字节跳动研究院的研究人员开发了GR-2,一个通用机器人智能体,它将大规模视频预训练与使用GPT风格Transformer模型的机器人动作生成相结合。该系统在多任务桌面操作中取得了97.7%的成功率,在工业拣箱中平均达到79.0%,并在CALVIN基准测试的语言条件任务中建立了新的最先进水平。
介绍
开发能够理解自然语言指令并执行各种操作任务的机器人系统,仍然是人工智能和机器人领域的一项重大挑战。GR-2 (通用机器人代理 2) 通过将视频预训练与机器人动作生成相结合,以统一的模型架构,代表了该领域的重大进步。
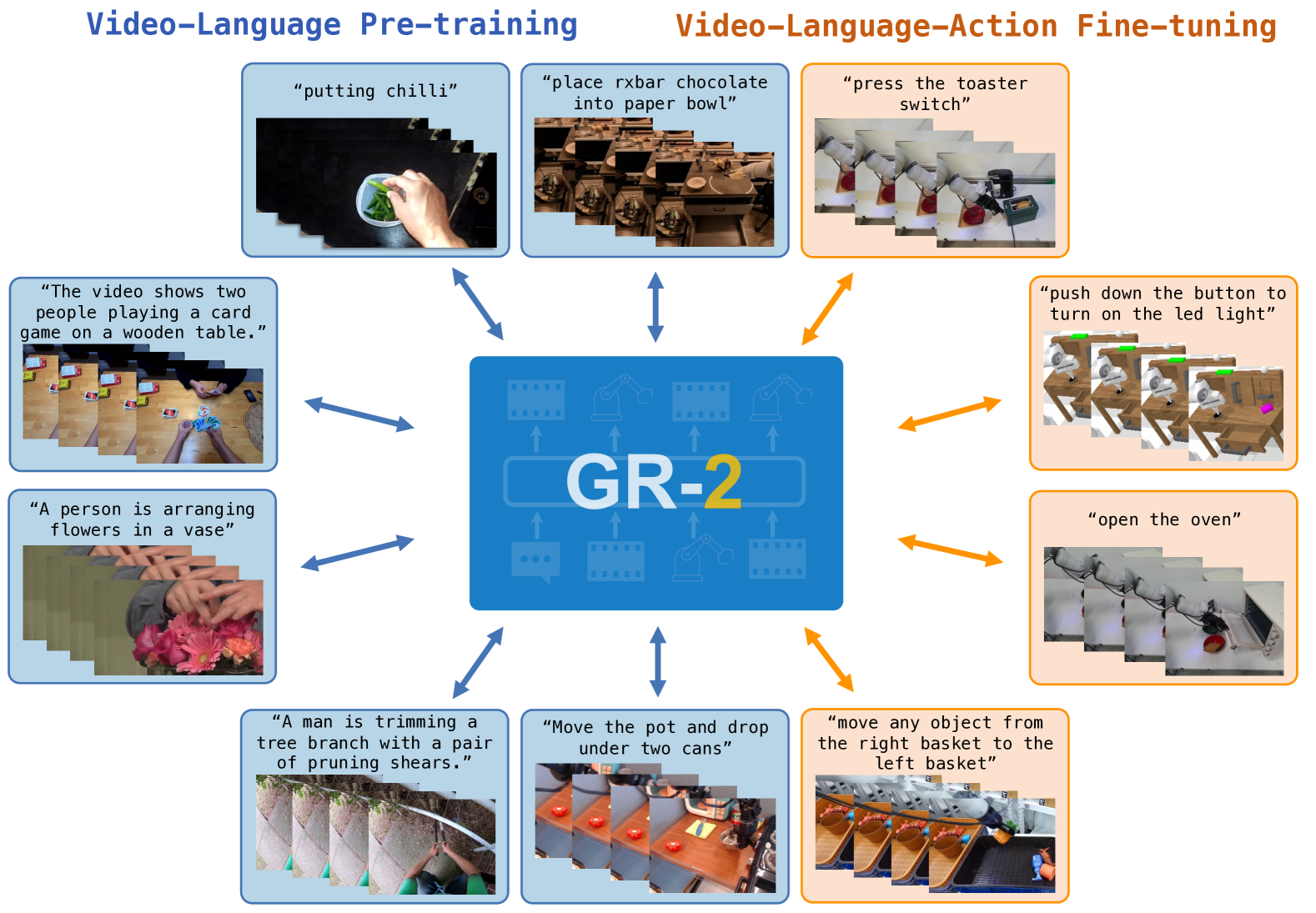
图 1:GR-2 的双重训练过程,展示了对各种人类活动的视频-语言预训练(左)和对机器人特定视频-语言-动作数据的微调(右)。
GR-2 由字节跳动研究人员开发,建立在基础模型原则之上,这些原则已在自然语言处理和计算机视觉等其他领域证明是成功的。通过对包含 3800 万个视频剪辑(超过 500 亿个 tokens)的大规模数据集进行预训练,然后在机器人特定数据上进行微调,GR-2 能够以卓越的效率推广到未见过的环境、对象和任务。
模型架构与训练
GR-2 采用 GPT 风格的 Transformer 架构,该架构处理文本指令、视频帧和机器人动作的 tokenized 表示。模型架构包括:
- 用于处理语言指令的冻结文本编码器
- 用于 tokenizing 图像帧的 VQGAN 模型
- 一个核心 Transformer 解码器,用于在预训练期间预测未来的视频帧,并在微调期间预测视频帧和机器人动作
