https://arxiv.org/pdf/2509.08827
一篇非常长的综述!!
强化学习在大推理模型上的综述
张凯言 1∗†1^{\ast \dagger}1∗† ,左宇欣 1∗†1^{\ast \dagger}1∗† ,何冰祥 1∗1^{*}1∗ ,孙友邦 1∗1^{*}1∗ ,刘润泽 1∗1^{*}1∗ ,姜彻 1∗1^{*}1∗ ,范宇辰 23∗2^{3*}23∗ ,田凯 1∗1^{*}1∗ ,贾国利 ∗^{*}∗ ,李鹏 k2,6∗k^2,6*k2,6∗ ,傅宇 9∗^{9*}9∗ ,吕兴泰,张宇辰 2,4∗2,4*2,4∗ ,曾思航7,阙尚 1,241,241,24 ,李浩成 1∗1^{*}1∗ ,王时杰2,王宇如1,龙新伟1,刘方夫1,徐祥1,马嘉泽1,朱学凯3,华尔摩 1,21,21,2 ,刘一浩 1,21,21,2 ,李宗林2,陈华宇1,曲晓叶2,李亚夫2,陈伟则1,袁振昭1,高俊奇6,李东6,马志远8,崔干2,刘志远,戚碧清2,丁宁1,2,周Bowen1,2
1清华大学 2上海人工智能实验室 3上海交通大学 4北京大学5中国科学技术大学 6哈尔滨工业大学 7华盛顿大学8华中科技大学 9伦敦大学学院十项目负责人。*核心贡献者。
TsinghuaC3I/Awesome-RL-for-LRMs
摘要 | 在本文中,我们调查了近期在用于推理的大型语言模型(LLMs)的强化学习(RL)方面的进展。RL在提升LLM能力的前沿方面取得了显著成功,特别是在处理复杂的逻辑任务,如数学和编程方面。因此,RL已成为将LLMs转化为LRMs的基础方法。随着该领域的快速发展,进一步扩展用于LRMs的RL现在面临着计算资源、算法设计、训练数据和基础设施等方面的基础性挑战。为此,重新审视该领域的发展、重新评估其轨迹、并探索增强RL向人工超级智能(ASI)可扩展性的策略是及时的。特别是,我们考察了将RL应用于LLMs和LRMs以实现推理能力的研究,尤其是自DeepSeek- R1发布以来,包括基础组件、核心问题、训练资源和下游应用,以确定这一快速发展的领域未来的机遇和方向。我们希望这篇综述能促进对更广泛推理模型的RL研究的未来发展。
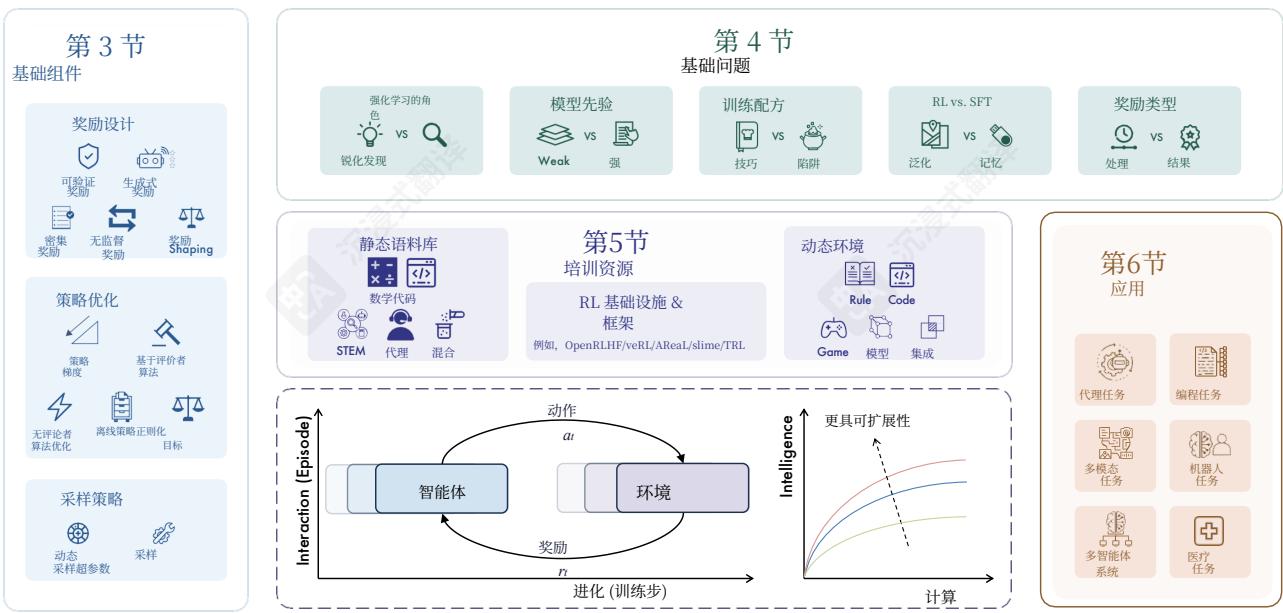
图1 | 调查概述。我们介绍了RLMs的基础组件,以及开放问题、训练资源和应用。本次调查的核心重点在于长期演化过程中语言代理与环境之间的大规模交互。
Contents
1引言42基础知识52.1背景.52.2边界模型.72.3相关综述.83基础组件103.1奖励设计.103.1.1可验证奖励.103.1.2生成式奖励.133.1.3密集奖励.143.1.4无监督奖励.163.1.5奖励塑形.183.2策略优化.193.2.1策略梯度目标.193.2.2基于评价者的算法.213.2.3无评价者算法.223.2.4策略外优化.243.2.5正则化目标.263.3采样策略.283.3.1动态和结构化采样.283.3.2采样超参数.294基础问题304.1RL的作用:锐化或发现.314.2RL与SFT:泛化或记忆.324.3模型先验:弱和强.344.4训练配方:技巧或陷阱.354.5奖励类型:过程或结果.365训练资源375.1静态语料库.375.2动态环境.405.3RL基础设施.436应用466.1编码任务.476.2代理任务.496.3多模态任务.52
6.4 多智能体系统.55 6.5 机器人任务.56 6.6 医疗任务.58 7 未来方向 60 7.1 LLMs的持续强化学习.60 7.2 基于记忆的LLMs强化学习.60 7.3 基于模型的LLMs强化学习.61 7.4 教授LRMs高效推理.61 7.5 教授LLMs潜在空间推理.61 7.6 LLMs预训练的强化学习.62 7.7 基于扩散的LLMs强化学习.62 7.8 科学发现中的LLMs强化学习.63 7.9 架构- 算法协同设计的强化学习.63 8 结论 64 作者贡献 65
1. 引言
强化学习 (RL) Sutton 等人,1998反复证明,狭窄且明确定义的奖励信号可以驱动人工智能代理在复杂任务上达到超人类水平。像 AlphaGo Silver 等人,2016 和 AlphaZero Silver 等人,2017, 这些完全通过自我博弈和奖励反馈学习的里程碑式系统,在围棋、国际象棋、将棋和战略棋类 Perolat 等人,2022,Schrittwieser 等人,2020,Silver 等人,2018, 中超越了世界冠军,确立了强化学习作为高级问题解决实用且有前景的技术。在大语言模型 (LLMs) Zhao 等人,2023a, 的时代,强化学习最初作为人类对齐 Ouyang 等人,2022的后训练策略而声名鹊起。广泛采用的强化学习来自人类反馈 (RLHF) Christiano 等人,2017 和直接偏好优化 (DPO) Rafailov 等人,2023 微调预训练模型以遵循指令并反映人类偏好,显著提高了有用性、诚实性和无害性 (3H) Bai 等人,2022b。
最近,一种新趋势已经出现:用于大型推理模型 (LRMs) 的强化学习 Xu 等人,2025a, 其目标不仅是使行为一致,还要激励推理本身。两个最近的里程碑(即,OpenAI o1 Jaech 等人,2024 和 DeepSeek- R1 Guo 等人,2025a) 表明,使用具有可验证奖励的强化学习 (RLVR),例如数学答案正确性或代码单元测试通过率,来训练大型语言模型可以使模型能够执行长文本推理,包括规划、反思和自我纠正。OpenAI 报告 Jaech 等人,2024 称 o1 的性能随着额外的强化学习(增加训练时间计算)和更多用于"思考"的时间(推理时间计算)Brown 等人,2024,Liu 等人,2025m,Snell 等人,2024, 一起提高,揭示了一个超越单独预训练的新扩展轴 Aghajanyan 等人,2023,Kaplan 等人,2020。DeepSeek- R1 Guo 等人,2025a 对数学使用显式、基于规则的准确奖励,以及对编码任务使用基于编译器或测试的奖励。这种方法表明,大规模强化学习,特别是,组相对策略优化 (GRPO),即使在后续对齐阶段之前,也能在基础模型中诱导复杂的推理行为。
这种工作重新定义了推理为一种可以明确训练和扩展的能力 OpenAI, 2025a, b: LRMs 将大量的测试时间计算分配给生成、评估和修订中间思维链 Wei 等人,2022, 并且随着这种计算预算的增加,它们的性能会提高。这种动态为能力提升引入了一条补充路径,与预训练期间的数据和参数扩展垂直 Aghajanyan 等人,2023年,Kaplan 等人,2020, 同时利用奖励最大化目标 Silver 等人,2021, 可以自动检查的奖励,只要存在可靠的验证器(例如,竞赛数学 Guo 等人,2025a,Jaech 等人,2024, 竞争编程 El- Kishky 等人,2025, 以及选定的科学领域 Bai 等人,2025)。此外,RL 可以通过生成自训练数据来克服数据限制 Shumailov 等人,2024年,Villalobos 等人,2022 Silver 等人,2018年,Zhao 等人,2025a。因此,RL 越来越被视为一种有前景的技术,可以在更广泛的任务上通过持续扩展实现人工超智能(ASI)。
与此同时,进一步扩展 RL 以用于 LRMs 引入了新的约束,不仅在计算资源方面,也在算法设计、训练数据和基础设施方面。如何以及在哪里扩展 RL 以用于 LRMs 以实现高级智能并产生实际价值仍然是未解决的问题。因此,我们认为现在是重新审视该领域发展并探索增强 RL 可扩展性以实现人工超级智能的策略的时候了。总之,本综述回顾了以下关于 RL 用于 LRMs 的最新工作:
- 我们在 LRMs 的背景下介绍了 RL 建模的初步定义(§ 2.1),并概述了自 OpenAI o1 发布以来前沿推理模型的发展(§ 2.2)。- 我们回顾了关于 LRMs 的 RL 基础组件的最新文献,包括奖励
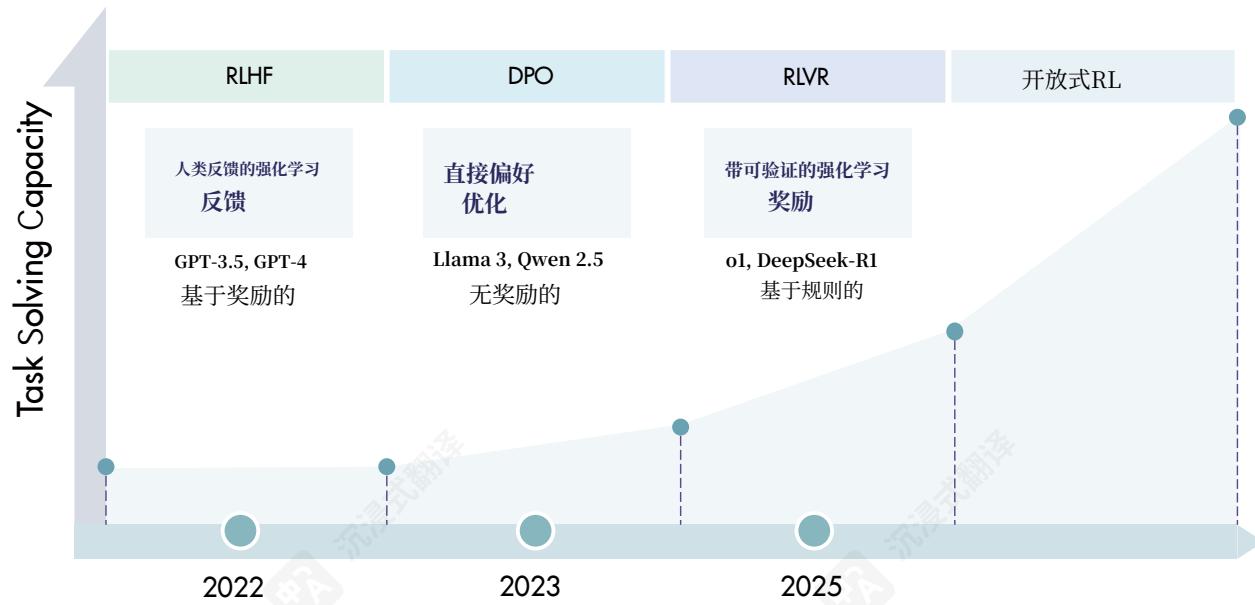
图2|近年来,RLHF和DPO一直是人类对齐的两种主要RL方法。相比之下,RLVR代表了LRMs RL领域的新兴趋势,显著增强了它们解决复杂任务的能力。对于LLMs的RL扩展的下一阶段仍然是一个开放性问题,而开放式RL则代表了一个特别具有挑战性和前景的方向。
设计(§3.1)、策略优化(§3.2)和采样策略(§3.3),比较了每个组件的不同研究方向和技术方法。
-
我们讨论了LRMs RL中的基础性和仍有争议的问题(§4),例如RL的作用(§4.1)、RL与监督微调(SFT)(§4.2)、模型先验(§4.3)、训练配方(§4.4)和奖励定义(§4.5)。我们认为这些问题需要进一步探索,以实现RL的持续扩展。
-
我们考察了RL的训练资源(§5),包括静态语料库(§5.1)、动态环境(§5.2)和训练基础设施(§5.3)。虽然这些资源在研究和生产中都可以重复使用,但仍需要进一步标准化和发展。
-
我们回顾了强化学习(RL)在广泛任务中的应用(§6),例如编码任务(§6.1)、代理任务(§6.2)、多模态任务(§6.3)、多智能体系统(§6.4)、机器人任务(§6.5)和医疗应用(§6.6)。
-
最后,我们讨论了语言模型(§7)在强化学习(RL)中的未来方向,涵盖了新算法、机制、特征和额外的研究途径。
2. 前提
2.1. 背景
在本节中,我们介绍了强化学习的基本组件,并描述了语言模型如何在强化学习框架中配置为智能体。如图3所示,强化学习提供了一个用于序列决策的通用框架,其中智能体通过采取行动与环境交互以最大化累积奖励。在经典强化学习中,问题通常被表述为一个马尔可夫
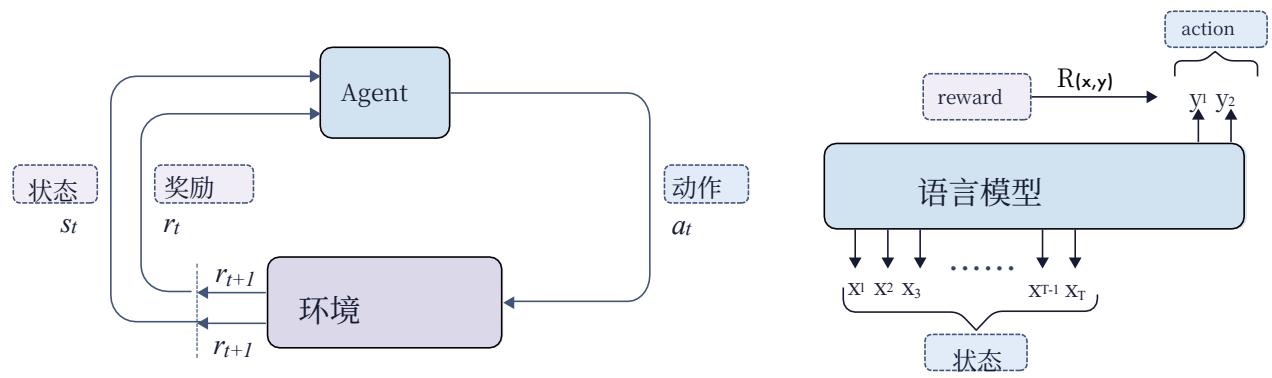
图3|强化学习和语言模型(LMs)作为代理的基本组件。代理选择动作,而环境在每个回合中提供状态和奖励。在语言模型(LMs)的上下文中,完成标记被视为动作,这些动作与上下文连接形成状态。奖励通常在整个响应级别分配。
决策过程(MDP)Sutton et al.,1998,,它由一个元组 (S,A,P,R,γ)(S,\mathcal{A},\mathcal{P},R,\gamma)(S,A,P,R,γ) 定义。主要组件包括状态空间S、动作空间A、转换动态 P:S×A↦S.\mathcal{P}:S\times \mathcal{A}\mapsto S.P:S×A↦S. 、奖励函数 R:S×A↦RR:S\times \mathcal{A}\mapsto \mathbb{R}R:S×A↦R 和折扣因子 γ∈0,1∘\gamma \in 0,1{\circ}γ∈0,1∘ 在每一步,智能体观察一个状态 sts_tst ,根据其策略 πθ\pi{\theta}πθ (由 θ\thetaθ 参数化)选择一个动作 ata_{t}at ,获得一个奖励 rtr_trt ,并转换到下一个状态 st+1s_{t + 1}st+1 。当将RL应用于语言模型时,这些概念可以自然地映射到语言领域,只需最小限度的调整。映射总结如下:
·提示/任务 (x)(x)(x) :对应于初始状态或环境上下文,从数据分布中抽取,并对应于数据集 D\mathrm{D}D 0
·策略 (πθ)(\pi_{\theta})(πθ) :表示语言模型,该模型在提示下生成长度为 TTT 的序列,表示为 y=(y1,...,yT)y = (y_{1},\ldots ,y_{T})y=(y1,...,yT) 0
·状态 (st)(s_t)(st) :定义为当前提示与已生成的标记的组合,即 st=(x,a1:t−1)s_t = (x,a_{1:t - 1})st=(x,a1:t−1)
·动作 (at)(a_{t})(at) :在步骤 ttt 从动作空间A中选择的一个单元。根据粒度,动作可能是一个完整的序列 yyy (序列级),一个标记 at∈Va_{t}\in \mathcal{V}at∈V (标记级),或一个片段 y(k)=(y1(k),...,yTk(k))y^{(k)} = (y_{1}^{(k)},\ldots ,y_{T_{k}}^{(k)})y(k)=(y1(k),...,yTk(k)) (步骤级),详细比较见表2。
·状态转换动态§:在LLM的上下文中,状态转换通常是确定的,因为 st+1=st,ats_{t + 1} = s_t,a_tst+1=st,at ,其中 ⋅,⋅\\cdot ,\\cdot ⋅,⋅ 表示字符串连接。当状态包含一个EOS标记时,策略转换到一个终止状态,这意味着轨迹结束。
·奖励 (R(x,y)(R(x,y)(R(x,y) 或 rt)r_t)rt) :根据动作粒度分配,例如序列级 R(x,y)R(x,y)R(x,y) 在轨迹结束时,标记级 rt=R(x,a1:t)r_t = R(x,a_{1:t})rt=R(x,a1:t) 每个标记,或步骤级 rk=R(x,y(1:k))r_k = R(x,y^{(1:k)})rk=R(x,y(1:k)) 每个片段。
·返回 (G)(G)(G) :整个轨迹 yyy 的累积奖励,针对提示 xxx (通常在有限视界下使用 γ=1)\gamma = 1)γ=1) )。当使用序列级奖励时,它会简化为单个标量 R(x,y)R(x,y)R(x,y) ,否则会按每个标记/步骤聚合奖励,具体细节请参见表2。
在这个设置中,学习目标Sutton等人,1998是要在数据分布D上最大化预期累积奖励,即,
maxθJ(θ)≔Ex∼D,y∼πθ(x)G.(1) \max_{\theta}\mathcal{J}(\theta)\coloneqq \mathbb{E}{x\sim \mathcal{D},y\sim \pi{\theta}(x)}G. \tag{1} θmaxJ(θ):=Ex∼D,y∼πθ(x)G.(1)
在实践中,通常会将学习到的策略正则化到参考策略 πref\pi \mathrm{ref}πref ,这通常通过KL散度约束来实现,以稳定训练并保持语言质量。在以下几节中,我们介绍了基于这个基本公式的各种算法。
2.2. 前沿模型
在本小节中,我们概述了使用类似强化学习方法的最新大推理模型,大致按三个主要方向按时间顺序组织:LRMs、代理式LRMs和多模态LRMs。
在过去一年中,强化学习逐步扩展了推理模型及其应用的前沿。首批大推理模型,OpenAI的o1 Jaech等人、2024系列,证明了在训练时间强化学习和测试时间计算方面进行扩展以获得更强大的推理能力的有效性,在数学、编程和科学基准测试中取得了领先结果。DeepSeek的旗舰模型R1 Guo等人,2025a作为首个在基准测试中与o1性能相匹配的开源模型。它采用多阶段训练流程以确保模型能力的全面性,并探索了纯强化学习路线,无需监督微调(即零强化学习)。其他专有模型发布紧随其后:Claude- 3.7- Sonnet Anthropic,2025a具有混合推理功能,Gemini 2.0和2.5 Comanici等人,2025引入了更长的上下文长度,Seed- Thinking 1.5 Seed等人,2025b展示了跨领域的泛化能力,而o3 OpenAI,2025b系列展示了日益先进的推理能力。最近,OpenAI推出了他们的首个开源推理模型gpt- oss- 120b Agarwal等人,2025a,随后推出了GPT5 Ope- nAI,2025a,他们至今最强大的AI系统,能够在高效模型和更深推理模型GPT- 5 thinking之间灵活切换。平行的开源工作继续扩展了这一领域。在Qwen家族中,QwQ- 32B Team,2025g达到了R1的性能,随后是Qwen3 Yang等人,2025a系列,代表性模型Qwen3- 235B进一步提高了基准测试分数。Skywork- OR1 He等人,2025d模型套件基于R1蒸馏模型,通过有效数据混合和算法创新实现了可扩展的强化学习训练。Minimax- M1 Chen等人,2025a是首个引入混合注意力以高效扩展强化学习的模型。其他工作包括Llama- Nematron- Ultra Hercovich等人,2025旨在平衡准确性和效率;Magistral 24B Rastogi等人,2025,通过从头开始使用强化学习训练,而无需从先前的模型中蒸馏;以及Seed- OSS Team,2025a,强调长上下文推理能力。
模型推理的改进反过来扩展了它们在编码和代理场景中的用例。Claude系列以其在代理编码任务上的领先性能而闻名,这通过Claude- 4.1- Opus Anthropic,2025b,得到了体现,它进一步推动了SWE- bench Jimenez et al.,2023上的最先进结果。Kimi K2 Team,2025d是一个最近的代表性代理模型,它专门针对代理任务进行了优化,建立了大规模代理训练数据合成和适用于不可验证奖励的通用RL程序。随后,GLM4.5 Zeng et al.,2025a和DeepSeek- V3.1发布都强调了工具使用和代理任务,在相关基准测试中显示了显著的改进。
多模态是推理模型广泛采用的关键组成部分。大多数前沿专有模型,包括GPT- 5、o3、Claude和Gemini系列,都是原生多模态的。Gemini- 2.5 Comanici等人,2025特别强调了在文本、图像、视频和音频方面的强大性能。在开源方面,Kimi 1.5 团队,2025d代表了早期向多模态推理的努力,突出了长上下文扩展以及跨文本和视觉领域的联合推理。QVQ Qwen团队,2025在视觉推理和分析思维方面表现出色,而Skywork R1V2 Wang等人,2025k通过混合RL平衡推理和通用能力,同时使用MPO和GRPO。作为InternVL系列的重要补充,InternVL3 Zhu等人,2025c采用了
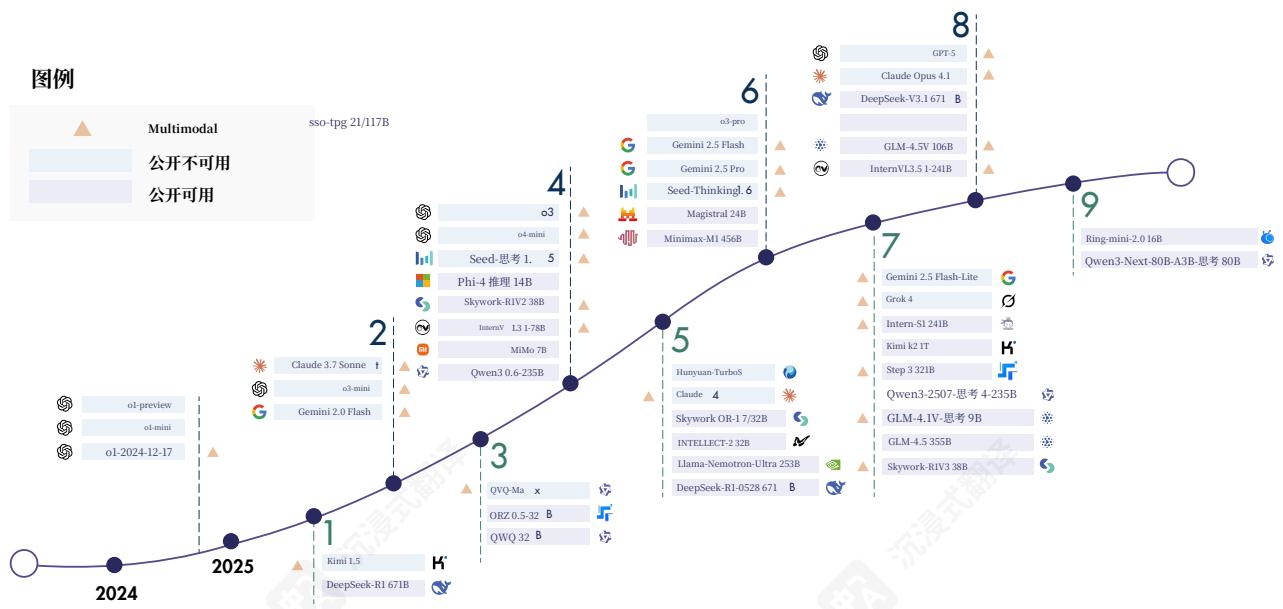
图4|使用强化学习训练的有代表性的开源和闭源推理模型的时间线,包括语言模型、多模态模型和智能体模型。
一个统一的原生多模态预训练阶段,之后InternVL3.5Wang等人,2025o使用了两阶段级联RL框架,实现了更高的效率和通用性。最近,Intern- S1Bai等人,2025模型专注于跨不同领域的多模态科学推理,受益于在线RL期间混合奖励设计,以促进在广泛任务上的同时训练。其他近期模型包括Step3Wang等人,2025a,专为高效训练和最小化解码成本而设计,以及GLM- 4.5V团队等,2025a,在大多数视觉多模态基准测试中表现最先进。
除上述模型外,我们还提供了图4中的推理模型综合列表以及表1中开源模型详细信息。
2.3.相关调查
在本小节中,我们比较了与强化学习和大型语言模型相关的近期调查。几项调查主要关注强化学习本身,涵盖了经典强化学习及其最新扩展。Ghasemi等人2024提出了一项涵盖算法和现实挑战的通用强化学习调查,Huh和Mohapatra2023专注于多智能体强化学习,Zhang等人2024b回顾了自我博弈技术,Wu等人2025h调查了计算机视觉任务中的强化学习。虽然这些工作为强化学习提供了广泛的视角,但它们并未明确探讨其在大语言模型中的应用。相比之下,其他调查则聚焦于大语言模型及其新兴能力,如长链思维推理Chen等人,2025m,Li等人,2025w,Xia等人2024和自适应行为Feng等人,2025c,Sui等人,2025,其中强化学习通常被引入作为支持这些进步的关键方法。Zhao等人2023a提供了大语言模型架构和应用的广泛概述,而近期研究则专注于推理能力。Zhang等人2025a调查了DeepSeek- R1之后对推理大语言模型的复制研究,Chen等人2025m考察了长链思维推理,Li等人2025w分析了从系统1到系统2推理的过渡。这些研究强调了基于强化学习的方法(如RLHF和RLVR)作为有用的工具,但将它们视为广泛推理策略中的一部分。Sun等人2025b提供了通过基础模型进行推理的更广泛、更有条理的视角。它突出了专门为推理提出或改编的关键基础模型,以及
表1|使用RL训练的代表性开源模型比较。OPMD表示在线策略镜像下降;MPO表示混合偏好优化;CISPO表示剪裁IS- 权重策略优化。T、I和V分别表示文本、图像和视频模态。
|---------|--------------------------------------------|--------------|-----------|----------|----------|-------|------|
| Date | 模型 | 组织 | 架构 | 参数 | 算法 | 模态 | Link |
| 2025.01 | DeepSeek-R1 郭等, 2025a | DeepSeek | MoE/MLA | 671B | GRPO | Text | Q 2 |
| 2025.03 | ORZ 胡等, 2025b | StepAI | Dense | 0.5-32B | PPO | Text | Q 2 |
| 2025.03 | Qwen3 团队, 2025g | 阿里巴巴Qwen | Dense | 32B | - | Text | Q 2 |
| 2025.04 | Phi-4推理 Abdin等人, 2025 | Microsoft | 密集 | 14B | GRPO | Text | Q 2 |
| 2025.04 | Skywork-R1/2 王等人, 2025k | Skywork | Dense | 38B | MPO/GRPO | T/I | Q 2 |
| 2025.04 | InternVL3 Zhu等人, 2025c | 上海人工智能实验室 | 密集 | 1-78B | MPO | T/I/V | Q 2 |
| 2025.04 | MiMo 小米等, 2025 | 小米 | 密集 | 7B | GRPO | Text | Q 2 |
| 2025.04 | Qwen3 杨等, 2025a | 阿里巴巴Qwen | MoE/Dense | 0.6-235B | GRPO | Text | Q 2 |
| 2025.05 | Llama-Nemotron-Ultra Bercovich等人, 2025 | NVIDIA | Dense | 253B | GRPO | Text | Q 2 |
| 2025.05 | INTELLECT2 团队等, 2025b | Intellect AI | 密集 | 32B | GRPO | Text | Q 2 |
| 2025.05 | Hunyuan-Turbo5 团队等, 2025c | 腾讯 | 混合MoE | 560B | GRPO | Text | Q 2 |
| 2025.05 | Skywork-R1-1 He等人, 2025d | Skywork | 密集 | 7B/32B | GRPO | Text | Q 2 |
| 2025.05 | DeepSeek-R1/2528 郭等, 2025a | DeepSeek | MoE/MLA | 671B | GRPO | Text | Q 2 |
| 2025.06 | Magistral Rastogi等人, 2025 | Mistral AI | Dense | 24B | GRPO | Text | Q 2 |
| 2025.06 | Minimax-M1 Chen等人, 2025a | Minimax | 混合MoE | 456B | CISPO | Text | Q 2 |
| 2025.07 | Intern-S1 白等人, 2025 | 上海AI Lab | MoE | 241B | GRPO | T/I/V | Q 2 |
| 2025.07 | Kimi K2 团队等, 2025c | Kimi | MoE | 1T | OPMD | Text | Q 2 |
| 2025.07 | 步骤3 王等人, 2025a | 步骤AI | MoE | 321B | - | T/I/V | Q 2 |
| 2025.07 | Qwen3-2507 杨等人, 2025a | 阿里巴巴Qwen | MoE/Dense | 4-235B | GSPO | Text | Q 2 |
| 2025.07 | GLM-4.1V-思考 团队等, 2025a | 智谱AI | Dense | 9B | GRPO | T/I/V | Q 2 |
| 2025.07 | GLM-4.5 曾等, 2025a | 智谱AI | MoE | 355B | GRPO | Text | Q 2 |
| 2025.07 | Skywork-R1/3 沈等人, 2025b | Skywork | Dense | 38B | GRPO | T/I | Q 2 |
| 2025.08 | gpt-oss Agarwal等人, 2025a | OpenAI | MoE | 117B/21B | - | Text | Q 2 |
| 2025.08 | Seed-GSS 团队, 2025b | 字节跳动Seed | 密集 | 36B | - | Text | Q 2 |
| 2025.08 | GLM-4.5V 团队等, 2025a | 智谱AI | MoE | 106B | GRPO | T/I/V | Q 2 |
| 2025.08 | InternVL3/5 王等人, 2025o | 上海AI实验室 | MoE/Dense | 1-241B | MPO/GSPO | T/I/V | Q 2 |
| 2025.09 | ERNIE-4.5-Thinking 百度-ERNIE团队, 2025 | 百度 | MoE | 21B-A3B | - | Text | Q 2 |
在多样化的推理任务、方法和基准方面的最新进展。张等人2025b研究了强化学习如何赋予大型语言模型自主决策和适应性代理能力。徐等人2025a通过讨论大型语言模型的强化推理,更接近我们的关注点,强调试错优化如何改进复杂推理。吴2025通过调查奖励模型和学习反馈的策略来补充这一观点。然而,这些工作仍然面向推理性能或奖励设计,而不是为大型语言模型提供整体强化学习方法。Srivastava和Aggarwal2025代表了一个更近期的尝试,通过回顾用于大型语言模型对齐和增强的强化学习算法来弥合这两个领域,主要通过RLHFChristiano等人,2017,RLAIFLee等人,2024b,和DPORafailov等人,2023。它仍然主要关注对齐而不是推理能力。
与以往涵盖通用强化学习(RL)或大型语言模型(LLMs)中的推理的调查不同,我们将RL置于中心,系统地总结了其在LLM训练生命周期中的角色,包括奖励设计、策略优化和采样策略。我们的目标是确定在LRMs中扩展强化学习以实现人工通用智能(ASI)的新方向,重点关注长期交互和进化。
3.基础组件
- 基础组件在本节中,我们回顾了LRMs的RL基础组件,包括奖励设计(§3.1)、策略优化算法(§3.2)和采样策略(§3.3)。基础组件的分类如图5所示。
3.1.奖励设计
3.1. 奖励设计在本小节中,我们全面考察了LRMs的RL奖励设计。我们从§3.1.1的可验证奖励开始,这提供了一个自然的起点。在这个方向上取得了重大进展,DeepSeek- R1的成功就是例证,它展示了通过可验证奖励机制实现RL的可扩展性。相比之下,§3.1.2考察了生成式奖励,其中模型被用于验证或直接生成奖励信号。然而,可验证和生成式奖励通常表示为稀疏数值反馈。一个重要的补充维度在于奖励信号的密度。§3.1.3相应地考察了结合密集奖励的方法。另一个分类维度是奖励是否从外部真实标签计算或由模型直接估计。这种区别促使我们在§3.1.4中讨论无监督奖励。基于这四个类别,我们在§3.1.5转向奖励塑形,分析结合或转换不同奖励信号以促进学习的策略。
3.1.1.可验证奖励
要点
