编者按: 您是否曾感觉到,尽管精心设计了提示词,AI 的表现却依然不尽如人意?甚至随着上下文越来越长,模型反而更容易"胡言乱语"?
我们今天为大家带来的这篇文章,作者的核心观点是:"提示词工程"已经不够用了,下一代 AI 应用的核心竞争力在于"上下文工程"(Context Engineering)。
文章系统地阐述了为何在智能体(Agent)时代,单纯堆砌信息的"提示词工程"思维会导致性能下降、成本飙升。作者提出,上下文工程是一套系统级的架构方法,它强调动态地、有策略地为模型组合信息,包括系统指令、对话历史、用户记忆、检索结果和工具定义等,从而在有限的上下文窗口中实现最优性能。文章还深入分析了生产环境中实施上下文工程面临的四大挑战,并提供了五项关键优化策略,最后通过一个医疗健康领域的实例展示了如何构建一个真正的上下文驱动型 AI 系统。
作者 | Paul Iusztin
编译 | 岳扬
开门见山地说:如果你现在还在只谈论"提示词工程",那你就已经落后了。 在大语言模型(LLM)的发展初期,精心设计提示词确实是核心任务。
对于 2022 年的简单聊天机器人(chatbots)来说,这已经绰绰有余了。到了 2023 年,检索增强生成(RAG)技术兴起,我们开始为模型注入领域知识。而现在,我们拥有了能使用工具、具备记忆能力的智能体,它们需要建立长期关系并维持状态。提示词工程那种只关注单次交互的思路已经完全不够用了。
随着 AI 应用变得越来越复杂,单纯往提示词里塞更多信息会引发一些严重的问题。首先是上下文衰减(context decay)现象。模型会被冗长杂乱的上下文搞糊涂,导致产生幻觉和错误答案。最近一项研究发现,一旦上下文超过 32,000 个 tokens,模型回答的正确率就会开始明显下降 ------ 这远低于宣传的 200 万 token 极限1。
其次,上下文窗口(模型的工作记忆)是有限的。即使上下文窗口再大,每个 token 都会增加成本和延迟。我曾经构建过一个工作流,把研究资料、指南、案例和评审意见全都塞进上下文。结果呢?运行一次需要 30 分钟。根本没法用。这种"上下文增强生成(context-augmented generation)"的天真做法(或者说简单粗暴的信息堆砌),在生产环境中注定会失败。
Context Engineering Guide 101
这正是上下文工程的意义所在。它标志着思维模式的转变:从精心设计单个提示词,转变为架构整个 AI 的信息生态系统。我们动态地从记忆库、数据库和相关工具中收集并筛选信息,只为 LLM 提供当前任务最必需的内容。这让我们的系统更精准、更快速,也更经济。
01 理解什么是上下文工程
