一组消息列表,同步生成一个完整的 AI 回复(一次性返回全部结果)。是最基础、最常用的对话方法,适合简单的单轮或多轮对话场景。
参数:
-
输入:
- 字符串(自动转为
HumanMessage) - 消息列表(如
[HumanMessage(...), SystemMessage(...)])
- 字符串(自动转为
-
messages:List[BaseMessage],对话消息列表(包含SystemMessage、HumanMessage、AIMessage等)。 -
kwargs:可选参数,用于控制生成行为,如:
stop:List[str],生成到指定字符串时停止(如["用户:", "###"])。max_tokens:生成的最大 token 数。temperature:控制输出随机性(0-1,值越高越随机)。- 其他模型专属参数(如
top_p、frequency_penalty等)。
返回值 :通常是AIMessage对象,包含 AI 的完整回复内容。
示例:
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import AIMessage, HumanMessage, SystemMessage
# 使用vllm本地部署的大模型
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
# 1.输入字符串自动转化为HumanMessage
# result = chat_model.invoke("请用中文回答我的问题:如何使用langchain进行对话?")
# print(result.content)
# 2.1输入消息列表(如 `[HumanMessage(...), SystemMessage(...)]`)
# result=chat_model.invoke(
# [SystemMessage(content="你是一个专业的大模型老师"),
# HumanMessage(content="请用中文回答我的问题:如何使用langchain进行对话?")
# ]
# )
# 2.2输入消息列表(如 `[HumanMessage(...), SystemMessage(...)]`)
result = chat_model.invoke([
{"role": "system",
"content": "你是一个专业大模型老师"},
{"role": "user",
"content": "请用中文回答我的问题:如何使用langchain进行对话?"}])
print(result.content)2. stream(messages, **kwargs):同步流式输出
功能 :接收消息列表,以流式方式返回 AI 回复(逐 token / 逐片段返回),适合需要实时展示回复过程的场景(如聊天界面、实时日志)。
参数 :与invoke完全一致。
返回值 :Iterable[BaseMessageChunk],一个可迭代对象,每次迭代返回一个消息片段(AIMessageChunk),最终拼接为完整回复。
示例:
python
# 流式输出示例(模拟聊天界面实时显示)
messages = [
HumanMessage(content="用3个步骤解释如何使用ChatModels的stream方法")
]
# 迭代获取流式结果
print("AI回复:", end="", flush=True)
for chunk in chat.stream(messages):
print(chunk.content, end="", flush=True) # 实时打印每个片段
# 输出(逐字/逐词显示):
# 1. 初始化ChatModel实例并配置参数;2. 构建消息列表;3. 迭代stream方法返回的片段并拼接。特点:
- 无需等待完整回复生成,可即时展示部分内容,提升用户体验。
- 适合前端交互场景(如 Web 聊天应用)。
3. generate(messages_list,** kwargs):同步批量处理
功能 :接收多个消息列表(即多组独立的对话),批量生成回复,适合一次性处理多个独立的对话任务(如批量问答、批量翻译)。
参数:
messages_list:List[List[BaseMessage]],多个消息列表的列表(每个子列表代表一组独立对话)。**kwargs:同invoke(生成参数对所有批量任务生效)。
返回值 :ChatResult,包含所有批量任务的结果,其中:
generations:List[List[ChatGeneration]],每个元素对应一组对话的生成结果。llm_output:模型额外输出(如 token 使用量等)。
示例:
python
# 批量处理两个独立对话
messages_list = [
# 第一个对话
[
SystemMessage(content="翻译为英文"),
HumanMessage(content="我爱编程")
],
# 第二个对话
[
SystemMessage(content="翻译为英文"),
HumanMessage(content="我喜欢用Python")
]
]
# 批量生成
results = chat.generate(messages_list)
# 解析结果
for i, generation in enumerate(results.generations):
print(f"任务{i+1}结果:{generation[0].message.content}")
# 输出:
# 任务1结果:I love programming
# 任务2结果:I like using Python4. 异步方法:ainvoke、astream、agenerate
以上同步方法均有对应的异步版本,命名以a开头,适合异步编程框架(如 FastAPI、asyncio),避免阻塞事件循环。
示例(ainvoke):
python
import asyncio
async def async_chat():
response = await chat.ainvoke([HumanMessage(content="异步调用返回什么?")])