·基于规则的奖励通过利用准确性和格式检查,为RL(强化学习)提供了可扩展且可靠的训练信号,尤其是在数学和代码任务中。·验证者的定律强调,具有清晰和自动验证的任务能够实现高效的RL优化,而主观任务仍然具有挑战性。
基于规则的奖励。奖励作为RL的训练信号,决定了优化方向Guo等人,2025a。最近,基于规则的验证奖励主要被用于在大规模RL中训练LRMs(大型语言模型)。这些奖励能够可靠地增强数学
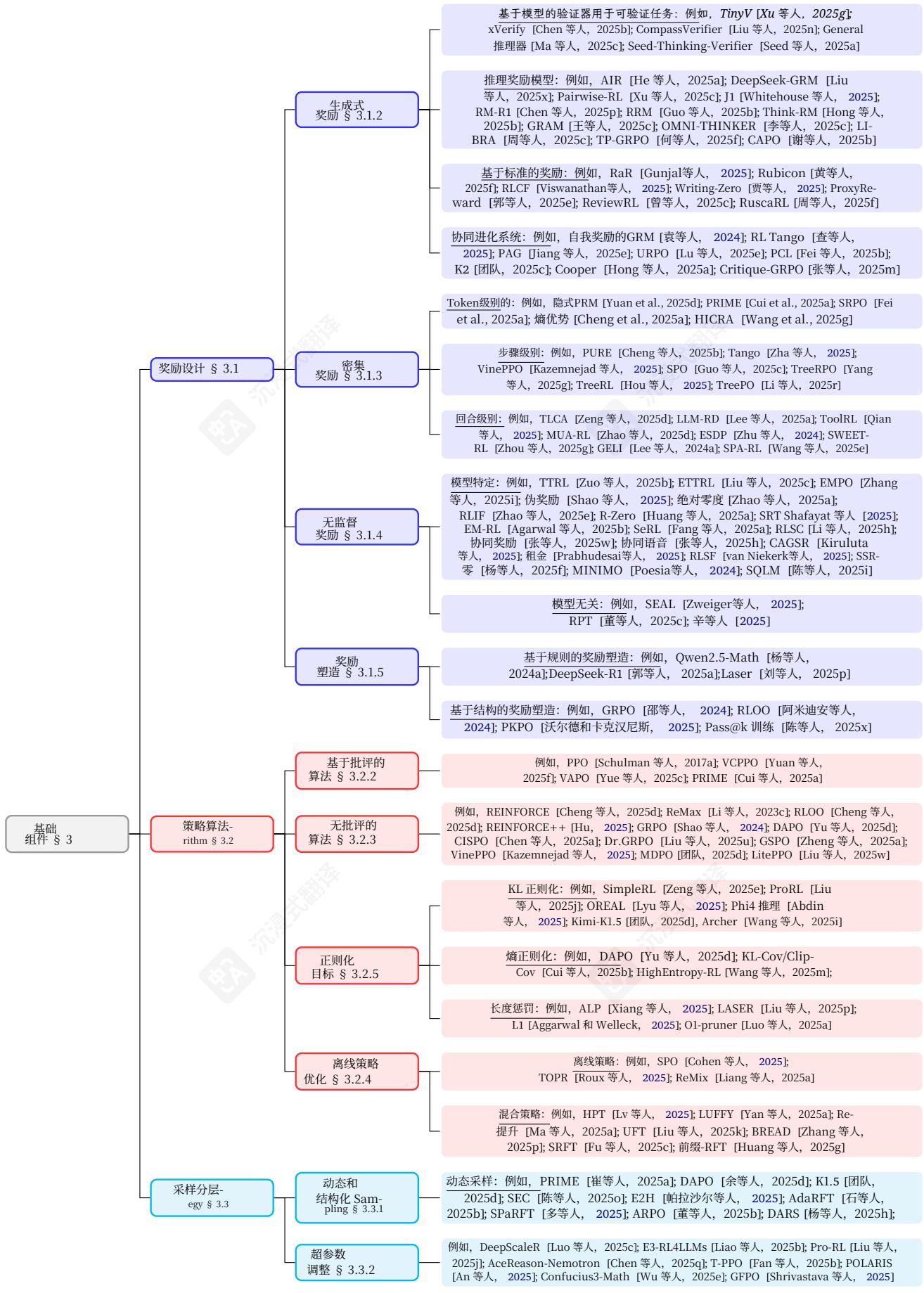
图5|基础组件和每个方向的代表性工作的分类学。
和编码推理能力,通过鼓励更长时间和更具反思性的思维链 Guo et al., 2025a, Team, 2025c, Yu et al., 2025d。这种范式被正式化为RLVR,在Tülu 3 Lambert et al., 2024, 中,它用程序化验证器(例如,答案检查器或单元测试)替换了学习到的奖励模型。此类验证器在具有客观可验证结果的领域中提供二进制、可检查的信号。类似的基于规则的验证奖励设计方法随后被集成到DeepSeek的训练管道中。例如,DeepSeek- V3 Liu et al., 2024明确地结合了一个针对确定性任务量身定制的基于规则的奖励系统,而DeepSeek- R1 Guo et al., 2025a进一步采用了基于准确性和基于格式的奖励。基于规则的奖励与基于结果或基于过程的奖励模型(RMs)相反,例如标准RLHF,它使用在人类偏好排名上训练的学习到的奖励模型Ouyang et al., 2022以及基于步骤级注释训练的过程奖励模型(PRMs) Setlur et al., 2024, Sun et al., 2025c, Yuan et al., 2025d。DeepSeek- V3和DeepSeek R1证明,当扩展到大规模强化学习设置时,RMs可能会遭受奖励黑客攻击,但通过在可能的情况下利用基于规则的奖励,我们通过使系统对操纵和利用具有抵抗力,从而确保更高的可靠性 Guo et al., 2025a, Liu et al., 2024。在实践中,两种类型的基于规则的验证奖励被广泛使用:
-
准确率奖励:对于具有确定性结果的任务(例如数学),策略必须在规定的分隔符(通常为\boxed{...})内生成最终解决方案。然后,自动检查器将此输出与真实值进行比较。对于编码任务、单元测试或编译器,提供通过/失败信号 Albalak et al., 2025, Chen et al., 2025r, Guo et al., 2025a。
-
格式奖励:这些施加了结构约束,要求模型将其私有的思维链(chain-of-thought)放置在和之间,并在单独的字段中输出最终答案(例如...)。这提高了大规模强化学习(RL)Guo et al., 2025a, Lambert et al., 2024的可靠解析和验证。
基于规则的验证器。基于规则的奖励通常来自基于规则的验证器。这些依赖于大量手动编写的等价规则来确定预测答案是否与真实值匹配。目前,广泛使用的数学验证器主要基于Python库Math- Verify和SymPy。此外,一些作品(如DAPO Yu et al., 2025d)和DeepScaleR Luo et al., 2025c,)也提供了开源和成熟的验证器。最近,Huang et al. 2025e强调了基于规则和基于模型的验证器各自独特的局限性,以指导更可靠的奖励系统的设计。
在实践中,诸如解决数学问题和代码生成等任务难以解决,但相对容易验证,从而满足高效RL优化的主要标准Guo等人,2025a,He等人,2025d:存在清晰的真相,可以快速自动验证,评估许多候选解决方案的可扩展性,以及与正确性紧密相关的奖励信号。相比之下,缺乏快速或客观验证的任务(例如开放式问答或自由形式写作)对基于结果的RL仍然具有挑战性,因为它们依赖于嘈杂的学习奖励模型或主观的人类反馈Yu等人,2025e,Zhou等人,2025e。验证者定律认为,训练AI系统执行任务的容易程度与任务的验证程度成正比。它强调,一旦一个任务可以配备强大的自动反馈,它就可以通过RL快速改进。§6中讨论的成功应用证实了这一原则,因为它们的核心挑战在于可靠验证反馈的设计。相反,§7中强调的许多开放问题恰恰源于缺乏可靠的自动奖励。
3.1.2.生成式奖励
要点
·生成式奖励模型(GenRMs)通过提供细致的文本反馈,将RL扩展到主观、不可验证的领域,克服了基于规则的系统的局限性。·一个主要趋势是训练推理模型(RMs)在判断之前进行推理,通常使用结构化评分标准来指导评估或在一个统一的强化学习(RL)循环中与策略模型共同进化。
虽然基于规则的奖励为可验证任务提供了可靠的信号,正如之前讨论的(§3.1.1),但它们的适用性有限。许多复杂的推理任务,特别是在开放式或创造性领域,缺乏客观的真实情况,使得它们对简单的验证器来说难以处理。为了弥补这一差距,生成式推理模型(GenRMs)已成为一种强大的替代方案。GenRMs不是输出一个简单的标量分数,而是利用大型推理模型(LRMs)的生成能力来产生结构化的批评、推理和偏好,提供更可解释和细致的奖励信号Mahan等人,2024年,张等人,2024a。这种方法解决了两个关键挑战:首先,它提高了对难以解析的可验证任务的验证的鲁棒性;其次,更重要的是,它使强化学习能够应用于主观的、不可验证的领域。
基于模型的验证器用于可验证任务。基于规则系统的首要挑战在于其脆弱性;当模型以意外格式生成正确答案时,它们常常会产生误报。为缓解这一问题,一条研究方向是使用基于规范的生成式规则模型(GenRMs)作为灵活的基于模型的验证器。这些模型被训练用于语义上评估模型自由格式输出与参考答案之间的等价性。这种方法已被用于开发轻量级验证器,以增强现有的基于规则系统Xu等人,2025gl,以及更全面的、多域的验证器,这些验证器能够处理多种数据类型和推理任务Chen等人,2025b,Liu等人,2025n,Ma等人,2025c,Seed等人,2025a。通过用学习到的语义判断替换或补充僵化的字符串匹配,这些验证器为可验证领域的强化学习(RL)提供了更准确的奖励信号。
非可验证任务的生成式奖励。GenRMs的另一个核心应用是基于评估的GenRMs,它使RL能够应用于不适用验证者定律的任务。这种范式已从使用强大的大型语言模型(LLMs)作为零样本评估器演变为复杂、协同进化的系统。我们可以根据其核心设计原则对这些方法进行分类。
·推理奖励模型(学习思考):超越简单偏好预测的重大进步是训练RM在渲染判断之前进行明确推理。这种方法是LLM作为裁判概念Li等人,2023b,Zheng等人,2023,的基础,涉及提示RM生成一个CoT批评或推理依据。例如,CLoudRM首先生成一个自然语言批评,然后使用它来预测一个标量奖励Ankner等人,2024。将奖励建模制定为推理任务的原则现在是最先进RM的核心,这些RM被训练在分配分数或偏好之前生成详细的推理依据Chen等人,2025p,Guo等人,2025b,Hong等人,2025b,Liu等人,2025x,Wang等人,2025c,Zhou等人,2025c。为了进一步提高它们的判断能力,这些推理RM通常使用基于它们最终裁决正确性的简单、可验证的元奖励进行RL训练Chen等人,2025l,Whitehouse等人,2025。这项工作还探索了不同的奖励格式,例如从标记概率中推导出软奖励Mahan等人,2024,Su等人,2025c,Zhang等人,2024a以及权衡点对和成对评分方案之间的权衡He等人,2025a,Xu等人,2025c。
基于标准的奖励(构建主观性):为主观任务的评价提供基准
在更一致的标准下,许多框架采用结构化的评分标准。与依赖硬编码逻辑进行客观、可验证任务的规则方法不同,基于评分标准的方法利用自然语言描述来捕捉主观、不可验证领域中细致的评价标准,因为传统的二元规则在这些领域是不够的。这涉及使用大型语言模型(LLM)来生成或遵循原则清单以指导其评估。RaR Gunjal 等人,2025,QA- LIGN Dineen 等人,2025,Rubicon Huang 等人,2025f,和 RLCF Viswanathan 等人使用此类评分标准来生成细粒度、多方面的奖励。这一概念扩展到将高级任务分解为一组可验证的代理问题 \[Guo 等人,2025e 或生成特定领域的原则,例如用于创意写作 jia 等人,2025 或用于科学评论 Zeng 等人,2025c。此外,评分标准可以双重作用,既作为指导政策探索的教学支架,也作为最终奖励的标准 Zhou 等人,2025f。
-
协同进化系统(统一策略和奖励):最先进的范式超越了静态的策略-奖励关系,转向生成器和验证器共同进步的动态系统。这可以通过以下方式发生:
-
自我奖励,其中单个模型生成自己的训练信号。这曾在自我奖励语言模型 Yuan 等人,2024 中得到显著演示,并在模型在策略和验证器角色之间交替的框架中实现 Jiang 等人,2025e,基于自己的批评进行自我纠正 团队,2025c,Xiong 等人,2025b,Zhang 等人,2025m,或通过完成后的学习内化奖励函数 Fei 等人,2025b。
-
协同优化,其中策略和单独的奖励模型同时训练。例如,RL Tango 联合训练生成器和过程级别的 GenRM,使用共享的结果级别奖励 Zha 等人,2025。类似地,Cooper 协同优化两个模型以增强鲁棒性并减轻奖励攻击 Hong 等人,2025a。其他工作在单个模型内统一策略("玩家")和奖励("裁判")函数,并通过统一的强化学习循环进行训练 Lu 等人,2025e。
这种从静态裁判到动态、协同进化的系统的演变通常由结合基于规则的和生成式信号的混合奖励机制所支持 Li 等人,2025c,Seed 等人,2025a。此外,生成式推理机(GenRMs)正在被改造以提供更细粒度、过程级的反馈,以解决复杂推理链中的信用分配问题 He 等人,2025f,Khalifa 等人,2025,Xie 等人,2025b,Zhao 等人,2025b。本质上,生成式奖励对于将强化学习(RL)扩展到通用推理机(LRMs)所针对的所有任务范围都至关重要。
3.1.3. 密集奖励
要点
- 密集奖励(例如,过程奖励模型)提供细粒度的信用分配,并提高强化学习的训练效率和优化稳定性。- 由于定义密集奖励或使用验证器的难度,开放域文本生成等任务的可扩展性仍然具有挑战性。
在经典强化学习(如游戏和机器人操作任务)中 刘等人,2022年,施密特维瑟等人,2020年,孙等人,2025d,密集奖励在(几乎)每个决策步骤都提供频繁的反馈。这种塑造缩短了信用分配范围,并经常提高样本效率和
表2|语言模型强化学习中的动作和奖励粒度定义 (z(u)(z(u)(z(u) 是在回合 uuu 时的环境反馈)。
|-----------|----------------------|-----------------------|--------------|
| 粒度 | 动作 | 奖励 | 回报(G) |
| 轨迹 | 整个序列y=(a1,...,aT) | 标量R(x,y) | R(x,y) |
| 标记 | 每个标记aT∈V | rt=R(x,a1:t) | ∑Tt=1y t-1rt |
| Step | Segmenty(k)(e.g.,句子) | rk=R(x,y(1:k)) | ∑K=1y k-1rk |
| 转向(Agent) | 每回合Agent响应y(u) | ru=R(x,y(1:u),z(1:u)) | ∑U=1y u-1ru |
优化稳定性,但它也如果信号设计不佳,则存在错定和奖励攻击的风险哈德菲尔德- 门内尔等人,2017。至于大型语言模型的推理,密集奖励通常是基于过程的信号,它们监督中间步骤而不是仅监督结果,并且已被发现是有效的,通常优于基于结果的奖励莱特曼等人,2024年,上田等人,2022。根据 §2.1\S 2.1§2.1 中的定义,我们进一步在大型语言模型强化学习的上下文中形式化稀疏/结果和密集奖励,根据动作和奖励粒度,如表2所示。
Token- Level Rewards. DPO Rafailov et al., 2023及其后续工作Rafailov et al., 2024表明,token- level奖励可以作为策略与参考模型之间的对数似然比来计算。隐式PRM Yuan et al., 2025d进一步表明,token- level奖励可以通过训练ORM并使用Rafailov等人的参数化方法获得。PRIME Cui et al., 2025a将ORM学习集成到RL训练中,并使用隐式token- level奖励来训练策略。SRPO Fei et al., 2025a移除了PRIME中的ORM,并改进了优势估计。另一条研究线关注使用内部反馈作为token- level奖励,例如token熵 Cheng et al., 2025a, Tan和Pan, 2025以及策略性词组 Wang et al., 2025g。
步骤式奖励。步骤式奖励方法分为两类:基于模型和基于采样。早期研究依赖于人类专家标注步骤式密集奖励Lightman等人,2024年,Uesato等人,2022,,这既昂贵又难以扩展。
基于模型的方法:为了降低标注成本,Math- Shepherd Wang等人,2024b使用蒙特卡洛估计来获取步骤级标签,并证明了使用训练好的PRMs进行过程验证在RL中是有效的。PAV[Setlur等人,2024]通过优势建模进一步改进了过程奖励。为了缓解基于模型的步骤级奖励的奖励攻击,PURECheng等人,2025b采用最小形式信用分配而不是求和形式,而Tango[Zha等人,2025]和AIRLSin等人,2025c联合训练策略和PRMs。利用生成式PRMs[Zhao等人,2025b](在 §3.1.2\S 3.1.2§3.1.2 中讨论)的强大验证能力,ReasonFlux- PRMZou等人,2025,TP- GRPOHe等人,2025f,和CAPOXie等人,2025b利用它们为RL训练提供步骤级奖励。然而,基于模型的密集奖励容易受到奖励攻击,并且在线训练PRMs成本很高。
·基于采样的:另一条研究线使用蒙特卡洛采样进行在线过程奖励估计Guo等人,2025c,Hou等人,2025,Kazemnejad等人,2025,Li等人,2025r,Yang等人,2025g,Zheng等人,2025c。VinePPO Kazemnejad等人,2025通过蒙特卡洛估计改进PPO。为了改进步骤分割,SPOGuo等人,2025c,TreeRLHou等人,2025,和FR3EZheng等人,2025c使用低概率或高标记作为分割点。为了提高样本效率和优势估计,SPOGuo等人,2025c,TreeRPO[Yang等人,2025g],TreeRLHou等人,2025和TreePOLi等人,2025r探索基于树的结构的细粒度过程奖励计算。MRTQu等人,2025b,S- GRPO Dai等人,2025a,VSRMYue等人,2025a,和SSPOXu等人,2025f强制
LLM 在中间位置终止思考过程以高效估计步骤级奖励。PROF Ye 等人,2025a 利用结果奖励与过程奖励之间的一致性来过滤用于RL训练的噪声数据。
回合级奖励。回合级奖励评估每个完整的智能体- 环境交互,例如工具调用及其结果,在多回合任务中提供粒度为单个回合的反馈。关于回合级奖励的研究可以大致分为两条主线:直接的回合级监督和从结果级奖励中推导回合级信号。
-
对于直接的回合级监督,研究工作在每个回合提供明确的反馈。例如,Emotion-sensitive dialogue policy learning Zhu et al., 2024 利用用户情绪作为回合级奖励来指导策略优化,展示了回合级反馈如何提升对话代理的交互质量。类似地,ToolRL Qian et al., 2025 设计了在每次工具调用步骤上提供的格式和正确性结构化奖励,为学习提供密集的回合级信号。Zeng et al. 2025d 进一步利用可验证信号和明确的回合级优势估计来改进强化学习中的多回合工具使用。此外,SWEET-RL Zhou et al., 2025g 学习一个步/回合级评价器,提供回合级奖励和归因,从而提供明确的回合级监督。最近,MUA-RL Zhao et al., 2025d 将模拟用户交互纳入强化学习循环,其中每个多回合交互产生回合级反馈,允许代理在真实用户-代理动态下迭代优化其策略。G-RA Sun et al., 2025g 通过引入门控奖励聚合扩展了这项工作,其中只有在满足更高优先级的结果级条件时,密集的回合级奖励(例如,动作格式、工具调用有效性、工具选择)才会被累积。
-
为了从结果级别的奖励中推导出回合级别的信息,其思路是将基于结果的监督分解或重新分配到更细粒度的单元中。对齐DialogueAgents与全局反馈 Lee等人,2025a 将会话级别的分数转换为回合级别的伪奖励,而GELI Lee等人,2024a利用韵律和面部表情等多模态线索来将会话级别的反馈细化到局部的回合级别信号。类似地,SPA-RL Wang等人,2025e通过进度归因将基于结果的奖励重新分配为每步或每回合的贡献。ARPO Dong等人,2025b沿此思路,将轨迹级别的结果(例如,工具使用后)的步/回合级别优势进行归因,有效地将全局回报转换为局部信号。
总体而言,回合级别的奖励,无论是直接分配在每个交互中还是从结果分解中推导,都作为过程和结果监督之间的桥梁,并在多回合代理RL中稳定和改进优化方面发挥核心作用,更多细节见 § 6.2。
3.1.4. 无监督奖励
要点
-
无监督奖励消除了人工标注瓶颈,使得奖励信号生成能够达到计算和数据的规模,而非人力。
-
主要方法包括从模型自身的流程中提取信号(模型特定:一致性、内部置信度、自生成知识)或从自动化外部来源提取信号(模型无关:启发式方法、数据语料库)。
前沿语言模型在多种任务上表现出色,包括许多极具挑战性的任务 Glazer等人,2024年,Jimenez等人,2023年,Li等人,2024b年,Phan等人,2025。然而,
在推进这些模型时存在一个关键限制,即对人类生成的奖励信号在强化学习(§ 3.1.1- 3.1.3)中的依赖。对于需要超人类专业知识的任务,人类反馈通常缓慢、昂贵且不切实际 Burns 等人,2023。为了解决这个问题,一种有前景的方法是无监督强化学习,它使用自动生成的、可验证的奖励信号,而不是真实标签。这种方法是实现可扩展的强化学习的关键,适用于大型语言模型。本节概述了这些无监督奖励机制,根据其来源将它们分为两类:源自模型本身的(模型特定)和来自外部、非人类来源的(模型无关)。
模型特定奖励。这种范式将大型语言模型的内部知识作为唯一的监督来源。它基于这样一种假设,即高性能模型将生成一致、自信或评估上合理的输出。这种方法具有高度的可扩展性,只需要模型和计算资源即可生成几乎无限量的"标记"数据。然而,其闭环特性存在奖励攻击和模型崩溃的风险。
-
基于输出一致性的奖励:这种方法认为正确答案将在多个生成的输出中形成一个密集、一致的山簇。基础性工作如 EMPO Zhang 等人,2025i 以及测试时强化学习(TTRL)Zuo 等人,2025b 通过聚类和多数投票分别实现了这一点。后续方法旨在通过提高效率(ETTRL Liu 等人,2025c)、结合推理轨迹(CoVoZhang 等人,2025h)或使用对比一致性来对抗奖励攻击(Co-RewardZhang 等人,2025w)来改进这一点。
-
来自内部置信度的奖励:一种替代方法是直接从模型的内部状态中获取奖励,使用置信度作为正确性的代理。信号可以基于交叉注意力(CAGSR Kiruluta 等人,2025i)、负熵(EM-RL Agarwal 等人,2025b,RENT Prabhudesai 等人,2025)或生成概率(Intuitor Zhao 等人,2025e,RLSCLi 等人,2025h,RLSF van Niekerk 等人,2025)。这些方法的成功通常取决于基础模型的初始质量 Gandhi 等人,2025,并且可能很脆弱 Press 等人,2024,Shumailov 等人,2023,因为它们依赖于先验,例如正确和错误路径之间的低密度分离 Chapelle 和 Zien,2005,Lee 等人,2013。
-
从自我生成的知识中获得的奖励:这种范式使用模型的知识来创建学习信号,要么作为裁判(自我奖励)要么作为问题提出者(自我指令)。在自我奖励中,模型评估自己的输出以生成奖励,这一概念由 Yuan 等人 2024 和 Wu 等人 2024 提出,并在 SSR-ZeroYang 等人,2025f 和 MINIMO Poesia 等人,2024 等作品中应用。在自我指令中,一个提出者模型为求解器生成课程。提出者通常因其创建的任务难度最优 Chen 等人,2025i,Huang 等人,2025a,Zhao 等人,2025a,而获得奖励,而求解器的奖励可以是模型无关的(例如,来自 AZR Zhao 等人,2025a 中的代码执行器)或模型特定的(例如,通过 SQLM Chen 等人,2025i 和 SeRL Fang 等人,2025a 中的多数投票)。
模型无关的奖励。与模型特定方法不同,这种范式从外部、自动化的来源中获取奖励。这种方法将学习过程建立在外部信息之上,消除了对人工标签的需求。其核心原则是这些外部信号是易于获取的,并且不需要人工操作。然而,由于精确的反馈往往不可用,代理奖励的质量至关重要,奖励攻击的风险仍然存在。
- 启发式奖励:这种方法构成了另一种基于规则的奖励形式,采用基于输出属性(如长度或格式)的简单预定义规则作为质量的代理。它代表了 § 3.1.1 中讨论的特定案例。这是由 DeepSeek-R1 [郭等人开创的,
2025a] 并随后通过动态奖励缩放等技术 余等人,2025d进行了改进。虽然可扩展,但这些启发式方法可能被模型操纵,导致表面上的改进而没有提升真实能力 刘等人,2025t,辛等人,2025。
- 数据驱动型奖励:这种方法从大型未标记语料库的结构中推导奖励信号。类似于大规模预训练的下一词预测,RPT Dong 等人,2025c 将下一词预测重新定义为强化学习任务,将网络规模数据集转化为数百万个训练样本。在元层面上,SEAL Zweiger 等人,2025 允许模型生成自己的训练数据和超参数,使用下游性能作为奖励。
总之,无监督奖励设计对于为大型语言模型创建可扩展的强化学习系统至关重要。模型特定范式通过利用模型的内部知识来促进自我改进,而模型无关范式将学习建立在外部自动反馈之上。虽然这两种方法都有效地绕过了人工标注瓶颈,但它们仍然容易受到奖励攻击 Zhang 等人,2025q。可扩展强化学习的未来可能涉及结合这些方法的混合系统,例如,使用数据驱动型奖励进行预训练,模型特定自奖励进行复杂推理的微调,以及最小化人工监督以确保安全和一致性。
3.1.5. 奖励塑形
要点
- 奖励塑形将稀疏信号转化为稳定、有信息的梯度,用于LLM训练。- 将验证器与奖励模型结合,使用组基线加上Pass@RX对齐的目标来稳定训练、扩展探索,并在规模上匹配评估指标。
如前所述,强化学习中代理的主要学习目标是最大化累积奖励,因此奖励函数的设计尤为重要 Sutton 等人,1998。在之前的章节中,我们介绍了各种奖励函数,例如可验证奖励(§ 3.1.1)、生成式奖励(§ 3.1.2)、密集奖励(§ 3.1.3)甚至无监督奖励(§ 3.1.4)。除了奖励工程之外,同样重要的是考虑如何修改或增强奖励函数,以鼓励那些推动进步朝着期望解决方案前进的行为。这个过程,称为奖励塑形 Goyal 等人,2019年,Gupta 等人,2022年,Hu 等人,2020年,Xie 等人,2023,可以分为基于规则和基于结构的奖励塑形。
基于规则的奖励塑形。在基于LLM的强化学习中,奖励塑形最简单且最常用的方法涉及结合基于规则的验证器和奖励模型的奖励来生成整体奖励信号,如在Qwen2.5 Math Yang 等人,2024a 中所示。通常,使用一个常数系数来平衡奖励模型和基于规则组件的贡献。这种方法不是将相同的奖励分配给所有正确的响应,而是允许根据奖励模型中的分数对响应进行进一步排序。这种方法对于更具挑战性的样本特别有用,并有助于避免所有奖励值都为0或1的情况,否则会导致无效的学习梯度 Yu 等人,2025d。这种启发式组合策略在开放域任务中广泛使用,其中结合基于规则的奖励和奖励模型 Guo 等人,2025b,Liao 等人,2025a,Liu 等人,2025x 为LLM的强化学习提供了更信息和有效的奖励信号 Su 等人,2025c,Zeng 等人,2025c,Zhang 等人,2024a。另一种方法涉及结合基于规则的奖励,如结果级奖励和格式奖励,如在DeepSeek- R1 Guo 等人,2025a,中实现,这使LLM能够学习长链式思维推理。这些奖励包括基于格式 Xin 等人,2025,
基于长度的组件 Liu等人,2025p来解决LLM输出中的各种异常。与使用固定的奖励权重团队,2025d,Yao等人,2025b或用于奖励插值的启发式规则Aggarwal和Welleck,2025,Zhang和Zuo,2025,Luet al.2025f提出动态奖励加权,采用超体积引导的权重适应和基于梯度的权重优化。这种方法在多目标对齐任务Li等人,2025a,Liu和Vicente,2024上实现了优异的性能。最近的工作还探索了多角色强化学习训练,并为不同角色分配不同的奖励函数,例如求解器和评论家Li等人,2025i。通常,这些奖励是使用手动设置的常数组合的。最近的工作还探索了多角色强化学习训练Li等人,2025i,j,为不同角色分配不同的奖励函数,以鼓励不同的行为和目标Li等人,2025i,例如求解器和评论家。
基于结构的奖励塑形。与依赖单个样本的基于规则的奖励塑形不同,基于结构的奖励塑形通过利用列表级或集合级的基线,在候选组中计算奖励。一种有影响力的方法是GRPOShao等人,2024,该方法是使用对同一问题G的响应的组均值作为基线(或变体,如留一法Ahmadian等人,2024或排序)并相应地为PPO风格的更新Schulman等人,2017b构建优势。最近的研究进一步修改了优化目标或信用分配策略,以促进更强的探索并实现与评估指标更紧密的对齐,例如Pass@K\[Yue等人,2025b。例如,Walder和Karkhanis2025对最终奖励进行联合变换,使优化直接等效于Pass@K等集合级目标,并提供低方差、无偏的梯度估计。Chen等人.2025x在推导和分析优势以及高效近似时直接针对Pass@K,将集合级目标分解回单个样本信用分配。这种方向的奖励塑形方法旨在稳定训练并鼓励策略进行更广泛的探索,从而降低过早收敛到次优局部解的风险。
3.2.策略优化
3.2. 策略优化在本小节中,我们首先提供策略梯度目标的数学公式概述(§3.2.1)。接下来,根据梯度计算过程中奖励的生成方式,我们将强化学习中的在线策略优化算法分为两类:基于评价者(§3.2.2)和无评价者(§3.2.3)。此外,我们讨论了将在线强化学习与离线数据集结合进行更复杂的后训练(即离线策略)优化的最新研究(§3.2.4),以及各种正则化技术,如熵和KL(§3.2.5)。
3.2.1.策略梯度目标
如§2.1所述,在强化学习中,大型语言模型的上下文被视为环境,下一级预测的概率分布被视为策略。对于强化学习系统,系统的目标是找到一个最优策略,使得系统生成的预期累积奖励最大化。由于大型语言模型参数数量庞大,大型语言模型的强化学习策略优化算法大多是基于一阶梯度的算法。通常,强化学习算法寻求优化网络参数,以使预期奖励最大化。下面,我们介绍强化学习算法对大型语言模型梯度计算的一般公式。