该模型以自回归方式训练,学习根据先前的 tokens 预测后续 tokens。GR-2 的一个关键创新是集成了条件变分自编码器 (cVAE) 以在微调期间生成动作轨迹,这有助于处理从观察到可能动作的一对多映射。
两阶段训练过程
GR-2 的训练分为两个不同的阶段:
视频-语言预训练: 在此初始阶段,GR-2 学习理解语言指令和视频序列之间的关系。该模型经过训练,可以根据文本描述和先前的帧来预测未来的视频帧。这种预训练发生在包含以下内容的多样化数据集上:
- Howto100M:带有叙述的教学视频
- Ego4D:日常活动的第一人称视角
- Something-Something V2:基本物体交互
- EPIC-KITCHENS:厨房活动
- Kinetics-700:各种环境中的人类动作
- 机器人数据集(RT-1、Bridge):机器人操作视频
预训练目标可以公式化为:
L_{pretrain} = -\\mathbb{E}_{(x,y)\\sim D_{pretrain}}\[\\log p_\\theta(y\|x)\]
其中 x 表示输入(文本和初始帧),y 表示目标未来帧。
视频-语言-动作微调: 在微调期间,GR-2 学习将语言指令和视觉观察映射到机器人动作。微调数据集包含与语言指令配对的机器人操作轨迹。该模型经过训练,可以预测未来的视频帧和动作轨迹:
L_{finetune} = \\lambda_{video}L_{video} + \\lambda_{action}L_{action}
其中,L_{video}是视频预测损失,L_{action} 是动作预测损失,\\lambda_{video} 和 \\lambda_{action} 用作平衡系数。
