
🔥个人主页:爱和冰阔乐
🐶学习方向:C++方向学习爱好者
⭐人生格言:得知坦然 ,失之淡然

博主简介

文章目录
- 前言
- 一、list的结构
- 二、list核心接口
-
- [2.1 构造函数](#2.1 构造函数)
- [2.2 迭代器/范围for遍历list](#2.2 迭代器/范围for遍历list)
- [2.3 emplace_back与push_back的比较](#2.3 emplace_back与push_back的比较)
- [2.4 insert插入与erase删除操作](#2.4 insert插入与erase删除操作)
- 2.5sort排序
- [2.6 合并两个有序链表merge接口](#2.6 合并两个有序链表merge接口)
- 2.7unique去重
- [2.8 splice 粘接](#2.8 splice 粘接)
- [2.9 链表排序效率](#2.9 链表排序效率)
- 三、资源分享
- 四、总结
前言
STL的学习都是类似的,在学完vector后,不可避免的要学习
list(链表),在这里我们将实现带头双向循环链表,与C语言中已经实现的链表有异曲同工之妙,如若有兴趣也可以看看C语言实现链表 手动实现单链表与双链表的接口及OJ挑战
一、list的结构
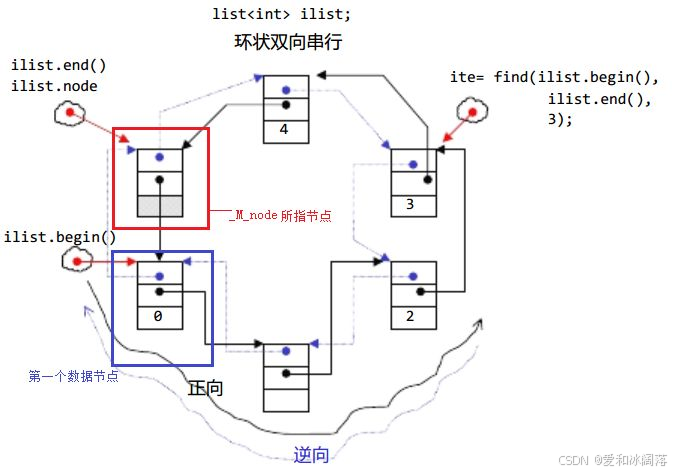
list是带头双向循环链表,下面我们将分析下其中的含义:
双向: 每个节点都有prev(前驱)和next(后继)指针,可正向 / 逆向遍历;
循环: 尾节点的next指向头结点,头结点的prev指向尾节点,形成闭环;
头结点/哨兵位: 不存储实际数据,仅用于统一接口(避免插入 / 删除首节点时的特殊处理)
二、list核心接口
在学习每个容器前我们都需要了解下其的文档介绍 list文档介绍
2.1 构造函数
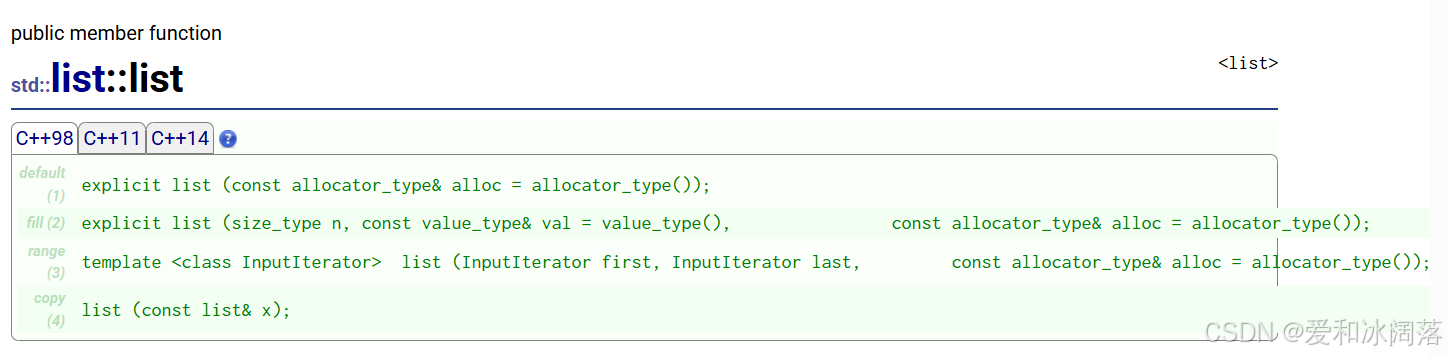
list和前面学习的lvector一样,分为四种:
1.全缺省构造(默认构造)
2.n个val构造
3.迭代器区间构造
4.拷贝构造
cpp
// 1. 空list
list<int> l1;
// 2. 5个元素,均为3
list<int> l2(5, 3); // [3,3,3,3,3]
// 3. 用数组区间初始化
int arr[] = {1,2,3,4,5};
list<int> l3(arr, arr+5); // [1,2,3,4,5]
// 4. 拷贝构造
list<int> l4(l3); // [1,2,3,4,5]
同样,析构和赋值与之前STL容器的实现几乎一样,不再进行实现
2.2 迭代器/范围for遍历list
在链表中不再支持下标+ 遍历,因为如果想要获取第n个数据,必须要重新遍历,时间复杂度过高(不再像数组一样是连续的物理空间,获取数据的复杂度为O(1),list的底层节点实现地址并不连续)
此处,大家可暂时将迭代器理解成一个指针,该指针指向list中的某个节点
注意:
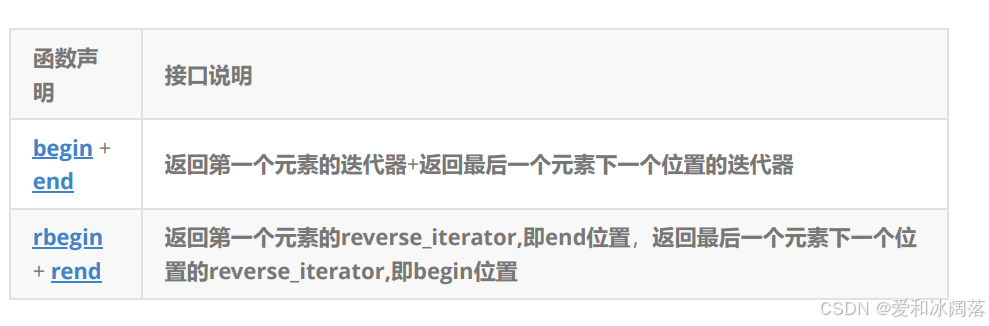
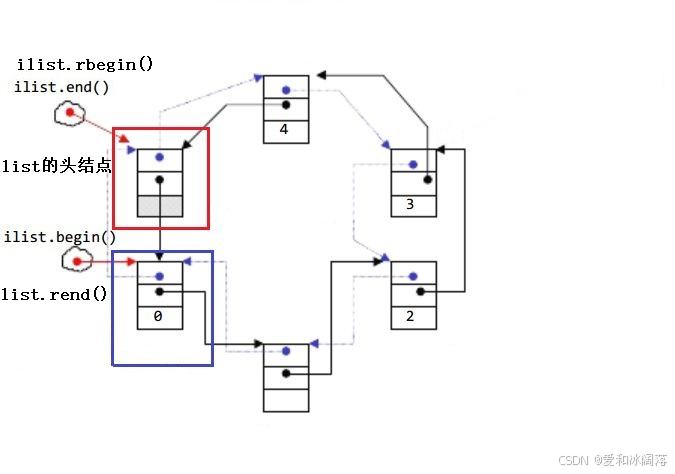
- begin与end为正向迭代器,对迭代器执行++操作,迭代器向后移动
- rbegin(end)与rend(begin)为反向迭代器,对迭代器执行++操作,迭代器向前移动(不是- -)
遍历链表
cpp
void test_list1()
{
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
//下标+[ ]便不可以了,我们使用迭代器
list<int>::iterator it=lt.begin();
while(it!=lt.end())
{
cout<<*it<<" ";
++it;
}
cout<<endl;
for(auto e:lt)
{
cout<<e<<" ";
}
cout<<endl;
}这里需要注意的是如果要删除链表某个位置的顺序不可以使用如下写法
cpp
//错误写法
it=ltbegin();
lt.erase(it+3);
在这段代码我们发现代码报错,我们回想下前面学习vector为什么可以,原来vector实现迭代器是原生指针,而在list这里不再是原生指针,那么为什么list不可以使用原生指针的原因还是其
底层不再是连续的地址
总结:
迭代器按照功能划分 : iterator reverse_iterator const_iterator const_reverse_iterator性质划分: 1.单向:forwad_list(单链表)/unordered-map... 只支持++ 2.双向:list/map/set 支持++/- - (不支持+/-) 3.随机:vector/string/deque... 支持++/--/+/-
list:迭代器
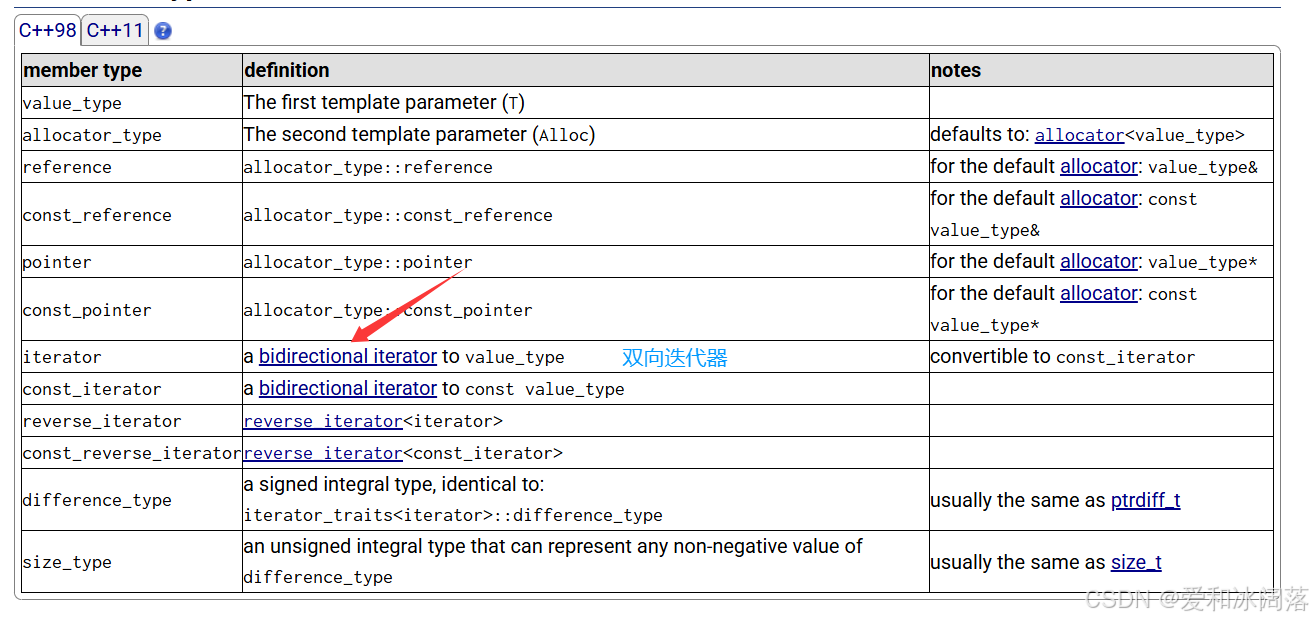
vector:随机迭代器
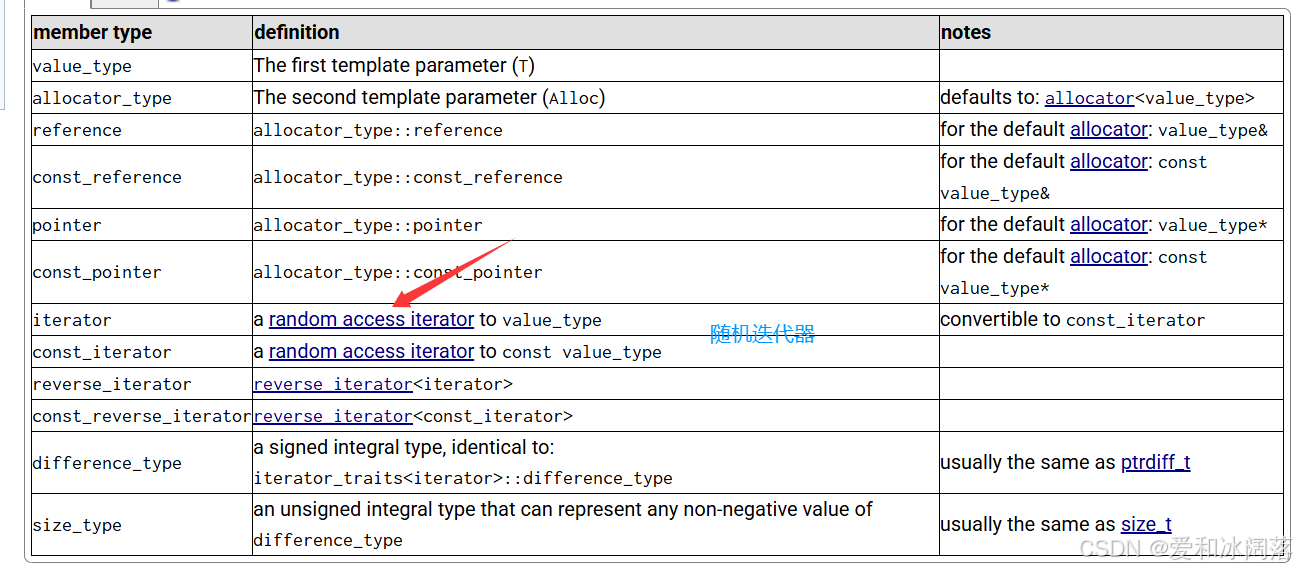
unordered_map:单向迭代器
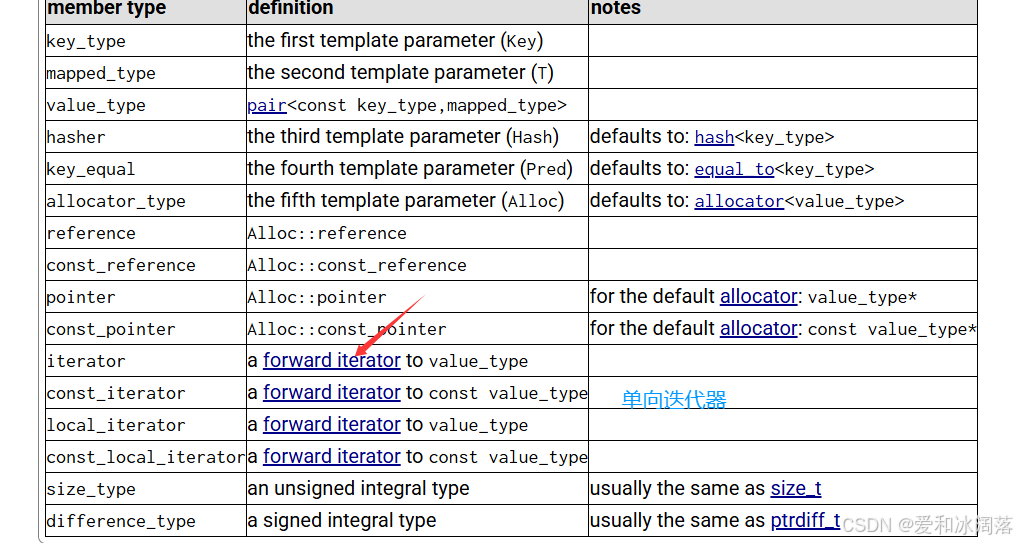
决定迭代器的性质是底层的结构决定的
性质决定了可以使用哪些算法,下面我们根据sort/reverse等算法来深入了解下:

sort是随机迭代器实现的,可以支持++/- -/+/-,并且其是由模板实现的,那么是不是所有的容器均可以排序,那当然不可以,sort的时候,迭代器只能使用随机迭代器,那么list便不行,因为其不支持 + / -
cpp
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
sort(lt.begin(),lt.end());
因此我们想要对list进行排序必须使用list自带的排序算法
cpp
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.sort();
for (auto t : lt)
{
cout << t << " " ;
}
cout << endl;reverse传双向迭代器,因此双向迭代器可以支持list,但不支持单向迭代器,因为在其实现时使用了- -,那么随机迭代器可=可不可以使用这里的逆置,那当然可以了,因为逆置实现的是++/- -,而随机迭代器本身也支持++/- -
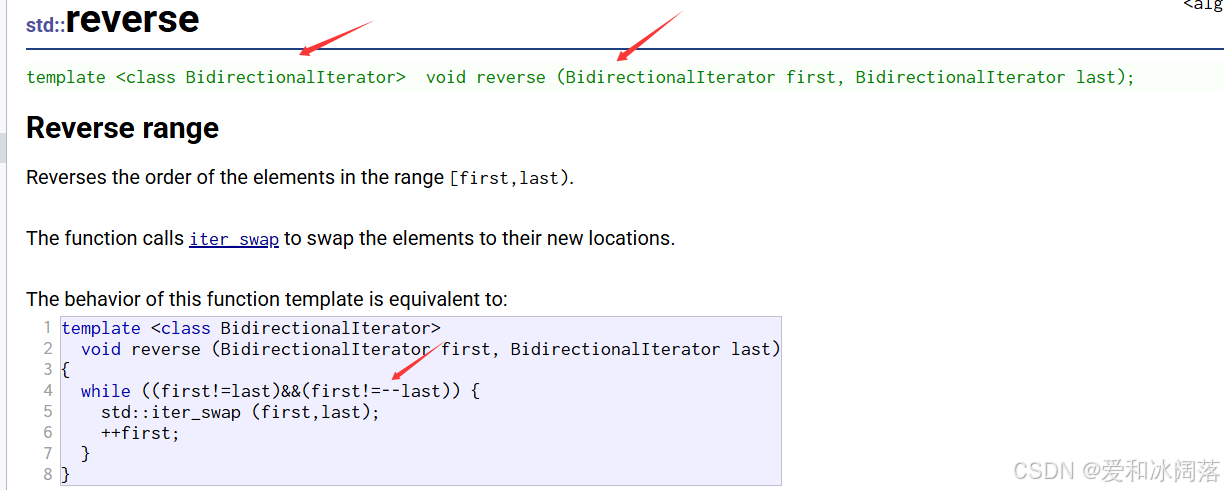
find的迭代器:所有提供输入迭代器的容器,在后面继承我们会学习

2.3 emplace_back与push_back的比较
从日常的角度,用push_back和emplace_back是一样的,在日常插入一个数据时,不管使用有名对象还是匿名对象,push_back支持的,emplace_back也支持,如下
cpp
struct A
{
public:
A(int a1 = 1, int a2 = 1)
:_a1(a1)
,_a2(a2)
{
cout << "A(int a1=1,int a2=1)" << endl;
}
A(const A& aa)
:_a1(aa._a1)
,_a2(aa._a2)
{
cout << "A(const A& aa)" << endl;
}
int _a1;
int _a2;
};
list<A> lt;
A aa1(1, 1);
//有名对象
lt.push_back(aa1);
//匿名对象
lt.push_back(A(2, 2));
lt.emplace_back(aa1);
lt.push_back(aa1);