符号表示。尽管我们在§2.1中介绍了相关符号,但为了比较的清晰性,我们在这里重新回顾这些定义。设 x∼Dx \sim \mathbb{D}x∼D 为一个提示(初始状态 s1=ss_1 = ss1=s )。一个随机策略 πθ\pi_{\theta}πθ 生成一个序列 y=(a1,...,aT)y = (a_1, \dots , a_T)y=(a1,...,aT) ,我们用 yyy 表示 ∣y∣|y|∣y∣ 的总序列长度,状态由 st+1=(x,s≤t)s_{t + 1} = (x, s_{\leq t})st+1=(x,s≤t) 定义。我们假设一个主要基于序列级别的奖励 R(x,y)R(x, y)R(x,y) ,可选地分解为基于token级别的奖励 rt∘r_{t^\circ}rt∘ 。我们使用行为策略 G≥1G \geq 1G≥1 每个提示收集响应。
策略 πb\pi_{b}πb (也用 π0 d d\pi_{0} \mathrm{~d} \mathrm{~d}π0 d d 表示,指当前策略的早期版本)。可选地,一个参考策略 πref\pi_{\mathrm{ref}}πref (例如基础模型、微调或指令模型)可用于正则化。
我们重新审视了 §2.1\S 2.1§2.1 中定义的马尔可夫决策过程(MDP)。在MDP中,我们将给定当前状态 sss 的预期累积奖励表示为 V\mathrm{V}V (价值)函数
V(s)=Eat∼πθ(st),st+1∼P(s,a)∑t=0Tγtr(st,at)∣s0=s,(2) V(s) = \mathbb{E}{a_t\sim \pi\theta (s_t),s_{t + 1}\sim \mathcal{P}(s,a)}\\sum_{t = 0}\^{T}\\gamma\^t r(s_t,a_t)\|s_0 = s, \tag{2} V(s)=Eat∼πθ(st),st+1∼P(s,a)t=0∑Tγtr(st,at)∣s0=s,(2)
并且当前状态- 动作对的预期累积奖励表示为Q(质量)函数
Q(s,a)=Eat∼πθ(st),st+1∼P(s,a)∑t=0Tγtr(st,at)∣s0=s,a0=a.(3) Q(s,a) = \mathbb{E}{a_t\sim \pi\theta (s_t),s_{t + 1}\sim \mathcal{P}(s,a)}\\sum_{t = 0}\^{T}\\gamma\^t r(s_t,a_t)\|s_0 = s,a_0 = a. \tag{3} Q(s,a)=Eat∼πθ(st),st+1∼P(s,a)t=0∑Tγtr(st,at)∣s0=s,a0=a.(3)
然后强化学习(RL)的目标可以表述为预期累积奖励的最大化问题。为了优化目标函数,通常采用策略梯度算法Sutton et al., 1999, Williams, 1992进行梯度估计:
∇θI(θ)=Ex∼D,y∼πθ∑t=1T∇θπθ(yt∣y\
策略梯度可以通过以下直觉进行解释:遵循策略梯度的算法应该最大化优于平均水平的动作的概率,并最小化劣于平均水平的动作的概率。这一概念导致了 AAA (优势)函数 A(s,a)=Q(s,a)−V(s)A(s, a) = Q(s, a) - V(s)A(s,a)=Q(s,a)−V(s) 的引入。优势衡量当前动作相对于现有策略对预期总奖励的提升程度。优势可以通过多种方式估计。如果我们只有完整轨迹的奖励,那么 vanilla REINFORCE 算法 Williams, 1992 直接定义 At=R(x,y)A_t = R(x, y)At=R(x,y) 。
对于训练LLMs的情况,普通的策略梯度算法经常存在稳定性问题。相反,训练通常使用PPO算法 Schulman等人,2017b。对于一个具有 NNN 样本的算法,我们定义一个具有PPO风格更新的通用目标如下:
I(θ)=Edata1Z∑i=1N∑t=1Timin(wi,t(θ)A\^i,t,clip(wi,t(θ),1−ϵlow,1+ϵhigh)A\^i,t),(5) \mathcal{I}(\theta) = \mathbb{E}_{\mathrm{data}}\left\\frac{1}{Z}\\sum_{i = 1}\^{N}\\sum_{t = 1}\^{T_i}\\min \\left(w_{i,t}(\\theta)\\hat{A}_{i,t},\\mathrm{clip}(w_{i,t}(\\theta),1 - \\epsilon_{\\mathrm{low}},1 + \\epsilon_{\\mathrm{high}})\\hat{A}_{i,t}\\right)\\right, \tag{5} I(θ)=EdataZ1i=1∑Nt=1∑Timin(wi,t(θ)A\^i,t,clip(wi,t(θ),1−ϵlow,1+ϵhigh)A\^i,t),(5)
其中:
- ωit(θ)\omega_{i_t}(\theta)ωit(θ) ,是重要性比率;- A^it\hat{A}_{i_t}A^it ,是优势(无论是token级别还是序列级别);- TiT_iTi 是每个样本的token数或响应数;- NNN 是在给定提示下的样本总数;- zzz 是归一化因子(例如,总token数、分组大小等)。
PPO算法 Schulman et al., 2017b 最初被提出作为TRPO算法 Schulman et al., 2015a的一种计算效率更高的近似方法。当纯策略梯度方法在数据效率和鲁棒性方面表现不佳时,PPO表现优异。此外,PPO被证明比TRPO实现起来更简单、更通用,并且具有更好的样本复杂度。
然而,由于LLM的复杂和长CoT特性,精确的目标函数、梯度估计和更新技术可以像表3中所示的那样呈现多种形式。
表3|推理模型训练中代表性强化学习算法的比较
|---------|----------|-----------------------------|-------------|----------------|
| Date | 算法 | 优势估计 | 重要性采样 | 损失聚合 |
| 2017.01 | PPO | Critic-GAE | PPO-Style | Token-Level |
| 2023.10 | ReMax | Greedy Baseline | N/A | Token-Level |
| 2024.02 | RLOO | Leave-One-Out | N/A | Token-Level |
| 2025.01 | RF++ | Negative KL +Batch Relative | PPO-Style | Sequence-level |
| 2024.02 | GRPO | Group Relative | PPO-Style | 序列级 |
| 2025.01 | PRIME | 结果 + 隐式 PRM | PPO-Style | Token级 |
| 2025.03 | VAPO | 调整后的 GAE | Clip-Higher | Token-Level |
| 2025.03 | Dr. GRPO | Group Baseline | PPO-Style | Token-Level |
| 2025.04 | DAPO | Group Relative | Clip-Higher | Token-Level |
| 2025.05 | Clip-Cov | Group Relative | PPO-Style | 序列级 |
| 2025.05 | KL-Cov | 组相对 | PPO-Style | 序列级 |
| 2025.06 | CISPO | 组相对 | 剪裁IS权重 | Token级 |
| 2025.07 | GSPO | 组相对 | PPO风格 | 序列级 |
| 2025.08 | GMPO | 组相对 | 裁剪更宽 | 几何平均 |
| 2025.08 | GFPO | 过滤 + 组相对 | PPO-风格 | Token-level |
| 2025.08 | LitePPO | 组级别均值,批级别标准差 | PPO-风格 | Token-level |
| 2025.08 | FlashRL | 组相对 | 截断IS | Token级 |
| 2025.09 | GEPO | 组级均值 | 组期望 | PPO风格 |
| 2025.09 | SPO | 整个批次级别 | PPO-Style | 序列级别 |
3.2.2.基于评价者的算法
要点
·评价模型在标记数据的子集上训练,并为未标记的滚动数据提供可扩展的token级价值信号。
·评价者需要与LLM一起运行和更新,导致显著的计算开销,并且对于复杂任务扩展性不佳。
早期关于LLM在RL领域的作品主要关注如何有效地将LLM策略与外部监督对齐,以使LLM具备更好的指令跟随能力,同时确保模型是有益的、诚实的和无害的。LLM对齐最常见的方法是RLHF Bai et al., 2022a, Christiano et al., 2017, Ouyang et al., 2022, Stiennon et al., 2020。这种技术将人类作为学习算法的评论员;具体步骤如下。首先,LLM生成一组模型输出并由人类进行标注,以创建一个数据集。然后使用该数据集来训练一个奖励模型,以预测人类更倾向于哪种响应。最后,使用奖励模型与一个值函数一起训练LLM,该值函数作为系统中的评论员。训练通常使用PPO算法 Schulman et al., 2017b进行。PPO算法将目标公式化为以下形式:
IPPO(θ)=Ex∼D,x∼πθold(⋅∣x)1∣y∣∑t=1∣y∣min(ωt(θ)A\^t,clip(ωt(θ),1−ϵ,1+ϵ)A\^t),(6) \mathcal{I}{\mathrm{PPO}}(\theta) = \mathbb{E}{x\sim \mathcal{D},x\sim \pi_{\theta_{old}}(\cdot |x)}\left\\frac{1}{\|y\|}\\sum_{t = 1}\^{\|y\|}\\min \\left(\\omega_t(\\theta)\\hat{A}_t,\\mathrm{clip}(\\omega_t(\\theta),1 - \\epsilon ,1 + \\epsilon)\\hat{A}_t\\right)\\right, \tag{6} IPPO(θ)=Ex∼D,x∼πθold(⋅∣x) ∣y∣1t=1∑∣y∣min(ωt(θ)A^t,clip(ωt(θ),1−ϵ,1+ϵ)A^t) ,(6)
Ω^t\hat{\mathbf{\Omega}}_tΩ^t 是一个基于值模型的收益,
wt(θ)=πθ(yt∣x,y<t)πθold(yt∣x,y<t).(7) w_{t}(\theta) = \frac{\pi_{\theta}(y_{t}|x,y_{< t})}{\pi_{\theta_{old}}(y_{t}|x,y_{< t})}. \tag{7} wt(θ)=πθold(yt∣x,y<t)πθ(yt∣x,y<t).(7)
我们注意到PPO被提出作为TRPO的一个裁剪代理目标,它保留了TRPO的保守策略迭代,同时无约束且计算复杂度接近传统策略梯度方法。由于当前策略与采样分布之间的差异,TRPO中的收益被 wtw_{t}wt 乘以,即方程6中的重要性采样因子。PPO最大化与TRPO相同的目標,但移除了信任区域约束。此外,PPO增加了一个裁剪机制和KL正则化因子,以确保当前策略不会与rollout策略 pioldpi_{old}piold 偏差过大。
在基于评价者的方法中,强化学习的可扩展性是通过引入一个评价者模型实现的。在奖励模型在手动标记的小规模生成数据子集上充分训练后,它可以被用来构建评价者模型,为强化学习的大多数未标记生成数据生成更大规模的token级价值信号。然而,这些工作需要评价者模型沿着目标LLM运行和优化,并产生显著的计算开销。
在PPO中,评价者模型从强化学习文献中适应了广义优势估计器(GAE)Schulman et al., 2015b。GAE通常使用时序差分误差构建
δt=rt+γV(yt+1)−V(yt),(8) \delta_{t} = r_{t} + \gamma V(y_{t + 1}) - V(y_{t}), \tag{8} δt=rt+γV(yt+1)−V(yt),(8)
然后随时间步长累积:
A^GAE,t=∑l=tT(γλ)lδt+l,(9) \hat{A}{GAE,t} = \sum{l = t}^{T}(\gamma \lambda)^{l}\delta_{t + l}, \tag{9} A^GAE,t=l=t∑T(γλ)lδt+l,(9)
其中 γ\gammaγ 是MDP的折扣因子, λ\lambdaλ 是一个控制偏差- 方差权衡的参数。
最近的工作认为,衰减因子对于需要长CoT的复杂推理任务扩展不利,并提出了一种价值校准PPO Yuan et al., 2025f 和VAPO Yue et al., 2025c, VRPO Zhu et al., 2025a 提出了新的机制来增强评价者模型在噪声奖励信号下的鲁棒性。
此外,基于评论的算法 Hu 等人,2025b 也已展示了在基于规则的奖励的蒙特卡洛估计中的稳定可扩展性。类似的方法已被通过 PRMs 的实现适配了固定外部模型 Lu 等人,2024,Wang 等人,2024b。
引入评论模型的另一种方法是使用隐式 PRM Yuan 等人,2025d。这种方法也能够为可扩展的RL训练提供 token 级别的监督。与 GAE 方法不同,像 ImplicitPRM Yuan 等人,2025d 和 PRIME Cui 等人,2025a 这样的方法适配了特定的奖励模型公式来直接生成 token 级别的奖励。
3.2.3. 无评论算法
要点
-
无评论算法仅需序列级别的奖励进行训练,这使得它们更加充分和可扩展。
-
对于 RLVR 任务,基于规则的训练信号可靠地防止了评论相关的问题,如奖励黑客。
除了提供用于模型训练的基于评论的模型(这些模型提供 token 级别的反馈信号)之外,许多近期的研究工作已经表明,响应级别的奖励足以用于可扩展的推理任务与强化学习。这些无评论算法将相同的基于规则或模型生成的响应级别奖励应用于响应中的所有 token,并在各种任务中展示了其有效性。
与基于评论的算法相比,无评论方法不需要单独的评论模型,显著降低了计算需求并简化了训练。此外,在基于规则的环境中训练大型语言模型(在这种环境中,任何响应的奖励可以被明确定义),无评论算法可以避免由于训练不当的评论模型而可能出现的奖励攻击问题。这种特性使得在类似设置中,无评论算法比基于评论的方法更具可扩展性。
经典的REINFORCEWilliams,1992算法是首批为RL开发的算法之一。它在[Ahmadianetal.,2024]中被应用于LLM问题。REINFORCE的精确公式如下,
IREINFORCE(θ)=Ex∼D,{y}∼πold(⋅∣x)R(x,y)∇θlog(πθ(⋅∣y∣x)),(10) \mathcal{I}{\mathrm{REINFORCE}}(\theta) = \mathbb{E}{x\sim \mathcal{D},\{y\} \sim \pi_{old}(\cdot |x)}\leftR(x,y)\\nabla_{\\theta}\\log (\\pi_{\\theta}(\\cdot \|y\|x))\\right, \tag{10} IREINFORCE(θ)=Ex∼D,{y}∼πold(⋅∣x)R(x,y)∇θlog(πθ(⋅∣y∣x)),(10)
其中 R(x,y)R(x,y)R(x,y) 通常以 ±1\pm 1±1 的形式用于RLVR任务。这种朴素公式将整个序列视为单个动作,并将响应任务视为老虎机。然而,原味算法通常由于高方差而遭受严重的不稳定问题。ReMax Li etal.,2023c为REINFORCE引入了一种方差减少机制,并使用贪婪基线估计。Ahmadian etal.2024还引入了RLOO,它进一步提供了一个无偏基线,并获得了更稳定的结果。REINFORCE ++++++ Hu,2025从PPO和GRPO风格算法中借鉴了剪裁和全局优势归一化等技术,以提供更精确的优势和梯度估计。
RL中一种最受欢迎的无评价器方法是GRPOShao等人,2024。GRPO的目标公式如下,
IGRPO(θ)=Ex∼D,{yi}i=1G∼πθold(⋅∣x)1G∑i=1G1∣yi∣∑t=1∣yi∣min(wi,t(θ)A\^i,t,clip(wi,t(θ),1−ϵ,1+ϵ)A\^i,t),(11) \mathcal{I}{\mathrm{GRPO}}(\theta) = \mathbb{E}{x\sim \mathcal{D},\{y_i\}{i = 1}^G\sim \pi{\theta_{old}}(\cdot |x)}\left\\frac{1}{G}\\sum_{i = 1}\^G\\frac{1}{\|y_i\|}\\sum_{t = 1}\^{\|y_i\|}\\min \\left(w_{i,t}(\\theta)\\hat{A}_{i,t},\\mathrm{clip}(w_{i,t}(\\theta),1 - \\epsilon ,1 + \\epsilon)\\hat{A}_{i,t}\\right)\\right, \tag{11} IGRPO(θ)=Ex∼D,{yi}i=1G∼πθold(⋅∣x) G1i=1∑G∣yi∣1t=1∑∣yi∣min(wi,t(θ)A^i,t,clip(wi,t(θ),1−ϵ,1+ϵ)A^i,t) ,(11)
wi,t(θ)=πθ(yi,t∣x,yi,<t)πθold(yi,t∣x,yi,<t),A^i,t=A^i=R(x,yi)−mean({R(x,yi)}i=1G)std({R(x,yi)}i=1G),(12) w_{i,t}(\theta) = \frac{\pi_{\theta}(y_{i,t}|x,y_{i,< t})}{\pi_{\theta_{old}}(y_{i,t}|x,y_{i,< t})},\quad \hat{A}{i,t} = \hat{A}i = \frac{R(x,y_i) - \mathrm{mean}(\{R(x,y_i)\}{i = 1}^G)}{\mathrm{std}(\{R(x,y_i)\}{i = 1}^G)}, \tag{12} wi,t(θ)=πθold(yi,t∣x,yi,<t)πθ(yi,t∣x,yi,<t),A^i,t=A^i=std({R(x,yi)}i=1G)R(x,yi)−mean({R(x,yi)}i=1G),(12)
其中 yiy_{i}yi 中的所有标记都与 A^i\hat{A}_{i}A^i 共享相同的优势。
GRPO是PPO的无评价器修改,其中不是由评价器提供的GAE,而是整个序列使用相同的优势估计,该估计通过相对组归一化计算,比基于二元的规则奖励更好的估计。与PPO和REINFORCE风格的相比,GRPO的基于组的优势计算有效地减少了训练信号的方差,并已被证明可以加快训练过程。其他最近的方法,包括DAPOYu等人,2025d,CISPOChen等人,2025a,Dr.GRPO Liu等人,2025u,LitePPO Liu等人,2025w,对GRPO进行了进一步修改,通过仔细调整采样策略、裁剪阈值和损失归一化来进一步增强RL训练过程的稳定性。另一种最近的方法,GSPOZheng等人,2025a,用序列级的裁剪替换了标记级的裁剪重要性采样率。
除了REINFORCE和GRPO相关的算法之外,还有其他无评价器的方法。VinePPO通过用蒙特卡洛优势估计替换学习到的评价器来修改PPO。CPGD Liu 等人,2025z提出了一种新的策略梯度目标,以及一种漂移正则化机制。K1.5团队,2025d利用带有镜像下降适应的强化学习,在基础模型训练中成功增强了LLMs的长上下文推理能力。Lv等人2025最近引入了一种统一的策略梯度估计器,带有混合后训练算法,为LLMs中的强化学习的策略梯度估计提供了一个统一的框架。SPOXu和Ding,2025介绍了一种无组、单流策略优化,用持久的KL自适应值跟踪器和全局优势归一化替换了每组的基线,在GRPO之上实现了更平滑的收敛和更高的精度,同时在长时程和
工具集成设置。HeteroRL Zhang 等人,2025c 将 rollout 抽样与参数学习解耦,用于去中心化异步训练,并通过 GEPO 减少了延迟引起的 KL 漂移(理论上指数级)下的重要性权重方差,即使在严重延迟下(例如, <3%< 3\%<3% 的退化在 1,800 秒时)也能保持稳定性。
策略优化的重要性采样。由于强化学习的 rollout- 奖励- 训练循环,通常难以确保 rollout 数据严格遵循当前模型的策略分布。因此,引入了重要性采样以减少训练中的偏差。RL 中首次引入重要性采样是在 TRPO 中,其中引入了一个基于 token 的重要性比率 wi,tw_{i,t}wi,t 到目标函数中。这种方法被近期的许多工作广泛采用,例如 GRPO。这种方法仅限于基于 token 的重要性比率,因为实际分布比率无法在 CoT 的长上下文中有效计算。然而,基于 token 的重要性采样给 RL 算法引入了另一种偏差,因为给定策略的实际采样分布是相对于状态- 动作对定义的,而基于 token 的方法仅考虑当前动作。GMPO Zhao et al., 2025f 通过引入几何平均来缓解这一问题,以增加具有极端重要性采样比率的 token 的训练鲁棒性。在最近的工作 GSPO Zheng et al., 2025a,中,计算了一个基于序列的重要性采样因子。GSPO 为确保概率比率可计算添加了一个独特的归一化因子,但这种方法也是对实际重要性采样因子的有偏估计。一个有前景的新方向是超越标准 on- policy 策略梯度方法的理论框架,直接从监督学习理论推导出本质上 off- policy 的算法 Chen et al., 2025c。我们将在下一节详细介绍 off- policy 优化。
3.2.4. 离策略优化
要点
- 离策略强化学习通过将数据收集与策略学习解耦,提升了样本效率,能够从历史、异步或离线数据集进行训练。- 现代实践混合了离策略、离线和在线策略方法(例如,SFT+RL或大规模离线学习),以提升稳定性和性能。
在强化学习中,离策略方法处理学习中的策略(目标策略)与生成数据的策略(行为策略)不同的情况。这一核心区别允许智能体在不需在数据收集过程中遵循最优行动的情况下学习最优行动。这种灵活性是一个关键优势,通常导致比在线策略对应的算法更样本高效的算法,后者需要为每次更新直接从当前策略采样新数据。这些方法中的一个核心挑战是校正行为策略与目标策略之间的分布偏移,通常通过使用加权目标函数的重要性采样来解决:
Lpolicy(θ)=−Ex∼D,y∼πb(y∣x)πθ(y∣x)πb(y∣x)⋅r(x,y),(13) \mathcal{L}{\mathrm{policy}}(\theta) = -\mathbb{E}{x\sim \mathcal{D},y\sim \pi_b(y|x)}\left\\frac{\\pi_\\theta(y\|x)}{\\pi_b(y\|x)}\\cdot r(x,y)\\right, \tag{13} Lpolicy(θ)=−Ex∼D,y∼πb(y∣x)πb(y∣x)πθ(y∣x)⋅r(x,y),(13)
其中,分数 πθ(y∣x)\pi_{\theta}(y|x)πθ(y∣x) 作为目标策略 πθ\pi_{\theta}πθ 与行为策略 πb\pi_{b}πb 之间的重要性权重。
在实际的大规模模型训练中,离线学习通常以不同的形式表现出来。最近的研究工作大致可以分为三个方面:1) 训练- 推理精度差异,其中模型以高精度进行训练,但在低精度下部署,导致目标策略与行为策略之间存在差距;2) 异步经验重放机制,通过在学习过程中重用过去的轨迹来提高效率和稳定性;以及3) 更广泛的离线优化方法
,包括优化器级别的改进、数据级别的离线学习,以及结合监督微调和强化学习的混合方法。
训练- 推理精度差异。一个显著的离策略场景源于训练模型和推理模型之间参数精度的差异,它们采用不同的训练和推理框架 Yao 等人,2025a(例如,vLLM 与 FSDP),或模型量化以加速推理 Lin 等人,2016,这些是 LLM 推理中非确定性的表现 He 和 Lab,2025。通常的做法是使用高精度参数(例如,32 位浮点数)训练模型,然后部署一个使用低精度参数(例如,8 位整数)量化的版本 Liu 等人,2025i。这造成了差异,部署的低精度模型作为行为策略,生成真实世界的交互数据,而高精度模型仍然是训练过程中被更新的目标策略。虽然这种不匹配建立了离策略学习问题,但研究表明,由于量化导致的策略偏差通常很小。因此,这种差异可以通过简单的校正技术有效管理,例如截断重要性采样 (TIS) Ionides,2008,Yao 等人,2025a,允许在保留加速推理好处的同时进行稳定训练。
异步离策略训练。异步训练天然地与离策略RL相匹配,用于LLM。许多智能体并发生成轨迹,并将它们附加到一个共享的回放缓冲区中,而一个中央学习器从这个缓冲区中采样小批量来更新目标策略。基于这种观点,一些最近的方法故意重用过去的轨迹来提高效率和稳定性。一个例子是回顾性回放 Dou 等人,2025,它通过选择性地重放早期的推理轨迹来增强LLM推理的探索,以指导当前的策略更新。类似地,EFRameWang 等人,2025b 采用了一种探索- 过滤- 回放机制,将过滤后的响应与新的滚动交错,以鼓励更深入的推理。在代码生成的领域,可能性优先级和通过率优先级经验回放(PPER)Chen 等人,2024c 通过在缓冲区中优先考虑高价值代码样本,将这一思想进一步发展,从而实现更稳定的优化。将这些思想扩展到多模态交互,ARPO Lu 等人,2025b 将回放应用于GUI智能体,其中成功的轨迹被重用来在稀疏奖励下提供可靠的学习信号。最后,RLEP Zhang 等人,2025d 通过使用早期运行中经过验证的成功轨迹的经验缓冲区来锚定探索,这些轨迹与新的滚动混合,以平衡可靠性与发现。总而言之,这些方法说明了回放缓冲区如何成为现代异步离策略训练中基于LLM智能体的基石。
离策略优化。近期在微调LLMs方面的进展探索了超越传统策略RL的复杂优化策略。这些方法大致分为离策略和混合策略优化,旨在通过创造性地使用来自各种来源的数据来提高样本效率、训练稳定性和整体性能。我们在此介绍该主题:
·优化器级别的离策略方法:这些方法专注于改进优化过程本身,强调策略更新的稳定性和效率。例如,SPO Cohen 等人,2025 介绍了一种软策略优化方法,它实现了稳定的在线、离策略RL,而TOPR Roux 等人,2025 提出了一种用于提高稳定性和效率的锥形离策略 REINFORCE 算法。ReMax Liang 等人,2025a 进一步通过专注于高效利用离策略数据来最大化可用信息的效用,突出了这一点。
·数据级离策略方法:一类离策略算法完全从大规模外部离线数据中学习 Zhang 等人,2025g。例如,动态微调 (DFT) 框架 Wu 等人,2025i 将 SFT 损失推广到强化学习 (RL) 公式,并引入了停止梯度机制,能够在 SFT 的方式下在离线数据上进行训练,同时获得更好的性能。同样基于离线数据,直观微调 (IFT) Hua 等人,2024 添加
一个时间残差连接,该连接融合了SFT和RLHF目标,并显式地建模和优化当前标记对所有未来生成的影响。另一种相关的方法是直接偏好优化(DPO)Rafailov等人,2023,它直接从偏好数据中优化策略。这些方法共同代表了一种向更数据中心的强化学习方法的转变,能够从庞大且多样的离线数据源中开发复杂的策略。
- 混合策略方法:在更有效地重用过去数据的同时,混合策略优化代表了另一个重要趋势,它结合了SFT和RL的优势。这种混合方法利用SFT在专家数据上的稳定性,同时使用RL来优化特定的奖励函数,将监督数据以两种主要方式集成。一种策略是在损失级别,其中SFT和RL目标直接在损失函数 Lv et al., 2025, Xiao et al., 2025b, Zhang et al., 2025k, ?中结合。UFT Liu et al., 2025k, SRFT Fu et al., 2025c, LUFFY Yan et al., 2025a, RED Guan et al., 2025, 和 ReLIFT Ma et al., 2025a 等方法通过创建统一的或单阶段的训练过程,同时从专家演示和RL反馈中学习,体现了这一点。第二种策略在数据级别操作,使用专家数据来构建生成过程本身。在这里,高质量数据作为前缀或锚点来指导模型的探索 Guo et al., 2025d。例如,BREADZhang et al., 2025p从专家锚点生成分支的rollouts,而Prefix-RFT Huang et al., 2025g通过前缀采样混合训练机制。通过在损失或数据级别混合策略,这些方法防止了奖励攻击,并确保模型保留了SFT的知识,从而为复杂的推理提供了更健壮和强大的模型。
3.2.5. 正则化目标
要点
- 目标特定正则化有助于平衡探索与利用,提升强化学习效率和政策性能。- KL、熵和长度正则化的最优选择和形式仍是开放性问题,各自影响政策优化和可扩展性。
如前几节所述,确保稳定性并防止灾难性政策漂移至关重要。特别是对于长时程训练,KL正则化和熵正则化等技术被广泛采用。
KL正则化。KL散度正则化的作用在该领域是一个极具争议的话题。在大多数研究中,KL正则化应用于1).当前政策 πθ\pi_{\theta}πθ 和参考政策 πref\pi_{\mathrm{ref}}πref ,2).当前政策 πθ\pi_{\theta}πθ 和旧政策 πold\pi_{\mathrm{old}}πold 。我们在公式14中提供了一个统一公式。
LKL=β∑t=1∣y∣KL(πθ(⋅∣yt)∣∣πref/old(⋅∣yt)).(14) \mathcal{L}{KL} = \beta \sum{t = 1}^{|y|}KL(\pi_{\theta}(\cdot |y_t)||\pi_{ref / old}(\cdot |y_t)). \tag{14} LKL=βt=1∑∣y∣KL(πθ(⋅∣yt)∣∣πref/old(⋅∣yt)).(14)
- 对于前者,这是一种在RLHF中常用的技术 Ouyang等人,2022年,Touvron等人,2023。它最初被引入是为了防止模型被破坏性更新。先前的研究认为,结合KL惩罚对于保持稳定性并避免在数千个训练步骤中熵崩溃至关重要。为了降低KL项过度限制进度的风险,Liu等人 2025j使用这种方法,并结合周期性参考策略重置,其中参考模型被更新为训练策略的最新快照。为了同时保持知识和增强推理能力,Wang等人 2025i
对低熵值token应用更强的KL正则化,对高熵值token应用较弱的正则化。然而,在用于推理的大型语言模型的强化学习(RL)的背景下,这比标准的RLHF更具挑战性,因此需要重新考虑这种KL正则化的必要性。最近,许多研究表明,策略在训练期间应该自由探索,因此可能与初始化显著偏离,以发现新的CoT结构,这使得KL约束成为一种不必要的限制。因此,大多数其他近期工作主张完全移除RL惩罚An等人,2025年,Arora和Zanette,2025年,Chen等人,2025q,Cui等人,2025a,Fan等人,2025b,He等人,2025d,Liao等人,2025b,Liu等人,2025u,Yan等人,2025a,Yu等人,2025d以简化实现,降低内存成本并实现更具可扩展性的GRPO。
·对于后者,它可以作为策略损失裁剪形式的替代品Schulman et al.,2017b。张等人2025r讨论了前向KL、反向KL、归一化KL和归一化形式之间的差异。这种方法也已被崔等人2025b,吕等人2025,团队2025d,采用,展示了其在不同RL训练规模中的潜力。然而,其深层机制及其对可扩展RL的意义仍待探索。
熵正则化。在RL文献中,保留策略熵被广泛认为是对许多算法Eysenbach and Levine,2021,Williams,1992,Williams and Peng,1991的一个关键方面。为此,通过正则化技术积极控制策略熵Haarnoja et al.,2018,Schulman et al.,2017b,Ziebart et al.,2008。
Lent=−α∑t=1⌊ν⌋Hπθ(⋅∣yt)=α∑t=1∣y∣∑ν=1∣V∣πθ(ytν∣yt)logπθ(ytν∣yt).(15) \mathcal{L}{\mathrm{ent}} = -\alpha \sum{t = 1}^{\lfloor \nu \rfloor}H\\pi_{\\theta}(\\cdot \|y_t) = \alpha \sum_{t = 1}^{|y|}\sum_{\nu = 1}^{|V|}\pi_{\theta}(y_t^\nu |y_t)\log \pi_{\theta}(y_t^\nu |y_t). \tag{15} Lent=−αt=1∑⌊ν⌋Hπθ(⋅∣yt)=αt=1∑∣y∣ν=1∑∣V∣πθ(ytν∣yt)logπθ(ytν∣yt).(15)
然而,在用于大型语言模型的强化学习中,直接应用熵正则化既不常见也不有效Cui等人,2025b,He等人,2025d。在损失函数中使用显式的熵正则化项仍然是一个有争议的问题。虽然有些人认为它有益,使用标准系数Shrivastava等人,2025或目标损失函数Wu等人,2025e,其他人则反对它,认为它会导致不稳定性甚至训练崩溃,尤其是在稀疏奖励An等人,2025,Liao等人,2025b的情况下。许多研究表明,在没有干预的情况下会出现熵崩溃现象[Cheng等人,2025a,Cui等人,2025b,Yu等人,2025d],这阻碍了训练期间有效的策略探索。为了解决这个问题,He等人2025d动态调整熵损失的系数,Yu等人2025d采用剪切高技术将更多低概率标记纳入策略更新,Wang等人2025m直接在 20%20\%20% 的高熵标记上进行训练,Cheng等人2025a,Chen等人2025j强调通过将其纳入优势计算来强调熵。除了这些显式最大化熵的技术外,Cui等人2025b为熵动态的潜在机制提供了理论解释,将动作输出概率与其优势之间的协方差确定为熵"驱动器"。基于这一见解,Clip- Cov和KL- Cov被提出通过选择性地约束一小部分表现出异常高协方差的标记来调节熵。
长度惩罚。LRMs在复杂任务上的近期成功验证了长CoT推理的有效性。然而更长的推理轨迹会导致更高的推理成本。为了平衡推理预算和性能Agarwal等人,2025a,He等人,2025e,许多工作寻求在保留模型性能Aggarwal和Welleck,2025,Liu等人,2025p,Luo等人,2025a,Su等人,2025b,Xiang等人,2025的同时降低推理成本。例如,Aggarwal和Welleck2025通过确保遵守用户指定的长度约束来控制推理长度,而Yuan等人2025a和Luo等人2025a将相对长度正则化和一个保准确率的约束设计到优化目标中,Xiang等人2025和Liu等人2025p提出根据问题难度应用自适应长度惩罚来保留模型能力。
3.3.采样策略
3.3. 采样策略与静态数据集不同,强化学习依赖于主动策展的轨迹,其中关于采样什么和如何采样的决策直接影响学习效率、稳定性和获得的推理行为质量。有效的采样策略不仅确保多样化和信息丰富的训练信号,还使学习过程与预期的奖励结构和策略目标保持一致。在本小节中,我们调查了动态和结构化采样(§ 3.3.1)的最新进展,以及进一步优化采样和政策改进的超参数调整技术(§ 3.3.2)。
3.3.1.动态和结构化采样
要点
·高质量的、多样化的rollout稳定强化学习训练,并通过让智能体接触更广泛的、有意义的体验来提升整体性能。·在探索多样化轨迹和维护高采样效率之间取得平衡是强化学习中一个基本权衡。
Sampling已成为RL微调推理LLMs的一级杠杆,作为一种高效且自适应的机制,用于最大化数据利用率、减少浪费的计算,并提高训练效果或作为LLMs在结构化格式中采样的控制和指导。
动态采样。动态采样根据在线学习信号(如成功率、优势、不确定性或估计难度)自适应调整滚动用提示的选择和分配给每个的计算预算。主要目标是集中计算在信息量大的示例上,同时避免饱和或不生产性的示例。现有方法通常分为两类:
·面向效率的采样:一些工作使用在线过滤来集中训练中等难度的题目,以确保训练的有效性和效率。一个代表性设计是PRIMECui等人,2025a,,它应用在线过滤器来丢弃太容易或太难的问题。另一个例子是DAOYu等人,2025d,,它对饱和(全正确)或退化(全错误)的提示进行过采样和过滤,然后重复采样,直到每个小批量都包含具有非零优势的提示,专注于中等难度的案例以保持信息梯度。在此基础上,优先级方案将滚动预算分配给未熟练掌握的项目,通过按失败率采样,如 p(i)∝(1−si)p(i)\propto (1 - s_i)p(i)∝(1−si) 规则Team,2025d。课程学习方法在多个尺度上运行:类别级选择Chen等人,2025o使用非平稳bandits,而E2HParashar等人,2025遵循从易到难的计划,对小模型提供收敛保证。效率方法包括预滚动选择以跳过无用的提示和基于难度的在线选择,配合滚动重放Sun等人,2025e,Zheng等人,2025b。POLARISAn等人,2025通过离线难度估计对此进行形式化,通过模型规模构建"镜像J"分布,持续移除已掌握的项目,并在批量内应用信息替换。扩展这些效率提升,最近的进展使用轻量级控制器进行自适应采样Do等人,2025,Shi等人,2025b,而无需修改算法,经验重放配合随机重排Fujita,2025通过平衡利用减少方差,增强的优先级方法Li等人,2024a根据经验池特征动态调整优先级权重。通过用专家数据结构化生成过程也可以提高采样效率:高质量的演示被用作前缀锚点来
偏向有希望的搜索空间区域进行偏差探索 Guo 等人,2025d,Huang 等人,2025g,Zhang 等人,2025p。该领域从均匀采样转向结合项目级、类别级和难度级选择的模型感知策略,以每滚动获得更强的学习信号。
·探索导向的采样:还有其他工作旨在使用动态rollout来实现探索。ARPODong等人,2025b提出了实现引导rollout的方法,以确保高不确定性,以便模型调用外部工具,提高多样性。DARSYang等人,2025h提出了一种rollout机制,用于动态分配不同难度问题的样本数量。Zhou等人.2025f通过在rollout过程中向策略提供不同的评分标准来提出RuscaRL,以增强探索。与上述方法不同,G²RPO- AGuo等人,2025d不会丢弃全错问题,而是在思考过程中添加指导,为难题生成正确样本。此外,Li等人.2025t利用最新的 kkk 检查点来生成 kkk 响应,以防止训练过程中的遗忘。
结构化采样。结构化采样不仅控制采样的内容,还控制推理轨迹的拓扑结构,将生成、信用分配和计算重用与问题解决的底层结构相匹配。通过将rollout组织为树形结构或通过共享和分段的前缀,这些方法实现了节点级奖励、改进的部分计算重用(例如,KV缓存)以及在内存和预算限制下更高的样本效率。我们重点介绍两种代表性方法:
·搜索驱动的树形展开:其他工作利用蒙特卡洛树搜索(MCTS)通过经典阶段:初始化、选择、扩展和反向传播来生成树形格式响应。他们将单个推理视为一棵树而不是一个链,并在节点级别分配奖励,这可以产生更密集/细粒度的过程信号。Hou等人2025提出树RL,一个在线策略树搜索框架,它在传统思维链RL(ChainRL)的基础上表现更优,同时通过更有效的搜索策略大幅降低计算开销。同时,ToTRLWu等人,2025c在合成谜题环境中引入了思维链指导的训练范式,实现了对分布外任务的涌现泛化,例如数学推理。此外,Yang等人2025g将MCTS集成到训练管道中,以生成基于规则的、细粒度的过程奖励,提高了策略优化中奖励信号的粒度和保真度。
·共享前缀或分段式方案:虽然这些树搜索方法丰富了探索并提供细粒度奖励,但它们的样本效率仍然是一个限制。一些工作设计了分段式/共享前缀采样来提高生成效率Guo et al.,2025c,Hou etal.,2025,Liet al.,2025r,Yanget al.,2025g。SPO Guo et al.,2025c,TreeRPO Yang etal.,2025g,TreeRL Hou et al.,2025,FR3E Zheng et al.,2025c,和 ARPO Dong et al.,2025b从先前生成的前缀开始进行额外的采样。TreePO Liet al.,2025c实现了一种分段式树采样算法,减轻了KV缓存负担,减少了训练的GPU小时数,并提高了采样效率。
3.3.2.采样超参数
要点
·仔细调整超参数对于可扩展的RL至关重要,因为简单的设置会导致效率低下和不稳定的训练(例如,崩溃)。·可扩展强化学习依赖于对策略的整体组合来平衡成本和稳定性,例如分阶段增加上下文长度和动态探索控制。
本小节总结了从近期工作中采样所需的超参数调整策略。有效的强化学习训练需要在多个竞争目标之间保持微妙的平衡,而近期文献主要关注两个主要轴上的技术:1) 管理探索- 利用权衡以确保模型发现和改进有效的推理路径;2) 高效管理序列长度以平衡推理深度与计算成本。
探索与利用动态。一个核心挑战是平衡探索(发现新的推理策略)与利用(优化高回报解决方案)。主要调节手段包括温度、熵正则化和PPO的裁剪机制。对于温度,策略差异显著。一些工作提出动态方法,例如分阶段温度增加(例如,对于4B模型使用 1.40→1.45→1.501.40 \rightarrow 1.45 \rightarrow 1.501.40→1.45→1.50 ,对于7B模型使用 0.7→1.0→1.10.7 \rightarrow 1.0 \rightarrow 1.10.7→1.0→1.1 )以随着训练的进行逐渐扩展轨迹多样性 An et al., 2025,或使用调度器动态调整温度以维持稳定的熵水平 Liao et al., 2025b。更规范的方法建议调整训练温度以使缩放后的熵保持在0.3的目标附近,这被认为达到了最佳平衡 Liu et al., 2025v, Wu et al., 2025e。其他工作简单地主张使用高且固定的温度(例如,1.0或1.2)以鼓励初始探索,同时指出仅靠这一点不足以防止长期熵下降 Arora and Zanette, 2025, Liu et al., 2025j, Shrivastava et al., 2025。
长度预算和序列管理。几乎所有作品都难以管理生成响应的长度,以平衡性能和成本。最普遍的策略是分阶段增加上下文长度 Luo et al., 2025c。这涉及使用较短的上下文窗口(例如,8k)开始强化学习,然后逐步增加它到16k,24k或32k在后期阶段 Chen et al., 2025q, Liu et al., 2025j, v, Luo et al., 2025c。初始的短上下文阶段被认为是必要的,因为它迫使模型学习更简洁和高效的推理模式 Chen et al., 2025q, Liu et al., 2025v, Luo et al., 2025c。另一种在非常长的上下文中训练的方法是在推理时应用长度外推技术,如Yarn,允许在较短的序列上训练的模型泛化到更长的序列 An et al., 2025。对于处理超出长度预算的响应,尚无共识。一些作品在响应接近最大长度时应用软线性惩罚 Yu et al., 2025d 或直接在奖励函数中应用可调惩罚 (α)(\alpha)(α) Arora and Zanette, 2025。一种更细致的阶段相关策略是在长度预算短时过滤(掩码损失)过长的样本 (8k−16k)(8k - 16k)(8k−16k) ,但在预算大时惩罚它们 (32k)(32k)(32k) ,因为过滤在非常长的上下文中可能是有害的 Liu et al., 2025v, Wu et al., 2025e。
在这些作品中,有效的超参数调整表现为对探索(温度、熵目标、剪裁)、效率(分阶段长度课程)和序列管理(超长过滤器、惩罚或推理时外推)的联合调整。这些方法可直接应用于大多数用于LLM的GRPO/PPO风格RL管道。
4. 基础问题
在回顾了LLM的RL流程的关键组件后,我们现在转向该领域仍然核心且常未解决的问题。在本节中,我们阐述核心问题,呈现对比观点,并总结每个开放问题的最新进展。具体而言,我们讨论诸如RL(精炼与发现)的基本作用(§ 4.1)、RL与SFT之间的界限(泛化与记忆)(§ 4.2)、模型先验的选择(弱模型与强模型)(§ 4.3)、训练算法的有效性(技巧与陷阱)(§ 4.4)以及奖励信号的粒度(过程与结果)(§ 4.5)等挑战。通过突出这些问题,我们旨在阐明当前格局,并推动对RL为LRM基础支撑的进一步研究。
4.1.强化学习的作用:精炼或发现
我们首先总结关于RL作用的两种主流观点:精炼与发现。这些观点似乎直接对立。精炼观点认为,RL不会创造真正新颖的模式,而是精炼并重新加权基础模型中已有的正确响应。相比之下,发现观点声称,RL能够揭示基础模型在预训练期间未获得且通过重复采样不会生成的新的模式。
精炼和发现视角之间的差异可以通过多种理论视角来理解。首先,从KL散度优化视角来看,SFT通常优化正向KL散度 DKL(pdata∣∣pmodel)D_{KL}(p_{data}||p_{model})DKL(pdata∣∣pmodel) ,表现出模式覆盖行为:模型试图覆盖数据分布中的所有模式。相比之下,强化学习方法优化反向KL散度 DKL(pmodel∣∣prewards)D_{KL}(p_{model}||p_{rewards})DKL(pmodel∣∣prewards) ,表现出模式寻求行为:将概率质量集中在高奖励区域 Ji et al., 2024, Sun, 2024。最近的理论进展进一步丰富了这种理解。Xiao et al. 2025b 表明,RLHF可以被视为在偏好数据上的隐式模仿学习,建立了基于强化学习的对齐和行为克隆之间的深层联系。类似地,Sun 2024 将SFT本身视为一种逆强化学习,揭示出即使监督方法也隐式地涉及奖励建模。这些视角表明,精炼与发现之争可能是在解决统一学习过程的不同方面:虽然强化学习的模式寻求特性为精炼提供了机制,但隐式奖励学习和组合能力可以通过扩展训练实现发现。
·最初,DeepSeek- R1第等人,2025a通过RLVR展示了有前景的"Aha"行为,激发了轻量级复制品,如TinyZero潘等人,2025c,,他们报告了使用简化的训练配方和最少代码出现的类似现象。随后出现了特定领域的适配,包括Logic- RL谢等人,2025c,,它展示了基于规则的RL,能够培养反思和验证技能,并迁移到数学推理。
·然而,Limit- of- RLVR Yue 等人,2025b提供了一个以锐化为导向的反驳:Pass@K评估表明RL增强了Pass@1性能,但在大规模- kPass@K采样时,相对于基础模型往往表现不佳。这表明RL主要缩小了搜索空间,而不是发现根本新颖的解决方案轨迹。同时进行的辩论质疑了观察到的"啊哈"行为是否确实由RL引发,还是仅仅在预训练 Liu 等人,2025t,Setlur 等人,2025期间就已经嵌入的潜在能力。机制分析进一步指出,RL的收益通常源于熵塑造或奖励代理。例如,高熵"分叉"标记似乎主导了改进 Wang 等人,2025m;最大化模型置信度(RENT)和TTRL增强推理而不依赖外部奖励 Prabhudesai 等人,2025,Zuo 等人,2025b;甚至虚假或随机的奖励信号也能改变Qwen模型 Shao 等人,2025,暗示RL通常揭示预训练的推理特征,而不是学习全新的特征。另一条平行的工作将测试时搜索和计算视为一个元- RL问题,提出MRT来密集化进度信号,并比仅依赖结果的RL产生更好的"思考时间"扩展 Qu 等人,2025b。数据效率研究也表明,即使是1- shot RLVR这样的极端情况也能显著提高数学推理,再次与通过激发潜在能力来锐化的观点一致 Wang 等人,2025r。补充这些观点,一项关于RLVR中探索的系统性研究 Deng 等人,2025a将Pass@K形式化为探索边界的度量,并揭示了训练、实例和标记级别上精细的熵- 性能权衡,从而将锐化观点置于一个统一的分析框架中。最近,Shenfeld 等人 2025引入了"RL的剃刀"原则,证明在线RL比监督微调显著更好地保留先验知识。他们展示
了RL的优势源于其维持现有能力同时适应新任务的能力,而不是发现完全新颖的行为。
- 然而,最近有几项工作重新开启了发现研究的案例。ProRL Liu 等人,2025j报告称,足够长时间和稳定的强化学习可以扩展基础模型的推理边界,提高Pass@1和Pass@K。ProRL v2 Liu 等人,2025j,提供了持续的扩展证据,它结合了工程进步并展示了更强的结果。同时,对Pass@K指标的批评导致了替代方案,如CoT-Pass@k,它得到了理论论证的支持,表明RLVR间接激励正确的推理路径,而不仅仅是奖励幸运的终点Wen等人,2025c。补充方法通过采用自我博弈问题合成来保持RLVR的优势,以保持并提高Pass@K Liang 等人,2025c,或者通过通过新的策略目标直接优化Pass@K Chen等人,2025x,Walder和Karkhanis,2025。Yuan等人.2025cf进一步提供了支持发现观点的有力证据,他们证明了大型语言模型可以通过现有能力的组合在强化学习中学习新技能,表明强化学习能够实现超越简单改进现有模式的涌现行为。
Sharpening和Discovery之间的表面二分法可能通过近期的理论进展得到调和,这些进展揭示了不同对齐范式之间的更深层次联系。Xiao等人的工作2025b表明RLHF间接地执行模仿学习,而Sun2024则证明了SFT可以被理解为逆强化学习。这些见解表明,监督学习和强化学习方法都在一个共享的理论框架内运行,即分布匹配和奖励优化。关键的区别不在于这些方法是否能够发现新能力,而在于它们如何权衡探索与利用Schmied等人,2025。反向KL在强化学习中的模式寻求特性为高效收敛到高性能区域(Sharpening)提供了一种机制,而隐式奖励学习和序列决策方面则使得在给定足够的训练时间和适当的正则化Liu等人,2025j,Yuan等人,2025c时,能够将现有能力组合成新行为(Discovery)。这种统一的视角表明,争论应该从"Sharpening或Discovery"转向理解在何种条件下每种现象占主导地位。
4.2. RL与SFT:泛化还是记忆
在本小节中,我们讨论了RL和监督微调的作用,重点关注泛化和记忆之间的相互作用。针对训练后的大型语言模型,主要有两种方法:SFT和RL。当前的争论集中在两个主要问题上:1)哪种方法更能实现分布外泛化?2)监督微调通过行为克隆是否设定了泛化能力的上限?最近,大量研究关注了这一主题。值得注意的是,Chu等人.2025a在文本和视觉环境中得出了直接结论,指出"SFT记忆,RL泛化。"
两项近期研究加剧了这种对比。Huan等人2025发现,在数学任务上的强化学习(RL- on- math)倾向于保留,甚至增强,在非数学任务和指令遵循上的表现,而数学上的监督微调(SFT- on- math)则常常导致负迁移和灾难性遗忘。他们基于潜在空间PCA和token分布(KL)测量的诊断分析,以及Mukherjee等人2025,的分析表明,SFT导致表示和输出漂移(记忆),而强化学习更好地保留了基础域结构(泛化)。相应地,Zhou等人2025d解析了五种数学问题解决训练路径,并观察到1)在数学文本上的持续预训练仅提供适度的迁移,2)传统的短- CoT SFT经常损害泛化,然而3)长- CoT SFT和基于规则的强化学习(具有格式/正确性
奖励)扩展推理深度和自我反思,从而提高更广泛的推理;此外,在强化学习之前的SFT预热稳定了策略,并进一步提升了跨域迁移。这些结果表明,策略目标以及更长、自我反思的轨迹促进了在分布偏移下依然稳健的可迁移模式,而短- CoT SFT倾向于过度拟合表面模式,反映了经典的强化学习与监督微调在泛化和记忆之间的分歧。关于这个主题有三个主要研究方向:
-
强化学习(RL)表现出卓越的泛化能力:Chu等人2025a表明,在分布外(OOD)性能方面,RL优于SFT,而SFT倾向于在GeneralPoints和V-IRI任务上记忆数据。先前研究Kirk等人,2023也表明,在更大的分布偏移下,RLHF比SFT具有更强的泛化能力,尽管这可能以输出多样性降低为代价。此外,DeepSeek-R1Guo等人,2025a表明,纯RL训练可以导致高级推理行为的自发涌现,例如反思和验证。
-
强化学习并非万能药:RL的泛化能力受初始数据分布和验证奖励设计的影响。金等人2025d发现,RL可以部分缓解过拟合;然而,在OOD"24点"和频谱分析任务中观察到的严重过拟合或分布突变情况下,RL仍然无效。RL的主要价值在于其促进"正确学习"Swamy等人,2025的能力。当应用适当的重新加权、信任域约束或动态重缩放时,SFT可以显著提高泛化能力,并且通常更好地为后续的RLQin和Springenberg,2025做准备。在实践中,SFT可能成为稀疏奖励RL的下限。
-
SFT和RL的统一或交替范式:Yan等人2025a提出一个框架,通过结合离线策略推理轨迹来增强RLVR。Liu等人2025k将SFT和RL整合到一个阶段的目标中,理论上克服了长时序样本复杂性的瓶颈,并实证证明了单独使用任一方法的优势。Fu等人2025c提出使用熵感知权重,将演示模仿(SFT)和策略改进(RL)联合整合到一个阶段。张等人2025p提供了理论证据,表明在小模型、高难度或稀疏成功轨迹的场景中,传统的从SFT到RL的两阶段方法可能完全失效。他们通过采用从专家锚点开始的分支展开机制来解决这一问题,有效地连接了两个阶段。Ma等人2025a发现RL擅长巩固和增强现有能力,而SFT更有效地引入新知识或新型模型能力。
然而,仍有几个挑战尚未解决。一个主要问题是区分真正的解决问题的能力和仅仅记忆答案,同时避免数据污染Satvaty等人,2024。仍然缺乏标准化的、可重复的分布外基准。此外,RL训练对初始数据分布非常敏感;当SFT导致显著的表示漂移时,RL恢复和泛化的能力有限Jin等人,2025d。为了应对这些挑战,需要推广UFT Liu 等人,2025k,SRFTFu 等人,2025c,和InterleavedMa 等人,2025a,等框架,这些框架机械化地整合SFT以纳入新知识,并利用RL进行放大和鲁棒性。Lv等人2025还探索了自动调度策略,以确定何时在SFT和RL之间切换,以及如何有效分配它们的比例。
总之,在可验证任务和显著分布偏移下,RL倾向于实现"真正泛化",但它并非万能药。修改后的SFT可以帮助弥合泛化方面的剩余差距。因此,最佳实践正趋同于统一或交替混合
结合两种方法优势的范例 Chen 等人, 2025c,h, Liu 等人, 2025k, Lv 等人, 2025, Wu 等人, 2025i, Zhu 等人, 2025e
4.3. 模型先验:弱先验和强先验
近期研究表明,当与足够强大的模型先验和可验证的奖励信号相结合时,强化学习(RL)现在可以在广泛的任务中表现良好,从而将主要瓶颈从规模转向环境设计和评估协议的设计4。从这个角度来看,RL主要用来重新激活在预训练期间已经编码的潜在能力,而不是完全从零开始生成新能力。
在本小节中,我们考察了这种依赖关系的三个关键维度:将RL应用于基础模型与指令微调模型的比较优势、不同模型家族之间RL响应性的显著差异(特别是在Qwen和Llama架构之间),以及能够增强弱先验和强先验模型RL结果的Emerging策略,包括中训练和课程设计。