那么,上下文工程究竟是什么呢?标准的解释是:这是一个最优化问题 ------ 通过寻找最佳的功能组合来构建上下文,从而在特定任务中最大化 LLM 的输出质量2。
简而言之,上下文工程的核心在于策略性地将正确的信息,在正确的时机,以正确的格式填入模型有限的上下文窗口。我们从短期记忆和长期记忆中检索必要的片段来完成任务,同时避免让模型过载。
安德烈·卡帕西(Andrej Karpathy)对此有一个精妙的类比:上下文工程就像一种新型的操作系统,模型充当 CPU,而其上下文窗口则相当于 RAM3。正如操作系统需要管理哪些数据可以放入 RAM,上下文工程则精心策划哪些内容占据模型的工作内存。需特别注意,上下文仅是系统总工作内存的子集;有些信息可以保留在系统中,而无需在每次交互时都传递给 LLM。
这门新学科与单纯编写优质提示词有着本质的区别。要有效地设计上下文,你首先需要弄清楚哪些组成部分是你可以实际操作的。
上下文工程并非要取代提示词工程。相反,你可以直观地将提示词工程视为上下文工程的一部分。在收集合适上下文的同时,你仍然需要学习如何撰写优质提示词,并确保将上下文填入提示词中而不导致 LLM 出错 ------ 这正是上下文工程的意义所在!更多细节请参见下表。
| 提示词工程 vs. 上下文工程 | ||
|---|---|---|
| 维度 | 提示词工程 | 上下文工程 |
| 复杂度 | 手动进行字符串操作 | 系统级的、多组件的优化 |
| 主要关注 | 如何表述任务 | 提供哪些信息 |
| 影响范围 | 单次交互优化 | 整个信息生态系统 |
| 状态管理 | 主要为"无状态" | 本质为"有状态",具有显式的内存管理 |
02 上下文的构成要素
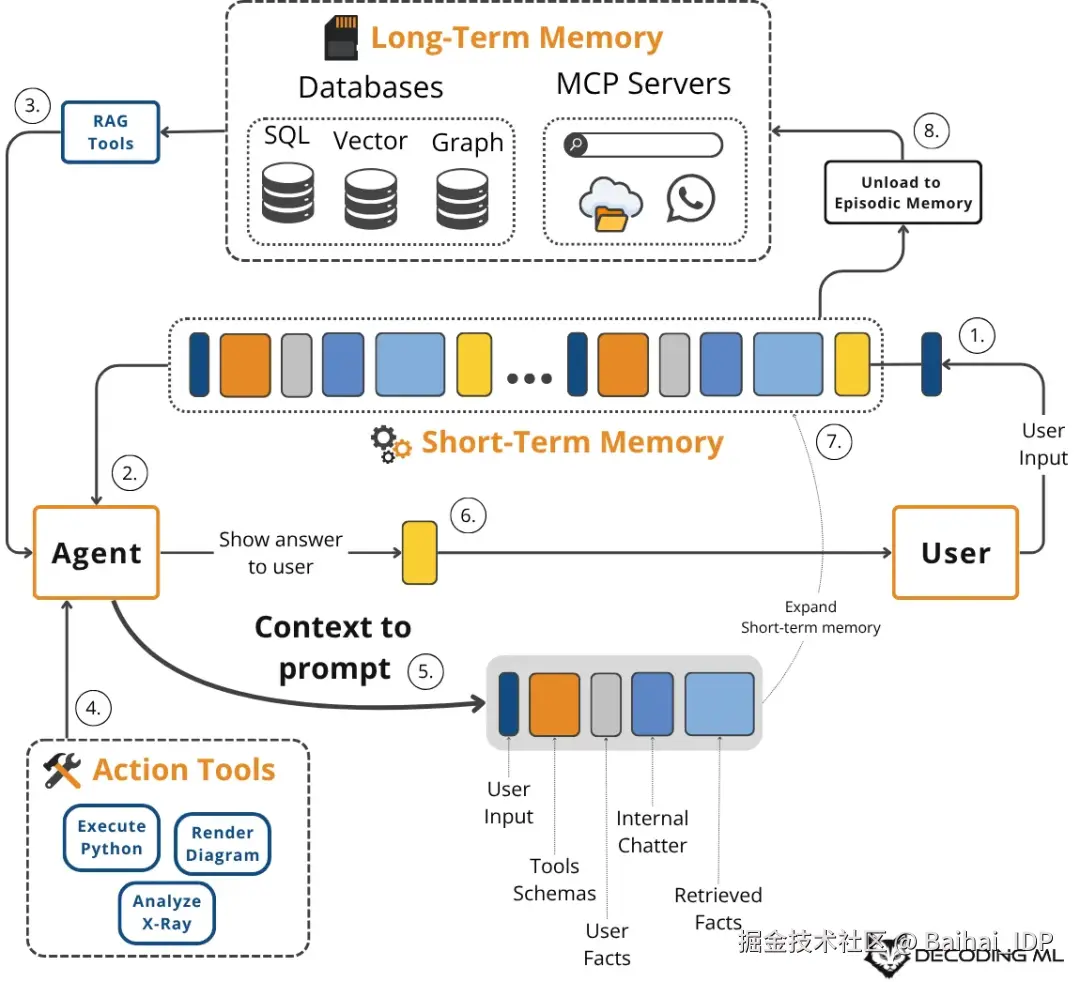
我们传递给大语言模型的上下文并非固定不变的字符串,而是为每次交互动态组装的信息载体。多种记忆系统协同构建这个载体 ------ 每种系统都受认知科学启发而承担着独特的功能4。
以下是构成 LLM 上下文的核心组件:
- System Prompt :包含智能体的核心指令、规则和角色设定。可视其为程序性记忆,定义了行为模式。
- Message History :记录了最近的对话往来,包括用户输入和智能体的内部思考(调用工具时的思考、行动与观察)。相当于短期工作记忆。
- User Preferences and Past Experiences :这部分属于智能体的情景记忆,负责存储特定事件和与用户相关的事实信息(通常保存在向量数据库或图数据库中)。它能实现个性化功能,例如记忆用户的身份特征或历史请求5。