lt.emplace_back(A(2.2));>emplace_back还支持如下写法
cpp
lt.emplace_back(3, 3);
但是push_back不可以
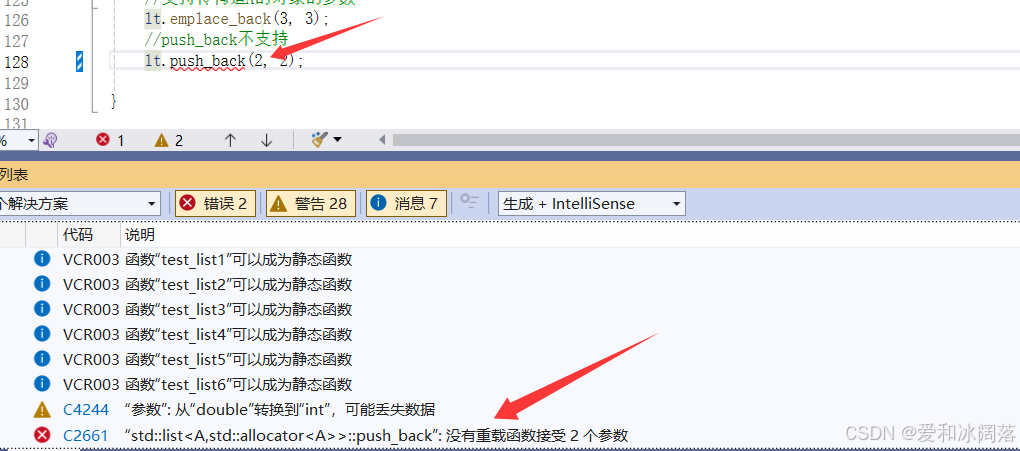
因为push_back只支持一个参数------A类型的对象,但是emplace_back是
可变类型的模板,因此支持直接传构造A的参数,由于我们并没有了解很多C++的知识,后续会对emplace_back再进行介绍,
我们只需要知道push_back 需要先有一个 A 类型的对象(无论是有名对象如 aa1,还是匿名对象如 A(2, 2)),然后将这个对象复制或移动到容器中(会触发拷贝构造或移动构造),即先构造再拷贝构造,emplace_back 则直接在容器内存中调用 A 的构造函数创建对象,没有拷贝构造,效率更高即可
2.4 insert插入与erase删除操作

这里的插入也和vector类似
1.在pos位置之前插入val
2.pos位置之前插入n个val
3.pos位置之前插入一段迭代器区间
但是我们知道list的地址并不是连续的,那么想要在指定位置之前插入数据,不能像vector一样使用(begin/end + n),list的迭代器是双向的,不支持随机的 + / -,因此我们只能定义新的变量代表在第i个位置前插入数据,使用while循环,i递减,让迭代器向目标位置递增
cpp
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(3);
lt.push_back(4);
lt.push_back(5);
lt.push_back(6);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
int k = 3;
//while循环遍历找到要插入数据的位置
while (k--)
{
//list 的迭代器(双向迭代器)已经封装了链表节点的指针跳转逻辑,
// ++it 并不是直接对物理地址进行加减,而是通过链表节点内部存储的next指针跳转到下一个位置的
++it;
}
lt.insert(it, 30);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
erase删除数据

在删除数据前,我们现需要输入删除的数据在list中是否存在,那么就需要使用到算法中find函数对list进行查找,这里我们想把1 2 3 30 4 5 6中的3删掉
cpp
int x=0;
cin>>x;
it=find(lt.begin(),lt.end());
if(it!=lt.end())
{
lt.erase(it);
}结果如下:

2.5sort排序
算法库中的sort是随机迭代器,而list对应的是双向迭代器,因此list自己必须要实现一个sort接口(无论是算法库中的还是list实现的均是默认
排升序)
cpp
list<int> lt;
lt.push_back(1);
lt.push_back(3);
lt.push_back(2);
lt.push_back(4);
lt.push_back(5);
lt.push_back(6);
//这里sort排序默认排的是升序
lt.sort();
那么如果我们想给list排降序,就需要用到仿函数,在后面栈和队列中会有所介绍
在排升序的时候,我们使用的数学符号为 " <" (小于),小于对应的英文为less
在排降序时,使用的数学符号为" > "(大于),对应的英文是greater
cpp
less<int> ls;//类模板
//有名对象
greater<int> gt;//类模板
//匿名对象
lt.sort(greater<int>());
lt.sort(gt);排降序

2.6 合并两个有序链表merge接口
在merge接口文档介绍中我们看到合并两个链表的前提是均是有序的
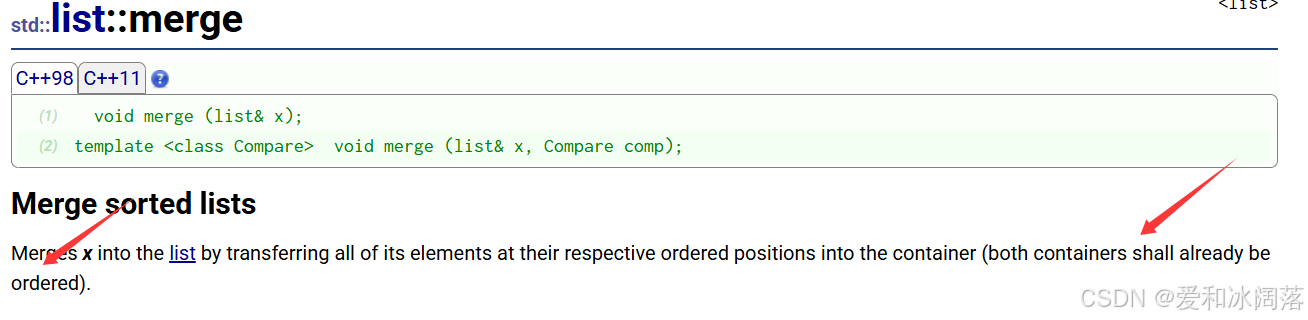
下面是官方给的案例:
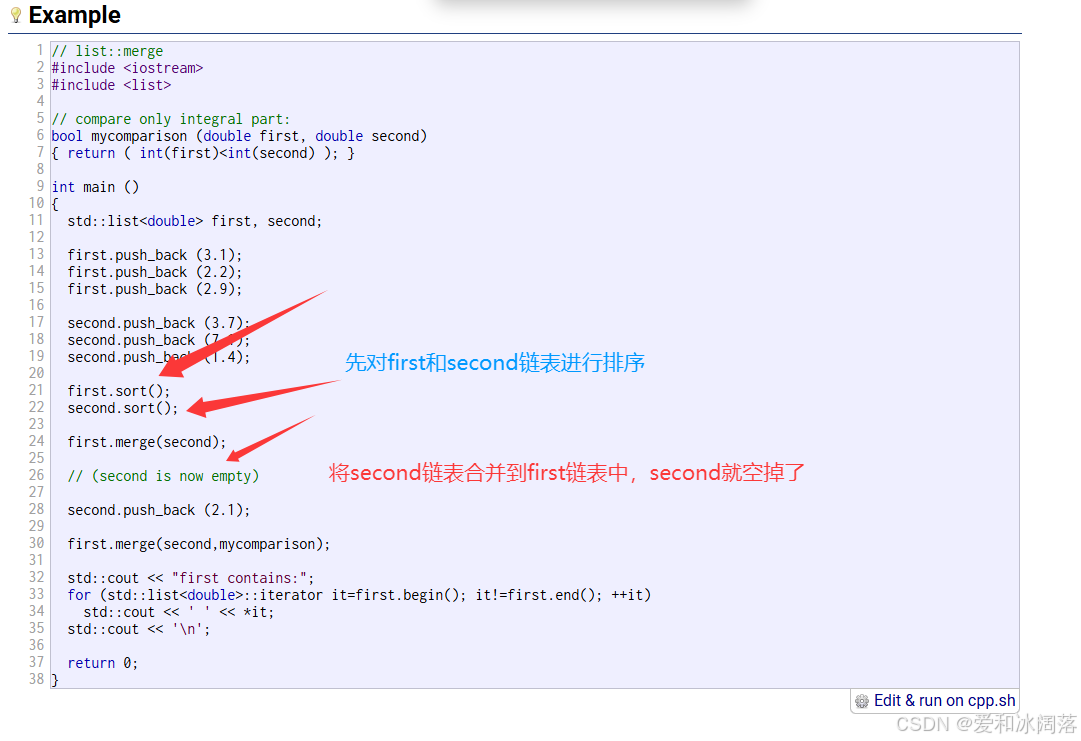
从两个链表的头部开始,逐个比较元素大小,将较小的元素(按排序规则)依次插入到结果链表中
当其中一个链表的元素全部处理完后,将另一个链表中剩余的元素直接拼接过来
cpp
int main() {
list<int> a = {1, 3, 5};
list<int> b = {2, 4, 6}; // a和b都是升序
a.merge(b); // 合并后a变为{1,2,3,4,5,6},b变为空
for (int x : a)
cout << x << " "; // 输出:1 2 3 4 5 6
return 0;
}2.7unique去重
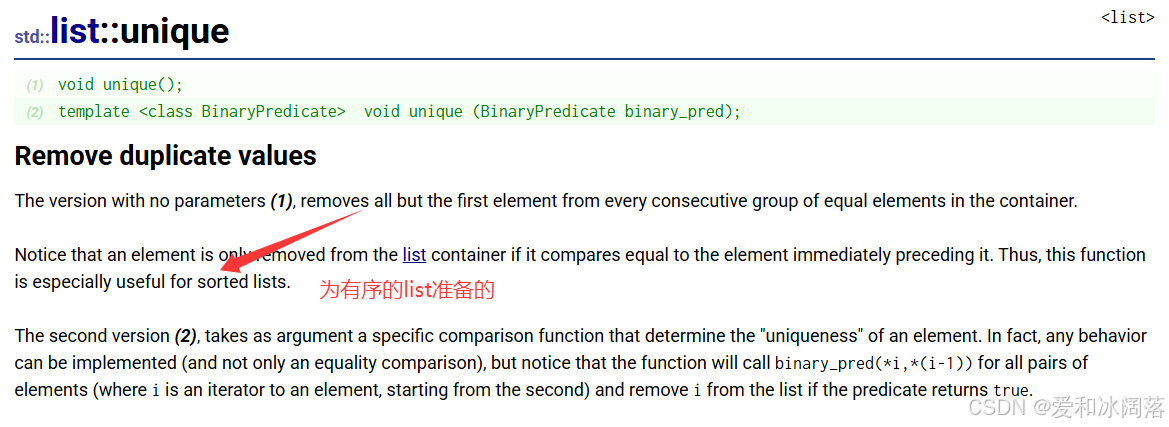
该接口的作用是删除链表中重复的元素,只会保留一个,去重要求数据必须是有序的,否则会出粗,下面我们通过代码来演示下
cpp
list<int> lt;
lt.push_back(1);
lt.push_back(2);