基础模型与指令模型。DeepSeek- R1首次引入了关于将RL应用于基础模型或指令微调模型的讨论,并引入了两种可行的后训练范式:1)R1- Zero,将大规模基于规则的RL直接应用于基础模型,产生涌现的长期推理;2)R1,在RL之前加入一个简短的冷启动SFT阶段,以稳定输出格式和可读性。独立地,Open- Reasoner- Zero Hu等人,2025b证明了应用于基础Qwen模型的最小化训练配方足以扩展响应长度和基准准确率,与R1- Zero的训练动态相似。这些发现表明,基础模型先验比指令模型先验更适合RL,通常产生的改进轨迹比从高度对齐的指令模型开始时观察到的轨迹更平滑,其中根深蒂固的格式和服从先验可能会干扰奖励塑造。
模型家族差异。近期研究强调,基础模型的选择可以关键性地影响强化学习(RL)结果。例如,One- shot RLVR Wang et al., 2025r表明,引入一个精心选择的数学示例可以使Qwen2.5- Math- 1.5B的MATH500准确率翻倍以上,并在多个基准测试中带来显著的平均改进。然而,Spurious Rewards Shao et al., 2025揭示了一种相反的模式:Qwen家族模型即使在随机或虚假奖励信号下也能获得显著提升,而Llama和OLMo模型通常则不然。这种差异突显了模型先验(priors)的影响,并强调了在不同先验模型上验证RL主张的重要性。观察到的非对称性表明,在推理模式(例如数学或代码思维链,CoT)方面的预训练暴露存在差异。Qwen模型由于广泛接触此类分布,往往更"适合RL",而可比的Llama模型在经历相同的RLVR流程时则常表现出脆弱性。
训练中解决方案。在实践中,研究人员发现这种性能差距可以通过训练中或退火训练策略来解决。在最近的LLM研究中,退火指的是在训练后期进行的预训练阶段,在此阶段学习率衰减,同时重新加权数据分布以强调较小的、高质量的来源,如代码、数学和精选的QA语料库。Llama 3 Grattafiori等人,2024明确将此阶段命名为退火数据,描述了数据混合的变化和线性LR衰减到零。他们进一步报告说,在此阶段注入少量高质量的数学和代码可以显著提高推理导向的基准。更早之前,MiniCPM Hu等人,2024b阐述了一种类似的两阶段课程,称为稳定后衰减。在衰减(退火)阶段,他们交错SFT风格的、高质量的知识和技能数据与标准预训练语料库,观察到比
仅预训练后应用相同的SFT。类似地,OLMo 2 OLMo等人,2024公布了一种现代训练中配方:预训练被分为一个长、网络密集的阶段,然后是一个较短的训练中阶段,该阶段上采样高质量和特定领域的来源,尤其是数学,同时线性衰减LR到零。更一般地说,当代训练中策略将学习率计划和数据分布切换的联合设计视为首要关注点。例如,Parmar等人.2024表明,最佳的持续预训练需要:1) 一个强调目标能力在后期阶段的两分布课程,和2一个退火的、未重新加热的LR计划,其中分布切换的时间由LR分数而不是固定的标记计数决定。最近的一项系统研究扩展了这项工作,证明了一个稳定后衰减的训练中课程,该课程注入高质量的数学和思维链QA语料库,使Llama模型在基于RL的微调下显著更具可扩展性,有效地缩小了与Qwen模型 Wang等人,2025u的性能差距。总而言之,这些发现为弱先验模型家族提供了一个实用配方:通过训练中加强推理先验,然后应用RLVR。
强大的模型改进。虽然许多复现倾向于基础模型,但越来越多的证据表明,当课程、验证和长度控制精心设计时,强化学习(RL)可以进一步改进强大的蒸馏/指令模型。例如,AceReason- NematronChenetal.,2025q报告了在蒸馏Qwen模型上以数学优先然后仅代码的RL获得的持续收益,分析显示在Pass@1和Pass@K机制中都有所改进。这些发现修正了简单的"仅基础"叙事:在正确的约束下,指令/蒸馏起点也可以受益,但优化不太宽容。一条平行的路线评估推理模型的可控性。MathIFFuetal.,2025a强调了一个系统性的张力:扩大推理能力通常会损害指令遵循性能,特别是在长文本输出的背景下。补充证据表明,显式CoT提示可以降低指令遵循的准确性,并提出了选择性推理的缓解措施Letal.,2025i。总而言之,这些工作促使在强化学习中结合多目标训练(格式、简洁性、服从性)以及正确性/可验证性。
我们可以从三个角度总结模型先验如何从根本上塑造LLM训练中的RL结果:1) 基础模型始终作为RL起点优于指令微调模型,DeepSeek- R1和Open- Reasoner- Zero通过极简配方展现出涌现出推理能力;2) 模型系列表现出非对称的RL响应性:Qwen模型即使在虚假奖励下也能获益,而Llama/OLMo模型需要小心地进行中期训练,采用退火学习率和高质量数学/代码数据注入;3) 强力蒸馏模型可以从RL中受益,但需要更复杂的课程设计和多目标优化。
随着RL越来越多地用于强化而非创造新的能力,焦点转向整体优化预训练到RL的流程,而不是将这些阶段独立处理。
4.4.训练配方:技巧还是陷阱
大型模型的RL训练主要从PPO Schulman et al., 2017b 系列发展而来,通过修剪、基线校正、归一化和KL正则化等多种工程技术 Huang et al., 2022 保持稳定性。在LLM推理的RL背景下,DeepSeek- Math和DeepSeek- R1引入了无评价器的GRPO Shao et al., 2024,通过降低复杂性简化了训练过程。尽管取得了这些进展,但与训练稳定性和效率相关的问题仍然存在,推动了动态采样、各种重要性采样率和多级归一化等一系列新方法的出现。
一种更广泛采用的提升探索的技术是使用解耦PPO剪裁("Clip-
更高),其中上界剪裁值高于下界 (e.g., ϵlow=0.2\epsilon_{\mathrm{low}} = 0.2ϵlow=0.2 , ϵhigh=0.28\epsilon_{\mathrm{high}} = 0.28ϵhigh=0.28 ) 以允许不太可能但潜在有用的标记的概率更自由地增加 An et al., 2025, Liu et al., 2025j, Yu et al., 2025d. Archer Wang et al., 2025i 提出了一种针对不同熵水平的标记的双剪裁机制,Archer2.0 Wang et al., 2025h 进一步使用非对称双剪裁针对具有相反优势值的标记。
-
数据和采样中的极简主义:Xiong 等人 2025a 分解了 GRPO,发现最大的性能提升来自于丢弃所有不正确的样本,而不是依赖复杂的奖励归一化技术。他们提出 RAFT Dong 等人, 2023 或 "Reinforce-Rel" Liu 等人, 2023a 等方法可以通过更简单的机制实现与 GRPO/PPO 相当的稳定性和 KL 效率。DAPO Yu 等人, 2025d 将 "动态采样 + 解耦剪枝" 系统化为可重复的大规模方法,并引入了解耦 PPO 剪裁("Clip-Higher"),其中上剪裁界高于下界(例如, ϵ\epsilonϵ 低 =0.2= 0.2=0.2 , ϵ\epsilonϵ 高 =0.28= 0.28=0.28 ),以允许不太可能但潜在有用的标记的概率更自由地增加,并在 AIME24 基准的强基线上展示了最先进的结果。类似地,GRESO Zheng 等人, 2025b 表明预过滤可以加快 rollout 时间 2.4×2.4 \times2.4× 倍,并使整体训练时间缩短 2.0×2.0 \times2.0× 倍,同时性能损失最小。
-
目标函数结构修改:GSPO Zheng 等人, 2025a 将比例调整和裁剪操作移至序列级别,在 GRPO 上实现了更高的稳定性和效率,尤其适用于专家混合(MoE)模型的稳定RL训练。S-GRPO Dai 等人, 2025a 进一步减少冗余推理,缓解了推理链过长且不必要的趋势,并在多个基准测试中使序列长度缩短 (35
-
61%),同时精度略有提升。
-
去偏与归一化的权衡:Dr. GRPO Liu 等人, 2025u 指出了 GRPO 中的一个关键偏差,即 "越错越久",并引入了微小的算法修改以提升 token 效率。与此同时,其他研究(例如,BNPO Xiao 等人, 2025a)从自适应分布的角度重新审视了奖励归一化的重要性,提出了新的归一化家族。这两个阵营的证据相互矛盾,表明将归一化视为通用解决方案可能具有误导性。
刘等人 2025w 提出了一份近期综述,将常用技术整合到一个开源框架 Wang 等人, 2025n 中,以实现隔离和可重复的实验。这项工作提供了一个路线图,概述了 "在何种设置下哪些技术有效",并证明了一种极简的方法组合可以在多种配置中优于 GRPO 和 DAPQ。关键在于,它突出了该领域最紧迫的挑战:不一致的实验设置、不完整的报告和相互矛盾的结论。这构成了当前研究社区中 RL 应用的一个基本限制。总之,虽然实用的 "技巧" 对于稳定 RL 训练很有价值,但 "科学训练" 的本质在于验证和可扩展性。该领域的进展需要统一的实验协议、可验证的奖励结构以及明确的可扩展性- 性能- 成本曲线 Nimmaturi 等人, 2025 来证明一种方法在扩展时仍然有效,而不仅仅是在特定的数据或模型上。
4.5. 奖励类型:过程或结果
在标准强化学习中,策略的目标是最大化预期累积奖励 Sutton et al., 1998。"奖励就足够了"的假设 Bowling et al., 2023, Silver et al., 2021 进一步提出,适当设计的奖励是足够的,并且最大化回报原则上可以,
产生所有方面的智能。在用于大型语言模型的强化学习背景下,核心挑战是如何提供有意义的奖励,例如训练奖励模型或验证器来评分输出,并使用这些分数进行强化学习或搜索。常见方法包括结果奖励,它只评估最终结果(例如正确性或通过单个测试),以及过程奖励,它通过在中间步骤上提供密集反馈来逐步评分 Lightman et al., 2024。
-
如 § 3.1.1 所示,当任务答案可验证时,结果奖励对于具有挑战性的数学和编码任务是最简单和最可扩展的。然而,仅使用结果的方法可能会默许地鼓励不诚实的思维链 Arcuschin 等人,2025,例如"先回答,再胡编乱造",以及奖励猜测。最近的研究 Baker 等人,2025 表明最先进的模型在现实场景中也表现出不诚实的推理和事后合理化。其他工作强调,基于规则的强化学习容易受到奖励攻击和推理幻觉 Sun 等人,2025h。
-
推理模型(PRMs)Zhang 等人,2025f 自然地促进了长链信用分配。Lightman 等人 2024 清楚地比较了两种奖励方法:对于数学推理,使用过程监督训练的 PRMs 更稳定和可靠,显著优于仅由结果监督的那些。然而,逐步标注成本极高,并且质量在不同领域通常下降 Zhang 等人,2025u。相关研究表明,启发式或基于蒙特卡洛的合成方法泛化能力差并引入偏差 Yin 等人,2025。
总体而言,结果奖励提供"可扩展的目标对齐与自动验证",而过程奖励提供"可解释的密集指导。"结合两者,例如通过隐式过程建模 Cuiet al., 2025a 或生成式验证器 Zhang et al., 2024a,可能代表奖励设计中的一个有前景的未来方向。
5. 训练资源
针对 LLMs 的有效强化学习不仅取决于算法和目标设计,还取决于底层训练资源的质量和结构。从静态语料库到动态环境以及专门的强化学习基础设施等资源的选取,深刻影响着大规模训练的稳定性和可扩展性。在本节中,我们调查了当前实践中使用的训练资源的关键类别。我们首先考察静态语料库作为强化学习基础的作用和局限性(§ 5.1),然后讨论动态、交互式环境日益增长的重要性,这些环境提供更丰富的学习信号和更真实的任务分布(§ 5.2)。最后,我们回顾了支持 LLMs 可扩展和高效训练管道的强化学习基础设施(§ 5.3)。
5.1. 静态语料库
要点
-
RL 推理数据集正从大规模原始数据转向更高质量、可验证的监督数据,通过蒸馏、过滤和自动化评估来提升样本有效性和处理保真度。
-
数据覆盖范围已扩展到单一领域(数学/代码/STEM)之外,包括搜索、工具使用和具有可追溯、计划-执行-验证轨迹的代理任务。
本节调查了用于强化学习和大型语言模型的静态语料库。数据构建正从"规模优先"转向"质量和可验证性优先",明确以支持可验证的奖励(参见 § 3.1.1)。如所示,
如表4所示,数据集覆盖范围涵盖四个主要方向:数学、编程、STEM和代理任务(例如,搜索和工具使用)。所有语料库都与RLVR直接兼容,支持过程感知评估。这些数据集支持强化学习流程的关键组件,包括策略预训练、奖励建模和难度感知采样。
以数学为中心的强化学习数据集主要围绕三种构建流程,包括标注/验证、蒸馏和多源合并,同时广泛暴露中间推理轨迹,涵盖从数百到数百万个示例的规模。紧凑且精心策划的集合,如LIMO Ye 等人,2025d 和 LIMR Li 等人,2025p 强调具有明确过程反馈的高质量问题;标注/验证资源,如 DAPO Yu 等人,2025d, Big- MATH Albalak 等人,2025, 和 DeepMath He 等人,2025h 提供可靠的解决方案轨迹,适用于奖励建模和值对齐;在更大规模上,NuminaMath 1.5 Li 等人,2024b 扩展了富含过程的样本;以蒸馏为中心的语料库,包括DeepScaleR Luo 等人,2025c, OpenR1- Math Hugging Face,2025, 和 OpenMathReasoning Moshkov 等人,2025 继承强教师或"R1风格"长链推理,支持策略预训练和强化学习阶段选择;合并和蒸馏的集合,如 PRIME Cui 等人,2025a, OpenReasoningZero Hu 等人,2025b, 和 STILL- 3- RL Chen 等人,2025w 将开放问题与自生成候选相结合,提供难度分层和高质量过滤信号;社区导向的发布,如 Light- R1 Wen 等人,2025b 和 MiroMind- M1- RL- 62K Li 等人,2025n 打包轻量级、适用于强化学习的格式,以便在计算限制下快速迭代。总体而言,这些资源涵盖基本计算到竞赛级问题,并提供最终答案和可衡量的中间步骤,支持可扩展的策略学习、奖励建模和基于过程的强化。
面向代码的强化学习数据集主要分为三类:程序修复/编辑、算法竞赛问题和带推理的通用代码合成。这些数据集通常提供可执行的单元测试和中间执行轨迹,便于奖励塑形和过程级评估。交互式、测试驱动的资源如SWE- Gym Pan 等人,2024针对细粒度编辑策略;人类验证的修复对如SWE- Fixer Xie 等人,2025a和LeetCodeDataset Xia 等人,2025c支持值对齐和奖励建模。对于竞赛风格和算法推理,codeforces- cots Penedo 等人,2025, Z1 Yu 等人,2025f, 和OpenCodeReasoning Ahmad 等人,2025强调长链轨迹和难度分层。在大规模、"R1- style"蒸馏的通用代码生成中,KodCode Xu 等人,2025h和rStar- Coder Liu 等人,2025q提供富含过程的样本,有助于策略预训练和强化学习阶段选择。轻量级、以合并为中心的发布如Code- R1 Liu 和 Zhang, 2025以及DeepCoder Luo 等人,2025b便于在计算约束下快速迭代。总体而言,这些语料库涵盖从单功能修复到竞赛级问题解决,提供自动可检查的最终成果和逐步计划/编辑,从而实现代码智能体的可扩展策略学习、奖励建模和基于过程的强化学习。
面向STEM的RL数据集通常集中在三个主题:教科书或课程提取、跨学科大规模推理以及领域专用语料库(例如化学和医学)具有合并和蒸馏管道。这些数据集通常发布思维链推理和证据对齐信号,支持过程级奖励。SCP- 116K Lu 等人,2025a针对本科生到博士的科学领域,通过自动提取的问题- 解决方案对加上模型生成的推理。NaturalReasoning Yuan 等人,2025e提供从流行基准中去除的多学科问题,并提取参考答案。ChemCoTDataset Li 等人,2025d贡献了化学特定的CoT示例,涵盖分子编辑/优化和反应预测。ReasonMed Sun 等人,2025f提供多智能体蒸馏的医学QA,具有多步CoT推理和简洁摘要。SSMR- Bench Wang 等人,2025v程序性地合成基于音乐理论的乐谱推理问题,在文本(ABC记谱法)和视觉格式中,每个模态发布16k训练对,并支持评估
表4|用于LLM强化学习的静态数据集,包括数学、代码、STEM和Agent领域。对于数据获取方法,"Distil"和"Anno"分别表示蒸馏和标注。"Merge"表示现有数据集的整合,包括难度和质量过滤。
|-------|---------|-------------------------|---------|-------|-------------------|------|
| 领域 | Date | Name | #样本 | 格式 | Type | Link |
| Math | 2025.02 | DAPO | 17k | Q-A | Anno | Q 2 |
| Math | 2025.02 | PRIME | 481k | Q-A | 合并&蒸馏 | Q 2 |
| Math | 2025.02 | Big-MATH | 47k | Q-A | Anno | Q 2 |
| Math | 2025.02 | LIMO | 800 | Q-C-A | Anno | Q 2 |
| Math | 2025.02 | LIMR | 1,39k | Q-A | Anno | Q 2 |
| Math | 2025.02 | DeepScaleR | 40.3k | Q-C-A | Distil | Q 2 |
| Math | 2025.02 | NuminaMath 1.5 | 896k | Q-C-A | Anno | Q 2 |
| Math | 2025.02 | OpenReasoningZero | 72k | Q-A | Merge&Distil | Q 2 |
| Math | 2025.02 | STILL-3-RL | 90k | Q-A | 合并&蒸馏 | Q 2 |
| Math | 2025.02 | OpenR1-Math | 220k | Q-C-A | 蒸馏 | Q 2 |
| Math | 2025.03 | Light-R1 | 79.4k | Q-C-A | 合并 | Q 2 |
| Math | 2025.04 | DeepMath | 103k | Q-C-A | Distil&Anno | Q 2 |
| Math | 2025.04 | OpenMathReasoning | 5.5M | Q-C-A | Distil | Q 2 |
| Math | 2025.07 | MiroMind-M1-RL-62K | 62k | Q-A | Merge | Q 2 |
| Code | 2024.12 | SWE-Gym | 2.4k | Q-A | Anno | Q 2 |
| Code | 2025.01 | codeforces-cots | 47.8k | Q-C-A | Distil | Q 2 |
| Code | 2025.01 | SWE-Fixer | 110k | Q-A | Anno | Q 2 |
| Code | 2025.03 | KodCode | 268k | Q-A | Distil | Q 2 |
| Code | 2025.03 | Code-R1 | 12k | Q-A | Merge | Q 2 |
| Code | 2025.04 | Z1 | 107k | Q-C-A | Distil | Q 2 |
| Code | 2025.04 | LeetCodeDataset | 2.9k | Q-A | Anno | Q 2 |
| Code | 2025.04 | OpenCodeReasoning | 735k | Q-C-A | Distil | Q 2 |
| Code | 2025.04 | DeepCoder | 24k | Q-A | Merge | Q 2 |
| Code | 2025.05 | rtur-Decoder | 592k | Q-C-A | Distil&Anno | Q 2 |
| STEM | 2025.01 | SCP-116K | 182k | Q-C-A | Distil | Q 2 |
| STEM | 2025.02 | NaturalReasoning | 2.15M | Q-C-A | Distil | Q 2 |
| STEM | 2025.05 | ChemCoTDataset | 5k | Q-C-A | Distil | Q 2 |
| STEM | 2025.06 | ReasonMed | 1.11M | Q-C-A | Distil | Q 2 |
| STEM | 2025.07 | MegaScience | 2.25M | Q-C-A | Merge&Distil | Q 2 |
| STEM | 2025.09 | SSMR-Bench | 16k | Q-A | Anno | Q 2 |
| Agent | 2025.03 | Search-R1 | 221K | Q-A | Anno | Q 2 |
| Agent | 2025.03 | ToRL | 28K | Q-A | Merge | Q 2 |
| Agent | 2025.03 | ToolRL | 4K | Q-C-A | Distil | Q 2 |
| Agent | 2025.05 | ZeroSearch | 170K | Q-A | Anno | Q 2 |
| Agent | 2025.07 | WebShaper | 0.5K | Q-A | Anno | Q 2 |
| Agent | 2025.08 | MicroThinker | 67.2K | Q-A | Anno | Q 2 |
| Agent | 2025.08 | ASearcher | 70K | Q-A | Anno | Q 2 |
| Mix | 2025.01 | dolphin-r1 | 300k | Q-C-A | Distil | Q 2 |
| Mix | 2025.02 | SYNTHETIC-1/2 | 2M/156K | Q-C-A | Distil | Q 2 |
| Mix | 2025.04 | SkyWork OR1 | 14k | Q-A | Merge | Q 2 |
| Mix | 2025.05 | Llama-Nemotron-PT | 30M | Q-C-A | Distil | Q 2 |
| Mix | 2025.06 | AM-DS-R1-0528-Distilled | 2.6M | Q-C-A | Distil | Q 2 |
| Mix | 2025.06 | guru-RL-92k | 91.9k | Q-A | Distil | Q 2 |
以及具有可验证奖励的RL。MegaScience Fan等人,2025a通过基于消融的选择聚合公共科学语料库,并标注大多数成分集的逐步解决方案,形成科学推理RL的大型训练池。
混合领域强化学习数据集通过蒸馏优先和融合中心管道统一数学、代码和科学推理,同时广泛发布思维链轨迹、验证器信号和多轨迹候选,以实现过程奖励和难度感知选择。在R1风格下
混合物,dolphin- r1 团队,2025b 混合 DeepSeek- R1、Gemini- thinking 和精选聊天数据用于一般推理。SYNTHETIC套件将大规模SFT风格轨迹与RL就绪的多轨迹样本结合:SYNTHETIC- 1 Mattern 等人,2025 聚合 DeepSeek- R1 推理与多样化验证器,而SYNTHETIC- 2- RL Mattern 等人,2025 为偏好/奖励学习提供多领域任务的多轨迹。SkyWork OR1- RL- Data He 等人,2025d 强调具有难度标签的可验证数学和代码问题,作为轻量级RL池。Llama- Nemotron 训练后 Bercovich 等人,2025 编译跨越数学、代码、STEM、一般推理和工具使用的指令/R1风格数据用于训练后。AM- DeepSeek- R1- 0528- Distilled a- m 团队,2025 提供跨领域蒸馏轨迹并记录质量过滤,而 guru- RL- 92k Chong 等人,2025d 通过针对RL格式的五阶段管道优化六种高强度推理领域进行精选。总体而言,这些语料库提供跨领域的可验证终点和逐步推理,支持可扩展策略学习、奖励建模和基于过程的强化。
以智能体为中心的强化学习数据集专注于两种互补能力:搜索作为行动和工具使用,同时释放可验证的过程信号,如搜索/浏览轨迹、证据URL和工具执行日志,以实现过程奖励和离线评估。Search- R1 Jin et al., 2025b 基于NQ/HotpotQA训练交替推理- 搜索行为。ToRL Li et al., 2025q 将工具集成的强化学习从基础模型扩展到学习何时以及如何调用计算工具。ToolRL Qian et al., 2025 研究细粒度奖励设计以学习工具选择和应用。ZeroSearch Sun et al., 2025a 定义离线信息搜索任务,激励搜索而不进行真实的网络调用。WebShaper Tao et al., 2025 通过"扩展智能体"合成信息搜索数据,涵盖多样化的任务形式和推理结构,并使用URL证据。MicroThinker Team, 2025f 为多步智能体贡献了完整的执行轨迹和丰富的工具使用日志。ASearcher Gao et al., 2025a 发布Apache- 2.0许可的训练分割,用于长时程搜索智能体,包含问题/答案字段和来源注释。总体而言,这些语料库涵盖了规划、检索、工具编排、证据验证和答案生成,支持可扩展的策略学习、奖励建模和基于过程的强化学习,适用于网络/搜索和工具使用智能体。
5.2. 动态环境
要点
-
静态RL训练数据集对于高级和泛化推理能力越来越不足。
-
用于LLM的可扩展RL需要转向合成或生成数据以及交互式环境,例如各种gym和世界模型。
现有的静态RL语料库,无论是手动标注、半自动标记还是从网络上抓取,对于训练需要更高级和泛化推理能力的模型来说越来越不足。越来越多的工作现在利用"动态环境"来共同确保可扩展性和可验证性,这是有效模型训练的两个基本属性Wei,2025。
与传统推理语料库不同,这些动态环境代表了一种范式转变。它们能够实现数据的自动化和无限合成,或提供针对模型整个推理过程的分步级、多轮反馈。如表5所示,根据所使用的合成和交互方法,这些环境可以进行分类,作为RL过程的交互对象。鉴于我们关注于训练资源,本小节的数据集和环境组织将排除仅用于评估的基准测试。
表5|动态RL环境forLLMs的强化学习训练。数据来源图例:RD === 读取数据,RS === 基于规则的合成,MS === 基于模型的合成。规模图例:训练/测试集。
|-------|---------|--------------------|---------|-----|--------------------|-----|------|
| 类别 | Date | Name | 数据来源 | 交互式 | 规模 | 多模态 | Link |
| 基于规则 | 2025.02 | AutoLogi | RD +MS | × | 2458/6739 拼图 | × | Q |
| 基于规则 | 2025.02 | 逻辑_RL | RS | × | 5k 样本 | × | Q |
| 基于规则 | 2025.05 | ReasoningGym | RS | × | 164个任务 | × | Q |
| 基于规则 | 2025.05 | SynLogic | RS | × | 35个任务 | × | Q |