- Retrieved Information :属于语义记忆 ------ 从内部知识库(如公司文档/内部记录)或通过实时 API 调用的外部数据源中获取的事实知识。这是 RAG 的核心。
- Tool and Structured Output Schemas :同样属于程序性记忆,定义智能体可使用的工具及其响应格式。
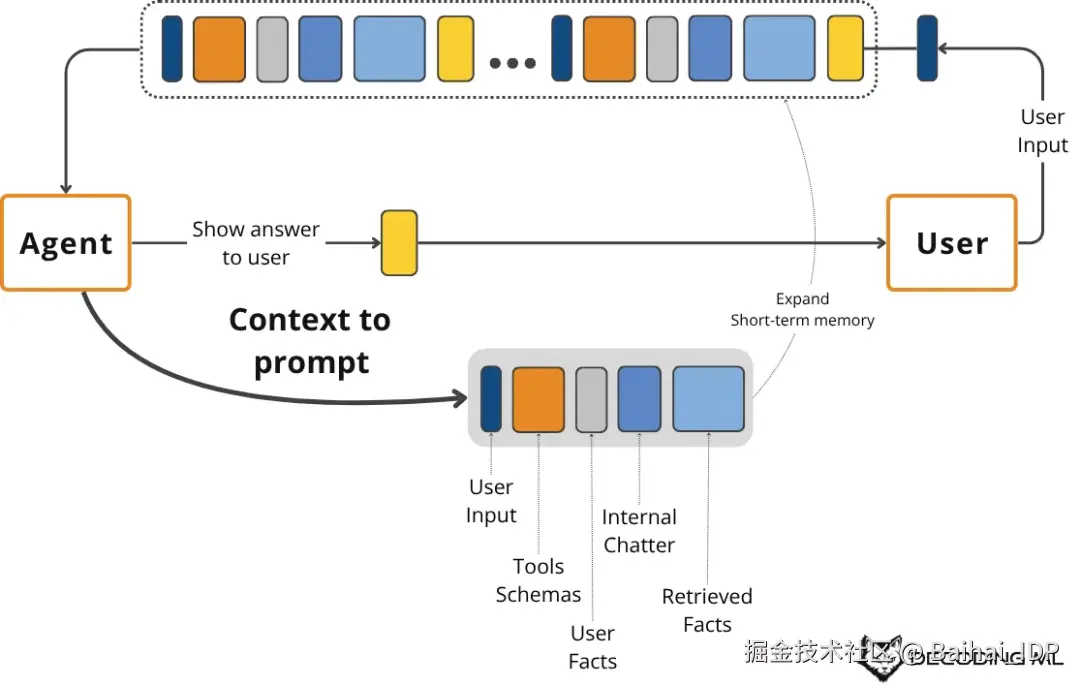
上下文的构成要素
这是一个循环且动态的流程。用户查询或任务会触发从长期记忆源(情景记忆、语义记忆、程序记忆)中检索信息,它不再是被动的传统 RAG,而是由一个"智能体"主动驱动的、更复杂的 Agentic RAG 组件。
随后,我们将这些信息与短期工作记忆、工具模式及结构化输出模式相结合,为本次 LLM 调用创建出最终的上下文。LLM 的响应会更新工作记忆,并可能将关键信息写回长期记忆,从而优化系统以适应未来的交互。
03 在生产环境实施上下文工程可能会遇到的一些挑战
构建健壮的上下文工程流程并非易事。在生产环境中,若未能妥善处理以下几个核心难题,将会导致智能体性能下降。
首先是上下文窗口的限制。 即便拥有超大容量的上下文窗口,其空间仍是昂贵且有限的资源。LLM 核心的自注意力机制会带来二次方的计算开销和内存开销2。每个 token 都会增加成本与延迟,聊天记录、工具输出和检索到的文档会迅速填满上下文窗口,从而严格限制智能体的"可见范围"。
这将引发信息过载问题(亦称上下文衰减或"中间信息丢失"现象)。 研究表明,当向上下文塞入过多信息时,模型会丧失关注关键细节的能力1。性能往往会断崖式下跌,导致生成混乱或无关的响应。这种信息丢失还可能触发幻觉,因为模型会试图填补感知到的信息缺口6。
另一个不易察觉的问题是上下文漂移(context drift),即关于同一件事存在的多个不一致甚至矛盾的记录会随着时间的推移而不断累积。 例如,若记忆中同时存在"用户预算为 500 美元"和后续的"用户预算为1000美元",智能体可能会产生困惑。若没有机制来解析或清除过时的事实性信息,智能体的知识库将变得不可靠。
最后是工具混淆问题(tool confusion)。 当为智能体提供过多工具时(尤其存在描述不清或功能重叠时),故障频发。Gorilla 基准测试表明,当提供超过一个工具时,几乎所有模型性能都会下降7。智能体会因选择过多而陷入瘫痪或选错工具,最终导致任务失败。
Context Engineering Guide 101
04 上下文优化的关键策略