多任务操作性能
GR-2 在多任务桌面操作方面表现出卓越的性能。该模型在各种条件下对 105 种不同的桌面任务进行了评估:
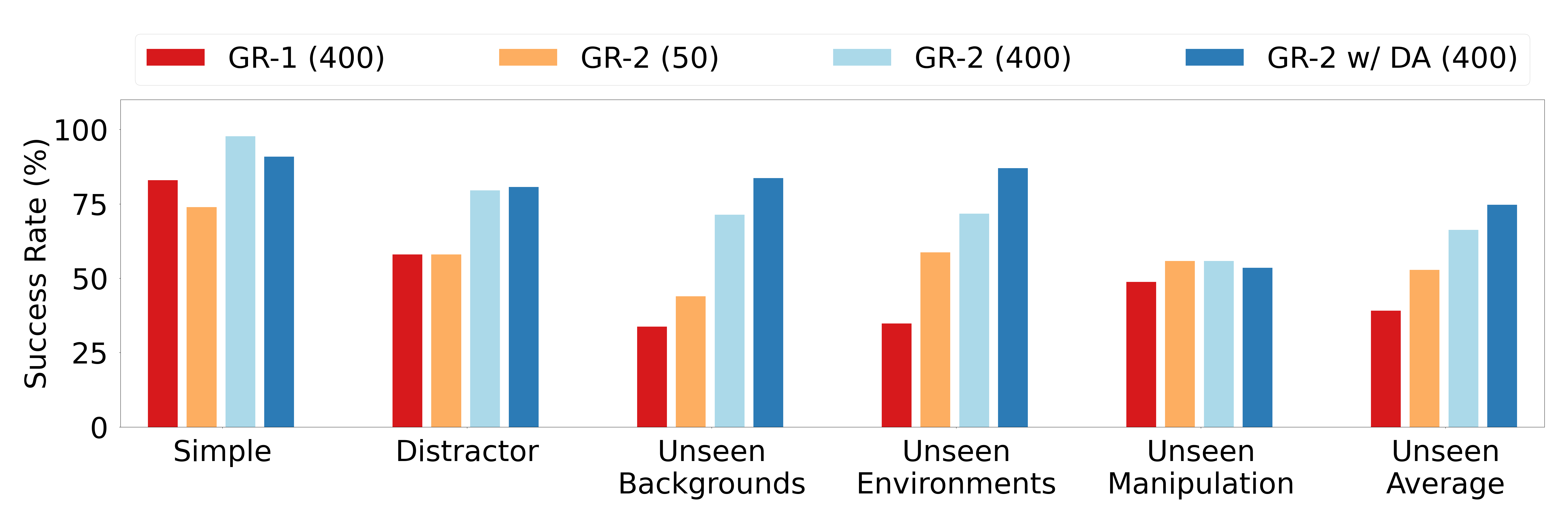
图 2:GR-1 (400)、GR-2 (50)、GR-2 (400) 和使用数据增强的 GR-2 (400) 在不同测试场景中的成功率。括号中的数字表示每个任务的演示次数。
如图 2 所示,GR-2 在每个任务 400 次演示的简单桌面任务中实现了 97.7% 的成功率。即使每个任务只有 50 次演示,GR-2 也能实现 75% 的成功率,这证明了其数据效率。该模型还在具有挑战性的场景中表现出强大的性能:
- 有干扰物(不相关的物体):成功率为 80.0%
- 有未见过的背景:成功率为 71.4%
- 在完全未见过的环境中:成功率为 71.7%
- 执行未见过的操作任务:成功率为 53.3%
这些结果突显了 GR-2 在各种条件下的泛化能力。添加数据增强(GR-2 w/ DA)进一步提高了在未见场景中的性能,将未见条件下的平均成功率提高到 75.3%。
拣选箱性能
GR-2 在工业拣选箱任务中表现出色,该任务需要在杂乱的环境中处理新颖的物体:
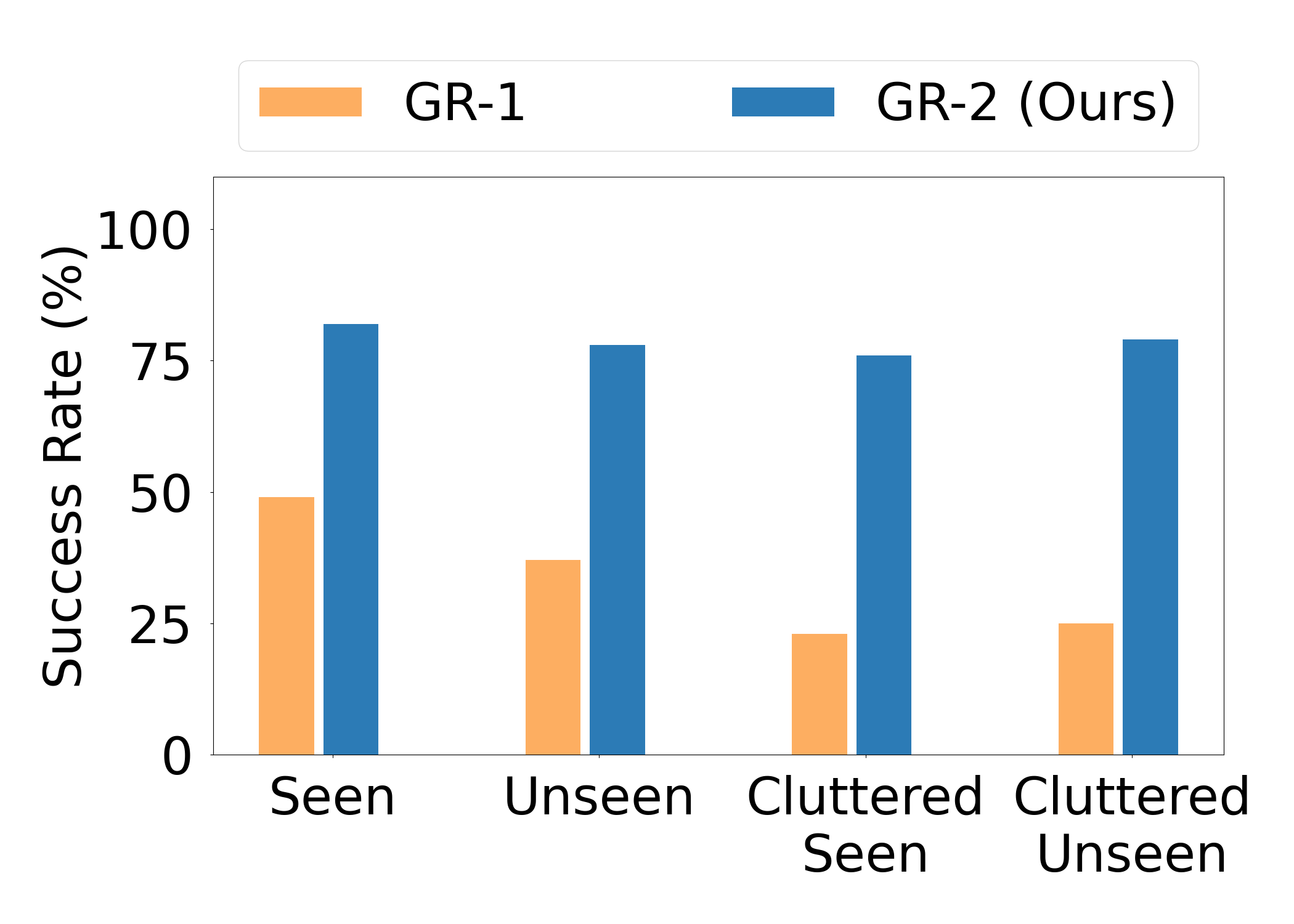
图 3:GR-1 和 GR-2 在不同条件下的拣选箱任务中的成功率比较。
如图 3 所示,GR-2 显著优于其前身 GR-1,平均成功率为 79.0%,而 GR-1 为 35.9%。这种改进在所有测试条件下都是一致的:
