线性回归是机器学习中最基础且重要的算法之一,它通过寻找特征与目标之间的线性关系来进行预测。本文将通过银行贷款的实例,带你全面理解线性回归的数学原理和实现方法。
一个实际例子:银行贷款预测
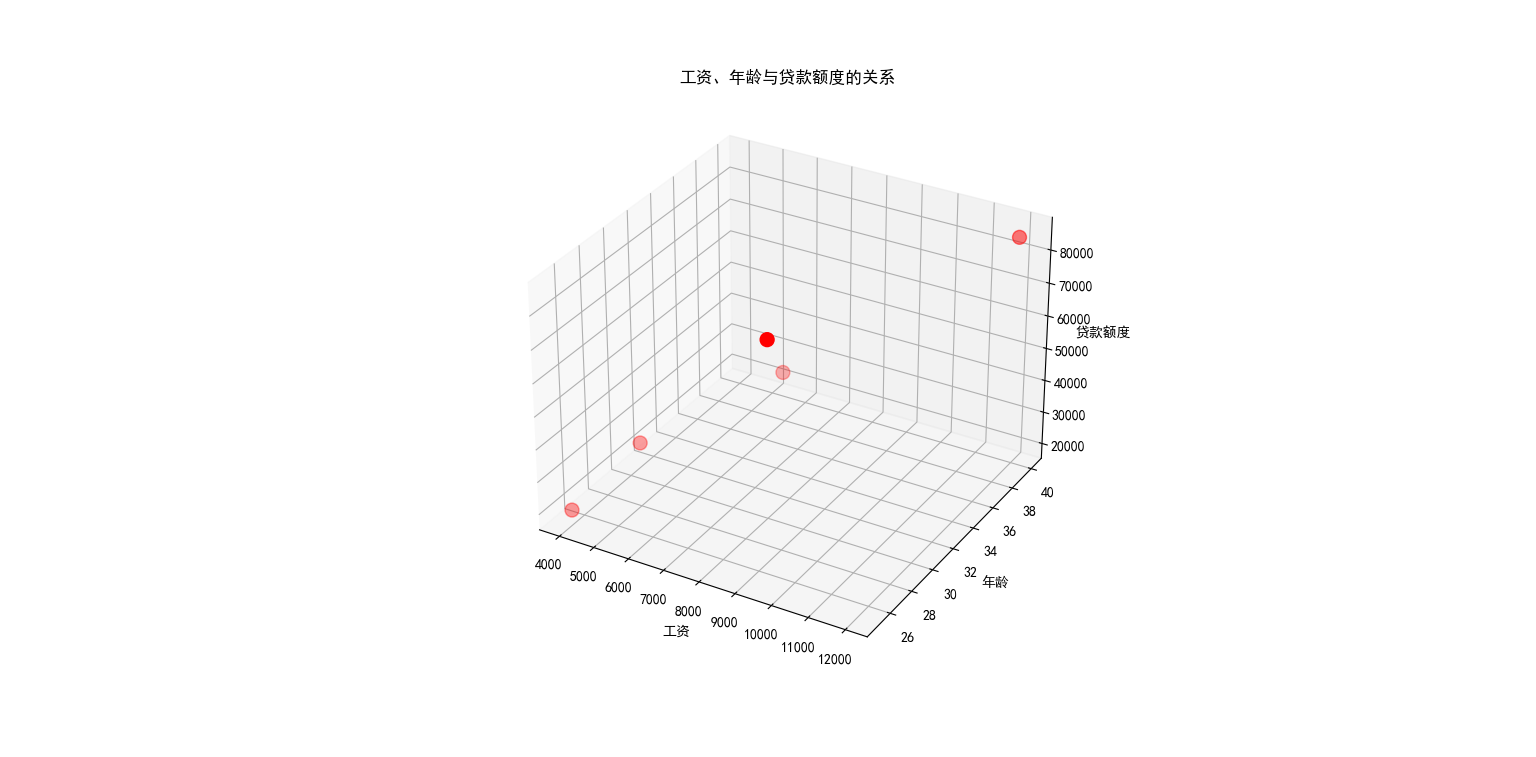
假设银行在决定贷款额度时主要考虑两个因素:工资 和年龄:
| 工资 | 年龄 | 额度 |
|---|---|---|
| 4000 | 25 | 20000 |
| 8000 | 30 | 70000 |
| 5000 | 28 | 35000 |
| 7500 | 33 | 50000 |
| 12000 | 40 | 85000 |
我们的目标是建立一个模型,根据工资和年龄预测银行会贷款多少钱。
线性回归模型
基本概念
线性回归假设目标变量(贷款额度)与特征变量(工资、年龄)之间存在线性关系:
hθ(x)=θ0+θ1x1+θ2x2h_\theta(x) = \theta_0 + \theta_1 x_1 + \theta_2 x_2hθ(x)=θ0+θ1x1+θ2x2
其中:
- θ0\theta_0θ0 是偏置项(截距)
- θ1\theta_1θ1 是工资的参数(权重)
- θ2\theta_2θ2 是年龄的参数(权重)
- x1x_1x1 是工资特征
- x2x_2x2 是年龄特征
用矩阵形式表示为:
hθ(x)=∑i=0nθixi=θTxh_\theta(x) = \sum_{i=0}^n \theta_i x_i = \theta^T xhθ(x)=i=0∑nθixi=θTx
误差与概率解释
为什么会有误差?
在现实中,预测值几乎不可能完全等于真实值:
y(i)=θTx(i)+ε(i) y^{(i)} = \theta^T x^{(i)} + \varepsilon^{(i)} y(i)=θTx(i)+ε(i)
其中 ε(i)\varepsilon^{(i)}ε(i) 表示误差。
误差的高斯分布假设
我们假设误差服从均值为0、方差为 σ2\sigma^2σ2 的高斯分布:
p(ϵ(i))=12πσexp(−(ϵ(i))22σ2) p(\epsilon^{(i)}) = \frac{1}{\sqrt{2\pi\sigma}} \exp\left(-\frac{(\epsilon^{(i)})^2}{2\sigma^2}\right) p(ϵ(i))=2πσ 1exp(−2σ2(ϵ(i))2)
这个假设很合理:银行可能会多给或少给贷款,但绝大多数情况下浮动不会太大,符合正常业务逻辑。
将预测公式代入得到:
