大家好,我是python222_小锋老师,看到一个不错的基于Python的深度学习音乐推荐系统(后端Django),分享下哈。
项目视频演示
https://www.bilibili.com/video/BV1mznFzEEHF/
项目介绍
数字化时代带动着整个社会的信息化发展,随着数字媒体的不断发展,现在通多媒体数字产品的内容越来越丰富,传播影响力越来越强,以音乐为例,现在的音乐文化多样、音乐资源也异常的丰富,在这种大数据的环境下,人们要想找到想要的音乐类型、找到心里所想的那首音乐无疑是大海捞针。现在音乐的推荐系统也非常的多,但是推荐的内容、推荐的方式却与用户的感知差距明显,或多或少都会存在一些问题。而随着深度学习、卷积神经网络的不断发展,现在的深度学习在图像识别、自然语言等领域都有着很好的发展,也很好的应用在了音乐的推荐过程中。
本次的研究是基于使用自动编码器,通过与卷积神经网络相结合,以挖掘音频、歌词本身的非线性特征,来实现很好的音乐推荐、音乐查找识别的功能实现,并将内容特征与协同过滤共同作用,训练紧耦合模型。通过此次的系统搭建与开发,能够通过深度学习的方式让系统可以实现按照用于的喜好来进行音乐的推荐的功能实现。
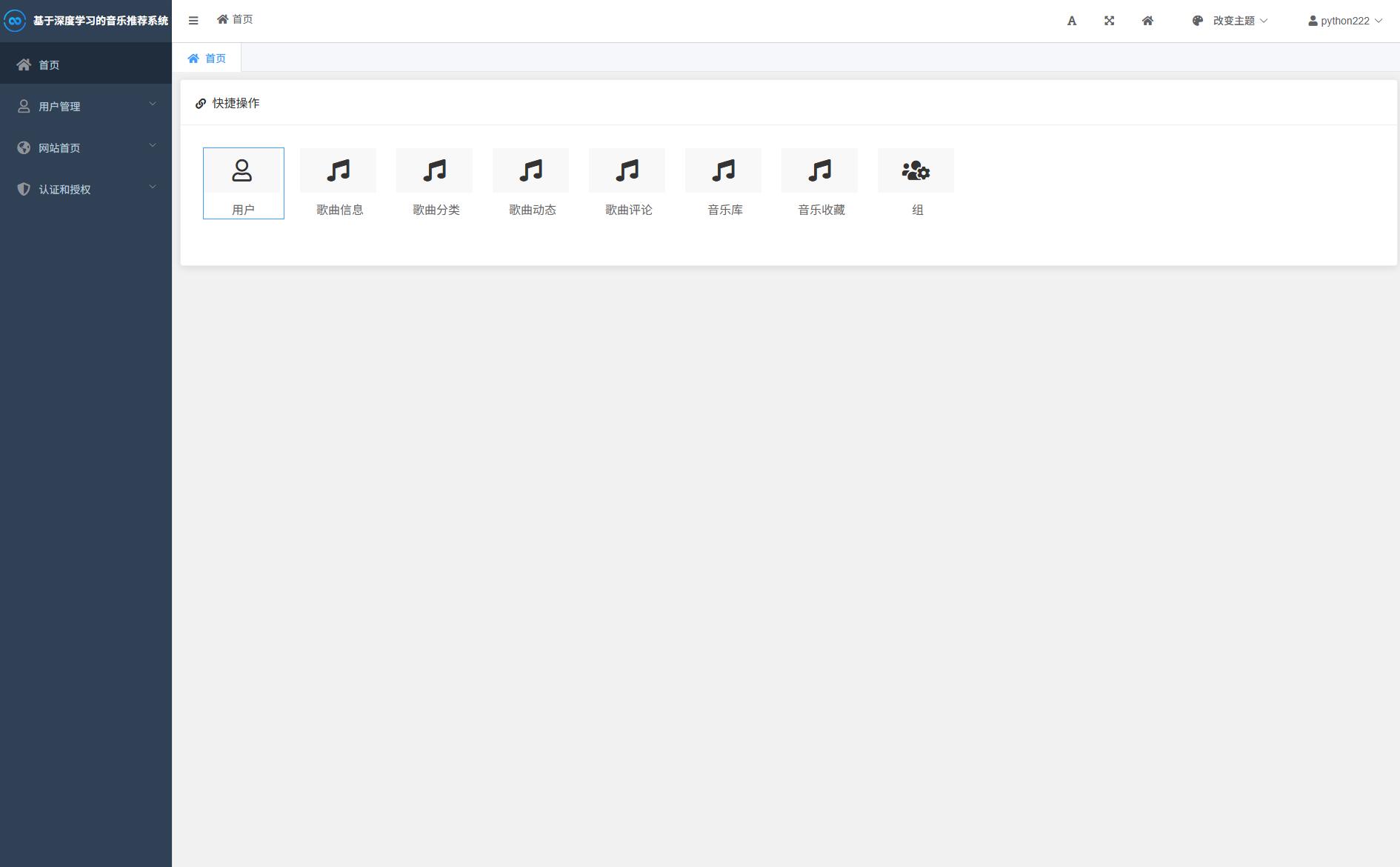
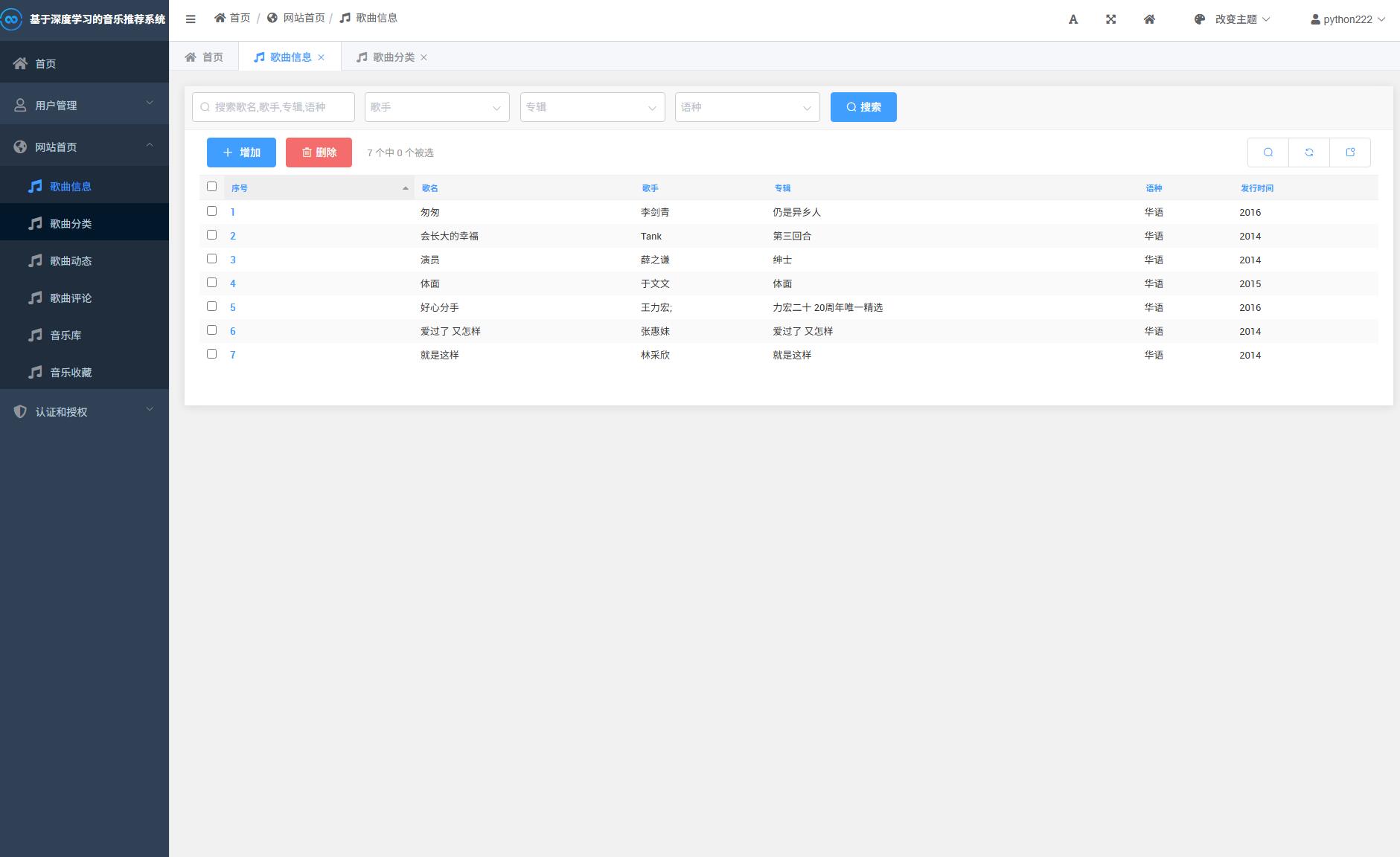
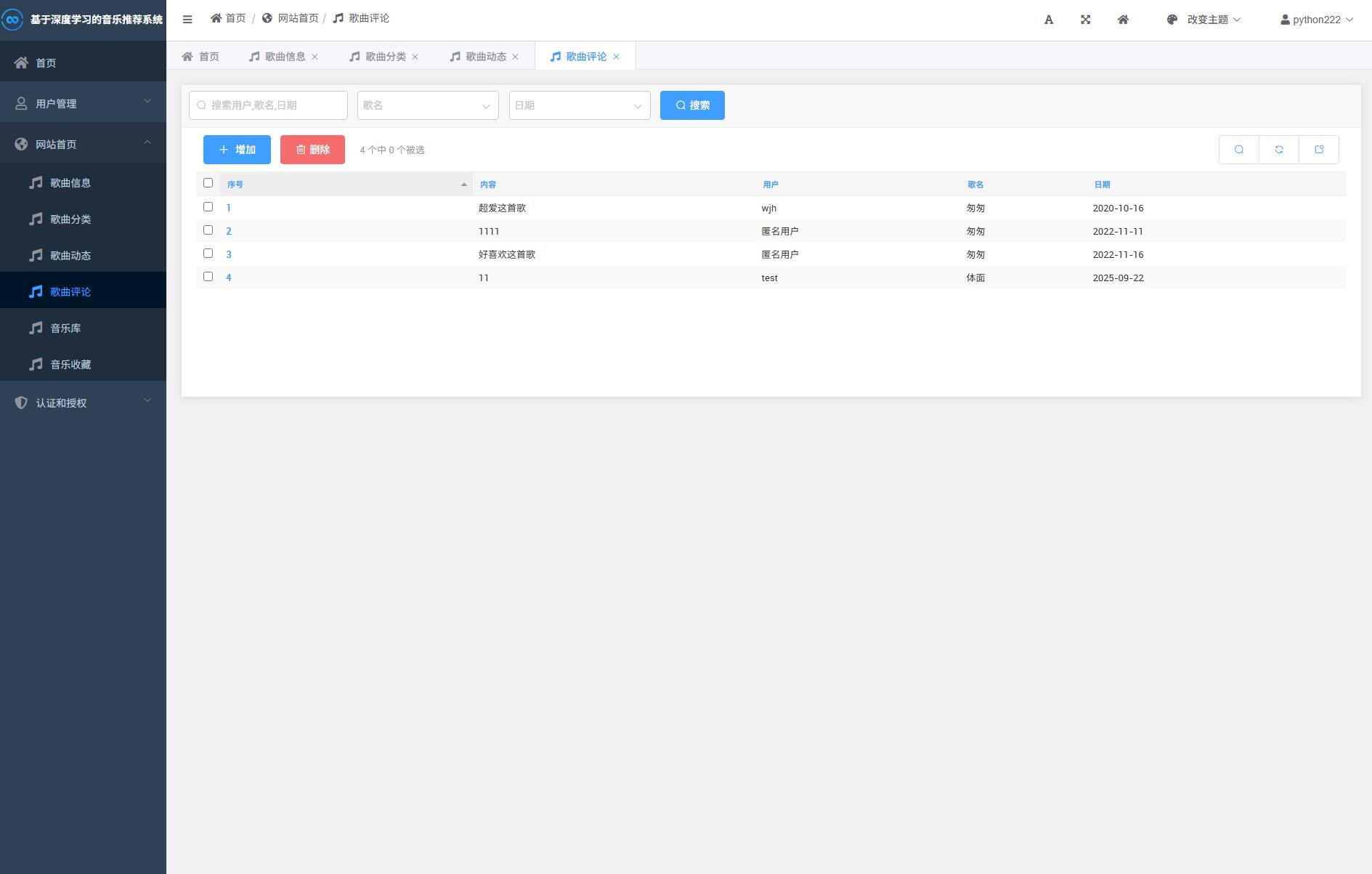
系统展示
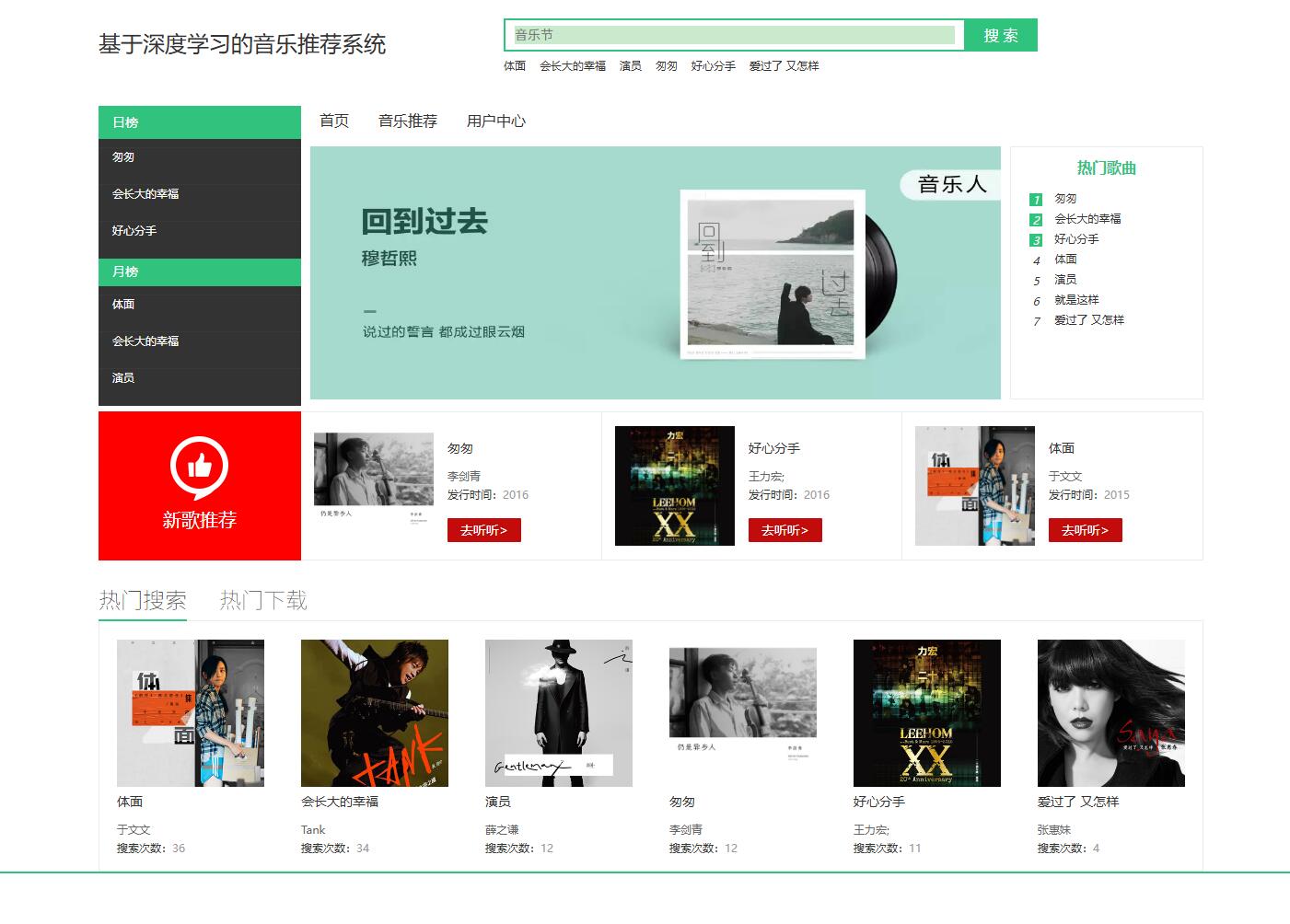
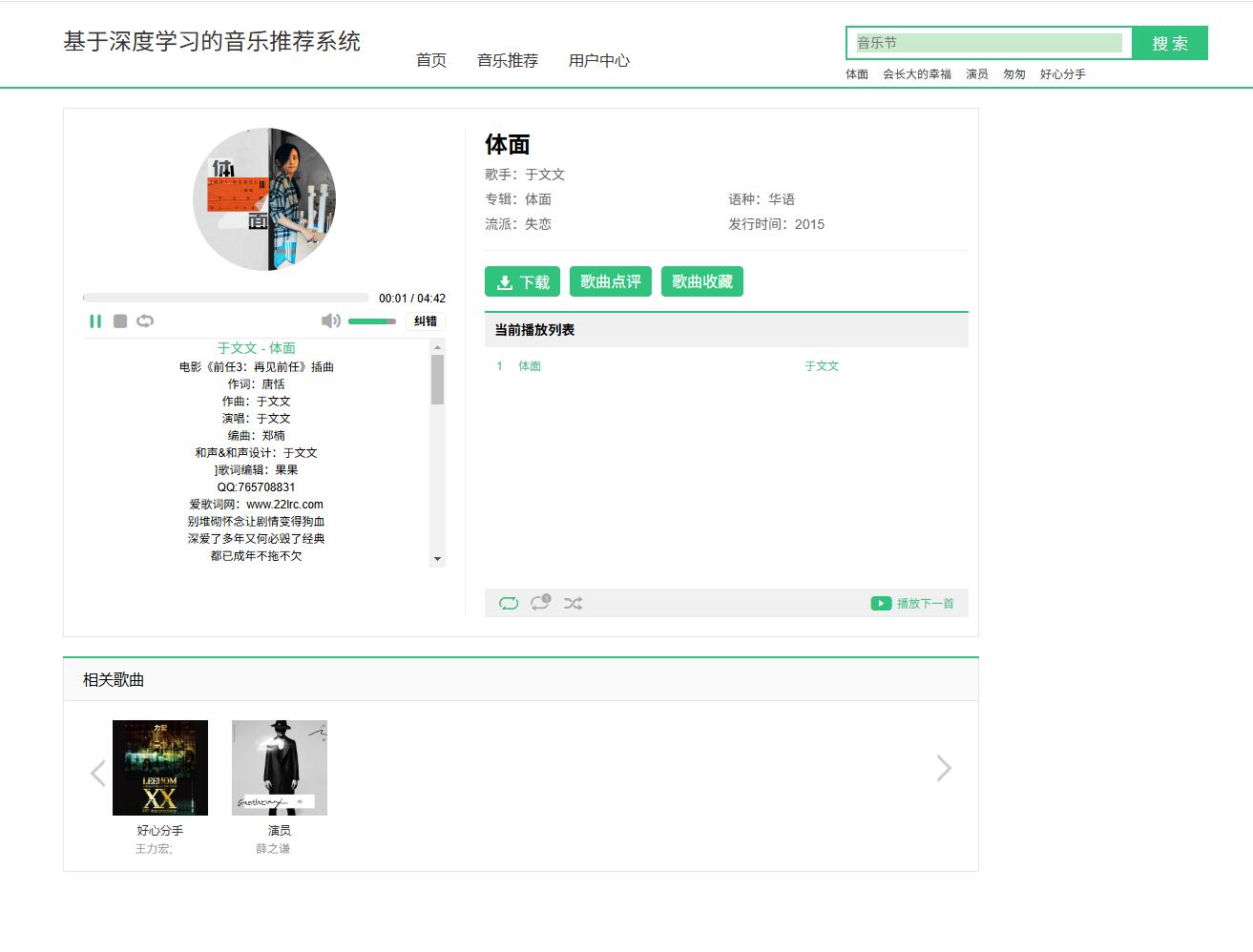
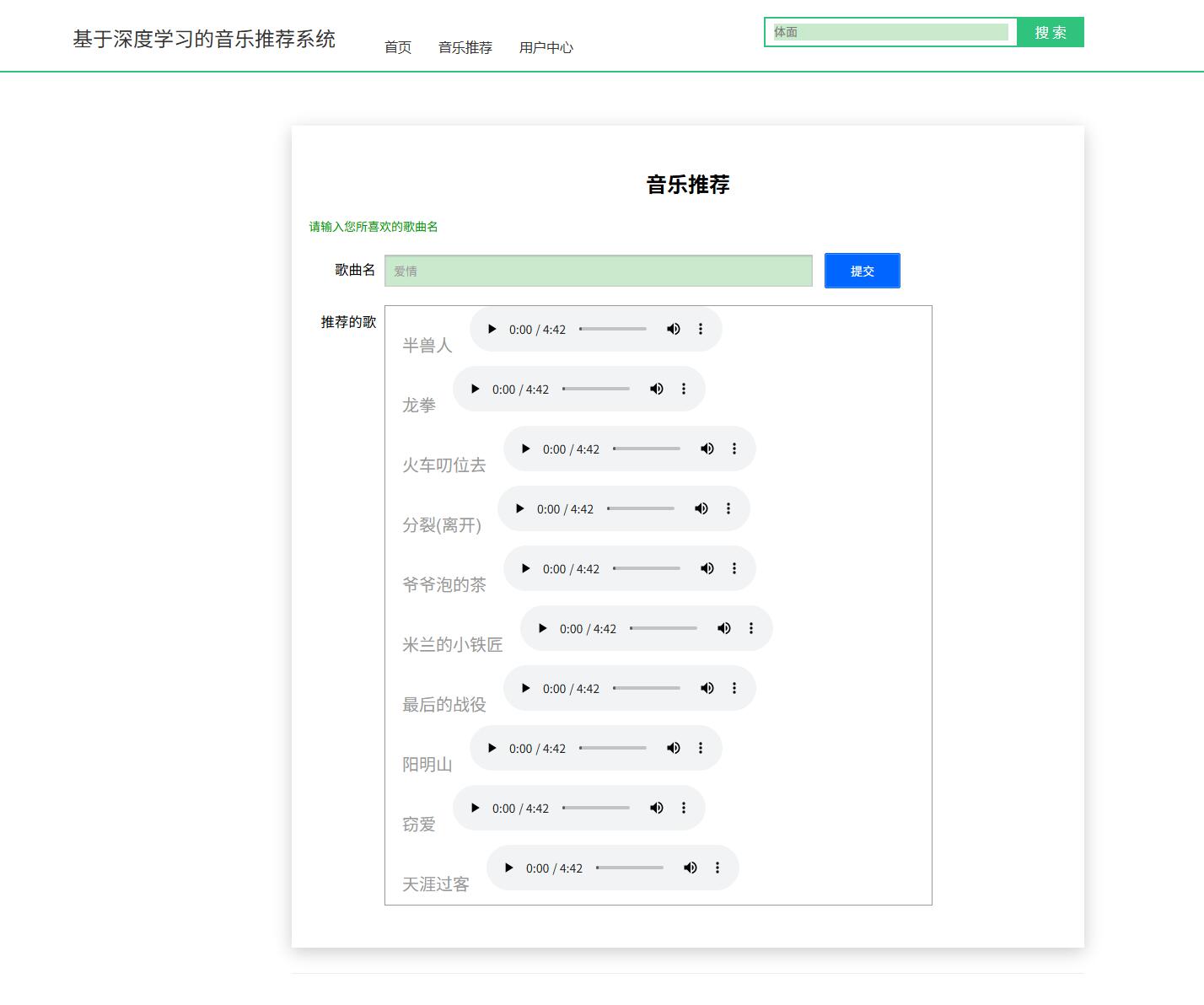
部分代码
import re
from django.db.models import Max, Count