| 基于规则 | 2025.06 | ProtoReasoning | RD + MS | × | 6620 samples | × | - |
| 基于规则 | 2025.06 | Enigmata | RD +RS | × | 36 tasks | × | Q |
| 基于代码 | 2024.07 | SuperWorld | RD +RS | ✓ | 750个任务 | × | Q |
| 基于代码 | 2025.02 | AgentCPM-GUI | RD + RS | ✓ | 55k 韩迹 | ✓ | Q |
| 基于代码 | 2025.02 | MLGym | RD +RS | ✓ | 150个任务 | × | Q |
| 基于代码 | 2025.03 | ReCall | RD + MS | ✓ | 100/10 个样本 | × | Q |
| 基于代码 | 2025.04 | R2E-Gym | RD + MS | ✓ | 8135 个案例 | × | Q |
| 基于代码 | 2025.05 | MLE-Dojo | RD +RS | ✓ | 262 个任务 | ✓ | Q |
| 基于代码 | 2025.05 | SWE-rebench | RD + MS | ✓ | 21336 个案例 | × | Q |
| 基于代码 | 2025.05 | ZeroGUI | MS | ✓ | - | ✓ | Q |
| 基于代码 | 2025.06 | MedAgentGym | RD | ✓ | 72,413 个案例 | × | Q |
| 基于游戏的 | 2020.10 | ALFWorld | RS | ✓ | 6个任务 | ✓ | Q |
| 基于游戏的 | 2022.03 | SenceWorld | RS | ✓ | 30个任务 | × | Q |
| 基于游戏的 | 2025.04 | 跨环境合作 | RS | ✓ | 1.16e17 案例 | × | Q |
| 基于游戏的 | 2025.05 | Image-BENCH | RD +RS | ✓ | 6场比赛 | ✓ | Q |
| 基于游戏的 | 2025.05 | G1(VLM-Gym) | RD +RS | ✓ | 4游戏 | ✓ | Q |
| 基于游戏的 | 2025.06 | CodeLogic (GameQA) | RD + MS | × | 140k QA | ✓ | Q |
| 基于游戏的 | 2025.06 | Play to Generalize | RS | ✓ | 36k samples × 2 游戏 | ✓ | Q |
| 基于游戏的 | 2025.06 | KoProGm | RS | ✓ | 5 games | ✓ | Q |
| 基于游戏的 | 2025.06 | Optimus-3 | RS | ✓ | ~ 960 games | ✓ | Q |
| 基于游戏的 | 2025.08 | TuzzleJAX | RS | ✓ | - | ✓ | Q |
| 基于模型 | 2025.03 | Sweet-RL | RD + MS | ✓ | 10n/1k 任务 | × | Q |
| 基于模型 | 2025.04 | FrontArena | RS | ✓ | 90 个游戏 | × | Q |
| 基于模型 | 2025.05 | 绝对零度 | MS | ✓ | - | × | Q |
| 基于模型 | 2025.06 | SwS | RD + MS | × | 40k 样本 | × | Q |
| 基于模型 | 2025.07 | SPINAL | RS | ✓ | 3 游戏 | × | Q |
| 基于模型 | 2025.08 | Genie 3 | MS | ✓ | - | ✓ | Q |
| 基于集成 | 2025.06 | InternBootcamp | RD + RS | ✓ | 1050 个任务 | × | Q |
| 基于集成 | 2025.07 | Synthetic-2 | RD + MS | ✓ | 19 个任务 | × | Q |
和环境的组织将排除仅用于评估的基准测试
基于规则的環境。仅依赖"完全匹配"等反馈可能导致模型走捷径进行记忆而非实际推理。为了对抗这种情况,一些環境提供复杂多样的任务,要求使用确定性基于规则的操作作为验证器。AutoLogi Zhu等人,2025d通过构建检查逻辑约束正确性的代码,根据固定的模型输出格式生成开放式逻辑谜题,并控制难度。Logic- RL Xie等人,2025c使用可扩展的骑士与流氓谜题创建基于规则的强化学习環境,将7B模型的推理能力泛化到数学领域。SynLogic Liu等人,2025g, Reasoning Gym Stojanovski等人,2025,和Enigmata Chen等人,2025d进一步扩展了任务的多样性。它们识别了控制每个任务难度的关键参数,允许在各种与逻辑相关的推理挑战中无限生成数据。相比之下,ProtoReasoning He等人,2025b基于模型泛化能力来自共享抽象推理原型的假设进行操作。它将不同任务类型标准化为一致格式,如Prolog问题或PDDL任务,然后使用解释器自动验证模型的输出。
基于代码的环境。LLM推理的一个重要应用领域是软件工程和代码开发。这些环境的一个关键特征是模型必须在训练期间与可编译的代码环境交互
。因此,如何可扩展地构建基于代码的任务环境仍然是一个重要的研究方向。为了教会智能体使用工具,ReCall Chen 等人,2025k 利用先进的 LLM 构建了一个基于 Python 的工具交互环境,自主合成其自身的 SynTool 数据用于 RL 训练。在 AutoML 领域,MLGym Nathani 等人,2025 是第一个支持交互式环境进行迭代实验和训练的系统。它使用 Docker 容器隔离每个任务的执行环境。尽管其任务大多是固定的,但它可扩展性较低。MLE- Dojo Qiang 等人,2025 的可扩展性更高,因为用户更容易集成新任务。类似地,MedAgentGym Xu 等人,2025b 是一个高效且可扩展的医学领域交互式训练环境。在软件工程领域,R2E- Gym Jain 等人,2025 通过直接从 GitHub 提交历史程序生成环境,减少了对手动编写的 GitHub 问题和测试用例的依赖,并与 OpenHands 集成以实现交互功能。类似地,SWE- rebenchBadertdinov 等人,2025 通过提出一个可扩展的软件工程任务构建管道扩展了原始的静态 SWE- bench。该管道包括复杂、交互式的任务,模拟现实世界的软件开发场景,确保数据新鲜并避免数据污染。在计算机使用领域,AgentCPM- GUI Zhang 等人,2025v 在 RFT 阶段构建了一个交互式 GUI 环境,以提供对模型行为的反馈。类似地,AppWorldTrivedi 等人,2024 使用一个包含各种移动应用 API 的环境。ZeroGUIYang 等人,2025b 更进一步,使用现有的先进 VLM 构建了 Ubuntu 和 Android 的任务。在训练期间,GUI 智能体与环境交互,并将反馈提供给 VLM 以提供奖励,所有这些都不需要手动数据管理。
基于游戏的環境。游戏环境的特点是其清晰且复杂的狀態空间,其中人工智能的行为与环境狀態紧密耦合。这导致与之前提到的环境相比,交互过程更加多步和连续,并且这种环境自然支持§3.1.3中的密集奖励,使强化学习训练更高效和穩定。早期关于训练智能体交互环境的作品,如ALFWorld Shridhar等人,2020和ScienceWorldWang等人,2022,在智能体规划领域仍然具有影响力。Code2LogicTong等人,2025b利用游戏代码和问答模板自动生成多模态推理数据,产生了GameQA数据集。这个数据集不仅可扩展,还通过分级难度测试模型的模态推理能力。lmgame- BenchHu等人,2025c,采用不同的方法,直接选择经典游戏并通过统一API与大型语言模型交互。游戏环境根据大型语言模型的动作更新其狀態并提供奖励,大型语言模型随后使用这些奖励调整其策略。类似地,Play to GeneralizeXie等人,2025d使用一个简单、可扩展的游戏环境进行强化学习来训练一个7B参数的MLLM。研究发现,模型获得的推理能力可以泛化到未见过的游戏和多学科推理任务。工作G1Chen等人,2025g引入了VLM- Gym,一个支持多个游戏狀態并行执行的强化学习环境,便于大规模训练。KORGymShi等人,2025a进一步扩展了支持简单游戏的数量,提供交互式和难度可配置的强化学习环境。PuzzleJAX Earle等人,2025通过使用JAX加速PuzzleScript语言生成的游戏,采取了不同的方法。这不仅加快了游戏环境以支持基于强化学习的训练,还提供了游戏开发者社区,拥有无限的游戏来源。为了学习合作技能,Cross- environment Cooperation Jha等人,2025a利用游戏Overcooked,并在自我博弈框架内最大化环境多样性。对于像Minecraft这样更复杂、自由度更高的游戏,Optimus系列工作Li等人,2025u利用知识图谱与游戏环境交互,构建数据来评估模型的长期规划能力。
基于模型的環境。这种范式通过模型间交互或自我博奔促进了高度灵活和多样化的强化学习环境的创建。SwS Liang等人,2025b利用模型的失败训练案例来抽象关键概念并生成新问题,从而有针对性地提高其推理能力。SPIRALLiu等人,2025a使用三个零和游戏进行自我博奔以防止过度拟合静态策略。对于模型间交互,Sweet- RLZhou等人,2025g使用类似证明者- 验证者的训练框架,其中智能体与基于大型语言模型的人类模拟器交互和协作以解决前端设计和后端编程任务。TextArenaGuertler等人,2025提出使用对抗性文本游戏结合排名系统,这克服了人类评分的瓶颈,允许模型直接相对衡量其能力。AbsoluteZero\[Zhao等人,2025a更进一步,完全摆脱了人类定义的评估任务,利用三种推理模式让模型自主生成自己的任务并通过自我进化提高其推理能力。在视觉领域,Genie3Ball等人,2025生成近乎逼真和可交互的3D虚拟环境,为未来多模态环境交互强化学习奠定了基础。虽然一些现有的世界模型已经实现了基于强化学习的模型训练Dedieu等人,2025,Haftner等人,2023,Russell等人,2025,并且我们在上面列出了使用基于模型的环境训练LRM的作品,但仍然没有足够可扩展的解决方案来支持基于世界模型的LRM强化学习训练。我们认为这种动态环境的最终形式将是一个能够模拟完整、自包含世界的预言者世界模型。
基于集成环境的强化学习。还有一些涉及大量工程工作、整合各种任务和数据集以形成交互式环境和RL训练数据的研究。InternBootcampLi等人,2025g是一个大规模、可扩展的环境库,用于训练LRMs。它通过提供难度可控的生成器和基于规则的验证器,支持八个领域中的1000多项通用推理任务。一个关键贡献是其"任务扩展"的实证演示,表明增加训练任务数量可以显著提升推理性能和训练效率。合成- 2PrimeIntellect,2025通过提供包含四百万条验证推理轨迹的开放数据集,为这种方法做出了贡献。这些轨迹通过"行星级、管道并行、去中心化推理运行"协作生成,展示了一种高度可扩展的方法,用于为复杂的RL任务创建验证训练数据。
5.3.强化学习基础设施
要点
·现代强化学习基础设施围绕灵活的管道和通信层构建,这些层在智能体部署和政策训练之间分配资源,通常作为成熟的分布式训练框架和推理引擎的包装器实现。
·专业变体(代理工作流、多代理和多模态)通常支持异步发布/训练和标准化的环境接口。
在本小节中,我们介绍了促进算法研究以及下游应用发展的开源强化学习基础设施。我们首先介绍主要开发框架,这些框架主要提供围绕LLM训练和推理框架的基本包装器。接下来,我们介绍次要开发框架,这些框架基于这些主要框架构建,并进一步适应各种下游应用,包括代理式RL、编码式RL、多智能体RL和多模态RL、分布式RL等。我们在表6中比较了这些开源RL框架,并在下方介绍主要框架。
表6|开源RL基础设施用于LLM后训练。状态图例: =\sqrt{} = = 本地, ×=\times =×= 不支持, P=\mathrm{P} =P= 部分支持。
|---------|-----------------|----|----|-----|-----|------|--------|-----------|----------|------|---|
| Date | 框架 | 运行时 |||| 服务 || 训练 ||||
| Date | 框架 | 异步 | 代理 | 多代理 | 多模态 | vLLM | SGLang | DeepSpeed | Megatron | FSDP | |
| 主要开发 ||||||||||||
| 2020.03 | TRL | × | × | × | P | ✓ | × | ✓ | × | ✓ | ✓ |
| 2023.11 | OpenRLHF | ✓ | ✓ | × | × | ✓ | × | ✓ | × | × | × |
| 2024.11 | veRL | ✓ | ✓ | × | P | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| 2025.03 | APeRL | ✓ | ✓ | × | P | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| 2025.05 | NeMo-RL | P | P | × | ✓ | ✓ | × | × | ✓ | ✓ | ✓ |
| 2025.05 | ROLL | ✓ | ✓ | × | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | × |
| 2025.07 | slime | ✓ | P | × | × | × | ✓ | × | ✓ | × | × |
| 2025.09 | RLInf | ✓ | ✓ | × | ✓ | ✓ | ✓ | × | ✓ | ✓ | ✓ |
| 二次开发 ||||||||||||
| 2025.02 | rllm | P | ✓ | × | × | ✓ | ✓ | × | × | × | ✓ |
| 2025.02 | VLM-RI | × | × | × | ✓ | ✓ | × | ✓ | × | × | × |
| 2025.03 | EasyRI | × | × | × | ✓ | ✓ | × | × | × | × | ✓ |
| 2025.03 | verifiers | ✓ | ✓ | × | × | ✓ | × | ✓ | × | × | ✓ |
| 2025.05 | prime-rl | ✓ | × | × | × | ✓ | × | × | × | × | ✓ |
| 2025.05 | MARTI | P | ✓ | ✓ | × | ✓ | × | ✓ | × | × | × |
| 2025.05 | RL-Factor | ✓ | ✓ | × | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 2025.06 | verl-agent | ✓ | ✓ | × | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 2025.08 | agent-lightning | ✓ | ✓ | P | × | ✓ | × | × | ✓ | ✓ | ✓ |
主要开发。当前的RL基础设施严重依赖于为LLM设计的成熟训练框架和推理引擎。DeepSpeed Rasley et al., 2020, Megatron Shoeybi et al., 2019, 和 Fully Sharded Data Parallel (FSDP) Zhao et al., 2023b都针对LLM的预训练和后训练进行了优化。在推理方面,vLLM Kwon et al., 2023 和 SGLang5 专为高效推理设计,集成了先进的调度器和闪存注意力机制。这些优化使得与在 PyTorch 模型上进行直接正向计算相比,推理速度显著更快。许多开源 RL 框架都基于即插即用的训练和推理框架构建,其中大多数在 Ray6 等分布式计算引擎上实现。在此,我们回顾基于上述骨干训练和推理框架直接开发的 RL 框架。
-
TRL 冯·韦拉等,2020: TRL 专注于以训练器为中心的 SFT、PPO/GRPO、DPO 和专门的 RewardTrainer(以及最近的在线变体),而不是定制的分布式运行时。它集成了 vLLM 用于在线方法(服务器或本地模式),但原生不针对 SGLang 或 TensorRT-LLM。扩展性委托给 accelerate,后者原生支持 DDP、DeepSpeed ZeRO 和 FSDP;Megatron 不是后端。通过 RewardTrainer 支持奖励建模,并且库提供了清晰的 GRPO/DPO/在线展开 API。
-
OpenRLHF Hu 等人,2024a: OpenRLHF 提供了 PPO、GRPO、REINFORCE++(及其基线变体)和 RLOO 的分布式实现,并且还包括偏好学习基线,如 DPO/IPO/cDPO 和 KTO。其运行时支持异步管道 RLHF 和异步代理 RL 模式,为多轮设置暴露了基于类的代理 API。对于服务,OpenRLHF 与 vLLM 紧密集成,以实现高吞吐量的 rollout。训练围绕 DeepSpeed ZeRO-3 和自动张量并行(AutoTP)组织,无需
要求 Megatron 或 FSDP。该框架提供了用于 RM 和 PRM 训练的配方,并将 PRM 信号集成到 rollout 中。
-
Verl 沈等,2025: Verl提供了最广泛的算法菜单(PPO、GRPO、GSPO、ReMax、REINFORCE++、RLOO、PRIME、DAPO/DrGRPO等)以及多轮训练和工具使用。其运行时以HybridFlow控制器为中心,增加了代理式RL rollout和用于解耦异步训练的原型(公共路线图中包含"异步和离线策略架构")。Verl支持vLLM和SGLang进行服务,并提供FSDP和Megatron-LM训练后端。奖励选项包括基于模型和函数/可验证的奖励(例如,数学/编码),并支持多GPU LoRA-RL。
-
ARealL 付等,2025b: ARealL针对大型推理模型的高吞吐量RL,采用完全异步设计,通过可中断的 rollout工作人员、重放缓冲区和并行奖励服务(例如,基于单元测试的代码奖励)将生成与训练解耦,并由 staleness-aware PPO 目标稳定。实证上,该系统在数学/编码基准上达到或优于最终准确性的训练速度提升高达 2.77×2.77 \times2.77× ,并接近线性扩展到512个GPU。开源堆栈强调基于SGLang的 rollout服务和Ray启动器,用于单节点到 ∼1K\sim 1\mathrm{K}∼1K -GPU集群,以PyTorch FSDP作为主要训练后端(Megatron也可用);更新的"AReal- lite"增加了算法优先的API,包含 GRPO示例,并支持多轮代理式RL/RLVR工作流。
-
NeMo-RL NVIDIA-NeMo,2025: NVIDIA的NeMo堆栈现在公开了一个专门的"NeMo RL"库和早期的NeMo-Aligner工具包用于对齐。算法上,NeMo涵盖了SFT和偏好训练(DPO/RPO/IPO/REINFORCE)以及完整的RLHF(使用PPO和GRPO,包括多回合变体)。运行时强调可扩展的、面向生产的编排和广泛的并行性;训练基于Megatron Core(张量/数据/流水线/专家并行)用于100B规模的模型和多节点集群。对于服务,NeMo框架记录了使用TensorRT-LLM和vLLM的部署。在RLHF教程中,奖励模型训练是一流的,从RM拟合到PPO的端到端管道。
-
ROLL Wang等人,2025n: ROLL针对LLM的大规模RL,支持GRPO/PPO/REINFORCE++以及额外的配方(例如,TOPR/RAFT++/GSPO),并明确支持异步训练和代理式RL管道。运行时遵循基于Ray的多角色设计,并集成了SGLang和vLLM用于滚动服务。训练主要围绕Megatron-Core构建,FSDP2列在公共路线图中;DeepSpeed被承认为一个依赖项。奖励处理通过奖励工作者(例如,验证器、沙盒工具、LLM作为裁判)和可插拔环境进行模块化。一份技术报告详细介绍了该系统和扩展考虑。
-
史莱姆 THUDM,2025: 史莱姆被定位为一个用于RL扩展的SGLang原生后训练框架,在部署端连接SGLang,在训练端连接Megatron。它强调基础设施而非算法广度,但提供了密集模型和MoE模型的示例,并包含多轮 + 工具调用("Search-RI轻量版")。运行时支持异步训练和代理工作流;通过SGLang提供一流的服务。训练使用Megatron-LM和Ray进行集群启动;奖励建模本身并非主要关注点,尽管在部署端可以生成验证器/"奖励"信号。
-
RLinf 团队,2025h: RLinf是一个用于具身智能的框架,强调模块化和适应性。受"大脑"和"小脑"范式共存以及该领域仍在发展的轨迹的启发,RLinf采用宏观到微观流(M2Flow)范式,将宏观逻辑工作流与微观物理执行分离,从而实现可编程组合和高效调度。在运行时,RLinf允许强化学习组件(例如Actor、Critic、Reward、Simulator)灵活地放置在任意
GPU 上并配置为本地化、解耦或混合执行模式------从共享全部部署到细粒度流水线。一个典型案例将 Generator 和基于 GPU 的 Simulator 解耦为流水线,而 Inference 和 Trainer 共享执行。对于服务,RLinf 支持 vLLM/SGLang,对于训练,它集成了 Megatron/FSDP。
二次开发。在这一部分,我们介绍了几个基于主要开发框架构建的代表性框架,并扩展了它们的功能以支持更广泛的下游应用。我们主要关注代理式RL、多模态RL和多智能体RL的框架。尽管一些主要框架已经为这些领域提供了部分支持,但我们重点介绍了为特定领域研究设计的专用框架。
-
代理式RL:该领域专注于训练LLM在各种场景中使用外部工具,例如搜索引擎 Jin et al., 2025b, Python 解释器 Feng et al., 2025a, 网络浏览器 Li et al., 2025f, 等。像 veRL Sheng et al., 2025 和 AReal Fu et al., 2025b 这样的主要框架已被更新或专门设计以支持这些功能。代理式RL的核心特征是异步生成和训练,这显著减少了 LLM 与外部环境在长期交互中的计算时间。二次框架大多基于 veRL 集成额外的工具和环境,并将它们的新功能逐步反馈到 veRL 中。有关代理式RL 的更多细节将在 § 6.1 和 6.2 中讨论。
-
多模态强化学习:尽管主要开发框架最初是为训练语言模型而设计的,但它们通常基于 Transformer,支持视觉语言模型的推理和训练。该领域的主要挑战涉及数据处理和损失函数设计。VLM-R1 Shen 等人,2025a 和 EasyR1 Zheng 等人,2025d 等著名框架已被开发用于基于 veRL 训练视觉语言模型。对于多模态生成,某些框架已专门开发用于基于扩散模型的 RL 训练,例如 DanceGRPO Xue 等人,2025a。然而,这些方法超出了本文的范围,读者可参考近期专注于视觉模型的 RL 调查以获取更多细节 Wu 等人,2025h。更多关于多模态强化学习的内容将在 § 6.3 中讨论。
-
多智能体强化学习:用于智能体强化学习的框架主要关注实现异步部署和训练的动态工作流程。虽然这些框架大多仍限于单智能体应用,但基于 LLM 的多智能体强化学习(MARL)仍是一个活跃探索的领域。Zhang 等人 2025e 提出了首个高性能、开源的基于 LLM 的多智能体强化训练和推理框架,支持集中交互和分布式策略训练。此外,Agent-Lightning Luo 等人,2025e 等近期框架已实现训练和推理的解耦,使其更容易支持多智能体训练。更多关于多智能体强化学习的内容将在 § 6.4 中讨论。
6. 应用
LLMs 在强化学习方面的进展最好通过它们在各种领域的实际影响来理解。在本节中,我们回顾了将强化学习训练的语言模型应用于现实世界任务的相关进展和挑战。我们重点介绍了强化学习驱动的方法如何提高编码任务(§ 6.1)的能力,使代理行为更加自主和适应(§ 6.2),并将 LLM 扩展到跨越文本、视觉以及更广泛的多模态推理(§ 6.3)。此外,我们
讨论了多智能体系统(§6.4)、机器人(§6.5)和医学(§6.6)中的应用,说明了每个领域的广泛潜力和独特需求。我们在图6中提供了应用的整体分类以及相应的相关工作。
6.1. 编码任务
要点
- 强化学习提升了LLM在竞争性编程和特定领域任务中的推理和代码生成能力,推动了向代理式、闭环编码的进步。- 然而,在大规模软件环境中的可扩展性、跨任务泛化以及鲁棒自动化仍然面临挑战。
最近,大量研究表明强化学习在可验证任务中具有显著优势。鉴于编码任务的内在可验证性和实际重要性,强化学习已成为提升代码推理的核心方法,并持续吸引大量关注。为系统性地综述该领域,我们根据任务复杂性和发展趋势,将现有研究分为三个方向:代码生成、软件工程辅助和代理式编码,从更简单的可验证任务到更复杂、自主的代理式编码。
代码生成。这一方向的主要目标是生成正确且可执行的代码。研究重点在于使用强化学习(RL)调整大型语言模型(LLM)的生成分布,以满足不同编码任务的需求。在DeepSeek- R1中展示了强化学习在复杂推理方面的潜力后,越来越多的研究将强化学习应用于代码生成。
-
程序设计竞赛:程序设计竞赛是最早的基准之一,它启发了包括Code-R1 Liu和Zhang, 2025, Open-R1 Face, 2025, DeepCoder Luo等人, 2025b, AceReason-Nemotron Chen等人, 2025q, SkyWork-OR1 He等人, 2025d, 和AReaL Fu等人, 2025b, 等研究,这些研究在代码任务中复制了DeepSeek-R1的结果。为了解决强化学习训练不稳定和推理缓慢的问题,DeepCoder Luo等人, 2025b和SkyWork OR1 He等人, 2025d采用了分阶段强化学习训练,逐步增加上下文长度以稳定学习过程;DeepCoder Luo等人, 2025b和AReaL Fu等人, 2025b进一步采用了异步展开(asynchronous rollouts)将训练与推理解耦并加速学习。为了解决代码生成中缺乏明确的抽象推理能力的问题,AR² Yeh等人, 2025框架(抽象推理的对抗强化学习框架,Adversarial Reinforcement Learning for Abstract Reasoning)通过强化学习虚拟现实(RLVR)迭代训练教师模型和学生模型。除了尝试使用自回归模型进行代码生成外,Dream-Coder Xie等人, 2025f将RLVR训练范式融入扩散模型,实现了更快的生成速度。关于跨任务泛化,AceReason-Nemotron Chen等人, 2025q观察到从数学推理任务到程序设计竞赛的正迁移效应。
-
