在使用spring ai 想构建一个rag demo被坑到想哭
软件版本
xml
<spring-ai-bom.version>1.0.2</spring-ai-bom.version>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai-bom.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId>
<exclusions>
java
/**
* 1. ETL文档入库
* 将pdf写入到向量库中
*
* @return
*/
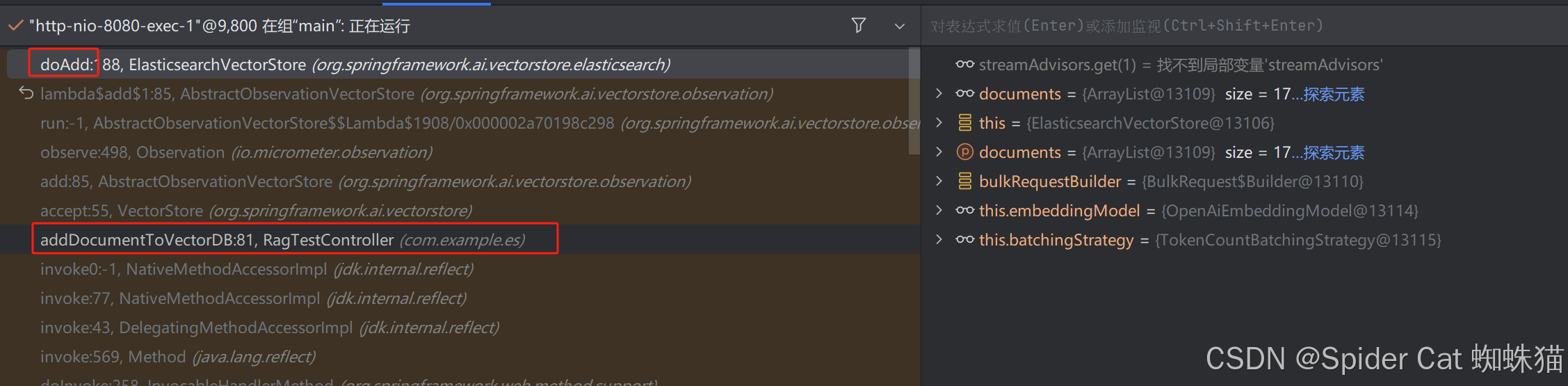
@GetMapping("/addDocumentToVectorDB")
public List<Document> addDocumentToVectorDB() {
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource);
// 将文件中的文本分割为多组Document
List<Document> fileDocuments = tikaDocumentReader.get();
// 基于Token将多组Document进行更细化的分割
List<Document> documents = tokenTransformer.apply(fileDocuments);
// 存储到向量数据库中
vectorStore.accept(documents);
return documents;
}选择embedding模型
yml
spring:
ai:
openai:
embedding:
options:
# 向量模型
model: doubao-embedding-large-text-250515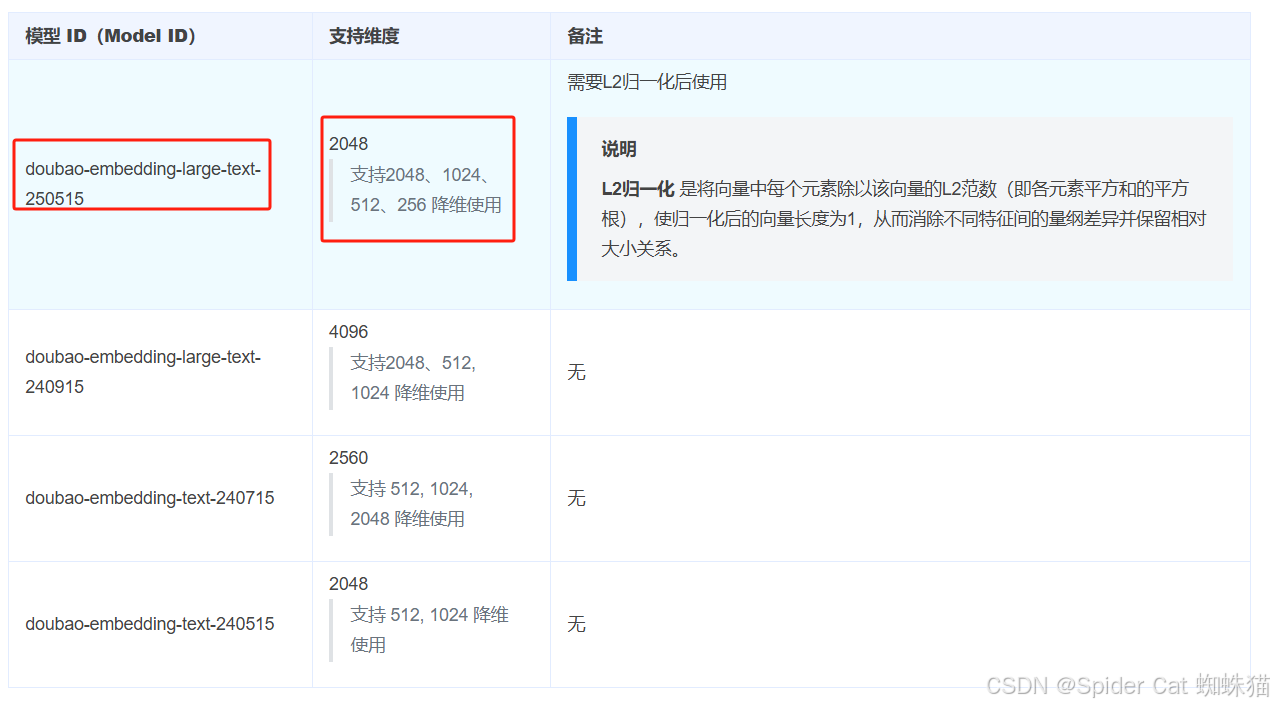
如果模型选择doubao-embedding-text-240715,它默认维度是2560和elasticsearch集成,elasticsearch最大就是2048,又集成不了,恶心