from django.http import JsonResponse
from django.shortcuts import render
from django.views import View
from index.models import Song, Dynamic,Music
from .predict import predict_baseon_item
def check(str):
my_re = re.compile(r'[A-Za-z]', re.S)
res = re.findall(my_re, str)
if len(res):
return True
else:
return False
class RankingView(View):
def get(self, request):
from .tests import main
results = Music.objects.all()
#
# for i in results:
# url = main(i.name)
# if not url:
# url = ''
#
# Music.objects.filter(id=i.id).update(
# url=url
# )
#rint('{}已更新{}'.format(i.name,url))
# 热搜歌曲
search_song = Dynamic.objects.all().order_by('-dynamic_plays')[0]
music_type = Song.objects.filter(song_id=search_song.song_id).first().song_type
songs = Song.objects.filter(song_type=music_type).all()
print(music_type)
# 歌曲分类列表
# All_list = Song.objects.values('song_type').distinct() # 去重
# 歌曲信息列表
song_type = request.GET.get('type', '')
return render(request, 'ranking/ranking.html', {'songs':songs})
def predict(request):
inputText = request.POST.get("name")
result= predict_baseon_item(str(inputText))
print('1111',result)
result_list = []
if not result:
pid = Music.objects.filter(name=inputText).first().pid
all_data = Music.objects.filter(pid=pid).all()
if len(all_data) > 10:
all_data = all_data[0:10]
for i in all_data:
result_dict = {
'name':i.name,
'singer':i.singer,
'src':'/static/songFile/体面.m4a',
}
result_list.append(result_dict)
else:
for i in result:
obj_music = Music.objects.filter(name=i).first()
result_dict = {
'name': i,
'src': '/static/songFile/体面.m4a',
}
result_list.append(result_dict)
print(result_list)
return JsonResponse({'input_text': inputText, 'result_list': result_list})