lt.push_back(2);
lt.push_back(2);
lt.push_back(2);
lt.push_back(30);
lt.push_back(2);
lt.push_back(4);
lt.push_back(5);
lt.push_back(6);
lt.push_back(7);
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;
//unique去重要求数据必须是有序的,否则会出粗,因此可以sort下
//lt.sort();
lt.unique();
for (auto e : lt)
{
cout << e << " ";
}
cout << endl;结果演示:
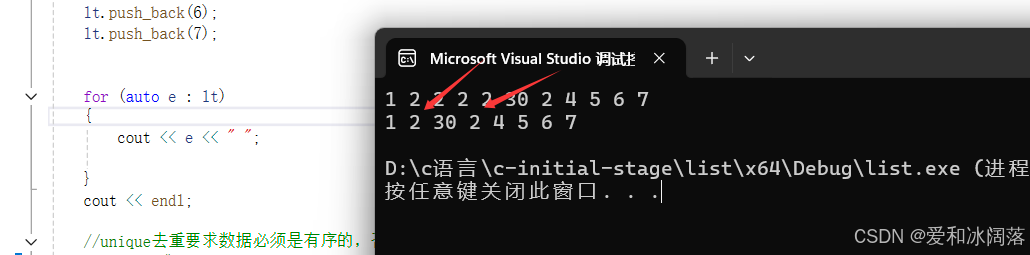
果然,我们发现使用unique去重后,还剩下2个2,因为list实现该接口时,默认list是有序的,即相同的值是连在一起的,因此在去重前,我们需要sort下,这里我们扩展想下,如果链表是有序的,那么去重我们自己实现也很简单,在前面C语言的数据结构章节我们介绍了双指针法便可以轻松解决
2.8 splice 粘接
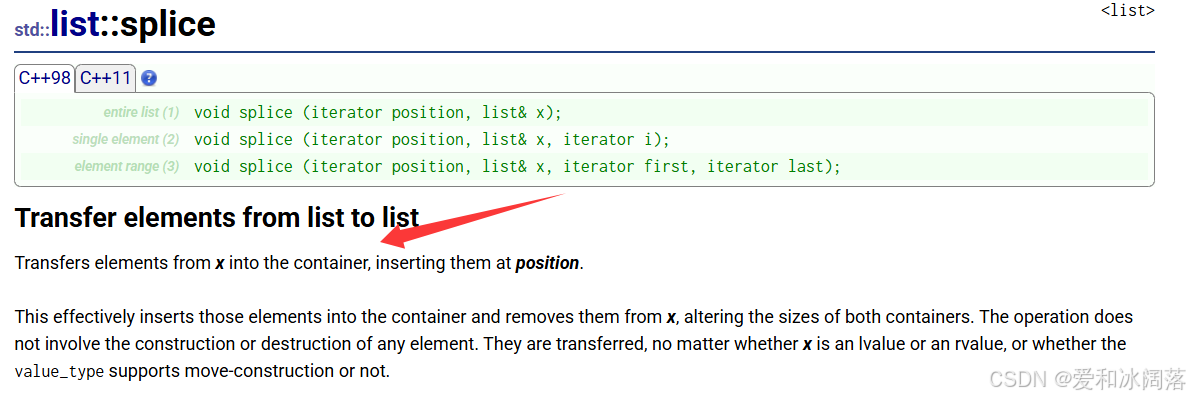 splice接口的含义是:剪切后再粘贴,不要与复制粘贴搞错乱。
splice接口的含义是:剪切后再粘贴,不要与复制粘贴搞错乱。
下面我们举个简单易懂的生活小例子:在生活中如果我们创业,那么肯定希望钱能生钱,这对应的便是复制粘贴,不动我的本金。那么如果在创业时,因为轻信他人被诈骗,导致本金转移到别人手里,那么这就是splice的含义,本质就是转移
下面我们通过splice给的文档代码来看看具体的步骤是如何的:
在mylist1中插入了1 2 3 4四个数据,在mylist2中插入了10 20 30,再把mylist2中的数据转移到mylist1中2数据之前
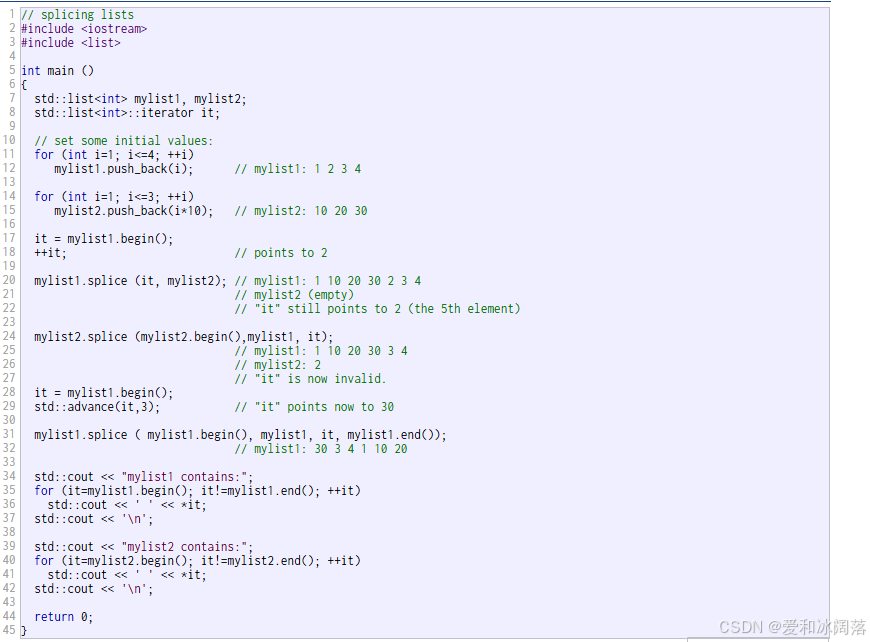
注意:不是把10 20 30拷贝到mylist1上面,而是把mylist2中的数据剪切走(mylist2就空了),再粘贴到mylist1中
在下面我看看一种常见的场景,我们希望把链表的顺序转移下,在下面链表中我们假设把6转移到1之前
在没学splice之前,我们可以把6删除,再在1之前插入6,由于释放了一个节点又增加了一个节点,时间复杂度便会很高
我们希望直接把6这个节点直接转移到1前面,那么首先我们需要find下找到目标节点,然后调用splice(lt.begin(),lt,it)即可
splice(lt.begin(),lt,it)是指将lt的it值转移到begin()之前
那么我们想要将目标节点及其之后的节点均移动到begin()之前只需给一段迭代区间即可
lt.splice(lt.begin(), lt, it, lt.end())
cpp
int x = 0;
cin >> x;
auto it = lt.begin();
//find查找+删除数据
it = find(lt.begin(), lt.end(), x);
if (it != lt.end())
{
//只转移it这个数据
//lt.splice(lt.begin(), lt,it);
//如果转移从该位置到最后的一段数据
lt.splice(lt.begin(), lt, it, lt.end());
}将目标节点转移至begin()位置

将目标元素及其之后的数据移动到begin()之前

2.9 链表排序效率
如果链表的数据量小可以使用list自带的sort进行1排序,但是一旦数据量很大则排序效率低下,下面我们通过将链表放在顺序表中排序和使用list自带的排序在debug版本下跑下
cpp
srand(time(0));
const int N = 1000000;
list<int> lt1;
vector<int> v;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
v.push_back(e);
}
int begin1 = clock();
// 算法库中的sort排序
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
//list自带的sort排序
lt1.sort();
int end2 = clock();
printf("vector sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);我们发现即使在优化没有全开的debug版本下vector排序更高
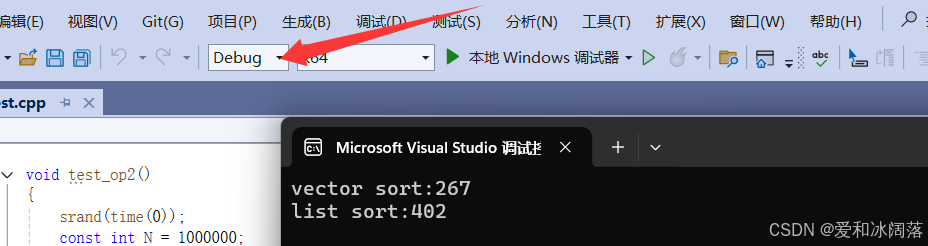
那么在release版本下显而易见,vector排序更快(注意在测性能时不用debug,不具有参考价值)
debug下不具有参考价值的原因可以通过生活中的小例子对比:将一岁的儿童和苏炳添放在一起进行百米冲刺比赛,在日常情况下,苏炳添会为了照顾小朋友会跑的快那么几米,可真正在比赛场上苏炳添全力冲刺肯定远比小朋友跑的远得多,因此我们只会以优化全开的release进行判断