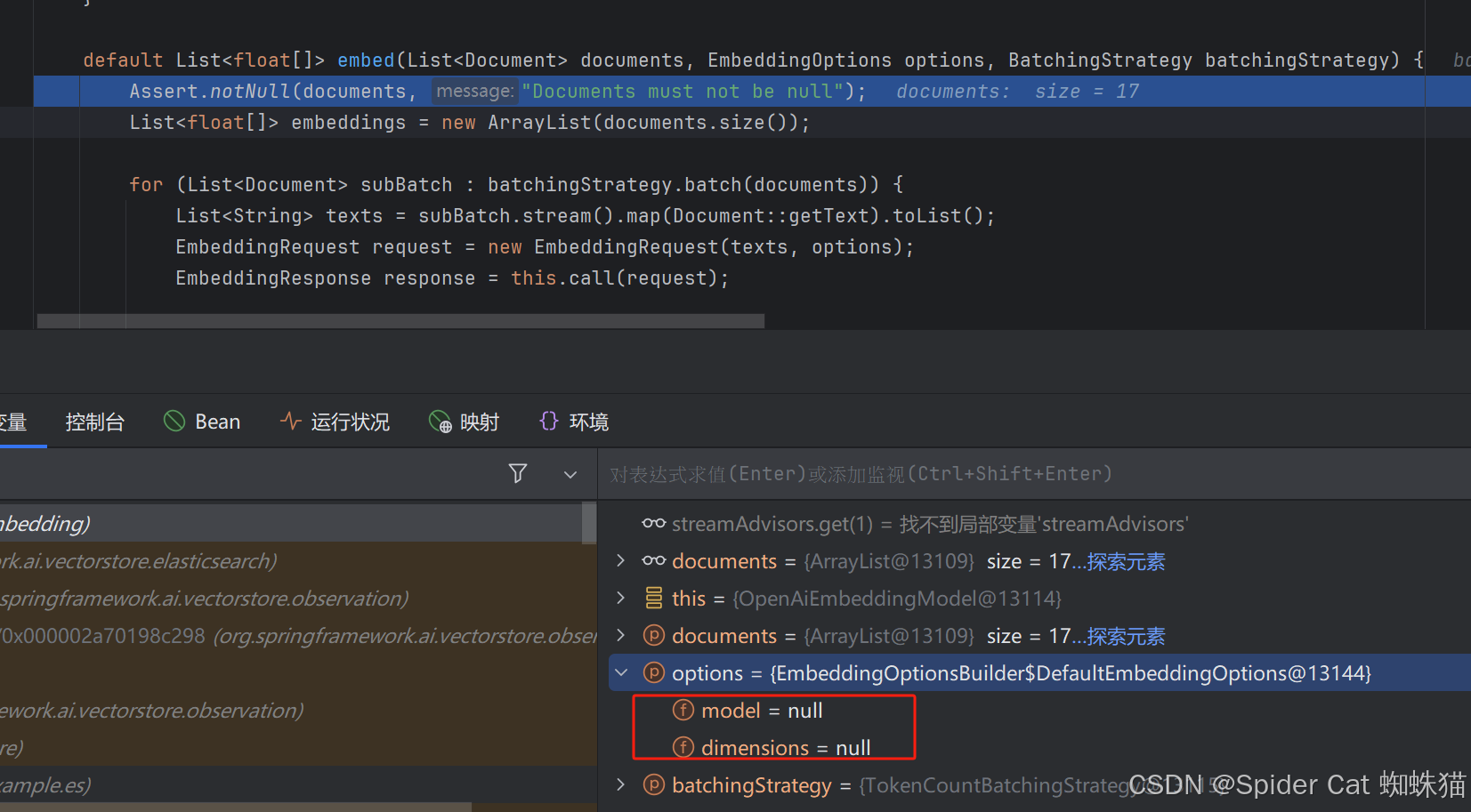
在addDocumentToVectorDB中vectorStore.accept(documents)调用的实现类为ElasticsearchVectorStore
具体代码为
java
List<float[]> embeddings = this.embeddingModel.embed(documents, EmbeddingOptionsBuilder.builder().build(), this.batchingStrategy);EmbeddingOptionsBuilder.builder().build()这部分代码没有使用到配置文件中的对模型维度的声明
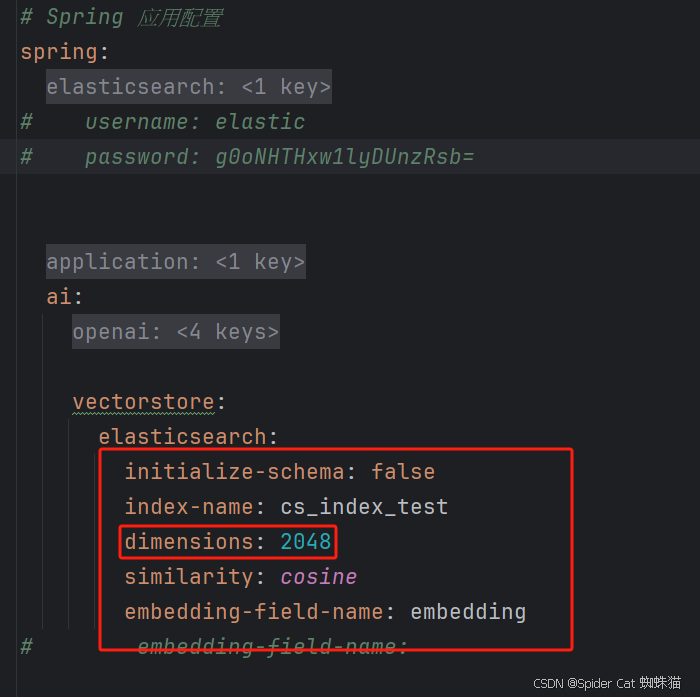
进入这个方法中this.embeddingModel.embed(),就会发现都为空,然后就会使用模型默认的维度,太恶心了,所以只能使用维度为2048的模型,这里spring ai 设置完全没有用,完全在搞笑