# -*- coding: UTF-8 -*-
import os
import pickle
import surprise
from surprise import KNNBaseline, Reader
from surprise import Dataset
work_dir = os.path.dirname(os.path.abspath(__file__))
def split_file(in_path, out_path, scale):
f1 = open(in_path, "r")
f2 = open(out_path, "w")
context = f1.readlines()
offset = int(len(context) * scale)
print("new length:", offset)
split_context = ""
for i in range(offset):
split_context += context[i]
f2.write(split_context)
f1.close()
f2.close()
# data pre-prossess
def parse_playlist_get_info(in_line, playlist_dic, song_dic):
contents = in_line.strip().split("\t")
name, tags, playlist_id, subscribed_count = contents[0].split("##")
playlist_dic[playlist_id] = name
for song in contents[1:]:
try:
print(song)
song_id, song_name, artist, popularity = song.split(":::")
song_dic[song_id] = song_name
except Exception as e:
print("song format error", e)
print(song + "\n")
def parse_file(in_file, out_playlist, out_song):
# 从歌单id到歌单名称的映射字典
playlist_dic = {}
# 从歌曲id到歌曲名称的映射字典
song_dic = {}
for line in open(in_file, 'r', encoding='UTF-8'):
parse_playlist_get_info(line, playlist_dic, song_dic)
# 把映射字典保存在二进制文件中
pickle.dump(playlist_dic, open(out_playlist, "wb"))
# 可以通过 playlist_dic = pickle.load(open("playlist.pkl","rb"))重新载入
pickle.dump(song_dic, open(out_song, "wb"))
def data_preprocess():
playlist_id_name_dic_file = os.path.join(work_dir, "data/playlist_id_name_dic.pkl")
song_id_name_dic_file = os.path.join(work_dir, "data/song_id_name_dic.pkl")
input_file = os.path.join(work_dir, "data/popular.playlist")
# 解析文件,保存字典「歌单ID-歌单名称」、字典「歌曲ID-歌曲名称」
parse_file(in_file=input_file, out_playlist=playlist_id_name_dic_file, out_song=song_id_name_dic_file)