由于vector底层的sort使用了快排,快排需要用到递归,递归在debug版本下会打很多的调试信息,建立栈帧等导致时间没有相差多少
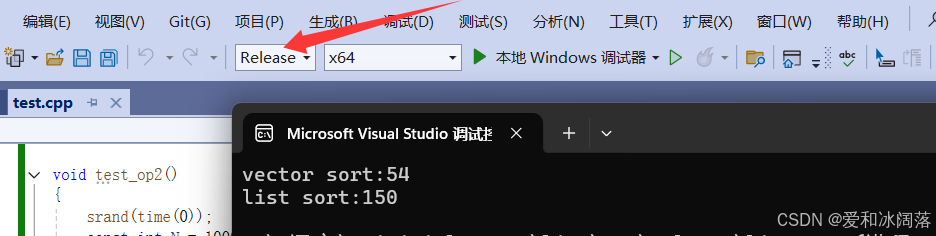
如果需求是将链表进行排序,那么将list的迭代区间传给vector还需要再拷贝回来,那么是否还是比直接调用list的sort排序快?
下面我们通过创建两个list对象进行比较
cpp
srand(time(0));
const int N = 1000000;
list<int> lt1;
list<int> lt2;
for (int i = 0; i < N; ++i)
{
auto e = rand() + i;
lt1.push_back(e);
lt2.push_back(e);
}
int begin1 = clock();
// 拷贝vector
vector<int> v(lt2.begin(), lt2.end());
// 排序
sort(v.begin(), v.end());
// 拷贝回lt,这里只能使用assign,因为不同容器之间无法赋值
lt2.assign(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
lt1.sort();
int end2 = clock();
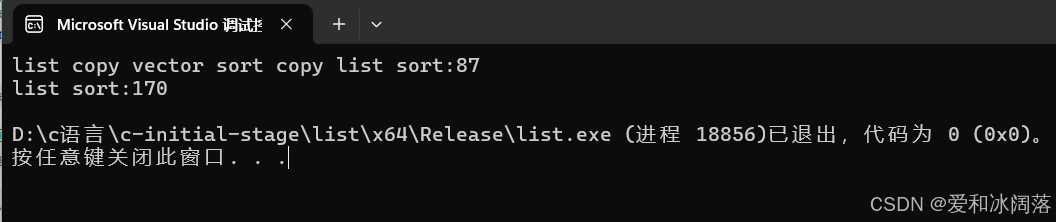
printf("list copy vector sort copy list sort:%d\n", end1 - begin1);
printf("list sort:%d\n", end2 - begin2);显而易见,使用vector排序即使多了两次拷贝,依旧比直接排序快,即苏炳添让1岁小孩先跑三米,也最后超越小孩
三、资源分享
1.list官方文 : https://cplusplus.com/reference/list/list/?kw=list
2.list重要接口实现案例: https://gitee.com/zero-point-civic/c-initial-stage/tree/master/list/list
四、总结
在C语言实现单向链表与双向链表中我们已经熟悉了链表的基本底层构成是如何实现的,在本文我们需要注意C++下的list的不同接口的实现及其避坑,在下一章中我们会简单模拟实现下链表的底层,让大家对list更加熟悉,敬请期待下节分解