目录
项目背景
在社交媒体时代,用户评论中蕴含着丰富的情感信息。对微博评论进行情感分析,能够帮助企业了解用户态度、监测舆情动向。本文将详细介绍一个微博评论情感分析项目的预处理流程,包括词表构建、文本预处理和数据集划分等关键步骤。
项目目标
本项目旨在实现对微博评论的情感自动识别,核心任务包括:
- 将每条评论内容转换为固定长度的词向量
- 建立情感分析模型,实现对评论情绪状态的自动分类
关键技术问题
在开始编码前,我们需要解决几个关键问题:
- 词向量维度:每个词 / 字转换为 200 维的词向量
- 固定长度处理:统一每条评论的长度为 32 个词 / 字
- 长评论处理:超过 32 个词 / 字的评论,截断后面的内容
- 短评论处理:不足 32 个词 / 字的评论,使用<PAD>填充
- 词表压缩:选择频率较高的 4760 个词 / 字构建词表
- 低频词处理:低频词和未登录词统一用<UNK>替代
项目实施步骤
第一步:读取文件,建立词表
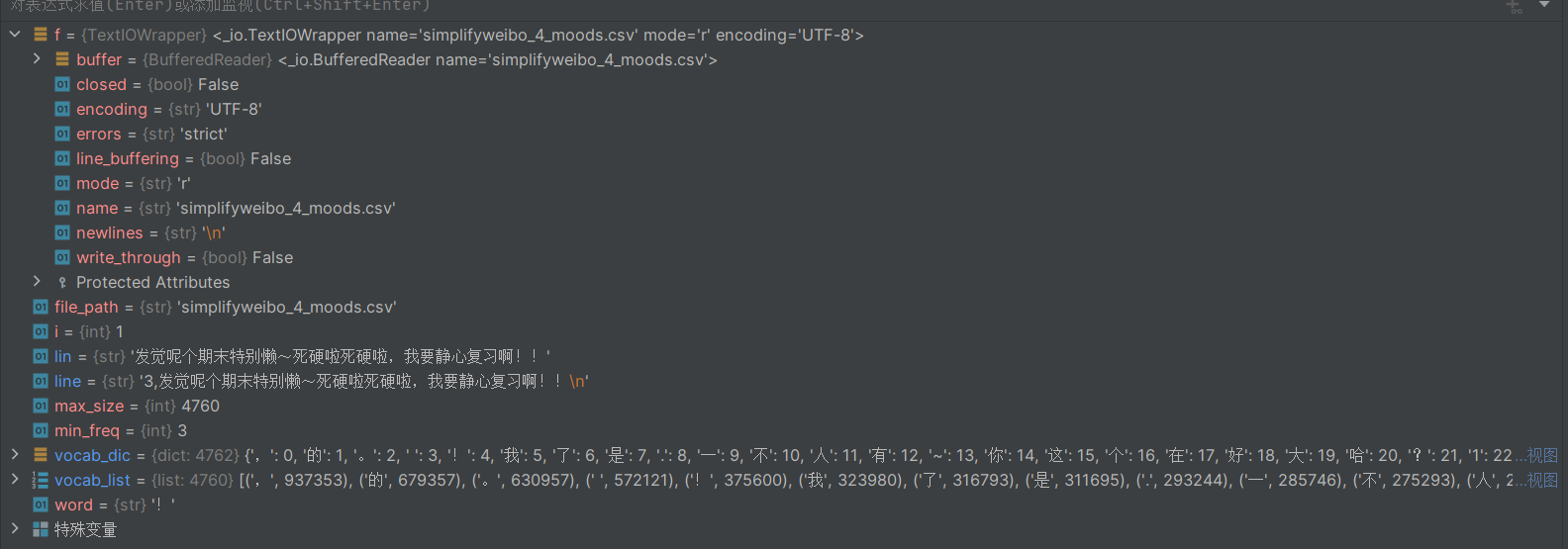
词表是连接原始文本和模型输入的桥梁,我们需要从语料中统计出现频率较高的字,构建一个实用的词表。
创建vocab_create.py文件,代码如下:
python
from tqdm import tqdm # 导入进度条函数
import pickle as pkl # 将序列化对象保存为二进制字节流文件
MAX_VOCAB_SIZE = 4760 # 词表长度限制,选择4760个高频字
UNK, PAD = '<UNK>', '<PAD>' # 未知字和padding符号
def build_vocab(file_path, max_size, min_freq):
"""基于文本内容建立词表vocab"""
# 定义分字函数,将字符串拆分为单个字符的列表
tokenizer = lambda x: [y for y in x]
vocab_dic = {} # 用于保存字及其出现次数的字典
with open(file_path, 'r', encoding='UTF-8') as f:
i = 0
# 逐行读取文件内容,并显示循环进度条
for line in tqdm(f):
if i == 0: # 跳过文件第一行表头
i += 1
continue
# 提取评论内容,剔除标签和逗号
lin = line[2:].strip()
if not lin: # 跳过空行
continue
# 遍历每个字,统计出现次数
for word in tokenizer(lin):
# 字典的get方法:如果word存在则返回其值,否则返回0
vocab_dic[word] = vocab_dic.get(word, 0) + 1
# 筛选词频大于min_freq的字,并按词频降序排列,取前max_size个
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq],
key=lambda x: x[1], reverse=True)[:max_size]
# 为每个字分配索引
vocab_dic = {word_count[0]: idx for idx, word_count in enumerate(vocab_list)}
# 添加未知字和padding符号的索引
vocab_dic.update({UNK: len(vocab_dic), PAD: len(vocab_dic) + 1})
# 保存词表供后续使用
pkl.dump(vocab_dic, open('simplifyweibo_4_moods.pkl', 'wb'))
print(f'词表大小: {len(vocab_dic)}')
return vocab_dic
if __name__ == '__main__':
# 构建词表,最小词频设为1
vocab = build_vocab('simplifyweibo_4_moods.csv', MAX_VOCAB_SIZE, 1)代码解析
上述代码的核心逻辑在build_vocab函数中,主要完成以下工作:
- 分字处理:使用 lambda 表达式定义了一个简单的分字函数,将每个评论拆分成单个字符
- 词频统计:遍历所有评论,统计每个字出现的次数
- 筛选高频字:只保留出现频率大于 min_freq 的字,并按词频降序排列
- 构建词表:为筛选后的字分配唯一索引,并添加<UNK>和<PAD>两个特殊符号
- 保存词表:使用 pickle 将词表保存为二进制文件,方便后续加载使用
其中,这行代码是核心筛选逻辑:
python
vocab_list = sorted([_ for _ in vocab_dic.items() if _[1] > min_freq],
key=lambda x: x[1], reverse=True)[:max_size]可以拆分为更易理解的形式:
python
vocab_list = []
# 筛选出词频大于min_freq的字
for a in vocab_dic.items():
if a[1] > min_freq:
vocab_list.append(a)