print("已保存字典「歌单ID-歌单名称」、字典「歌曲ID-歌曲名称」")
def train_baseon_item():
# 数据预处理
data_preprocess()
path = os.path.join(work_dir, "data/")
file_path = os.path.expanduser(path + "popular_music_suprise_format1.txt")
# 指定文件格式
reader = Reader(line_format='user item rating timestamp', sep=',')
# 从文件读取数据
music_data = Dataset.load_from_file(file_path, reader=reader)
# 计算歌曲和歌曲之间的相似度
print("构建数据集...")
trainset = music_data.build_full_trainset() # 把全部数据进行训练,不进行交叉验证
print("开始训练模型...")
sim_options = {'user_based': False} # 基于歌曲的协同过滤
algo = KNNBaseline(sim_options=sim_options)
# algo = SVD(sim_options=sim_options)
algo.fit(trainset)
surprise.dump.dump(os.path.join(work_dir, 'model/KNNBaseline_Item_Recommand.model'), algo=algo)
# 保证数据一致性
# 重建歌曲id到歌曲名的映射字典
f1 = open(path + "song_id_name_dic.pkl", "rb")
song_id_name_dic = pickle.load(f1)
f1.close()
f2 = open(path + "popular_music_suprise_format1.txt")
context = f2.readlines()
new_song_id_name_dic = {}
for line in context:
playlist_id, song_id, rating, time = line.split(',')
new_song_id_name_dic[song_id] = song_id_name_dic[song_id]
pickle.dump(new_song_id_name_dic, open(path + "song_id_name_dic.pkl", "wb"))
f2.close()
def train_baseon_playlist():
# 数据预处理
data_preprocess()
path = os.path.join(work_dir, "data/")
file_path = os.path.expanduser(path + "popular_music_suprise_format.txt")
# 指定文件格式
reader = Reader(line_format='user item rating timestamp', sep=',')
# 从文件读取数据
music_data = Dataset.load_from_file(file_path, reader=reader)
# 计算歌单和歌单之间的相似度
print("构建数据集...")
trainset = music_data.build_full_trainset() # 把全部数据进行训练,不进行交叉验证
print("开始训练模型...")