- 见过的物体:82.0% vs. 49.0%
- 未见过的物体:77.0% vs. 38.0%
- 具有见过物体的杂乱环境:75.0% vs. 24.0%
- 具有未见过物体的杂乱环境:78.0% vs. 26.0%
巨大的性能差距表明 GR-2 增强了泛化到新对象和处理复杂、杂乱环境的能力,这对于实际工业应用至关重要。
CALVIN 基准测试结果
GR-2 在 CALVIN 基准测试中建立了一个新的最先进水平,CALVIN 基准测试是一个用于语言条件机器人操作的标准化评估框架:
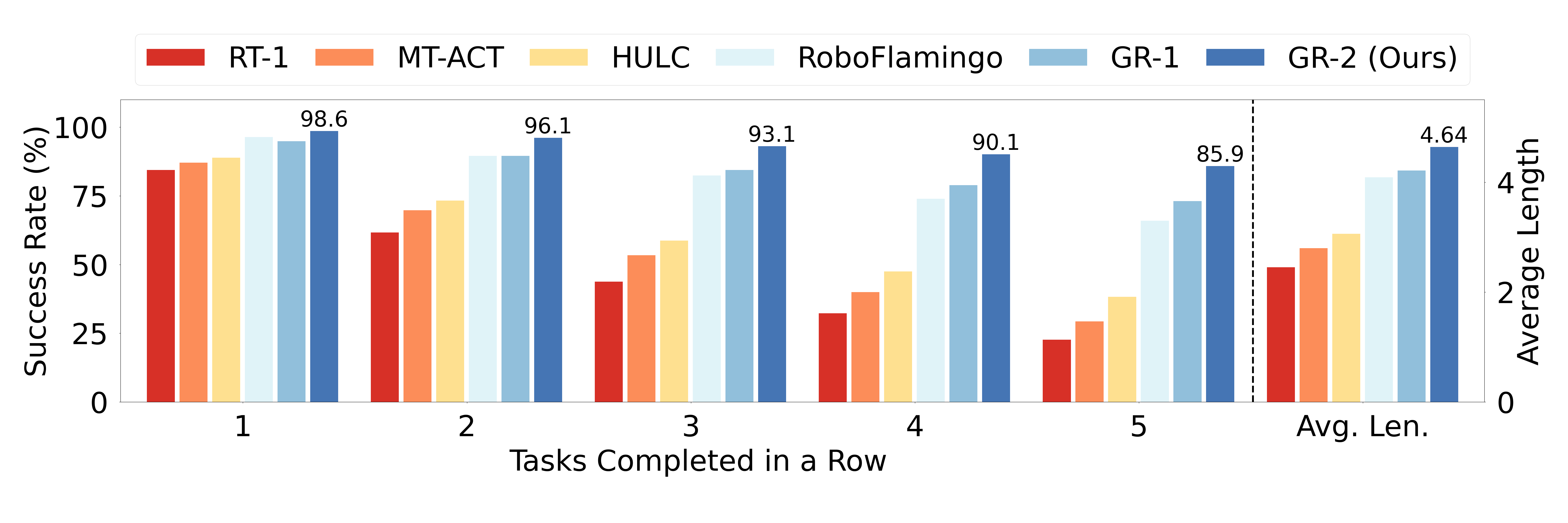
图 4:GR-2 与 CALVIN 基准测试中其他方法的比较,显示了完成不同数量的连续任务的成功率。
GR-2 在 CALVIN 基准测试的所有指标上都实现了卓越的性能:
- 完成一项任务的成功率为 98.6%
- 完成两项连续任务的成功率为 96.1%
- 完成三项连续任务的成功率为 93.1%
- 完成四项连续任务的成功率为 90.1%
- 完成五项连续任务的成功率为 85.9%
该模型的平均任务完成长度为 4.64,远高于 RT-1、MT-ACT、HULC、RoboFlamingo 甚至 GR-1 等竞争方法。这意味着 GR-2 可以成功执行更长的任务序列而不会失败,这证明了其在扩展操作场景中的可靠性。
模型缩放效果
研究团队进行了实验,以了解模型缩放如何影响性能:
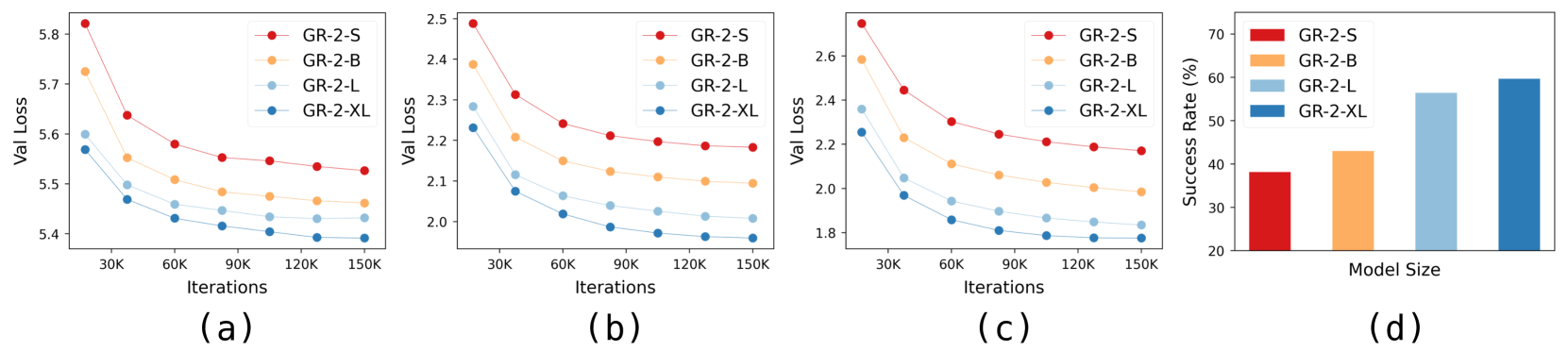
图 5:缩放模型大小对验证损失和成功率的影响:(a-c)不同模型大小在整个训练迭代过程中的验证损失曲线;(d)成功率与模型大小的关系。