print("异步回复:", response.content)
# 运行异步函数
asyncio.run(async_chat())示例(astream):
python
async def async_stream_chat():
print("异步流式回复:", end="", flush=True)
async for chunk in chat.astream([HumanMessage(content="用异步流式输出一句话")]):
print(chunk.content, end="", flush=True)
asyncio.run(async_stream_chat())5. predict()
-
功能 : 输入字符串,直接返回回复字符串(简化版
invoke)。 -
输入: 字符串。
-
返回: 回复字符串。
-
示例:
pythonreply = chat_model.predict("What is AI?") print(reply)
6. predict_messages()
-
功能 : 输入消息列表,返回
AIMessage对象。 -
输入: 消息列表。
-
返回 :
AIMessage对象。 -
示例:
pythonfrom langchain_core.messages import SystemMessage, HumanMessage messages = [ SystemMessage(content="You are a helpful assistant."), HumanMessage(content="Who won the 2020 US election?") ] response = chat_model.predict_messages(messages) print(response.content)
7. batch()
-
功能 : 批量同步处理多个输入(类似
generate,但返回简化结果)。 -
输入: 一维列表(元素为字符串或消息列表)。
-
返回 :
AIMessage列表。 -
示例:
pythoninputs = ["Hello!", "How are you?"] responses = chat_model.batch(inputs) for res in responses: print(res.content)
四、提示词prompt
LangChain 的核心是 "串联 LLM 与外部资源(数据、工具等)",而 Prompt 的本质是将 "人类意图" 转化为 "LLM 可理解的任务指令",同时协调外部资源与模型的交互逻辑。
- 对用户:将模糊需求(如 "分析这个文档")转化为明确任务(如 "从文档中提取 3 个核心观点,用 bullet point 列出")。
- 对模型:提供 "任务边界"(做什么、不做什么)、"上下文锚点"(基于什么信息处理)、"输出约束"(格式、风格、详略)。
- 对 LangChain 流程:作为链条(Chain)中的 "调度指令",例如在
RetrievalQA中,Prompt 需要明确告诉模型 "使用检索到的文档回答问题,不要编造信息"。
-
占位符机制 :使用
{}作为占位符(如{language}、{text}),在生成提示词时通过字典传入具体值 -
角色区分:
system:系统提示,设置AI的角色和行为准则user:用户输入assistant:模型的响应(在对话中使用)
-
多模板组合:可以组合多个提示模板,构建复杂的提示链
单个变量:
py
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
template = """
今天{location}天气如何?
"""
# 使用 PromptTemplate 类从模板字符串创建一个提示对象
# 第1种.显式指定输入变量和模板字符串
# prompt = PromptTemplate(template=template, input_variables=["location"])
# 第2种.from_template方法可以直接从字符串模板创建 PromptTemplate 对象
prompt = PromptTemplate.from_template(template)
inpute= prompt.format(location="上海")
res = chat_model.invoke(inpute)
print(res)-
a.显式指定
template和input_variables: -
这种方式是通过直接实例化
PromptTemplate类,显式传入两个核心参数:template:包含变量占位符(如{variable})的字符串模板;input_variables:一个列表,明确指定模板中所有变量的名称(需与占位符一致)。
-
b.使用
from_template类方法创建from_template是PromptTemplate提供的类方法,只需传入模板字符串,无需手动指定input_variables------ 它会自动解析模板中所有{variable}格式的占位符,并将其作为输入变量。
【多个变量】:
py
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
# 多个变量
template = """
{date}{location}天气如何?