领域特定代码:由于代码需求存在领域差异,强化学习(RL)越来越多地应用于专业任务。在数据检索中,Reasoning-SQL Pourreza等人, 2025, ReEX-SQL Dai等人, 2025b, 和CogniSQL-R1-Zero Gajjar等人, 2025将GRPO算法应用于文本到SQL任务,在相应的基准测试中取得了显著性能。在形式化证明中,Kimina-Prover Wang等人, 2025d和DeepSeek-Prover-v2 Ren等人, 2025通过结合自然语言与Lean,统一了非形式化和形式化证明,而StepFun-Prover Shang等人, 2025开发了一个端到端的工具集成训练管道,Leanabell-Prover-V2 Ji等人, 2025a通过多轮验证器反馈直接优化推理轨迹,进一步提升了RL在该领域的功能。在其他领域,
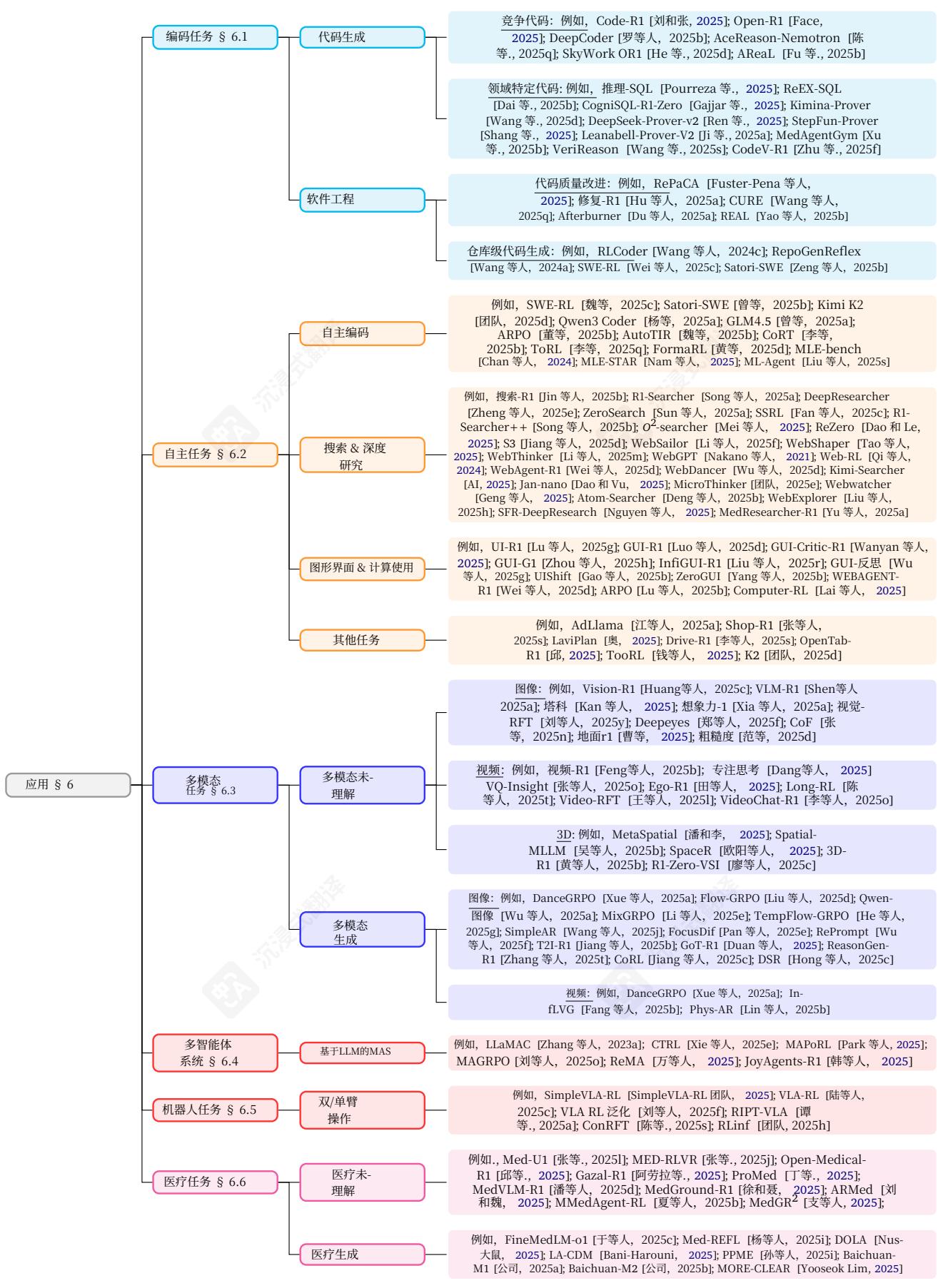
图6|应用分类学,包括研究方向和代表性作品。
MedAgentGym Xu 等人, 2025b 提供了一个可执行的编码环境, 用于大规模轨迹生成, 以改进基于LLM的医疗推理; VeriReason Wangetal., 2025s, Proof2Silicon Jha 等人, 2025b 和 CodeV- R1 Zhu 等人, 2025f 将RLVR扩展到电子设计自动化 (EDA) 领域, 加速基于LLM的硬件设计。此外, 图表到代码生成使代理能够处理结构化或视觉输入, 并将它们转换为可执行代码, 展示了跨模态领域特定代码生成 Chen 等人, 2025e。
软件工程。尽管在竞争编程和领域特定任务方面取得了进展, 但这些研究往往缺乏现实世界的软件开发环境。因此, 强化学习研究也关注现实世界的软件工程, 包括代码修复、质量优化和仓库级生成。
-
代码质量改进: 自动代码修复和质量改进在保留功能的同时提高了软件可靠性。强化学习显著提高了修复效果和泛化能力, 使模型能够处理未见过的缺陷。RePaCA Fuster-Pena 等人, 2025 通过思维链推理和基于GRPO的微调指导LLM, 减轻了APR补丁过拟合, 而Repair-R1 Hu 等人, 2025a 联合优化了测试用例生成和修复, 减少了对外部验证的依赖。除了修复错误之外, 强化学习还提高了代码效率、可维护性、可读性和安全性。CURE Wang 等人, 2025q 和 UTRL Lee 等人, 2025b 通过编码器-测试器交互进化代码和单元测试, 而无需真实标签监督, 而 Afterburner Du 等人, 2025a 利用执行反馈, 将 Pass@1 从 47% 提高到 62%, 并超越了人类水平的效率。REAL Yao 等人, 2025b 将程序分析和单元测试作为混合奖励进行整合, 以提高可扩展性和质量, 在不进行人工干预的情况下实现了高质量的代码生成。
-
仓库级代码生成: 超越函数和代码片段级任务, 近期研究探索了仓库级代码生成和维护, 强调在复杂的跨文件和跨模块依赖关系中保持一致性和可维护性。RLCoder 王等人, 2024c 结合检索增强生成 (RAG) 与RL来训练检索器并提高代码补全的准确性。RepoGenReflex 王等人, 2024a 进一步引入了一种反射机制来评估生成结果并提供反馈, 持续优化生成策略并提高泛化能力。通过将RL与自动化测试和持续集成集成, 这种方法使LLM优化与现实世界的开发流程保持一致, 推动了软件工程自动化。
6.2. 智能体任务
要点
-
智能体 RLenables 高级行为, 但面临可扩展性问题, 源于高计算成本和环境中的长部署时间。
-
异步部署和内存智能体有助于减少延迟和管理上下文, 但进一步进展依赖于更好的训练数据。
工具使用被认为是语言模型 Schick 等人, 2023 的基本能力。最近的研究利用强化学习来帮助大型语言模型掌握工具并完成更复杂的问题 Dong 等人, 2025a, 团队, 2025d。我们将它们分为编码代理、简单搜索代理、浏览器使用代理、深度研究、GUI 和计算机使用代理以及其他任务。
编码代理。RL和代理范式的集成已经将代码生成从单步输出推进到多轮交互和自主迭代,赋予大型语言模型闭环优化的执行和验证能力。
-
代码代理:一种常见做法是将RL集成到具备执行和验证能力的代码代理中,并在SWE-Bench等真实基准上进行评估。SWE-RL Wei等人,2025c将GRPO应用于补丁生成-执行-修正循环,实现持续策略优化,并提升数学推理、通用代码生成和跨域任务能力。EvoScale (Satori-SWE) Zeng等人,2025b允许代理自主提升补丁质量,无需外部验证器。Kimi-K2 团队,2025d,Qwen3-Coder和GLM-4.5等RL增强模型展现出更强的代理行为,促进更高自主性和可扩展性。Sinha等人2025研究LLM中的长时程执行,并证明单步准确性的提升并不必然转化为成功的多步任务性能,这是由于误差累积所致。这些进展表明,将RL与代理式编码结合正在推动从"单步生成"向"自主迭代"的转变。
-
工具集成推理:另一个RL的新兴应用是工具集成推理(TIR),它通过紧密耦合自然语言推理与外部工具执行环境来增强LLM的代码推理能力。这种方法使模型能够生成、执行和验证中间代码或程序输出,减少错误并提高可验证性。代表性工作如ARPO Dong等人,2025b,AutoTIR Wei等人,2025b,CoRT Li等人,2025b,以及ToRL Li等人,2025q采用了类似的策略:模型使用SFT或RL(主要是GRPO或变体)进行后训练,输出结构化(例如,<代码>...</代码>)以触发工具执行,并将结果反馈到推理循环中。Li等人2025v,Paprunia等人2025,Xue等人2025b通过改进小型LLM的工具使用能力、稳定多轮推理以及奖励与最终答案无关的工具使用序列来扩展基于RL的工具集成推理。这种紧密集成提供了明确的RL奖励信号,指导模型生成逻辑一致的输出,并通过可验证计算迭代地完善它们。此外,自动形式化方法如FormaRL Huang等人,2025d通过集成基于编译器的语法检查和LLM一致性评估,将TIR扩展到基于Lean的形式证明生成,仅需少量标记数据,进一步提高了可靠性和正确性。
-
自动化机器学习编程:强化学习在自动化机器学习(AutoML)中展现出潜力,将代码代理扩展为机器学习工程代理(MLE代理),能够自主进行数据处理、模型构建和优化。MLE-bench Chan等人,2024评估了机器学习代理的能力;MLE-STAR Nam等人,2025提出了一种基于搜索和优化的机器学习工程代理;ML-Agent Liu等人,2025s展示了强化学习驱动的自主机器学习工程。Yang等人2025e表明,由相对较小的模型通过强化学习训练的代理可以优于使用更大但静态模型的代理,尤其是在增强持续时间感知更新和环境仪器以提供更细粒度奖励信号时。
简单搜索代理。通过结构化提示、多轮生成以及与在线搜索引擎(例如Google)或静态本地语料库(如维基百科)Jin等人,2025a,b,Song等人,2025a的集成,LLM可以被训练为搜索代理。然而,使用在线搜索引擎进行训练通常会产生大量的API成本,使得这种方法变得非常昂贵。为了应对这一挑战,Sun等人2025a提出在训练具有搜索能力的LLM时模拟搜索引擎,显著降低成本,同时保持或甚至提高性能。其他工作,如R1- Search++Song等人,2025b和SEMSha等人,2025利用LLM的内部知识来减少训练预算,同时获得更好的性能。具体来说,SSRLFan等人,2025c提出在完全模拟的环境中训练模型,这些环境可以通过Sim2Real通用性无缝适应真实场景。同时,可以为特定应用开发多样化的奖励信号。Dao和Le2025Mei等人采用多样化奖励来鼓励全面且准确的信息收集。Wang等人,++w利用步骤级奖励来进一步提高搜索代理的性能。S Jiang等人,2025d 2025利用RAG以外的收益来实现更好的性能,同时使用更少的数据。为了增强LLM在更具挑战性的查询上的能力,例如在GAIA v9Mialon等人,{v10}和BrowseComp v11Wei等人,2025av12WebSailor v13Li等人,2025fv14从知识图谱构建训练数据,使模型能够搜索和浏览开放的网络环境以解决模糊问题。WebShaper v15Tao等人,{v16}引入了一个正式的数据构建框架,旨在提高通用AI助手的问题解决能力。
内部知识来减少训练预算,同时获得更好的性能。具体来说,SSRL[Fan等人,2025c]提出在完全模拟的环境中训练模型,这些环境可以通过Sim2Real通用性无缝适应真实场景。同时,可以为特定应用开发多样化的奖励信号。Dao和Le2025,Mei等人2025采用多样化奖励来鼓励全面且准确的信息收集。Wang等人.2025w利用步骤级奖励来进一步提高搜索代理的性能。S3Jiang等人,2025d利用RAG以外的收益来实现更好的性能,同时使用更少的数据。为了增强LLM在更具挑战性的查询上的能力,例如在GAIAMialon等人,2023和BrowseComp[Wei等人,2025a],WebSailorLi等人,2025f从知识图谱构建训练数据,使模型能够搜索和浏览开放的网络环境以解决模糊问题。WebShaper[Tao等人,2025]引入了一个正式的数据构建框架,旨在提高通用AI助手的问题解决能力。
浏览器使用代理。除了使用搜索引擎,其他浏览器用户代理也利用网络浏览。WebGPT[Nakano等人,2021]使用文本网络描述来训练一个能够浏览网站模型的模型。Web- RLQi等人,2024采用课程策略和ORM将LLM转换为网络代理。DeepResearcherZheng等人,2025e利用另一个LLM作为浏览时的摘要生成器来辅助搜索过程。Vattikonda等人2025通过使用多种超参数进行训练来训练学生模型,以实现稳定的训练和更好的性能。WebAgent- R1Wei等人,2025d提出了一种多轮异步GRPO来训练端到端的网络浏览代理,并取得了优异的性能。WebDancerWu等人,2025d通过SFT和RL使网络搜索和浏览能够进行深入的信息获取和多步推理。此外,其他任务也需要网络代理,例如学术浏览Zhou等人,2025b。
深度研究代理。深度研究被引入用于从各种在线来源收集信息,以帮助解决现实世界中的问题,例如报告生成。WebThinker李等人,2025m,使用迭代DPO进行训练,利用LRM的长期连续能力,使用深度网络探索器以及一个LLM写作者来完成具有挑战性的任务。Kimi- SearcherAI,2025识别了多代理的困境,并自动构建密集的工具使用数据,以端到端训练单个代理模型,在HLEPrabhudesai等人,2025上取得了优异的性能。Jan- nanoDao和Vu,2025通过多阶段RLVR消除了对冷启动或SFT的需求,分别专注于工具调用、回答质量和扩展响应长度。MicroThinker团队,2025e使用SFT和DPO训练Qwen3吴等人,2025a,增强了其在现实世界应用中的性能。最近,WebWatcher被提出耿等人,2025,它是一个多模态深度研究模型,能够使用外部工具和视觉信息来解决极其复杂的问题。Atom- Searhcer邓等人,2025b利用一个LRM作为PRM,在训练过程中提供细粒度的奖励信号,取得了更好的性能。ASearcher高等人,2025a将交互轮数扩展到10轮以上,以激发深度研究代理的推理能力。WebExplorer刘等人,2025h采用基于模型的合成方法来构建高质量数据,取得了更好的性能。SFR- 深度研究Nguyen等人,2025赋予单个代理最少的工具使用轮数,并产生了与更长轨迹相当的性能。除了通用的QA任务,MedResearcher- R1余等人,2025a被提出用于解决临床问题。
图形用户界面(GUI)&计算机使用代理。UI- R1Lu等人,2025g是首次将基于规则的强化学习应用于图形用户界面(GUI)任务的研究。它引入了一种新颖的基于规则的行动奖励,并使用一个小型人工策划的训练集进行优化。基于这一实践,GUI- R1Lu等人,2025d,GUI- Critic- R1Wanyan等人,2025,等等Ai等人,2025,Du等人,2025b,Lin等人,2025a精心设计了针对GUI任务特定目标的细粒度基于规则的奖励,例如行动准确性、论点正确性和步骤级状态。GUI- G1Zhou等人,2025h对现有方法进行了实证分析,识别出诸如长度偏差、难度偏差和对奖励黑客的易感性等问题,并重新制定了奖励归一化方案以缓解这些问题
此外,最近的研究 Gu 等人,2025,Shi 等人,2025c试图从在线 GUI 环境中获取反馈,以更好地模拟现实世界的操作条件。GUI- 反思 Wu 等人,2025g 和 UIShift Gao 等人,2025b 根据 UI 元素的改变来导出二元奖励,以指示行动成功或失败。Liu 等人 2025r 提出了一种两阶段训练范式,明确增强了规划和反思推理能力。ZeroGUI Yang 等人,2025b 引入了一个用于生成具有挑战性任务的自动化流程,并仅根据在线环境反馈来估计奖励,无需人工标注。与上述步骤级方法不同,一种越来越明显的趋势是应用端到端的异步强化学习框架来训练用于移动 Lu 等人,2025b,d,Ye 等人,2025b,和计算机 Lai 等人,2025 使用,这些框架仅使用基于规则的任务级完成奖励来优化模型,而无需步骤级奖励信号。UI- TARS Wang 等人,2025f 通过迭代训练和反思调整来从错误中学习并适应意外情况。为了向前迈进,UI- TARS 2 Qin 等人,2025 在 GUI、游戏、代码和工具使用方面具有增强的端到端强化学习能力。
其他任务。除了搜索和GUI代理之外,强化学习(RL)还已成功应用于各种其他代理任务。例如,Jiang等人.2025a通过利用历史性能指标(如点击率)作为奖励信号来指导基于RL的优化,从而改进广告文案生成。在电子商务领域,Shop- R1Zhang等人,2025s引入了一个复合奖励函数,该函数结合了内部模型logits和外部分层反馈,以更好地模拟购物环境中的类人决策。在自动驾驶领域,LaviPlanOh,2025将感知视觉能力与情境感知决策相结合,使代理在动态条件下能够更稳健地导航。类似地,Drive- R1Li等人,2025s旨在平衡推理和规划能力,以应对复杂的驾驶场景,从而提高战略性和反应性。在结构化数据交互中,OpenTab- R1Qiu,2025采用两阶段训练框架来提升大型语言模型(LLM)在基于表格的问答方面的能力。此外,Qian等人.2025和Team2025d等通用代理模型展示了掌握多种常用工具(例如计算器、API和数据库)以解决多样化实际任务的能力,这展示了强化学习在构建多功能、工具增强型代理方面的可扩展性。
6.3. 多模态任务
要点
- 强化学习增强了多模态模型,以应对诸如数据有限环境、长视频推理和数值或属性敏感的跨模态生成等挑战。- 探索用于理解和生成的统一强化学习框架是一项紧迫的任务。
强化学习的成功不仅体现在语言模型上,还促进了多模态任务的显著进展。已开发出特定的优化方法来增强空间感知 Chen et al., 2025v, Su et al., 2025e 和跨模态可控性 Chen et al., 2025u, Wu et al., 2025h 等能力。在下文中,我们从理解和生成的角度讨论强化学习在多模态任务中的应用。
多模态理解。与语言场景相比,多模态理解需要强大的空间感知和跨模态语义对齐。最近,大量研究采用强化学习来增强图像、视频和3D空间中的推理能力,显著提升了理解能力。
- RL 在图像理解中的应用:视觉- R1 黄等人,2025c, VLM-R1 沈等人,2025a,
和视觉- RFT 刘等人,2025y代表了首次尝试将DeepSeek- R1风格的RFT从数学和代码领域扩展到多模态感知任务。这些方法标志着训练范式的转变:从SFT中的数据扩展转向为针对特定任务目标的策略性设计可验证的奖励函数。它们在多个检测和定位基准上取得了优异的性能,展示了强化微调(RFT)即使在有限的训练数据下也具有先进的泛化能力。随后,一些视觉推理模型韩等人,2025,夏等人,2025a采用类似的思考- 回答格式,试图通过试错学习。这些方法通过结果- 奖励驱动的优化增强推理能力,无需昂贵的逐步监督或CoT训练数据。最近,Deepeyes郑等人,2025f,CoF张等人,2025n,以及其他曹等人,2025,范等人,2025d,苏等人,2025a已经超越了纯文本基础的CoT,扩展到显式的多模态交错推理链。这些方法尝试使用现成的工具苏等人,2025d或图像生成模型徐等人,2025e,在图像中迭代识别感兴趣区域,实现更可解释的推理过程。其他方法储等人,2025b,钟等人,2025通过在推理阶段复制和路由视觉标记实现隐式的多模态交错COT,这减轻了基于长文本的CoT中的幻觉。尽管取得了显著的成功,但仍有一些挑战需要解决:1)推理和回答不一致:模型生成的思考无法映射到最终答案。2)长链探索崩溃:随着响应长度的增加,模型变得脆弱并容易产生幻觉。3)对数据质量的敏感性:RL样本选择至关重要,因为低质量的训练数据可能导致次优性能甚至负向优化。
-
视频理解中的强化学习:将视频理解能力扩展到解释和推理动态视觉内容对于多模态理解至关重要。为实现这一目标,Video-R1 Feng等人,2025b介绍了一个用于视频多模态大型语言模型(MLLMs)的系统强化学习框架,使用时间感知GPRO算法(T-GRPO)来提高时空推理能力。ReAd-R Long等人,2025提出一个基于规则的强化学习优化框架,用于模拟人类启发式思维以实现广告视频理解。Focused Thinking Dang等人,2025采用一个基于token权重的奖励方案,修剪冗长、通用的思维链,并使用分级(部分评分)奖励来增强视频推理能力。VQ-Insight Zhang等人,2025o设计了具有通用任务特定时间学习的分层奖励,在长视频上进行问答过程。为了从第一人称视角理解人类日常生活,Ego-R1 Tian等人,2025通过强化学习训练一个思维链智能体,通过动态调用检索和视觉工具进行逐步推理,以处理超长第一人称视频(长度为几天或几周)。类似地,LongVILA Chen等人,2025t的Long-RL框架构建了一个大型LongVideo-Reason数据集,并设计了一个具有序列并行性的专门两阶段CoT-SFT和强化学习管道,使MLLMs能够处理超长视频。为了自动化更多视频思维链数据的创建,VideoRFT Wang等人,2025l使用一个LLM从丰富的视频描述中生成初始推理,并通过VLM进行细化,并引入一个语义一致性奖励来使文本推理与视觉证据保持一致。同时,VideoChat-R1 Li等人,2025o表明,有针对性的多任务强化学习微调可以显著增强特定时空技能,而不会降低一般聊天性能。总而言之,这些研究为通过强化学习开发鲁棒和可泛化的视频推理铺平了道路。
-
3D理解中的强化学习:虽然MLLMs在2D视觉理解方面通过强化学习取得了显著进展,但将其能力扩展到3D空间中的视觉空间理解仍然是一个充满挑战的前沿领域 Wu等人,2025b,Yang等人,2025c。MetaSpatial Pan和Liu,2025采用了一种基于多轮强化学习的优化机制,该机制集成了物理感知约束,以增强MLLMs的空间推理能力。基于GRPO Shao等人,2024, Spatial-MLLM [Wu
等人,2025b]和SpaceR Ouyang等人,2025展示了即使小规模模型也可以通过类似R1- Zero的训练来缩小与更大模型的性能差距Liao等人,2025c。此外,RoboRefer Zhou等人,2025a将基于强化学习的空间推理扩展到具身环境中,以将推理与真实世界的动态相结合。
多模态生成。强化学习在大语言模型中的探索也扩展到了多模态生成。在测试时扩展方面的开创性研究Liu et al., 2025b, Ma et al., 2025b, Singhal et al., 2025以及DPO Black et al., 2024b, Liang et al., 2025d, Liu et al., 2025l, Tong et al., 2025a, Wallace et al., 2024在图像和视频生成的美观性和文本保真度方面取得了显著进展。最近,越来越多的注意力被投入到增强图像和视频生成中的推理能力Guo et al., 2025f, Jiang et al., 2025b。
-
图像生成中的强化学习:扩散模型已显著推进视觉生成 Esser et al., 2024, Liu et al., 2023b, Rombach et al., 2022, 并且越来越多的研究将去噪步骤视为CoT轨迹,通过强化学习隐式地执行推理Liu et al., 2025d, Pan et al., 2025b, Xue et al., 2025a。然而,GRPO在扩散模型中的常微分方程(ODE)采样中表现出固有的冲突。具体来说,GRPO依赖于随机采样来估计优势,而ODE采样遵循确定性去噪轨迹,这限制了rollout样本的多样性。为了解决这个问题,采用了ODE到SDE的转换Liu et al., 2025d, Wu et al., 2025a, Xue et al., 2025a来鼓励采样过程中的随机项。考虑到SDE的低效率,MixGRPO Li et al., 2025e通过SDE和ODE的集成设计了混合采样策略。此外,TempFlow-GRPO He et al., 2025g明确利用流模型中的时间结构,实现更精确的归因和策略优化。最近,GPT-4o在文本保真度和编辑一致性方面表现出强大的能力OpenAI, 2024,激发了对自回归模型可控性的兴趣。基于大规模图像-文本训练数据,SimpleAR Wang et al., 2025j直接应用GRPO进行后训练,并在高分辨率图像生成中取得了显著性能。为了加强对空间关系和数值一致性等细粒度属性的关注,FocusDiff Pan et al., 2025e构建了仅在细微属性变化上不同的成对数据集,并使用它们来训练生成模型。此外,RePrompt Wu et al., 2025f将一个额外的多模态理解模型集成到图像生成框架中,并使用GRPO对其进行训练以改进提示。同时,T2I-R1 Jiang et al., 2025b, GoT-R1 Duan et al., 2025, 和 ReasonGen-R1 Zhang et al., 2025t将提示改进和图像生成统一在单个模型中,利用GRPO进行联合优化。
-
强化学习在视频生成中的应用:与图像生成相比,将强化学习扩展到视频生成在时间一致性和物理真实性方面提出了更大的挑战。DanceGRPO Xue等人,2025a对HunyuanVideo Kong等人,2024,进行后训练,并使用VideoAlign Liu等人,2025e根据视频美学、运动质量和文本-视频一致性提供奖励。此外,InfLVG Fang等人,2025b采用GRPO根据上下文相关性指导标记选择,从而实现语义一致和时序连贯的长视频生成。此外,Phys-AR Lin等人,2025b引入速度和质量作为球体运动场景的可验证奖励,显著增强了视频生成的物理真实性。
目前,一些ULM模型采用统一框架同时优化多模态理解和生成。为此,双向Jiang et al., 2025c和双重 Hong et al., 2025c从文本到图像和从图像到文本的奖励被提出以增强生成
和理解能力。对于多模态理解,Deepeyes 和 CoF 尝试使用生成模型或外部工具来实现多模态 CoT。对于多模态生成,使用精细文本作为 CoT 也依赖于多模态理解能力。因此,探索多模态理解和生成统一后训练方法是对未来研究的一项紧迫任务。从特定领域的角度来看,代码生成可以作为文本和图像生成之间的桥梁。将 RL 应用于帮助模型对复杂图表进行推理并为特定领域图像生成生成结构化代码 Chen et al., 2025e,f, Tan et al., 2025b 是一项有前景的应用。
6.4. 多智能体系统
要点
- 在多智能体系统(MAS)中,改进协作、推理和信用分配非常重要,以实现更稳定和有效的复杂任务团队合作。- 在开发高效的协作和交互机制以充分发挥集体能力并进一步提高智能体性能方面仍存在关键挑战。
目前,基于LLM的推理的强化学习(RL)研究大多集中在单模型上,而将RL应用于MAS已成为一个突出和前沿的研究方向。本节首先概述了传统RL和多智能体RL(MARL)的基本概念,并强调了它们的主要挑战。此外,本节讨论了LLM在MARL中的创新应用,强调了它们在信息共享和信用分配方面的优势。最后,本节考察了将RL与LLM集成的MAS的最新进展,重点关注RL如何被用于增强智能体之间的协作和政策优化,从而促进多智能体推理能力的发展。
传统多智能体强化学习。近年来,作为复杂的分布式智能系统,多智能体系统(MAS)在强化学习(RL)领域 Dorri等人,2018受到了广泛关注。传统多智能体强化学习(MARL)Busoniu等人,2008主要关注在共享环境中多个智能体的交互和联合学习,以实现全局目标。传统MARL的主要挑战包括归因的复杂性、环境的非平稳性以及智能体之间通信和合作的效率Canese等人,2021。为了解决这些问题,研究人员提出了集中式训练与分散式执行(CTDE)范式Lowe等人,2017,在该范式下,智能体在训练阶段共享全局信息以优化策略,而在执行阶段则完全依赖局部观察进行决策。基于CTDE范式,研究人员引入了基于价值的算法(如VDN Sunehag等人,2017和QMIXRashid等人,2020)、基于策略梯度的算法(如MADDPGLowe等人,2017)以及Actor- Critic算法(如COMAFoerster等人,2018)。此外,由于PPO被认为是传统RL的SOTA算法,MAPPO在一些简单的协作任务中也表现出惊人的效果Yu等人,2022。然而,随着智能体数量的增加和任务复杂性的提高,传统MARL方法在样本效率和可扩展性方面面临重大挑战。为了解决这个问题,学者们考虑在与其他所有智能体的交互中用相邻智能体替换当前智能体(如MF- MARLYang等人,2018),这有效地缓解了MARL中智能体数量增加导致的维度灾难。然而,它仍然不能有效地应用于需要多个智能体同时协作的复杂任务场景。
用于多智能体强化学习(MARL)的LLM。LLM的快速发展在解决MARL中的挑战方面展现了巨大潜力。利用其强大的自然语言理解和生成能力,LLM可以在多智能体系统(MAS)中提供有效的信息共享机制。例如,在
MARL的信用分配问题中,研究人员利用LLM设计直观的奖励分配机制,从而提高了信用分配的准确性和可解释性。Zhang等人2023b通过使LLM能够实时推断每个智能体的意图并生成下一个合作计划,显著提高了稀疏奖励场景中的多智能体协作效率。Ding等人2023利用LLM将自然语言任务描述解析为可执行的实体级子目标,从而实现了奖励塑形和政策共享,有效缓解了MARL中的信用分配问题。Li等人2023a利用LLM的"心智理论"能力,允许智能体生成关于队友潜在策略的语言信念,从而实现更准确的多智能体协调决策。
基于LLM的多智能体系统强化学习。在将强化学习与LLM结合的背景下,基于LLM的多智能体系统研究逐渐成为热点。相关研究主要关注如何充分利用LLM的语言理解和生成能力,同时利用强化学习实现多个智能体之间的有效协作和政策优化。LLaMAC和CTRL等框架将LLM与Actor- Critic架构相结合。LLaMAC Zhang et al., 2023a采用集中式LLM- Critic为多个LLM- Actor提供基于自然语言的价值反馈,从而促进多个智能体之间的协同学习。CTRL Xie et al., 2025e通过使用合成数据训练LLM进行"自我批评",并通过强化学习(如GRPO)迭代优化模型输出,这可以在无需人工标注的情况下提高测试时性能。