GR-2 经过四种尺寸的测试:
- GR-2-S:小型(11 亿参数)
- GR-2-B:基础(19 亿参数)
- GR-2-L:大型(35 亿参数)
- GR-2-XL:超大型(68 亿参数)
如图5所示,更大的模型在训练过程中始终能实现更低的验证损失。性能的提升在真实机器人实验中尤为明显,成功率从GR-2-S的39%提升到GR-2-XL的60%。这种扩展趋势表明,通过进一步增加模型大小,可能会获得更大的性能提升。
视频生成能力
GR-2的一个显著特点是它能够生成与真实执行过程对齐的高质量预测视频:


图6:五个连续任务的预测(Pred)和真实(GT)视频帧的比较,展示了GR-2高质量的视频预测能力。
如图6所示,GR-2可以准确地预测未来视频帧,这些帧与真实情况非常吻合。这种能力有两个目的:
- 它表明该模型对动作如何影响环境有很好的理解
- 它提供了模型计划动作的可解释可视化
预测视频和真实视频之间的高度一致性表明,GR-2正在其预测视频空间中有效地"重放"轨迹,这表明该模型已经学习了视觉世界和机器人动作的有意义的表示。
真实世界部署
对于真实世界的部署,GR-2 采用了一种全身控制(Whole-Body Control, WBC)算法,该算法可确保平稳而准确地执行生成的动作轨迹。系统设置包括:
- Kinova Gen3 机械臂
- Robotiq 2F-85 夹爪
- 两个摄像头(静态和末端执行器安装)
WBC 算法将轨迹跟踪表述为一个优化问题:
def whole_body_control(desired_trajectory, current_state):