"""
# prompt = PromptTemplate.from_template(template)
prompt = PromptTemplate(input_variables=["date","location"], template=template)
print(prompt.format(date="今天",location="北京"))五、输出解析器
LLM 的原生输出通常是自由文本,而实际应用中往往需要结构化数据(例如提取用户信息时需要{"name": "", "age": ""}格式,工具调用时需要{"tool": "", "params": {}}格式)。输出解析器解决了三个核心问题:
- 格式转换:将非结构化文本转为可直接使用的结构化数据(如字典、列表);
- 校验约束:确保输出符合预设格式(如字段完整性、类型正确性);
- 简化下游逻辑:避免手动编写字符串解析代码(如正则匹配),降低开发成本。
常见输出解析器类型及用法
1. 列表解析器(CommaSeparatedListOutputParser)
核心功能:将 LLM 输出的逗号分隔文本转换为 Python 列表,适用于提取关键词、标签、选项等简单序列。
适用场景:
- 提取文章关键词、标签;
- 生成多个同类项(如 "列出 3 个旅游目的地");
- 需要简单列表结构的场景。
示例代码:
python
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import CommaSeparatedListOutputParser
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
#创建输出解析器(列表)
parser = CommaSeparatedListOutputParser()
prompt = PromptTemplate(
template="回答用户查询.\n{x}\n{query}\n",
input_variables=["query"],
# 获取解析器的提示词
partial_variables={"x": parser.get_format_instructions()}
)
inpute = prompt.format(query="列举五个地区的天气")
res = chat_model.invoke(inpute).content.split("</think>")[-1]
print(parser.parse(res))2. 时间解析器(DatetimeOutputParser)
核心功能 :从 LLM 输出中提取日期 / 时间信息,并自动转换为 Python datetime对象,支持多种时间格式解析。
适用场景:
- 提取文本中的日期(如 "会议定在 3 月 15 日");
- 处理时间相关问答(如 "明天几点 sunrise");
- 需要将时间字符串转为可计算的
datetime对象的场景。
示例代码:
python
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import DatetimeOutputParser
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
#创建输出解析器
parser = DatetimeOutputParser()
prompt = PromptTemplate(
template="回答用户查询.\n{instructions}\n{query}\n",
input_variables=["query"],
# 获取解析器的提示词
partial_variables={"instructions": parser.get_format_instructions()}
)
print(parser.get_format_instructions())
inpute = prompt.format(query="今年过年的阳历时间")
res = chat_model.invoke(inpute).content.split("</think>")[-1]
print(parser.parse(res))3. 枚举解析器(EnumOutputParser)
核心功能 :强制 LLM 输出符合预定义枚举(Enum)类型的值,确保输出在指定选项范围内,避免无效值。
适用场景:
- 输出必须从固定选项中选择(如 "是 / 否 / 不确定""高 / 中 / 低");
- 需要严格限制输出范围的场景(如分类标签必须在预设列表中)。
示例代码:
python
from langchain.output_parsers import EnumOutputParser
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
from enum import Enum
# 定义枚举类型(固定输出选项)
class Sentiment(Enum):
POSITIVE = "正面"
NEGATIVE = "负面"
NEUTRAL = "中性"
# 创建枚举解析器(绑定枚举类型)
output_parser = EnumOutputParser(enum=Sentiment)
# 格式说明(告诉LLM必须从枚举选项中选择)
format_instructions = output_parser.get_format_instructions()
# 格式说明示例:"请从以下选项中选择输出:正面、负面、中性。只能输出选项本身,不要添加其他内容。"
# 提示词模板
template = "分析这句话的情感:'{text}',按要求格式输出。\n{format_instructions}"
prompt = PromptTemplate(
template=template,
input_variables=["text"],
partial_variables={"format_instructions": format_instructions}
)
# 调用LLM并解析
llm = OpenAI(temperature=0)
input_prompt = prompt.format(text="这部电影剧情精彩,演员表现出色")
llm_output = llm(input_prompt) # LLM输出示例:"正面"
result = output_parser.parse(llm_output)
