总结:前面是各版本对比+流程图表对比,可以拿了去做组会汇报,后面是dinov3的详解结构讲解(张量变化角度),然后是实际的GitHub项目中的下流任务的流程图(主要是分割的详细流程,还有深度,分类,检测的比较复杂没画),最后还有一个dinov3 LORA的项目推荐和部分分析讲解。
一.DINOv1到v3区别和变化
1.结构区别流程图
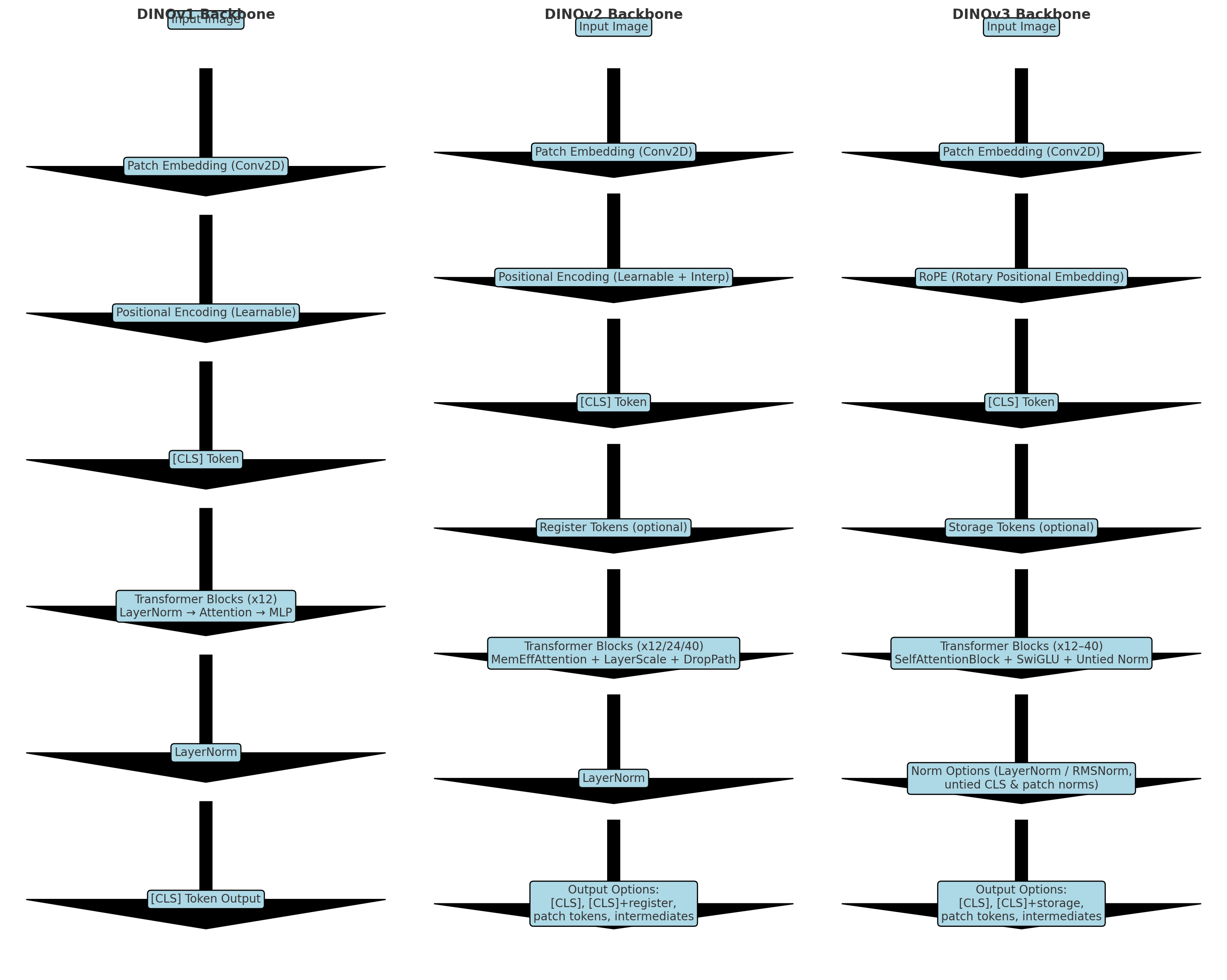
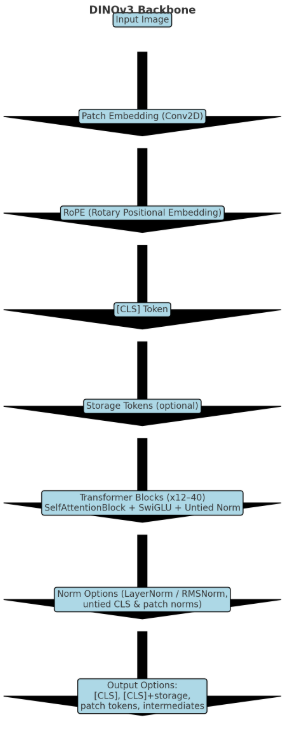
2.结构区别
| 对比维度 | DINOv1 | DINOv2 | DINOv3 |
|---|---|---|---|
| Patch Embedding | Conv2D (patch=16, embed_dim=192/384/768) | Conv2D (patch=16, embed_dim=384/768/1024/1536) | Conv2D (patch=16, embed_dim=384/768/1024/1152/1280/1536/4096) |
| Positional Encoding | Learnable positional embeddings | Learnable embeddings + 插值 (interpolation) | RoPE (Rotary Position Embedding) |
| 额外 Tokens | CLS Token | CLS + 可选 Register Tokens | CLS + 可选 Storage Tokens |