p(y(i)∣x(i);θ)=12πσexp(−(y(i)−θTx(i))22σ2) p(y^{(i)}|x^{(i)};\theta) = \frac{1}{\sqrt{2\pi\sigma}} \exp\left(-\frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2}\right)p(y(i)∣x(i);θ)=2πσ 1exp(−2σ2(y(i)−θTx(i))2)
最大似然估计
似然函数
我们希望找到使观测数据出现概率最大的参数:
L(θ)=∏i=1mp(y(i)∣x(i);θ)=∏i=1m12πσexp(−(y(i)−θTx(i))22σ2) L(\theta) = \prod_{i=1}^m p(y^{(i)} | x^{(i)}; \theta) = \prod_{i=1}^m \frac{1}{\sqrt{2\pi\sigma}} \exp\left(-\frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2}\right) L(θ)=i=1∏mp(y(i)∣x(i);θ)=i=1∏m2πσ 1exp(−2σ2(y(i)−θTx(i))2)
对数似然
为了计算方便,取对数将乘法转换为加法:
logL(θ)=log∏i=1m12πσexp(−(y(i)−θTx(i))22σ2)\log L(\theta) = \log \prod_{i=1}^m \frac{1}{\sqrt{2\pi\sigma}} \exp\left(-\frac{(y^{(i)} - \theta^T x^{(i)})^2}{2\sigma^2}\right) logL(θ)=logi=1∏m2πσ 1exp(−2σ2(y(i)−θTx(i))2)
展开化简后:
logL(θ)=mlog12πσ−1σ2⋅12∑i=1m(y(i)−θTx(i))2\log L(\theta) = m \log \frac{1}{\sqrt{2\pi\sigma}} - \frac{1}{\sigma^2} \cdot \frac{1}{2} \sum_{i=1}^m (y^{(i)} - \theta^T x^{(i)})^2logL(θ)=mlog2πσ 1−σ21⋅21i=1∑m(y(i)−θTx(i))2
最小二乘法
最大化似然函数等价于最小化:
J(θ)=12∑i=1m(y(i)−θTx(i))2 J(\theta) = \frac{1}{2} \sum_{i=1}^m (y^{(i)} - \theta^T x^{(i)})^2J(θ)=21i=1∑m(y(i)−θTx(i))2
这就是著名的最小二乘法
参数求解方法
1. 直接求解(正规方程)
对目标函数求导并令导数为零:
J(θ)=12(Xθ−y)T(Xθ−y) J(\theta) = \frac{1}{2} (X\theta - y)^T (X\theta - y)J(θ)=21(Xθ−y)T(Xθ−y)
求偏导:
∇θJ(θ)=XTXθ−XTy \nabla_\theta J(\theta) = X^T X\theta - X^T y ∇θJ(θ)=XTXθ−XTy
令偏导等于0,得到解析解:
θ=(XTX)−1XTy \theta = \left( X^T X \right)^{-1} X^T y θ=(XTX)−1XTy
2. 梯度下降法
当数据量很大时,直接求逆矩阵计算代价高昂,我们使用迭代方法。
目标函数
J(θ)=12m∑i=1m(hθ(xi)−yi)2 J(\theta) = \frac{1}{2m} \sum_{i=1}^{m} (h_\theta(x^i) - y^i)^2 J(θ)=2m1i=1∑m(hθ(xi)−yi)2
批量梯度下降
∂J(θ)∂θj=1m∑i=1m(hθ(xi)−yi)xji \frac{\partial J(\theta)}{\partial \theta_j} = \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^i) - y^i) x_j^i ∂θj∂J(θ)=m1i=1∑m(hθ(xi)−yi)xji
θj:=θj−α1m∑i=1m(hθ(xi)−yi)xji \theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^{m} (h_\theta(x^i) - y^i) x_j^i θj:=θj−αm1i=1∑m(hθ(xi)−yi)xji
随机梯度下降
θj:=θj−α(hθ(xi)−yi)xji \theta_j := \theta_j - \alpha (h_\theta(x^i) - y^i) x_j^iθj:=θj−α(hθ(xi)−yi)xji
每次使用一个样本更新参数,速度快但波动大。
小批量梯度下降
θj:=θj−α1b∑k=ii+b−1(hθ(x(k))−y(k))xj(k) \theta_j := \theta_j - \alpha \frac{1}{b} \sum_{k=i}^{i+b-1} (h_\theta(x^{(k)}) - y^{(k)}) x_j^{(k)} θj:=θj−αb1k=i∑i+b−1(hθ(x(k))−y(k))xj(k)
折中方案,每次使用小批量样本。
总结
线性回归的核心思想可以概括为:
- 模型假设:目标与特征之间存在线性关系
- 误差建模:假设误差服从高斯分布
- 最大似然:通过最大似然估计推导出最小二乘法
- 参数求解:可以通过正规方程直接求解或梯度下降迭代求解
线性回归虽然简单,但它包含了机器学习的基本思想:建立模型、定义损失函数、优化参数。理解线性回归为进一步学习更复杂的机器学习算法奠定了坚实的基础。
在实际应用中,我们还需要考虑特征缩放、正则化、多项式特征等技巧来提升模型性能,这些都是在掌握了线性回归基本原理后的自然延伸。