print(result) # 输出:Sentiment.POSITIVE(枚举成员)
print(result.value) # 输出:"正面"(枚举值)4. 结构化解析器(StructuredOutputParser)
核心功能 :将 LLM 输出转换为 JSON 格式的结构化数据,支持自定义字段、描述和类型约束,通过ResponseSchema定义输出结构。
适用场景:
- 提取多字段信息(如用户信息、产品参数);
- 需要 JSON 格式输出的场景(如 API 交互、数据存储);
- 字段较多但类型约束不严格的结构化需求。
示例代码:
python
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
'''
用于解析具有特定结构的LLM输出,如JSON、CSV等。它可以预定义输出的结构
'''
# 定义响应模式
response_schemas = [
ResponseSchema(name="event_name", description="事件名称"),
ResponseSchema(name="person", description="人物"),
ResponseSchema(name="date", description="时间")
]
#创建输出解析器
parser = StructuredOutputParser(response_schemas=response_schemas)
prompt = PromptTemplate(
template="回答用户查询.\n{instructions}\n{query}\n",
input_variables=["query"],
# 获取解析器的提示词
partial_variables={"instructions": parser.get_format_instructions()}
)
print(parser.get_format_instructions())
inpute = prompt.format(query="中国人民解放")
res = chat_model.invoke(inpute).content.split("</think>")[-1]
print(parser.parse(res))5. Pydantic 解析器(PydanticOutputParser)
核心功能:基于 Pydantic 模型定义输出结构,支持严格的类型校验(如整数、布尔值、嵌套结构),解析失败时会抛出明确错误。
与StructuredOutputParser的区别:
- 前者基于 Pydantic 模型,支持更复杂的类型约束(如
int/float严格校验、嵌套模型); - 后者基于
ResponseSchema,更简单,适合字段少、类型约束宽松的场景。
适用场景:
- 输出需要严格类型校验(如价格必须是数字,数量必须是正整数);
- 包含嵌套结构的复杂数据(如 "用户信息包含姓名、地址(省 / 市)");
- 需要确保数据合法性的场景(如 API 输入验证)。
示例代码:
python
from langchain_core.prompts import PromptTemplate
from langchain.chat_models import ChatOpenAI
from pydantic import BaseModel,Field
from langchain.output_parsers import PydanticOutputParser
chat_model = ChatOpenAI(
api_key="none",
base_url="http://localhost:8000/v1",
model="/mnt/e/huggingface_models/Qwen3-0.6B"
)
'''
用于将LLM的输出解析为JSON格式并转换为Pydantic模型。
'''
# 定义输出数据的结构
class Mydata(BaseModel):
event_name: str = Field(description="事件名称")
person: str = Field(description="人物")
time: str = Field(description="时间")
#创建输出解析器
parser = PydanticOutputParser(pydantic_object=Mydata)
prompt = PromptTemplate(
template="回答用户查询.\n{instructions}\n{query}\n",
input_variables=["query"],
# 获取解析器的提示词
partial_variables={"instructions": parser.get_format_instructions()}
)
print(parser.get_format_instructions())
inpute = prompt.format(query="2025国庆节")
res = chat_model.invoke(inpute).content.split("</think>")[-1]
print(parser.parse(res))6. 自动修复解析器(OutputFixingParser)
核心功能:当 LLM 输出不符合解析器要求(如 JSON 语法错误、字段缺失)时,自动生成 "修正提示" 让 LLM 重新生成符合格式的输出,无需人工干预。
工作原理:
- 尝试使用基础解析器解析模型输出。
- 如果解析失败,记录错误并尝试修复输出。
- 如果修复后仍然解析失败,继续重试,直到达到最大重试次数。
- 如果所有重试都失败,最终抛出解析失败的异常。
适用场景:
- LLM 输出格式不稳定(如偶尔生成错误的 JSON);
- 希望自动化处理解析失败的场景(如生产环境中避免流程中断)。
示例代码:
python
from langchain_openai import ChatOpenAI
# 创建模型
chat_model = ChatOpenAI(
api_key="sk-9304b1fa0aa44284b63742b4e8c9b74", # 你的 API key
base_url="https://api.deepseek.com/v1",
model="deepseek-chat"
)
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
class Person(BaseModel):