sim_options = {'user_based': True} # 基于歌单的协同过滤
algo = KNNBaseline(sim_options=sim_options)
algo.fit(trainset)
surprise.dump.dump(os.path.join(work_dir, 'model/KNNBaseline_Playlist_Recommand.model'), algo=algo)
# 保证数据一致性
# 重建歌单id到歌单名的映射字典
f1 = open(path + "playlist_id_name_dic.pkl", "rb")
playlist_id_name_dic = pickle.load(f1)
f1.close()
f2 = open(path + "popular_music_suprise_format1.txt")
context = f2.readlines()
new_playlist_id_name_dic = {}
for line in context:
playlist_id, song_id, rating, time = line.split(',')
new_playlist_id_name_dic[playlist_id] = playlist_id_name_dic[playlist_id]
pickle.dump(new_playlist_id_name_dic, open(path + "playlist_id_name_dic.pkl", "wb"))
f2.close()
def predict_baseon_item(song_name):
path = os.path.join(work_dir, "data/")
# 重建歌曲id到歌曲名的映射字典
song_id_name_dic = pickle.load(open(path + "song_id_name_dic.pkl", "rb"))
# 重建歌单名到歌单id的映射字典
song_name_id_dic = {}
for song_id in song_id_name_dic:
song_name_id_dic[song_id_name_dic[song_id]] = song_id
if song_name not in song_name_id_dic.keys():
return "数据库还没有收录这首歌"
_, algo = surprise.dump.load(os.path.join(work_dir, 'model/KNNBaseline_Item_Recommand.model'))
# 取出近邻
# 映射名字到id
song_id = song_name_id_dic[song_name]
print("歌曲id", song_id)
# 取出来对应的内部item id => to_inner_iid
try:
song_inner_id = algo.trainset.to_inner_iid(song_id)
except Exception as e:
print("查找内部歌曲id发生异常:", e)
song_list_neighbors = []
return
else:
print("歌曲内部id", song_inner_id)
song_list_neighbors = algo.get_neighbors(song_inner_id, k=10)
# 把歌曲id转成歌曲名字
# to_raw_uid映射回去
song_list_neighbors = (algo.trainset.to_raw_iid(inner_id)
for inner_id in song_list_neighbors)
song_list_neighbors = list(song_id_name_dic[song_id]
for song_id in song_list_neighbors)
result = ""
for song_name in song_list_neighbors:
result += song_name
return song_list_neighbors
def predict_baseon_playlist(playlist_name):
path = "./data/"
# 重建歌单id到歌单名的映射字典
playlist_id_name_dic = pickle.load(open(path + "playlist_id_name_dic.pkl", "rb"))
# 重建歌单名到歌单id的映射字典
playlist_name_id_dic = {}
for playlist_id in playlist_id_name_dic:
playlist_name_id_dic[playlist_id_name_dic[playlist_id]] = playlist_id
# if playlist_name not in playlist_name_id_dic.keys():
# return "数据库还没有收录这首歌"
_, algo = surprise.dump.load(path + '/KNNBaseline_Playlist_Recommand.model')
# 取出近邻
# 映射名字到id
print(playlist_name_id_dic)
playlist_id = playlist_name_id_dic[playlist_name]
print("歌单id", playlist_id)
# 取出来对应的内部user id => to_inner_uid
try:
playlist_inner_id = algo.trainset.to_inner_uid(playlist_id)
except ValueError:
print("查找内部歌曲id发生异常:", ValueError.__name__)
return
else:
print("歌曲内部id", playlist_inner_id)
playlist_list_neighbors = algo.get_neighbors(playlist_inner_id, k=10)
# 把歌曲id转成歌曲名字
# to_raw_uid映射回去
playlist_list_neighbors = (algo.trainset.to_raw_uid(inner_id)
for inner_id in playlist_list_neighbors)
# raw_uid -> playlist_name
playlist_list_neighbors = list(playlist_id_name_dic[playlist_id]
for playlist_id in playlist_list_neighbors)
playlist_list_neighbors.insert(0, "和歌单 《" + playlist_name + "》 最接近的10个歌曲为:")
for song_name in playlist_list_neighbors:
print(song_name)
return playlist_list_neighbors
if __name__ == '__main__':
# data_preprocess()
# file = open("./data/song_id_name_dic.pkl",'rb')
# song_id_name_dic = pickle.load(file)
# key = list(song_id_name_dic.keys())[6]
# print(song_id_name_dic[key])
# file.close()
# data_preprocess()
# file = open("./data/playlist_id_name_dic.pkl",'rb')
# playlist_id_name_dic = pickle.load(file)
# keys = list(playlist_id_name_dic.keys())[:30]
# for key in keys:
# print(playlist_id_name_dic[key])
# file.close()
# predict_baseon_playlist("中国好声音第四季原唱")
# result = predict("本草纲目")
# predict(result)
split_file("./data/popular_music_suprise_format.txt", "./data/popular_music_suprise_format1.txt", 0.08)
train_baseon_item()
train_baseon_playlist()源码下载
链接:https://pan.baidu.com/s/1JUD11ciMD4MmInyPw4WWaQ
提取码:1234