# 按词频降序排列
vocab_list = sorted(vocab_list, key=lambda x: x[1], reverse=True)
# 取前max_size个高频字
vocab_list = vocab_list[:max_size]运行该脚本后,会生成simplifyweibo_4_moods.pkl文件,包含了我们构建的词表。
运行结果如下:

第二步:评论预处理与数据集划分
接下来,我们需要对原始评论进行预处理(截断、填充等),并将数据集划分为训练集、验证集和测试集。
创建load_dataset.py文件,代码如下:
python
from tqdm import tqdm
import pickle as pkl
import random
import torch
UNK, PAD = '<UNK>', '<PAD>' # 未知字,padding符号
def load_dataset(path, pad_size=32):
"""
加载数据集并进行预处理
path: 文件路径
pad_size: 评论固定长度
"""
contents = [] # 存储处理后的数据集
# 加载之前创建的词表
vocab = pkl.load(open('simplifyweibo_4_moods.pkl', 'rb'))
# 分字函数
tokenizer = lambda x: [y for y in x]
with open(path, 'r', encoding='utf8') as f:
i = 0
for line in tqdm(f): # 逐行处理
if i == 0: # 跳过表头
i += 1
continue
if not line: # 跳过空行
continue
# 提取标签和评论内容
label = int(line[0]) # 评论标签(情感类别)
content = line[2:].strip('\n') # 评论内容
words_line = [] # 存储评论中每个字对应的索引
token = tokenizer(content) # 分字处理
seq_len = len(token) # 评论原始长度
# 处理评论长度,统一为pad_size
if pad_size:
if len(token) < pad_size:
# 不足pad_size,用PAD填充
token.extend([PAD] * (pad_size - len(token)))
else:
# 超过pad_size,截断
token = token[:pad_size]
seq_len = pad_size
# 将每个字转换为对应的索引
for word in token:
# 如果字不在词表中,用UNK的索引替代
words_line.append(vocab.get(word, vocab.get(UNK)))
# 保存处理结果:(字索引列表, 标签, 原始长度)
contents.append((words_line, int(label), seq_len))
# 随机打乱数据集
random.shuffle(contents)
# 划分训练集(80%)、验证集(10%)、测试集(10%)
train_data = contents[:int(len(contents)*0.8)]
dev_data = contents[int(len(contents)*0.8):int(len(contents)*0.9)]
test_data = contents[int(len(contents)*0.9):]
return vocab, train_data, dev_data, test_data
if __name__ == '__main__':
vocab, train_data, dev_data, test_data = load_dataset('simplifyweibo_4_moods.csv')
print(f"训练集大小: {len(train_data)}")
print(f"验证集大小: {len(dev_data)}")
print(f"测试集大小: {len(test_data)}")
print("数据处理完成!")
代码解析
load_dataset函数主要完成以下工作:
- 加载词表:读取之前保存的词表文件
- 文本预处理 :
- 提取每条评论的标签和内容
- 对评论进行分字处理
- 统一评论长度:短评论用<PAD>填充,长评论截断
- 字转索引:将每个字转换为词表中对应的索引,未登录词用<UNK>的索引
- 数据集划分:按照 8:1:1 的比例将数据集划分为训练集、验证集和测试集
- 随机打乱:打乱数据集顺序,避免模型学习到数据顺序规律
总结与后续工作
本文介绍了微博评论情感分析项目的预处理阶段,包括词表构建和文本预处理两个关键步骤。通过这些步骤,我们将原始的文本数据转换为模型可以处理的数字形式,为后续的模型训练奠定了基础。
后续工作将包括:
- 加载腾讯预训练词向量,并转换为 200 维
- 构建情感分析模型(如 LSTM、CNN 等)
- 模型训练与评估
- 模型优化与部署
通过这些步骤,我们可以构建一个能够自动识别微博评论情感的模型,为舆情分析提供有力支持。