name: str = Field(description="姓名")
age: int = Field(description="年龄")
# 假设有一个格式不正确的输出(注意:这个假设代表大模型的输出结果)
misformatted = "{'name': 'John', 'age': 30}"#格式不符合Pydantic解析器的要求,里面是单引号
parser = PydanticOutputParser(pydantic_object=Person)
try:
output = parser.parse(misformatted)
print("output:", output)
except Exception as e:
print(e)
# 利用大模型自动修复
from langchain.output_parsers import OutputFixingParser
new_parser = OutputFixingParser.from_llm(parser=parser, llm=chat_model)
output = new_parser.parse(misformatted)
print("output:", output)7. 重试解析器(RetryOutputParser)
核心功能 :与OutputFixingParser类似,用于处理解析失败,但允许自定义 "重试提示",更灵活地引导 LLM 修正输出。
与OutputFixingParser的区别:
- 前者支持自定义重试逻辑和提示模板;
- 后者使用默认修复逻辑,更简单但灵活性低。
适用场景:
- 需要定制化修复提示(如强调特定字段的重要性);
- 复杂解析场景(如嵌套结构错误,需要更详细的修正指引)。
示例代码:
python
from langchain.output_parsers import PydanticOutputParser, RetryOutputParser
from langchain.prompts import PromptTemplate, BasePromptTemplate
from langchain.llms import OpenAI
from pydantic import BaseModel, Field
from typing import List
# 1. 定义Pydantic模型
class Product(BaseModel):
name: str = Field(description="产品名")
prices: List[float] = Field(description="历史价格列表,浮点数")
# 2. 目标解析器
base_parser = PydanticOutputParser(pydantic_object=Product)
# 3. 定义重试提示模板(自定义修复逻辑)
retry_template = """
你之前的输出格式错误:{error}
请修正以下内容,确保prices是浮点数列表:{output}
修正后必须符合格式:{format_instructions}
"""
retry_prompt = PromptTemplate(
input_variables=["error", "output", "format_instructions"],
template=retry_template
)
# 4. 创建重试解析器
llm = OpenAI(temperature=0)
output_parser = RetryOutputParser(
parser=base_parser,
prompt=retry_prompt,
llm=llm
)
# 5. 模拟错误输出(prices包含字符串)
bad_llm_output = '{"name": "笔记本", "prices": ["5999", 6199, 5799]}'
# 6. 重试解析
result = output_parser.parse_with_prompt(bad_llm_output, retry_prompt)
print(result) # 输出:Product(name='笔记本', prices=[5999.0, 6199.0, 5799.0])六、链
在 LangChain 中,链(Chain) 是核心概念之一,它的本质是将多个组件(如提示词模板、LLM、输出解析器、工具等)按特定逻辑串联起来,形成一个可执行的 "流水线",用于处理复杂任务。链解决了单一组件(如单独调用 LLM)无法处理多步骤任务的问题,让开发者可以通过组合组件实现更复杂的功能(如 "检索文档→生成回答→格式化输出" 的完整流程)。
1. 链的核心价值
- 组件协同 :将独立组件(如
PromptTemplate、LLM、OutputParser)按逻辑串联,避免手动分步调用的繁琐。 - 流程封装:将多步骤任务(如 "用户提问→检索知识库→生成回答")封装为一个可复用的链,简化调用。
- 灵活性:支持嵌套、并行等复杂逻辑,满足不同场景需求(如先分析问题类型,再决定调用哪个工具)。
2. 内置链(Built-in Chains)
LangChain 提供了大量开箱即用的内置链,覆盖了常见场景(如问答、摘要、多步骤处理等),无需从零构建。以下是最常用的几种:
2.1 LLMChain:最基础的链(核心)
功能 :将 "提示词模板(PromptTemplate)" 和 "LLM" 组合,生成基于模板的 LLM 调用流程。适用场景:所有需要 "输入变量→生成提示词→调用 LLM" 的基础场景(如文本生成、翻译、简单问答)。
示例代码:
python
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# 1. 定义提示词模板
template = "用{language}翻译这句话:{text}"
prompt = PromptTemplate(input_variables=["language", "text"], template=template)
# 2. 初始化LLM
llm = OpenAI(temperature=0)
# 3. 创建LLMChain(组合模板和LLM)
chain = LLMChain(llm=llm, prompt=prompt)
# 4. 运行链(输入变量)
result = chain.run(language="法语", text="我爱自然语言处理")