| Transformer Blocks | 基本 Self-Attention + MLP | MemEffAttention, MLP/SwiGLU 可选, + LayerScale + Stochastic Depth | SelfAttentionBlock, 支持 SwiGLU 变体, 更灵活的正则化 (untied norms, LayerNorm/RMSNorm) |
| 归一化 (Norm) | LayerNorm (统一) | LayerNorm (+ LayerScale, drop path) | 灵活配置:LayerNorm 或 RMSNorm, Untied CLS / patch norm |
| 输出策略 | CLS token only | 多样: CLS, CLS+register, patch tokens, 中间层 | 多样: CLS, CLS+storage, patch tokens, 中间层 |
| 参数规模范围 | 5.7M -- 86.6M | 22M -- 1.1B | 22M -- 7.4B |
| 代表性改进 | 标准 ViT | 高效 Attention (MemEff), LayerScale, Stochastic Depth, Register Tokens | RoPE, Storage Tokens, 灵活 norm, 更大模型 (SO400M / Huge2 / Giant2 / 7B) |
3.论文图表
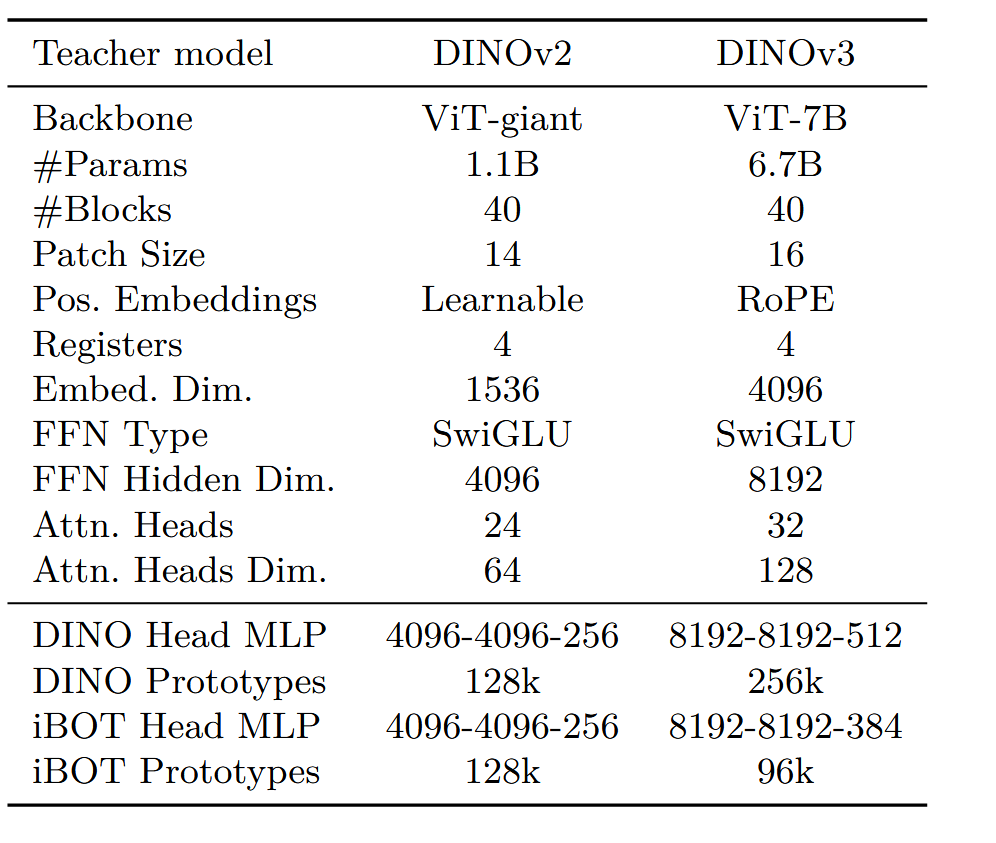
4.DINO在1,2,3版本之间的详细区别
| 对比维度 | DINO (2021) | DINOv2 (2024) | DINOv3 (2025) |
|---|---|---|---|
| 核心思想 | 自监督蒸馏 (student-teacher EMA);multi-crop | DINO + iBOT 结合,双头 (image-level + patch-level) | Online Token Matching:统一目标,去掉多头/正则 |
| 架构设计 | 单 projection head (MLP);teacher/student 同构 | 双 projection head;额外引入 Sinkhorn-Knopp、KoLeo 正则;高分辨率阶段 | 单一 head;动态 token matching;无额外正则;更简洁 |
| 目标函数 | 交叉熵,避免 collapse 依赖 centering + sharpening | 组合:DINO loss + iBOT masked prediction + 正则项 | 单一 token matching loss,同时覆盖全局与局部特征 |
| 数据规模 | ImageNet-1k (无监督) | LVD-142M (142M curated images);高质量大规模 | 延续大规模 curated data,但更高效训练 |
| 模型规模 | ViT-S/B (20M--85M 参数) | ViT-B/L/H/g (到 1.1B 参数),并用蒸馏扩展小模型 | 同级别 ViT,但训练效率更高,低算力场景更优 |
| 性能特点 | 在 ImageNet 上首次展示 ViT 自监督能达到 ~80% linear probe;attention 显式捕捉分割 | 多任务领先,dense prediction 更强,性能接近弱监督 (OpenCLIP) | 泛化更均衡,zero-shot/linear probe 更强,低算力场景优于 v2 |
| 工程复杂度 | 中等,目标函数简单,超参数少 | 高,双头 + 多正则,调参复杂;依赖大算力和工程优化 | 低,目标函数简化,复现和部署更友好 |
| 适合场景 | 小规模实验;证明 ViT 自监督潜力 | 大规模训练、追求多任务极限性能 | 需要通用 backbone;算力有限;追求高效、易用和泛化 |
二. DINOv3详解和下游使用
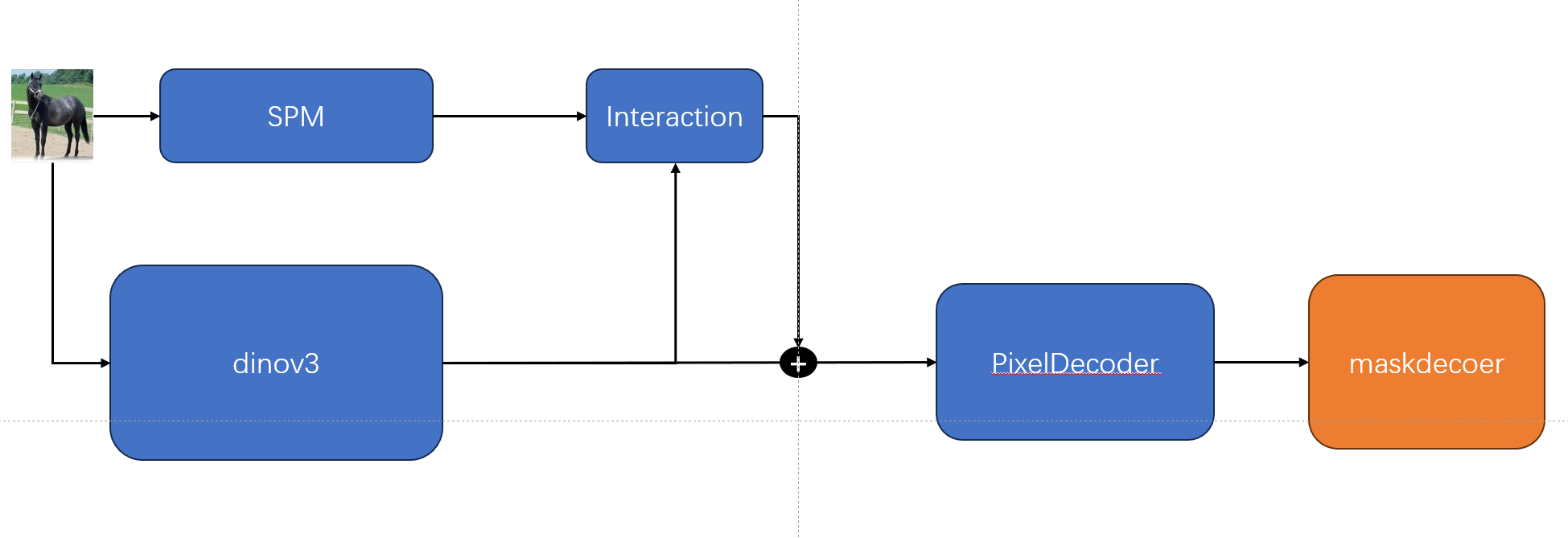
1.用于分割(大致流程图)
像素解码器(结构为当前代码实际版本,fpn+多尺度可变注意力,结构有些丑,不过是实际情况,并且笔者实测效果不错)
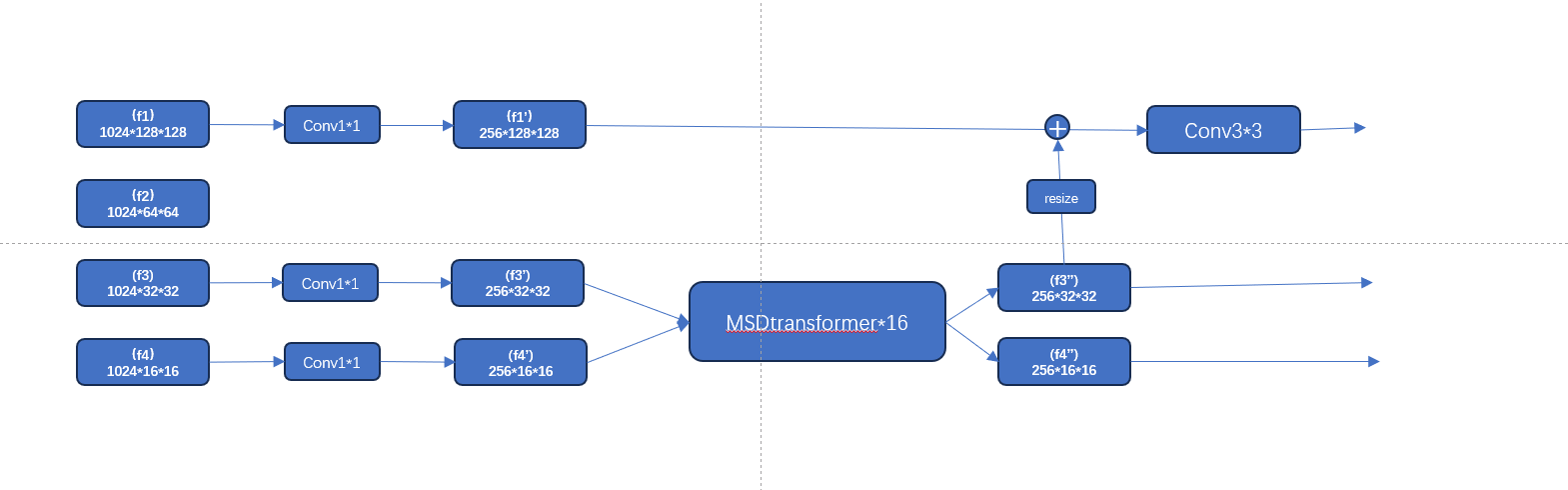
两种融合方式的优缺点
1. 多尺度可变形注意力融合 (MSDeformAttn)
优点:
真正的全局和跨尺度融合:这是它最核心的优势。一个像素点的特征可以直接、自适应地从所有其他尺度的特征图上采样信息。它能轻松建立图像中任意两个遥远像素之间的关系(例如,左手和右脚的关系),这是卷积网络难以做到的。
强大的上下文建模能力:由于其全局视野,它非常擅长理解高级语义。对于骨架检测,它能理解"这是一条完整的胳膊",而不仅仅是"这里有一些像素看起来像皮肤"。
内容自适应 (Content-Adaptive):注意力机制是动态的。模型会学习去哪里寻找最有价值的信息,而不是像卷积那样使用固定的、一成不变的模式去扫描。
缺点:
计算成本高昂:尽管"可变形"已经比标准Transformer高效很多,但与简单的卷积和上采样相比,它的计算量和内存消耗依然巨大。
不擅长保留高频细节:在进行全局关系建模时,可能会平滑或丢失一些精细的、像素级的纹理和边缘信息。将它应用于非常高分辨率的特征图(如res2)会极其昂贵且收益递减。
2. FPN上采样+卷积融合
优点:
高效且轻量:它的核心操作是插值(上采样)、逐元素相加和3x3卷积,这些都是计算速度极快、内存占用很低的操作。
擅长保留空间细节:卷积操作天生就是为了处理局部空间信息而设计的。FPN通过自顶向下的路径,能非常有效地将高层语义(来自深层网络)与高分辨率特征图的精细空间细节(如边缘、角点)对齐和结合。
结构简单、鲁棒:FPN是一个被广泛验证、非常稳定有效的结构,易于实现和理解。
缺点:
感受野受限,融合局部化:FPN的每一步融合都非常"局部"。它通过+操作将两个特征图相加,但这种融合是点对点的,缺乏对长距离依赖的建模。它只能通过不断堆叠来间接扩大感受野。
融合方式固定:它总是通过上采样和相加来融合,这种方式是固定的,不能像注意力那样根据图片内容动态调整融合策略。
详细版(但head简化)
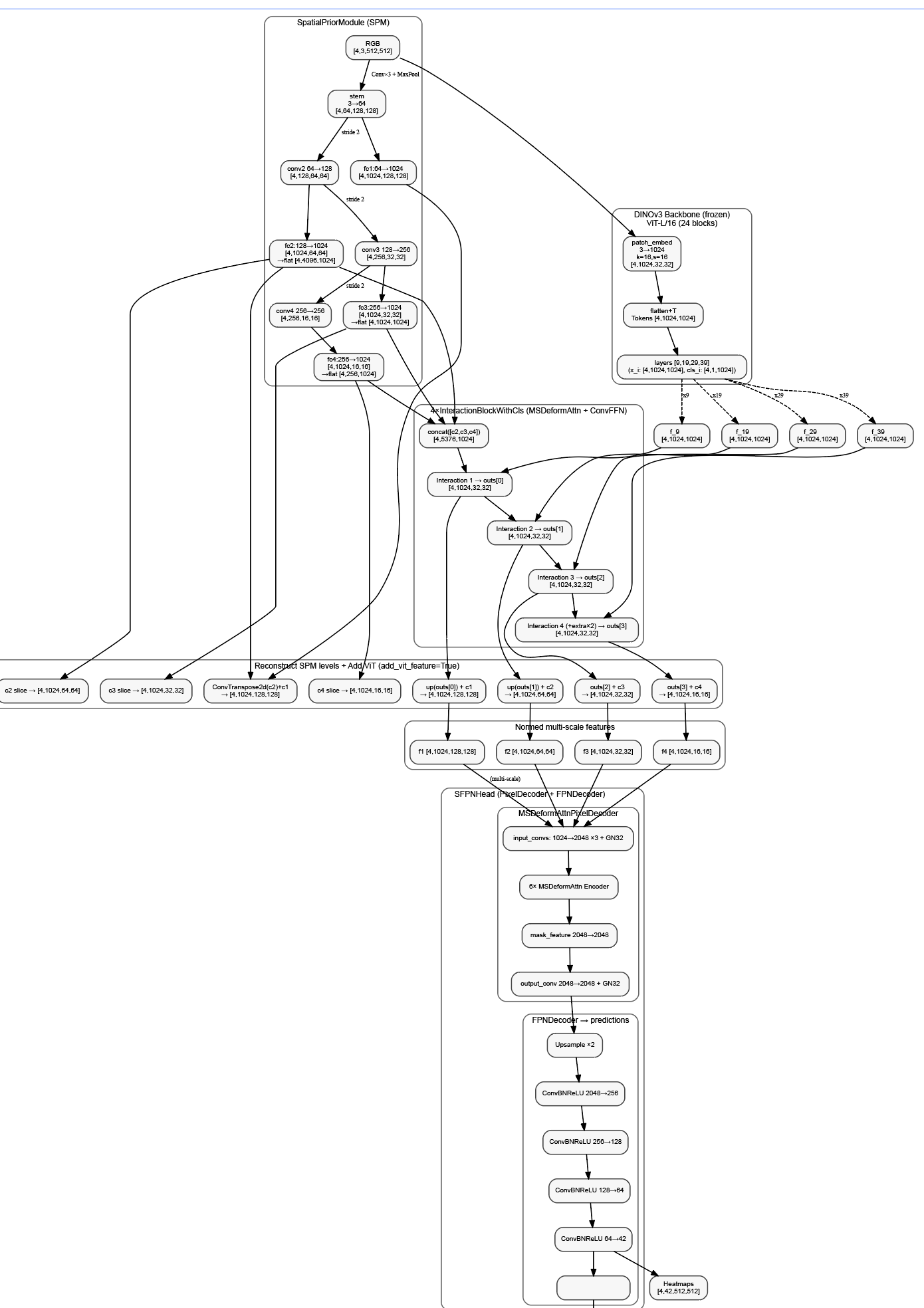
详细流程
第一阶段:数据输入与预处理
原始输入:
├── RGB图像: [B=4, C=3, H=512, W=512]
└── 真值
数据归一化 (data_norm):
├── RGB: mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]第二阶段:DINOv3_Adapter特征提取
1. SpatialPriorModule (SPM) 处理RGB:
RGB [4,3,512,512] → SPM → 多尺度特征:
├── c1: [4,1024,128,128] (stride=4)
├── c2: [4,1024,64,64] → flatten → [4,4096,1024] (stride=8)
├── c3: [4,1024,32,32] → flatten → [4,1024,1024] (stride=16)
└── c4: [4,1024,16,16] → flatten → [4,256,1024] (stride=32)
2. DINOv3 Backbone :
RGB [4,3,512,512] → DINOv3-L → 4层特征 [4,1024,1024] each
3. Multi-scale Interaction:
SPM特征,ViT特征 → 4层InteractionBlockWithCls(增强SPM特征) → 增强特征
4. Adapter最终输出:(增强的SPM特征 + VIT特征)
├── f1: [4,1024,128,128] (stride=4, 1/4下采样)
├── f2: [4,1024,64,64] (stride=8, 1/8下采样)
├── f3: [4,1024,32,32] (stride=16, 1/16下采样)
└── f4: [4,1024,16,16] (stride=32, 1/32下采样)第三阶段:FPNHead解码器
DINOv3_Adapter输出 {"1": f1, "2": f2, "3": f3, "4": f4} 送入FPNHead:
1. MSDeformAttnPixelDecoder处理:
输入特征: {"1": [4,1024,128,128], "2": [4,1024,64,64],
"3": [4,1024,32,32], "4": [4,1024,16,16]}
a) 多尺度可变形注意力编码:
├── 6层Transformer编码器 (16头注意力, dim=4096)
├── 特征增强和跨尺度交互
└── 生成增强的多尺度特征
b) FPN自顶向下融合:
├── 从最小尺度f4开始上采样
├── 横向连接融合各尺度特征
└── 输出高质量掩码特征
输出:
├── mask_features: [4,2048,128,128] (高分辨率掩码特征)
└── multi_scale_features: 4层增强特征 [4,2048,H,W]
2. FPNDecoder最终预测:
multi_scale_features → FPNDecoder:
特征处理流程:
x = features[-1] # 最小尺度特征 [4,2048,16,16]
├── conv1: [4,2048,16,16] → [4,256,16,16] (ConvBNReLU)
├── conv2: [4,256,16,16] → [4,128,16,16]
├── upsample: [4,128,16,16] → [4,128,32,32]
├── + lateral_conv1(features[0]): [4,2048,128,128] → [4,128,32,32]
├── conv3: [4,128,32,32] → [4,64,32,32]
├── upsample: [4,64,32,32] → [4,64,64,64]
├── + lateral_conv2(features[1]): [4,2048,64,64] → [4,64,64,64]
├── conv4: [4,64,64,64] → [4,42,64,64]
├── + lateral_conv3(features[2]): [4,2048,32,32] → [4,42,64,64]
└── conv5 (最终预测): 第四阶段:最终输出与上采样
FPNDecoder输出: [4,1,64,64] (logits)
最终上采样到原始分辨率:
├── F.interpolate(pred, size=(512,512), mode='bilinear')关键技术要点总结
- 双模态早期融合: RGB+深度在DINOv3 backbone层面融合
- 三级特征处理: DINOv3_Adapter → MSDeformAttnPixelDecoder → FPNDecoder
- 多尺度信息流: 从1/32到1/4的4个尺度特征逐级融合
- 注意力机制: 可变形注意力实现跨尺度特征交互
- FPN架构: 自顶向下+横向连接的经典特征金字塔
- 端到端训练: 只训练adapter和decoder,冻结DINOv3权重
完整的张量流维度跟踪
输入: RGB[4,3,512,512]
↓
DINOv3_Adapter: 4×[4,1024,128/64/32/16,128/64/32/16]
↓
MSDeformAttnPixelDecoder: 4×[4,2048,128/64/32/16,128/64/32/16]
↓
FPNDecoder: [4,1,64,64] → upsample → [4,1,512,512]
↓
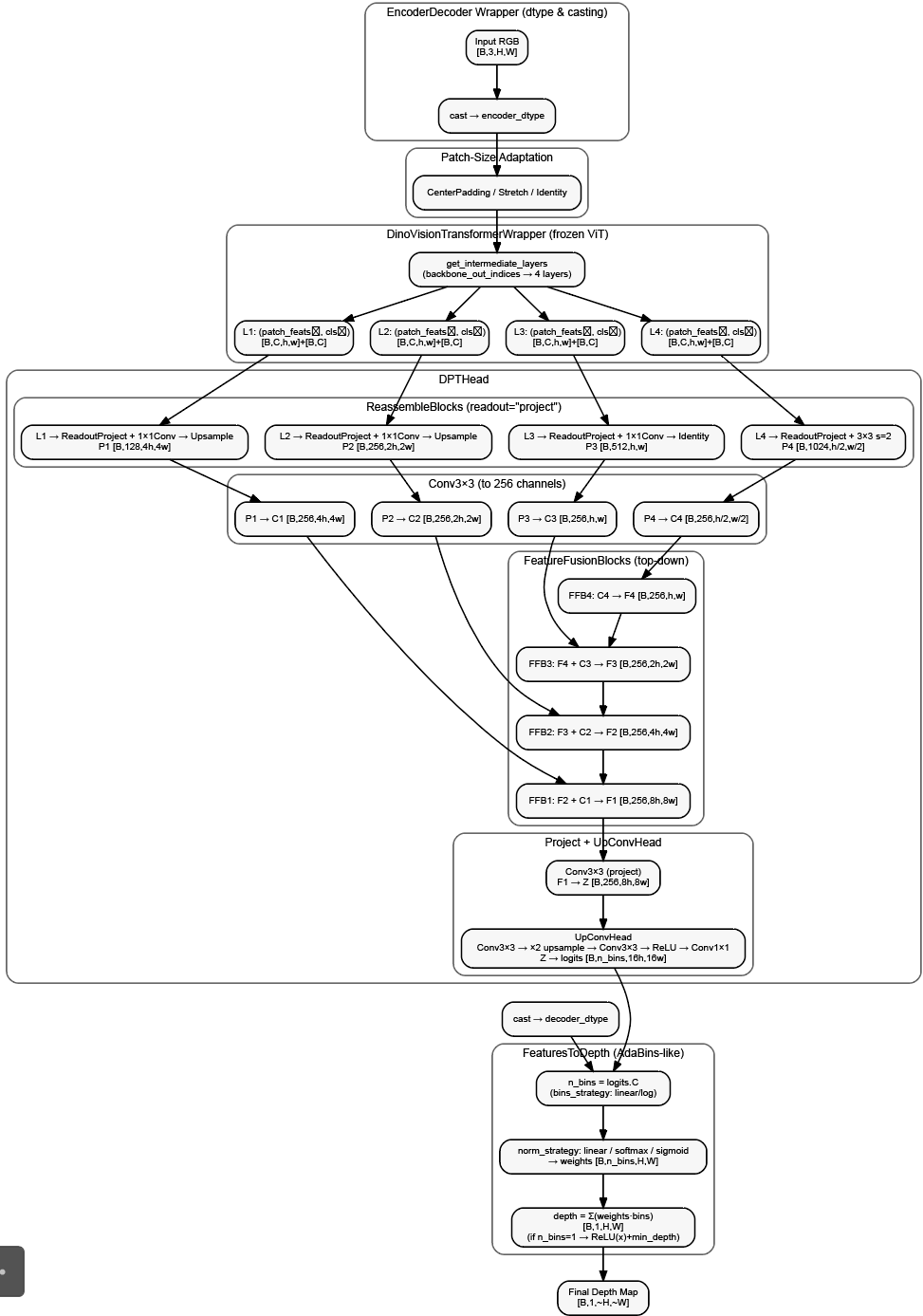
最终预测:2. 用于深度预测(完整版)
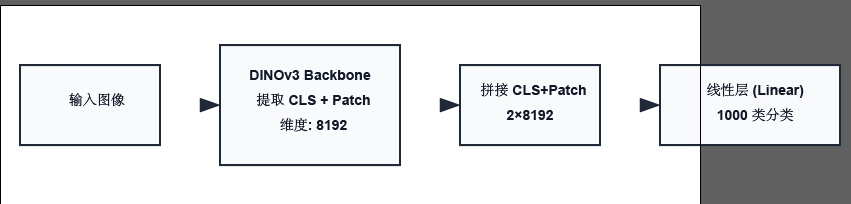
3. 用于分类
三.backbone的Lora微调
Lora效果
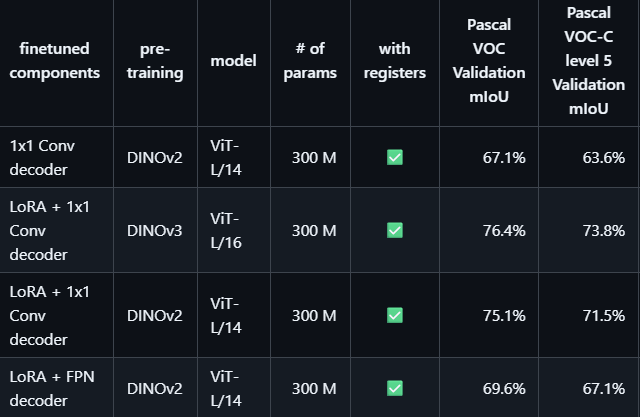
分析
这个项目的Lora是在backbone的注意力层的q,v上面加上了BA,其他地方保持一致,看起来效果很可以,后面等笔者自己做完实验,可以参见笔者论文。