# 目标函数结合了位置、方向和夹爪跟踪
def objective(action):
return position_cost(action) + orientation_cost(action) + gripper_cost(action)
# 通过优化找到最优动作
optimal_action = minimize(objective, initial_guess)
return optimal_action该算法确保机器人能够准确执行 GR-2 生成的复杂操作轨迹,从而提高了在真实世界实验中观察到的高成功率。

图7:多任务实验中使用的不同测试环境,展示了基本设置、未见过的背景、未见过的环境和未见过的操作场景。
结论
GR-2 通过将大规模视频预训练与高效的机器人动作生成相结合,代表了通用机器人操作领域的重大进步。该模型在各种评估指标上表现出卓越的性能:
- 在多任务桌面操作中具有高成功率(97.7%)
- 对未见过的环境、物体和任务具有强大的泛化能力
- 在工业料箱拣选任务中表现出色
- 在 CALVIN 基准测试中获得最先进的结果
- 随着模型尺寸的增加,具有有效的扩展特性
该模型生成准确的视频预测以及动作轨迹的能力提供了可解释性以及调试模型理解的方法。使用全身控制算法成功进行真实世界部署证明了 GR-2 在机器人系统中的实际应用价值。
GR-2 在多样化视频数据上进行预训练,然后在机器人特定数据上进行微调,展示了如何将相邻领域的基础模型应用于机器人技术,从而可能降低学习新任务的数据需求。这种方法为更强大、通用的机器人系统铺平了道路,这些系统可以理解自然语言指令并在各种环境中执行多样化的操作任务。