print(result) # 输出:J'aime le traitement du langage naturel2.2 SequentialChain:顺序执行多链
功能 :按顺序执行多个链,前一个链的输出作为后一个链的输入,支持多输入、多输出。适用场景:多步骤任务(如 "摘要→翻译→分析情感" 的流水线)。
示例代码:
python
from langchain.chains import SequentialChain, LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# 1. 定义第一个链:生成产品描述
prompt1 = PromptTemplate(
input_variables=["product"],
template="为{product}写一段20字的宣传语:"
)
chain1 = LLMChain(llm=OpenAI(temperature=0.7), prompt=prompt1, output_key="description")
# 2. 定义第二个链:翻译描述为英文
prompt2 = PromptTemplate(
input_variables=["description"],
template="将这段宣传语翻译成英文:{description}"
)
chain2 = LLMChain(llm=OpenAI(temperature=0), prompt=prompt2, output_key="english_description")
# 3. 定义第三个链:分析情感(正面/负面)
prompt3 = PromptTemplate(
input_variables=["english_description"],
template="分析这段英文的情感(仅输出'正面'或'负面'):{english_description}"
)
chain3 = LLMChain(llm=OpenAI(temperature=0), prompt=prompt3, output_key="sentiment")
# 4. 创建顺序链(按chain1→chain2→chain3顺序执行)
overall_chain = SequentialChain(
chains=[chain1, chain2, chain3],
input_variables=["product"], # 初始输入
output_variables=["description", "english_description", "sentiment"], # 最终输出所有中间结果
verbose=True # 打印执行过程
)
# 5. 运行链
result = overall_chain.run(product="无线耳机")
print(result)
# 输出示例:
# {
# "description": "无线自由,纯净音质,畅享每一刻音乐时光",
# "english_description": "Wireless freedom, pure sound quality, enjoy every moment of music",
# "sentiment": "正面"
# }2.3 SimpleSequentialChain:简化的顺序链
功能 :SequentialChain的简化版,仅支持单输入、单输出(前一个链的输出直接作为下一个链的输入),结构更简洁。适用场景:步骤简单、无需保留中间结果的多步骤任务。
示例代码:
python
from langchain.chains import SimpleSequentialChain, LLMChain
from langchain.prompts import PromptTemplate
from langchain.llms import OpenAI
# 1. 第一个链:生成标题
prompt1 = PromptTemplate(input_variables=["topic"], template="为{topic}生成一个吸引人的标题:")
chain1 = LLMChain(llm=OpenAI(temperature=0.8), prompt=prompt1)
# 2. 第二个链:基于标题写摘要
prompt2 = PromptTemplate(input_variables=["title"], template="为这个标题写一段50字摘要:{title}")
chain2 = LLMChain(llm=OpenAI(temperature=0.5), prompt=prompt2)
# 3. 简化顺序链(仅输出最终结果)
overall_chain = SimpleSequentialChain(chains=[chain1, chain2], verbose=True)
# 4. 运行(输入topic,输出最终摘要)
result = overall_chain.run(topic="人工智能在医疗中的应用")
print(result) # 输出:基于标题的摘要内容2.3RetrievalQA:检索增强问答链
功能 :将 "检索器(Retriever,用于从知识库中找相关文档)" 和 "LLM" 结合,实现 "基于检索到的文档回答问题"(避免 LLM 幻觉)。适用场景:需要结合外部知识库的问答(如企业文档问答、专业领域问答)。
示例代码:
python
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
# 1. 加载知识库(示例:本地文本文件)
loader = TextLoader("medical_knowledge.txt") # 假设文件包含医疗知识
documents = loader.load()
# 2. 分割文档并创建向量库(用于检索)
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever() # 创建检索器
# 3. 创建RetrievalQA链(检索+问答)
qa_chain = RetrievalQA.from_chain_type(
llm=OpenAI(temperature=0),
chain_type="stuff", # 文档处理方式(stuff指将所有文档塞进提示词)
retriever=retriever,
return_source_documents=True # 返回用于回答的源文档
)
# 4. 运行链(提问)
query = "糖尿病患者适合吃哪些水果?"