早期,大多数 AI 应用只是简单的 RAG 系统。如今,智能体需要同时处理多个数据源、工具及记忆类型,这就要求采用更复杂的上下文工程方法。以下为有效管理 LLM 上下文窗口的关键策略。
4.1 选择合适的上下文
选择正确的上下文是你的第一道防线。应避免提供所有的可用上下文,应使用带重排序机制的 RAG 来仅检索最相关的上下文。
结构化输出同样也能确保 LLM 将响应拆分为多个逻辑片段,并仅将必要的片段传递至下游。这种动态的上下文优化会过滤内容并筛选出关键信息,从而在有限的上下文窗口内实现信息密度的最大化2。
4.2 上下文压缩
上下文压缩对于管理长对话非常重要。随着消息历史的增长,需要对其进行摘要或压缩以避免超出上下文窗口的容量,其原理类似于管理计算机的 RAM。
可使用 LLM 生成旧对话的摘要,通过 mem0 等工具将关键信息转移至长期情景记忆,或使用 MinHash 算法进行去重8。
4.3 上下文排序
LLM 会更关注提示词的开头和结尾部分,而常常忽略中间的信息 ------ 这就是"中间信息丢失"(lost-in-the-middle)现象 1。
请将关键指令置于开头,将最新或最相关的数据放在末尾。
重排序机制与时效相关性确保 LLM 不会埋没关键信息2。动态上下文优先级还能通过适配变化的用户偏好来解决歧义和维持个性化的响应9。
4.4 上下文隔离
上下文隔离(Isolating context)是指将复杂问题拆分给多个专用智能体处理。每个智能体专注维护自身的上下文窗口,避免干扰并且可以提升性能。
这是多智能体系统背后的核心原则,利用了软件工程中经典的关注点分离原则(separation of concerns principle)。
4.5 上下文格式优化
最后,使用 XML 或 YAML 等结构进行上下文格式优化可使上下文更易被模型"消化"。这样可以清晰地划分不同信息类型,并提升推理的可靠性。
💡 小提示:始终用 YAML 替代 JSON,因其可节省 66% 的 token 消耗。

Context Engineering Cheat Sheet - Source thread on X by @lenadroid
05 示例
上下文工程并非仅是理论概念,我们已将其应用于构建多个领域的强大 AI 系统。
在医疗健康领域,AI 助手可调用患者病史、当前症状及相关医学文献,以提供个性化的诊断建议。
在金融领域,智能体可集成公司的客户关系管理(CRM)系统、日历和财务数据,从而基于用户偏好做出决策。
对于项目管理,AI 系统可接入 CRM、Slack、Zoom、日历及任务管理器等企业级工具,自动理解项目需求并更新任务。
让我们看一个具体案例。假设用户向医疗助手提问:我头痛。有什么不吃药的方法能缓解吗?