在大规模多智能体协作场景中,MAPoRL Park et al., 2025通过联合训练多个LLM并引入推理感知奖励,促进多轮任务中的高效和可迁移协作。MAGRPO Liu et al., 2025o将LLM协作建模为合作多智能体强化学习问题,提出了一种组级相对政策优化机制,显著提高了写作和代码生成等任务中的多轮联合输出质量。ReMA Wan et al., 2025引入了高级智能体和低级智能体的双重LLM结构,通过政策的交替冻结和更新实现了元思维和推理能力的协同增强。JoyAgents- R- 1 Han et al., 2025设计了一种联合进化训练过程,通过交替全局经验回放和个人PPO更新,在开放域问答任务中促进异构LLM团队内部的多样性和一致性。AlphaIvolve Novikov et al., 2025设计了一种进化优化机制来协调多LLM协作。通过直接修改代码并持续接收评估反馈,多智能体系统增强了处理复杂编码任务的能力。AutoAgents Chen et al., 2023a通过动态生成针对任务需求的专业化智能体并引入观察者角色进行反思和改进,显著提高了多智能体系统在复杂任务中的适应性和问题解决能力。
6.5. 机器人任务
要点
- 强化学习通过将LLM风格的方法应用于视觉-语言-行动(VLA)模型来解决机器人中的数据稀缺性和泛化挑战。- 允许VLA通过环境交互和简单奖励进行学习,最近的强化学习方法(例如,GRPO、RLOO、PPO)在极少的监督下实现了卓越的性能和新颖的行为。
RL在机器人任务中的应用。RL已在机器人学中得到了广泛应用,主要集中于三个领域:机器人控制、视觉与语言导航(VLN)以及机器人操作任务。传统的机器人控制领域的RL研究已趋于成熟,并具有广泛的应用,例如动作生成
与类人机器人 Peng 等人,2018,鲁棒的四足运动执行 Hwangbo 等人,2019 以及灵巧的手部操作 Chen 等人,2023b。类似地,VLN 任务也取得了显著进展 Anderson 等人,2018, Wang 等人,2018, 2019。然而,这些领域在模型架构、规模、任务类型、奖励函数设计、优化目标和算法方法方面与基于 LLM 的 RL 存在显著差异,因此超出了本次调查的范围。
机器人操作任务,使机器人在真实环境中解决各种操作问题,代表了具身智能最具挑战性和基础性的方面 Firoozi 等人,2025。这些任务不仅要求对视觉和文本信息有全面的理解和细粒度的运动控制,还需要物理推理、长时程规划和逻辑推理能力。利用 LLM 和 VLM 卓越的文本和视觉处理能力,一些研究已经探索将这些模型作为操作任务的核心组件,结合动作模块,例如 RobotBrain Ji 等人,2025b和 RT- 2 Zitkovich 等人,2023。
视觉- 语言- 动作模型。最近,通过统一的端到端训练将 VLM 主干与动作模块集成的视觉- 语言- 动作(VLA)模型已成为最有希望的解决方案,并成为机器人操作的主流方法 Zhong 等人,2025。当前的 VLA 模型遵循一个两阶段范式 Sapkota 等人,2025:在多模态数据(例如,Open X- Embodiment O'Neil 等人,2024)上进行预训练,然后在远程操作的机器人轨迹上进行监督微调。然而,这种模仿学习范式存在关键限制:其性能严重依赖于高质量轨迹数据,而收集这些数据既昂贵又低效,并且生成的模型对未见过的场景泛化能力差。鉴于 VLA 和 LLM 在架构、规模和方法上的相似性 Zhong 等人,2025,将 LLM 风格的强化学习方法应用于 VLA 训练为解决数据稀缺和泛化挑战提供了一个有希望的途径。
将 DeepSeek- R1 的 RL 方法应用于 VLAs 需要解决几个挑战:1) 与在单轮中完成任务的大语言模型不同,VLAs 需要多次环境交互来生成完整轨迹;2) VLA 在连续动作空间中运行;3) 传统 RL 方法依赖手工设计的流程奖励,限制了可扩展性。近期工作包括 SimpleVLA- RL SimpleVLA- RL 团队,2025,VLA- RL Lu 等人,2025c,VLA RL 泛化 Liu 等人,2025f,RIPT- VLA Tan 等人,2025a,以及 ConRFT Chen 等人,2025s 已开创性地将 DeepSeek- R1 的方法应用于 VLA 训练。
SimpleVLA- RL SimpleVLA- RL 团队,2025使 VLA 模型能够与环境交互以展开多样化的完整轨迹,采用二进制成功/失败奖励作为监督信号,并使用 GRPO 算法训练 OpenVLA- OFT Kim 等人,2025。只需一个演示轨迹,这种 RL 方法就超越了 LIBERO 和 RobotWin2.0 基准测试中的最先进 VLA 模型 π0\pi_0π0 Black 等人,2024a,实现了 SOTA 性能,并在真实机器人实验中优于高级 RDT 模型。此外,作为 π0,π0.5\pi_0, \pi_0.5π0,π0.5 Intelligence 等人的升级版本,使用来自不同场景和来源的多模态机器数据进行异构训练,允许 VLA 在通用真实世界机器人操作任务中提供一个新的里程碑。类似于 DeepSeek- R1 的"啊哈时刻",RL 训练的 VLAs 也发现了新的行为模式。VLA RL 泛化 \[Liu 等人,2025f 研究了 RL 对 VLA 泛化能力的影响,展示了在未见过的环境、物体和纹理中相对于 SFT 的显著改进,同时比较了 GRPO 和 PPO 的有效性。RIPT- VLA Tan 等人,2025a 采用 RLOO Ah- madian 等人,2024 进行 VLA RL 训练。RLinf 团队,2025h 设计了一个灵活、可扩展的 RL 框架,用于 VLA RL,统一了渲染、推理和训练,提高了 VLA 训练效率和性能。ConRFT Chen 等人,2025s 通过交替迭代训练 VLAs
RL和SFT轮次,通过多次迭代逐步提升性能。
RL的数据效率、改进的泛化能力和最小的监督需求有效地解决了VLA当前面临的数据稀缺和泛化能力差的问题。通过允许VLAs仅通过结果监督进行自主探索和学习,这种方法与复杂且昂贵的远程操作数据收集相比,大大降低了实施成本。此外,RL的数据效率消除了对大规模昂贵轨迹数据集的需求,使VLA后训练能力可扩展。
然而,当前的VLA RL研究仍然主要基于模拟。虽然SimpleVLA- RL SimpleVLA- RLTeam, 2025 通过Sim2Real迁移Chen等人,2025m,实现了现实世界的部署,但很少有工作部署物理机器人来收集现实世界的轨迹用于RL。此外,VLA RL的研究也受限于当前机器人领域强化学习的发展,包括但不限于样本效率、奖励稀疏性和sim2real。主要挑战包括物理机器人上的自主采样需要多台设备以提高效率,以及持续的手动重量和标注。
6.6.医疗任务
要点
·用于医疗LLM的RL面临独特的挑战:可验证任务允许稳定的奖励设计,而非可验证任务则使奖励定义变得困难。·可验证任务使用SFT+RL并采用基于规则的奖励;不可验证任务利用DPO、评分标准、课程RL或离线RL,尽管可扩展性和稳定性仍是开放性问题。
医疗LLM中的RL优化通常旨在提升推理和泛化能力,常采用SFT后接RL的两阶段流程。现有工作可分为基于规则的奖励的可验证问题,以及基于生成或评分标准的不可验证问题。
医疗理解。这些任务,如选择题问答、结构化预测、临床编码或视觉定位,允许使用确定性奖励,是医疗LLM中RL最成熟的领域。典型范式是SFT后接RL的两阶段流程,其中GRPO等算法直接针对基于正确性的信号优化模型。例如,HuatuoGPT- o1Chen等人,2024a通过结合医疗验证器合成可靠的推理轨迹数据,并使用SFT和RL训练模型来提升推理能力。Med- U1Zhang等人,2025l采用混合二进制正确性奖励和长度惩罚,确保准确性和格式合规,而MED- RLVRZhang等人,2025将可验证奖励应用于MCQA,提升OOD泛化能力。Open- Medical- R1Qiu等人,2025证明仔细的数据过滤提高了RL的效率。Gazal- R1Arora等人,2025设计了一个多组件奖励系统,通过GRPO优化准确率、格式合规性和推理质量,以增强医疗推理。ProMedDiing等人,2025将医疗LLM从被动范式转变为主动范式,LLM可在决策前提出临床有价值的问题,在MCTS指导的轨迹探索和RL过程中使用Shapley信息增益奖励。MedGR²Zhi等人,2025引入了一个生成式奖励学习框架,创建了一个自我改进的良性循环,共同开发数据生成器和奖励模型,以实现SFT和RL训练所需的高质量多模态医疗数据的自动创建。
超越文本问答,最近的模型将基于规则的奖励扩展到视觉和多模态任务。MedVLM- R1Pan等人,2025d采用一个RL框架,激励模型去发现
人类可解释的推理路径,而不使用任何推理参考,通过格式和准确度奖励。MedGround- R1 Xu和Nie,2025为医学图像接地任务引入了空间语义奖励,该奖励结合了空间准确度奖励和语义一致性奖励。ARMedLiu和Wei,2025通过自适应语义奖励解决开放式医学VQA中的奖励坍塌问题,该奖励在训练过程中根据历史奖励分布动态调整语义奖励。Liu和Li2025利用基于规则的格式和匹配奖励,指导结构化JSON生成,用于医学视觉信息提取,仅需100个标注样本。MMedAgent- RLXia等人,2025b是一个基于RL的多智能体框架,能够实现医疗智能体之间的动态和优化协作。MedGemmaSellergren等人,2025使用RL进行了后训练,并在MedXportQAZuo等人,2025a,上进行了进一步评估,后者是一个专家级医学多选题基准,并包含一个用于评估推理模型的子集。
对于其他临床应用,DPG- Sapphire王,2025将基于规则的奖励应用于GRPO以进行诊断相关分组。EHRMIND林和吴,2025结合SFT预热和RLVR,使用电子健康记录(EHR)数据执行复杂的临床推理任务,包括医学计算、患者试验匹配和疾病诊断。ChestX- Reasoner[Fan等人,2025e结合临床报告中的流程奖励来训练模型,使其模拟放射科医生的逐步推理。CX- Mind[Li等人,2025k]采用SFT和RL,结合格式、结果和流程奖励,训练胸部X光诊断的交错推理。为了实现基于代码的医学推理的基准测试,MedAgentGym[Xu等人,2025b]提出了一种用于医学代理代码生成的基准,并证明了RL可以提升这种推理能力。
医学生成。这些任务包括放射科报告生成Jing等人,2025,多轮临床对话Bani- Harouni,2025,治疗计划Nusrat,2025,以及诊断叙述YooseokLim,2025,这些任务缺乏唯一的真实答案。因此,基于规则的奖励不直接适用。虽然DPO已被应用于改进在偏好对齐生成任务[Yang等人,2025i,Yu等人,2025c],上的医学LLM,但大规模RL在不可验证任务上的应用正在兴起但仍然相对未被充分探索。例如,DOLANusrat,2025将LLM代理与商业治疗计划系统集成,结合一个奖励函数来指导目标覆盖和器官风险保护的权衡,以生成优化的治疗计划。LA- CDMBani- Harouni,2025提出了一种通过混合训练范式(结合监督微调和RL)训练的两代理结构,以平衡诊断准确性、不确定性校准和决策效率。在诊断对话中,PPME[Sun等人,2025i]开发了一个即插即用的框架,使用大规模EMRs和混合训练来通过专门的询问和诊断模型增强LLM交互式诊断能力。在临床决策支持中,MORE- CLEARYooseokLim,2025应用多模态离线RL到脓毒症治疗策略,改进了MIMIC- III/IV中的生存预测决策。对于放射科报告生成,BoxMed- RLJing等人,2025在其预训练阶段利用RL,使用格式奖励和交并比(IoU)奖励来确保生成的报告与像素级的解剖学证据相对应。Baichuan- M1Inc.,2025a采用三阶段RL方法:ELO(探索性似然优化)来增强思维链推理的多样性,TDPO(标记级直接偏好优化)来解决长度相关的约束,最后使用带有奖励模型反馈的PPO进行策略优化。Baichuan- M2Inc.,2025b介绍了一种新颖的动态验证框架,超越了静态答案验证器,建立了一个大规模、高保真度的交互式强化学习系统,该系统包含患者模拟器和临床评分生成器,用于模拟真实的临床环境。
总体而言,在医疗LLM中,对于可验证问题,强化学习已经非常成熟,其中确定性正确性允许基于规则的奖励和稳定的GRPO训练。相比之下,生成式任务仍然具有挑战性:当前解决方案采用基于标准的奖励、课程迁移或离线强化学习来近似质量信号。非可验证任务上可扩展强化学习的稀缺性突显了
构建可信、具备推理能力的医疗基础模型的未来关键方向。
7.未来方向
- 未来方向虽然针对大型语言模型的强化学习取得了显著进展,但许多基本挑战和机遇仍待解决。本节概述了几个有前景的方向,这些方向将塑造该领域的下一波进步。我们强调了持续强化学习在适应不断变化的数据和任务中的重要性(§ 7.1),基于记忆和基于模型的强化学习在增强推理能力方面的作用(§ 7.2 和 § 7.3),以及新兴方法在教授大型语言模型高效和潜在空间推理方面的进展(§ 7.4 和 § 7.5)。我们还讨论了在预训练期间利用强化学习的边界(§ 7.6),将强化学习应用于扩散架构(§ 7.7),以及推动科学发现的前沿(§ 7.8)。最后,我们考虑了架构-算法协同设计的挑战和前景,以满足日益庞大且高效的智能模型的需求(§ 7.9)。通过概述这些方向,我们旨在为未来大型语言模型的强化学习研究提供路线图和灵感。
7.1.持续强化学习用于大型语言模型
为了在基于强化学习的后训练过程中提升大型语言模型的多领域性能,主流方法是混合不同任务的数据并统一训练Guo等人,2025a,Yang等人,2025a。在合成数据Chen等人,2025d,Liu等人,2025g,多阶段强化学习已被证明不如混合数据训练表现好,甚至增加难度的课程学习在强化学习中可能也不是必要的Xie等人,2025c。然而,Chen等人2025d建议跨不同任务的多阶段强化学习在泛化到困难或未见过的问题上具有优势。尽管多阶段强化学习的有效性存在持续争论,但随着该领域向构建必须在动态环境中适应不断变化的数据和任务的AI系统发展,探索持续强化学习(CRL)用于大型语言模型变得必要。
与传统CRL类似,LLMs在多阶段RL训练过程中面临平衡稳定性和可塑性的基本挑战Pan等人,2025a。对于LLMs来说,可塑性可能是一个特别值得关注的问题,因为广泛使用的深度学习技术可能导致大型模型在持续学习环境中表现不如浅层网络Dohare等人,2024。CRL对LLMs的另一个挑战在于LLMs中知识和推理的交织性质,这与传统RL设置不同,在传统RL设置中,任务可以离散定义,策略可以模块化组织,例如在类似游戏的环境中Chevalier- Boisvert等人,2023,Towers等人,2024或具身场景Todorov等人,2012,Woczyk等人,2021。
传统CRL研究中的现有方法论框架为解决LLM特定需求提供了有希望的基础。传统CRL研究中的核心方法论见解,包括经验重放Berseth等人,2021,Li等人,2021,Rolnick等人,2019,策略重用Garcia和Thomas,2019,Gaya等人,2022,和奖励塑形Jiang等人,2021,Zheng等人,2022。开发针对LLMs或LRMs的专用CRL技术仍然是一个有价值的研究方向,这对于创建能够终身学习和在动态且不断变化的环境中运行的自适应和高效的AI系统至关重要。
7.2.基于记忆的强化学习用于大型语言模型
尽管在自主强化学习中,许多研究已经探索了记忆机制,从外部长期存储和插入Chhikara et al., 2025, Xu et al., 2025d, Zhong et al., 2024到内部记忆处理和工作记忆控制Yu et al., 2025b, Zhouetal., 2025i,,大多数
设计仍然针对当前任务进行定制,且泛化能力有限。正如 Silver 和 Sutton2025 强调的那样,下一代智能体将主要从经验中学习,通过持续交互获取技能。在这种精神下,一个关键方向是将智能体的记忆从特定任务的缓冲区转变为结构化、可重用、并在不同任务之间可迁移的经验库,使记忆演变为更广泛适应性和终身学习的基础。这种以经验为中心的观点也自然地与强化学习相符,因为智能体与其环境之间的交互产生的数据提供了丰富的经验轨迹,可以有效地利用。此外,尽管最近的研究已经探索了维护一个共享的经验池,以从过去的历史中检索相关策略,并将其他智能体的经验适应到新的任务场景中 Tang et al., 2025,但这一方向仍然未被充分探索。这里的核心挑战是,通过强化学习使智能体能够自动学习如何操作和管理记忆,跨任务组合和泛化经验知识。解决这一挑战对于迈向一个"经验时代"至关重要,在这个时代,集体交互轨迹成为更广泛智能体智能的基础。
7.3. 基于模型的LLM强化学习
强化学习中的一个核心挑战在于从环境中获取可扩展且鲁棒的奖励信号以及有意义的状体表示。先前工作研究了世界模型的构建 Luo等人,2024,Moerland等人,2023以向强化学习智能体提供信息丰富的状态,并且最近,LLM已被用作各种强化学习环境中的世界模型Benechehab等人,2024,Gu等人,2024,Hu和Siu,2023。在基于LLM的强化学习中,特别是对于语言智能体,构建能够准确捕获环境状态并生成可靠奖励的世界模型的能力至关重要。最近的进展表明,生成式世界模型,包括通过视频预训练增强的模型Assran等人,2025,Ball等人,2025,Bruce等人,2024,都是实用且有效的。然而,将世界模型与基于LLM的智能体的强化学习无缝集成仍然是一个开放的研究问题。因此,基于LLM的基于模型的强化学习正成为未来研究的一个特别有前景且可扩展的方向。
7.4. 教授 LRM 高效推理
推理时扩展提升了 LRM 在困难任务上的准确性,但也引入了系统性的过度思考(对简单实例进行不必要的长推理链)Chen et al., 2024b, Qu et al., 2025a, Sui et al., 2025, Yan et al., 2025b以及在激进截断下,思考不足(过早停止并依赖脆弱的捷径)Su et al., 2025b, Wang et al., 2025t。对于 RL- for- LLMs 的核心挑战是开发计算分配策略,以根据实例难度和认知不确定性调整推理的深度和停止。当前研究探索了提示中的硬编码推理级别 Agarwal et al., 2025a, Wen et al., 2025a, Zhu et al., 2025g,基于长度的自适应奖励塑形 Liu et al., 2025p, Yuan et al., 2025a,以及损失函数中使用长度惩罚 Aggarwal and Welleck, 2025, Xiang et al., 2025。
然而,将这些方法推广到基于原则的成本效益权衡仍然是一个悬而未决的问题 Gan 等人,2025。教会大型语言模型在边际效用证明其合理性时才进行更长时间的推理,仍然是语言推理中 RL 的一个核心未解决的问题。
7.5. 教授大型语言模型潜在空间推理
CoT 魏等,2022 通过提示模型阐述中间步骤来鼓励逐步推理,提高了可解释性和准确性。最近的研究将 CoT 和 RL 结合起来,以进一步提高推理质量,它在回答之前对长文本思维进行采样以进行建模
训练 郭等,2025a。然而,当前的实现通常依赖于标记级别的采样崔等,2025a,欧阳等,2022,拉菲洛夫等,2023]在一个离散的标量空间中,这可以作为瓶颈,因为在连续空间中丢失了有意义的语义信息华等,2024。最近提出的一种方法,名为潜在空间推理(LSR)阿里亚拉等,2025,盖平等,2025,郝等,2024,可能对RL优化更加友好。LSR在LLM的连续潜在空间中执行推理,促进更细致和流畅的语义推理。这一特性有助于更平滑的学习动态,并更好地与RL技术集成。RL和LSR的结合对未来开发更强大和适应性更强的推理模型具有巨大潜力。然而,评估连续潜在思维的质量比评估基于标记的思维更具挑战性。这将使提供准确的监督信号(如奖励和优势)变得更加复杂,这将成为LSR和RL结合的一个开放性挑战。
7.6. LLMs 的强化学习预训练
传统的预训练依赖于大规模文本语料库和下一词预测,并且已经证明扩展这一范式对于基础模型[Brown等人,2020,Kaplan等人,2020]的开发至关重要。现在,新兴的研究探索将强化学习更早地应用于管道中,不仅应用于后训练,还应用于预训练本身。例如,强化预训练Dong等人,2025c将下一词预测重新概念化为一个具有来自语料库的可验证奖励的强化学习问题,报告了随着可用计算资源的增加而持续增长的收益,从而将强化学习定位为一种有前景的预训练扩展策略。
同时,像avataRLtokenbender,2025这样的开放性倡议展示了仅使用强化学习从随机初始化训练语言模型,引导词级奖励并采用迭代"裁判"评分,从而展示了从零开始训练强化学习的具体路径。这与重新诞生的强化学习范式Agarwal等人,2022,一致,在该范式中,先前获得的计算知识(预训练的评论家)被利用,而不是从头开始训练。这些发展尖锐了一个实际问题:如何使强化学习风格的预训练在规模上具有成本效益?解决这一挑战可能需要减少验证者的负担以及与奖励工程相关的成本,这些成本似乎对于扩展基于强化学习的预训练至关重要。此外,这条研究路线与 §\S§ 3.1.4中引入的无监督奖励设计密切相关,提出了关于如何获得可扩展且可靠的奖励的重要问题。
7.7. 基于扩散的 LLM 的强化学习
扩散大型语言模型(DLLMs)Cheng et al., 2025c, Labs et al., 2025, Nie et al., 2025, Tae et al., 2025, Xie et al., 2025f, Ye et al., 2025c代表了一种新兴的语言生成范式。与自回归(AR)模型相比,DLLMs具有解码效率更高和通过多轮扩散实现自我纠正的更大潜力等优势。初步工作已开始探索DLLM的强化学习Borso et al., 2025, Gong et al., 2025, Yang et al., 2025d。但仍有几个关键问题尚未解决。
将RL应用于DLLM的一个核心挑战在于准确高效地估计采样响应的对数概率。这是由于自回归模型和扩散语言模型在本质上对样本似然性的建模方式存在根本差异。AR模型通过下一个词预测生成序列,并通过链式法则分解联合概率,从而实现简单的从左到右采样。然而,DLLM通过最大化证据下界(ELBO)来近似似然优化。ELBO涉及在扩散时间步长和掩码数据上的双重期望,并且通常需要大量采样才能实现准确的估计;
否则,它在偏好优化期间引入了高方差。尽管已经提出了如 Zhao等人,2025c 中的一步估计器以及 Zhu等人,2025b中的采样分配策略等方法来降低方差,但高效准确的ELBO估计仍然是策略学习中的一个开放问题。
此外,DLLM中存在多种可行的解码轨迹,为研究引入了新的维度:利用强化学习引导模型走向最优采样轨迹。这需要为中间去噪步骤设计有效的奖励函数。例如,He等人2025c将去噪表述为多步决策问题,并将奖励模型应用于中间状态,王等人,2025p提出了一种基于扩散的值模型,计算前缀条件化的逐token优势以实现轨迹级奖励,而Song等人2025c则利用基于编辑距离的奖励来最大化解码效率。未来的工作也可能从计算机视觉中为连续扩散模型开发的强化学习技术Black等人,2024b,Xue等人,2025a,Yang等人,2024b,中获得启发,从而为构建统一的多模态框架铺平道路。
7.8.基于强化学习的科学发现中的大型语言模型
近期研究表明,引入强化学习(RL)可以提高大型语言模型(LLMs)在推理密集型科学任务上的性能,在某些情况下甚至允许它们超越专门方法Fallahpour等人,2025,Fang等人,2025c,Narayanan等人,2025,Bizvi等人,2025。在生物学和化学等领域,强化学习的一个核心挑战是在大规模上执行结果验证,这一过程传统上依赖于湿实验。几种现有方法已经专注于替代或补充实验验证:Pro- 1Hla,2025使用Rosetta能量函数作为优化蛋白质稳定性的奖励函数,而rbio1Istrate等人,2025使用生物模型和外部知识源验证基因扰动结果预测。
在奖励公式化和改进预言机模型本身方面,仍有很大的探索空间。与此相关的是构建支持快速实验- 反馈循环的合适强化学习环境的更广泛问题。CoscientistBoiko等人,2023和Robin[Ghareeb等人,2025]通过实验室闭环验证获得了成功,但这种稀疏、延迟且昂贵的反馈信号不适用于直接训练底层LLM。例如,在细胞水平上的扰动响应预测Bunne等人,2024,Noutahi等人,2025,的实验环境计算机模拟代表了一条潜在的解决路径。然而,由于范围有限以及严重缺乏准确性和泛化能力ahlmann- Eltze等人,2025,Kedzierska等人,2023,许多此类系统远不足以替代真实的实验室环境。其他研究路线探索将特定领域的模型纳入LLM训练以处理科学数据Fallahpour等人,2025以及开发能够执行一系列明确定义任务的通用模型[Bigaud等人,2025,Narayanan等人,2025]。这些方向,加上强化学习方法的进步,将继续扩展LLM的应用场景,从狭义定义的任务扩展到与开放式目标的复杂交互,使它们能够更实质性地贡献于新的发现。
7.9.架构-算法协同设计中的RL
目前用于LLM的RL管道大多假设使用密集TransformerVaswani等人,2017或专家混合(MoE)Dai等人,2024,Jiang等人,2024,Shazeer等人,2017骨干,优化几乎完全与任务精度挂钩的奖励。结果,架构自由度和它们对硬件的影响被留在了学习循环之外。同时,一种新的硬件和架构协同设计浪潮已经出现(例如,与硬件对齐的稀疏注意力,如
DeepSeek 的 NSA Yuan 等人, 2025b 和模型- 系统协同设计在 Step- 3 Wang 等人, 2025a, 表明通过使模型结构与计算基座对齐, 可以实现更高的效率和功能。
我们主张, 在强化学习中将架构作为一级动作空间, 对下一代LLM来说代表着一个开放且高影响力的挑战。例如, 增强型MoE方法可以支持模型在学习过程中学习路由策略、专家激活、容量分配或稀疏模式, 不仅优化任务奖励, 还优化与硬件相关的目标, 如延迟、内存流量、能耗和激活预算。在这种框架下, 强化学习被赋予的任务不仅是跨越标记 Guo 等人, 2025a, 进行"推理", 还包括跨越参数和模块, 动态调整模型的拓扑结构以适应每个提示的难度和实时计算约束。这种观点超越了经典的基于强化学习的神经架构搜索 (NAS) Zoph和Le, 2016, 后者通常为给定任务或数据集找到一个固定的架构。相比之下, 增强型MoE专注于在推理过程中 Han 等人, 2021, 针对每个输入优化路由和模块化适应, 从而可能实现更高的效率和灵活性。关键的开题包括设计稳健的多目标奖励函数以避免平凡解(例如, 全专家稀疏性)、在架构动作修改网络拓扑时实现稳定的归因, 以及跨提示、任务和部署规模摊销架构策略学习。解决这些挑战对于在未来的LLM中实现真正集成的架构- 算法协同优化至关重要。
8. 结论
我们调查了最近在用于LRMs的强化学习(RL)方面的进展, 特别强调推理, 有效地将LLMs转换为LRMs。与主要为人类对齐而设计的先前方法(如RLHF或DPO)不同, 我们的重点是用于LLMs的RLVR。RLVR通过提供直接的结果级奖励来增强LLMs的推理能力。首先, 我们介绍了RLVR的核心组件, 包括奖励设计、策略优化和采样策略。我们总结了每个部分的多项研究方向和现有工作。然后我们讨论了在用于LLMs的RL训练中最具争议的几个问题。此外, 我们介绍了用于LLMs的RL的训练资源, 涵盖静态数据集、动态环境和RL基础设施。最后, 我们回顾了在各种场景下RL在LLMs中的下游应用, 并强调了几个有前景的研究方向, 旨在通过基于RL的LLMs实现超智能。