result = qa_chain({"query": query})
print("回答:", result["result"])
print("来源文档:", [doc.page_content for doc in result["source_documents"]])其他常用内置链
MapReduceDocumentsChain:分块处理长文档(先单独处理每个片段,再汇总结果),适合长文本摘要。RefineDocumentsChain:迭代优化文档处理结果(基于前一个片段的结果处理下一个片段),适合高精度长文本分析。ConversationalRetrievalChain:结合检索和对话历史,支持多轮对话式问答(如 "基于历史对话继续提问")。
3. 自定义链(Custom Chains)
当内置链无法满足特定需求(如复杂业务逻辑、特殊组件组合)时,可通过自定义链实现。自定义链的核心是继承Chain类,定义输入 / 输出键和执行逻辑。
自定义链的实现步骤
- 继承
langchain.chains.base.Chain类; - 定义
input_keys(输入变量名列表)和output_keys(输出变量名列表); - 实现
_call方法(核心逻辑:接收输入,处理后返回输出); - (可选)实现
_chain_type属性(标识链类型)。
【自定义链示例:"文本长度过滤 + 翻译" 链】
需求:先过滤掉过短的文本(<5 个字),再将合格文本翻译成英文。
python
from langchain.chains import Chain
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from typing import Dict, List
class FilterAndTranslateChain(Chain):
# 定义链依赖的组件(需在初始化时传入)
llm: OpenAI
translate_prompt: PromptTemplate
@property
def input_keys(self) -> List[str]:
# 输入变量:待处理的文本
return ["text"]
@property
def output_keys(self) -> List[str]:
# 输出变量:处理结果(是否合格+翻译)
return ["is_valid", "translated_text"]
def _call(self, inputs: Dict[str, str]) -> Dict[str, str]:
text = inputs["text"]
# 1. 过滤逻辑:文本长度<5则不合格
if len(text) < 5:
return {"is_valid": False, "translated_text": ""}
# 2. 翻译逻辑:调用LLM翻译
translated = self.llm(
self.translate_prompt.format(text=text)
)
return {"is_valid": True, "translated_text": translated}
@property
def _chain_type(self) -> str:
return "filter_and_translate_chain"
# 使用自定义链
if __name__ == "__main__":
# 1. 定义翻译提示词模板
translate_template = "将这句话翻译成英文:{text}"
translate_prompt = PromptTemplate(
input_variables=["text"],
template=translate_template
)
# 2. 初始化自定义链
custom_chain = FilterAndTranslateChain(
llm=OpenAI(temperature=0),
translate_prompt=translate_prompt
)
# 3. 测试(短文本:被过滤)
result1 = custom_chain.run(text="你好")
print(result1) # 输出:{'is_valid': False, 'translated_text': ''}
# 4. 测试(长文本:被翻译)
result2 = custom_chain.run(text="自然语言处理很有趣")
print(result2) # 输出:{'is_valid': True, 'translated_text': 'Natural language processing is interesting'}