在深度学习中,损失函数通过比较预测值与真实值之间的差异,来衡量模型参数质量
数据差异越小,越拟合,损失值越小
损失函数主要根据任务类型来选择,最常见的是分类 和回归两大类。
一、分类任务损失函数
交叉熵损失
这是分类任务中最主流、最常用的损失函数。
1.多分类交叉熵
- 适用:两个以上类别的任务(如:猫、狗、鸟)。
- 公式:
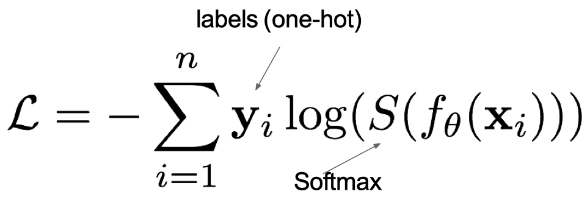

- **PyTorch:**nn.CrossEntropyLoss()
2.二分类交叉熵
- 适用:只有两个类别的任务(如:是/否,猫/狗)。
- 公式:
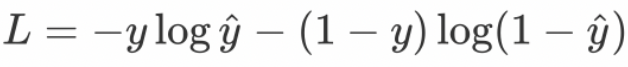
- **PyTorch:**nn.BCELoss()
二、回归任务损失函数
用于预测连续的数值。
1. 平均绝对误差 (Mean Absolute Error, MAE) / L1 Loss
- 原理:计算预测值与真实值之差的绝对值的平均值。
- 公式 :
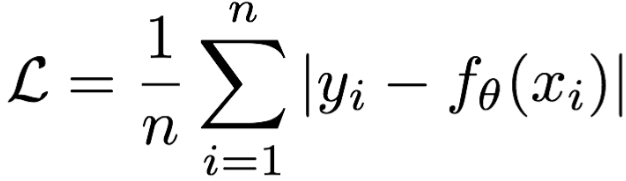
- 优点:对异常值不敏感,更稳健。
- 缺点 :在
y = ŷ处不可导(但通常可以处理)。 - PyTorch :
nn.L1Loss()
2. 均方误差 (Mean Squared Error, MSE)/ L2 Loss
这是回归任务中最基础、最常用的损失函数。
- 原理:计算预测值与真实值之差的平方的平均值。
- 公式 :
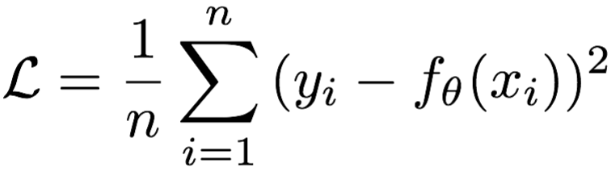
- 优点:数学性质好,可导,易于优化。
- 缺点:对异常值(离群点)非常敏感,因为误差被平方了。
- PyTorch :
nn.MSELoss()
3. SmoothL1 Loss (平滑的L1损失)
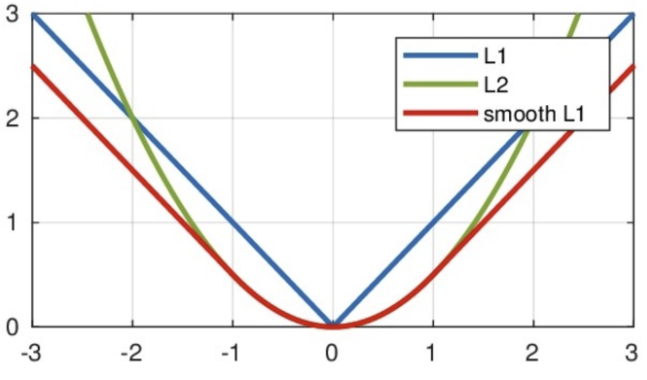
- 原理:MSE 和 MAE 的结合体。当误差较小时,行为像MSE(二次);当误差较大时,行为像MAE(线性)。
- 公式 :
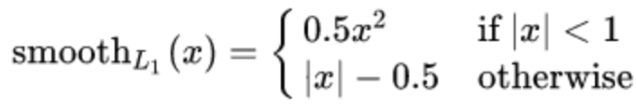
- 优点:结合了MSE的平滑性和MAE对异常值的鲁棒性。
- PyTorch: nn.SmoothL1Loss()
三、小结
| 任务类型 | 推荐损失函数 | PyTorch 实现 | TensorFlow 实现(扩展) |
|---|---|---|---|
| 二分类 | 二元交叉熵 | nn.BCELoss() |
BinaryCrossentropy |
| 多分类 | 交叉熵 | nn.CrossEntropyLoss() |
SparseCategoricalCrossentropy |
| 回归 | MSE / MAE / SmoothL1 | nn.MSELoss() / nn.L1Loss() / nn.SmoothL1Loss() |
MeanSquaredError / MeanAbsoluteError / Huber |