在 LLM 接收到用户查询之前,上下文工程系统已开始工作:
1)它从情景记忆存储库(通常是向量数据库或图数据库5)中检索用户的病史、已知过敏原和生活习惯。
2)它查询存储最新医学文献的语义记忆库,获取非药物性头痛疗法4。
3)它将上述信息与用户查询及对话历史一起,组装成一个结构化的提示词。
4)我们将此提示词发送给 LLM,由其生成个性化的、安全且相关的建议。
5)记录此次交互,并将任何新的偏好保存回用户的情景记忆中。
以下是一个简化的 Python 示例,展示了如何将这些组件组装成一个完整的系统提示词。请注意其清晰的结构与编排顺序。
医疗 AI 助手的系统提示词:
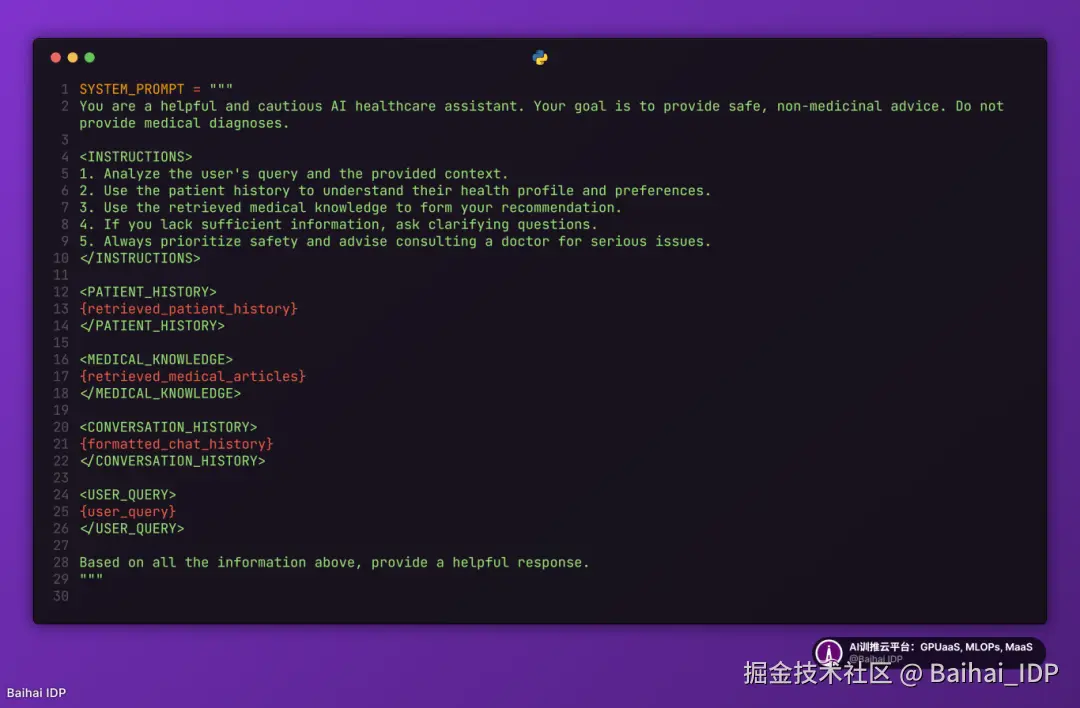
当然,整个系统的关键仍在于其周边的支撑系统,该系统能引入恰当的上下文来填充系统提示词。
要构建此类系统,需要组合使用多种工具。比如,Gemini 等 LLM 提供推理引擎,LangChain 等框架编排工作流,PostgreSQL/Qdrant/Neo4j 等数据库作为长期记忆存储库,Mem0 等专用工具管理记忆状态,而可观测性平台对调试复杂交互至关重要。
06 将上下文工程与 AI 工程相融合
掌握上下文工程的关键不在于学习特定算法,而在于培养一种直觉。这是一门懂得如何构建提示词结构、选择纳入哪些信息以及如何排序以实现最大效用的艺术。
这项技能并非孤立存在。它是一种跨学科的实践,位于多个关键工程领域的交汇处:
- AI Engineering:理解 LLM、RAG 和 AI 智能体是基础。
- Software Engineering:需要构建可扩展且可维护的系统来聚合上下文,并将智能体封装在健壮的 API 中。
- Data Engineering:为 RAG 及其他记忆系统构建可靠的数据管道非常重要。
- MLOps:在合适的基础设施上部署智能体,并实现持续集成/持续部署(CI/CD)自动化,使其具备可复现性、可观测性与可扩展性。
培养上下文工程技能的最佳方式是亲自动手实践。
开始构建集成以下功能的 AI 智能体:使用 RAG 实现语义记忆,使用工具实现程序性记忆,以及利用用户配置文件实现情景记忆。通过在实际项目中努力权衡上下文管理的各种利弊,你将培养出那种能将简单 Chatbot 与真正智能体区分开来的直觉。
现在,停止阅读,运用这些上下文工程技能去构建你的下一个 AI 应用吧!
END
本期互动内容 🍻
❓如果让你向一个新手解释"上下文工程"和"提示词工程"的区别,你会怎么比喻?
文中链接
1www.databricks.com/blog/long-c...
4www.nature.com/articles/s4...
7gorilla.cs.berkeley.edu/leaderboard...
8www.datacamp.com/tutorial/pr...
9aclanthology.org/2025.naacl-...
10www.anthropic.com/engineering...
11www.speakeasy.com/mcp/ai-agen...
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接: