| 序号 | 属性 | 值 |
|---|---|---|
| 1 | 论文名称 | RDT-1B |
| 2 | 发表时间/位置 | 2025 |
| 3 | Code | RDT-1B: a Diffusion Foundation Model for Bimanual Manipulation |
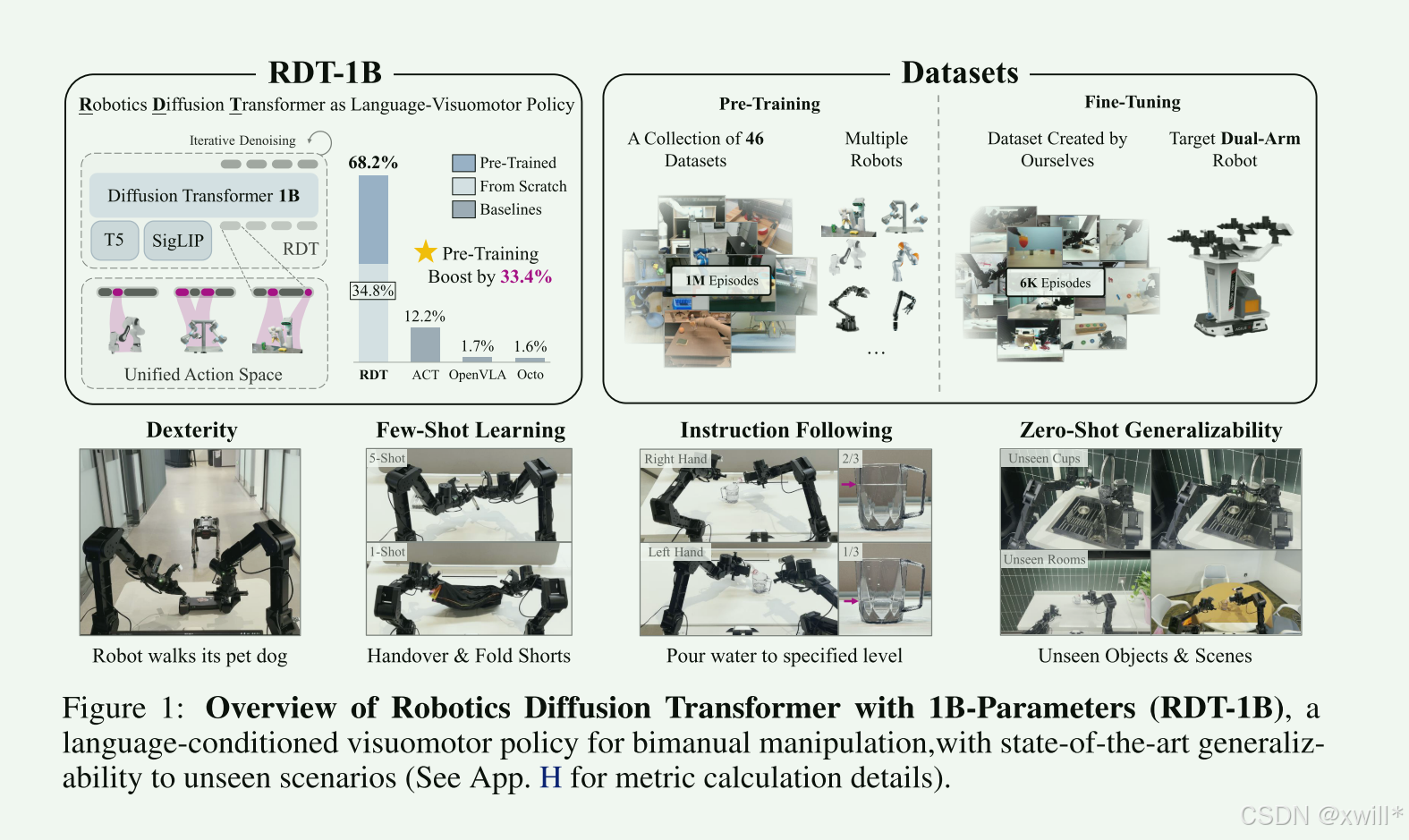
| 4 | 创新点 | 1:数据层面提出物理可解释的统一动作空间 (Physically Interpretable Unified Action Space) 以前为了训练大模型,必须把不同机器人(Franka, UR5, Aloha)的数据强行归一化,导致丢失物理意义,且难以兼容。本文设计了一个包含所有主流机械臂物理量(关节角、末端位置、力矩等)的超大向量空间。像"填空题"一样,机器人A填位置槽,机器人B填关节槽,其余补零。有效的保留了物理含义。模型学到的是通用的物理规律(如重力、惯性),而不是无意义的数字。这使得 RDT 可以利用 46+ 个异构数据集(21TB)进行预训练。 2:架构层面 (The "RDT Model"),基于DIT进行了如下的改进 RMSNorm & QKNorm (为了稳定): 机器人传感器数据数值范围波动极大,且不需要像图像那样做中心化。用 RMSNorm (不减均值,只做缩放)保持物理对称性;用 QKNorm 稳定注意力计算。 防止梯度爆炸,训练更稳定。 **MLP Decoder (为了非线性):**机器人的动力学是非常复杂的非线性系统,线性层(Linear)拟合不了。引入MLP Decoder增强模型对复杂动作的表达能力。 **交替条件注入 (Alternating Condition Injection, ACI):**图像 Token 太多,文本 Token 太少。同时输入会导致文本被淹没,机器人"听不见"指令。通过交替条件注入,让模型这一层听图像的,下一层听文本的,轮流进行,保证指令遵循能力。 **采用扩散模型建模p(action∣obs) 分布,而不是回归均值。**完美解决了双手操作中"左手先还是右手先"的多解问题,避免了动作冲突和平均化。 为了解决双臂数据少,搞了个物理统一空间吃百家饭;为了解决动作复杂,用了 DiT 架构但改了 Normalization 和 Decoder;为了听懂人话,让图像文本轮流注入。最终练出了个 12亿参数、能举一反三的大模型。 |
| 5 | 引用量 | 数据设置一个很大的空间,有数据就填上,没有就置0。从而保证能够实现不同类型数据的使用。 |
一:提出问题
双臂机器人的操作比较复杂,而且训练数据稀缺。本文提出了针对双臂机器人的 Robotics Diffusion Transformer (RDT)。双臂机器人主要存在以下两点困难的地方:
-
多模态动作分布 (Multi-modal action distributions): 这里的"多模态"不是指图像/文本,而是指统计学上的分布。对于同一个任务(比如"叠衣服"),双手配合的方式有无数种(先左后右、同时动作、左手扶右手折等)。传统的回归模型(Predicting Mean/Average)往往会预测出一个"平均动作",导致两个手"打架"或者停在半空。
-
数据稀缺 (Scarcity of training data): 相比于互联网上的文本数据,双臂机器人的高质量操作数据非常少,且采集成本高昂。
为了解决上述问题,作者提出了 RDT,结合了两个强力工具:
-
Diffusion Model (扩散模型): 就像生成图片一样(Stable Diffusion),扩散模型非常擅长生成"分布"。**它不是预测一个确定的动作,而是通过去噪过程生成一个合理的动作序列。**这完美解决了"双手协调"中的多模态分布问题,防止动作僵硬或冲突。
-
Transformer: 用于处理序列数据和大规模输入。机器人的传感器数据是异构的(图像、关节角度、力反馈、文本指令),Transformer 强大的注意力机制可以很好地融合这些信息,并捕捉高频信号中的非线性特征。
提出了物理可解释的统一动作空间,解决 "想用海量数据,但不同机器人的数据格式不一样" 的问题。(这就很像HPT了)
网上有很多单臂、双臂、不同品牌机器人的数据。有的控制位置(Position),有的控制扭矩(Torque),有的控制速度(Velocity)。直接混在一起训练,模型并不会取得理想的效果。 作者没有简单地把所有数据归一化成一个抽象的数字,而是设计了一个空间,既能统一格式 ,又能保留物理含义 。这意味着模型能理解"这代表力"或"这代表速度"。这使得模型学到的"物理知识"可以迁移(Transferable),比如学会了用力推门,换个机器人它依然知道要用力。
RDT模型具有12亿参数。虽然在LLM(如GPT-4)面前这很小,但在机器人操作策略(Policy)领域,这属于巨型模型。作者使用了"迄今为止最大的多机器人数据集"进行预训练(Pre-training),让模型见多识广;然后用高质量的"自建双手数据集"(6000+条)进行微调(Fine-tuning),让模型专精于双手操作。
用扩散模型解决动作生成的多样性,用Transformer解决数据处理的规模化,用统一动作空间解决跨机器人数据的鸿沟。
1 动机与背景
大家都知道双手操作很重要,但现在的机器人太"笨"了,要么只能做特定动作(Primitives),要么只能在特定环境里动。我们想要一个像 GPT 或 Stable Diffusion 那样的"基础模型(Foundation Model)",通吃各种任务。那么模仿学习(Imitation Learning)+ 大规模数据是一个可行的解决方案。
2遇到的问题
数据太少(Data Scarcity): 双臂机器人很贵,数据很难通过单一实验室收集。
解决方案:跨机器人学习(Cross-robot Pretraining)。 既然双臂数据少,那我就把单臂的、别的品牌机器人的数据都拿来用。但这引出了新的问题:
问题1:多模态分布(Multi-modal Distribution)。 两个手配合的方式太多了,数据分布极其复杂。
问题2:异构性与负迁移(Heterogeneity & Negative Transfer)。
- "负迁移" 是迁移学习中的一个概念。如果你强行把A机器人的经验用在B机器人上,但两者结构不同(比如A的关节向左转是正数,B是负数),模型不仅学不会,反而会变笨。以前的方法为了避免这个问题,往往会扔掉很多数据,或者只保留最简单的特征,这就浪费了数据的潜力。
3 解决方案:RDT
为了解决上述问题,作者提出了 RDT,主要包含三个核心设计:
一:Diffusion Transformer (DiT)
为什么用 Diffusion? 解决"多模态分布"。它能生成复杂的动作分布,而不是只预测一个平均值。 为什么用 Transformer? 解决"可扩展性(Scalability)"。它能吃进海量数据,且参数量可以堆得很大(1.2B)。
DiT 是最近生成式 AI 领域(如 Sora)的核心架构,这里被搬到了机器人领域。
二:针对机器人特性的架构修改
机器人数据和图像不一样。图像是平滑的,机器人传感器数据是高频的、非线性的、数值范围乱跳的。MLP 解码(更适合处理具体数值)、改进归一化(防止数值爆炸)、条件交替注入(更好地理解语言指令)。
三:物理可解释的统一动作空间
这是解决"跨机器人数据异构"的关键。作者没有把数据变成抽象的 Latent Vector(潜变量),而是保留了物理意义(位置、角度、力矩)。这样模型学到的是物理规律(Physics),而不是死记硬背的数据,从而实现了真正的"泛化"。
二:解决方案
本文选择ALOHA (因为便宜,配套齐全)。
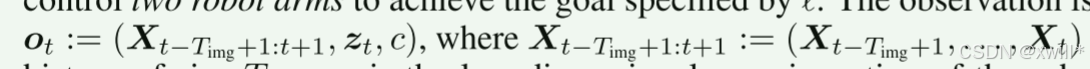
给定一个语言指令 ℓ,策略(Policy)在时间步 t∈N+ 接收一个观测值 ot;然后产生一个动作 at来控制两个机械臂以完成 ℓ指定的目标。观测值表示为一个三元组 ot:=(Xt−Timg+1:t+1,zt,c)。其中:X是长度为 Timg 的 RGB 图像观测历史;zt是机器人的低维本体感觉(Proprioception,如关节角度等);c是控制频率。动作 at通常是期望的下一时刻本体感觉 zt+1的一个子集。
我们注意到,注意观测值 ot 里包含了一个 c(Control Frequency)。这其实就是解决多机器人数据的一个关键。
机器人A可能每秒采样10次 (10Hz),机器人B可能每秒采样50次 (50Hz)。
如果不告诉模型这个频率,模型会很困惑:为什么同样的动作,A机器人只需几步,B机器人要走几十步?
把 c 作为输入,等于告诉模型:"注意了,现在的时间流速不一样"。这是处理异构数据的一个小技巧。
很多人看到"用多机器人数据训练",以为作者要做一个通用的"大脑",插到任何机器人上都能用,实际上作者目标是让 ALOHA 这个双臂机器人变得更强。用别的机器人的数据,是为了让 ALOHA 见多识广,学会通用的物理规律(比如重力、摩擦力、物体抓取点),最终是为了提升 ALOHA 的泛化能力。
就像培养一个网球运动员(ALOHA),我让他去看羽毛球、乒乓球的录像(其他机器人数据)。我的目的不是让他去打羽毛球,而是通过看别人的运动,领悟通用的"挥拍发力"技巧,从而把网球打得更好。
多模态和异构性是目前存在的两个关键的挑战:How to design a powerful architecture? How to train on heterogeneous data?
1:机器人扩散 Transformer (ROBOTICS DIFFUSION TRANSFORMER)
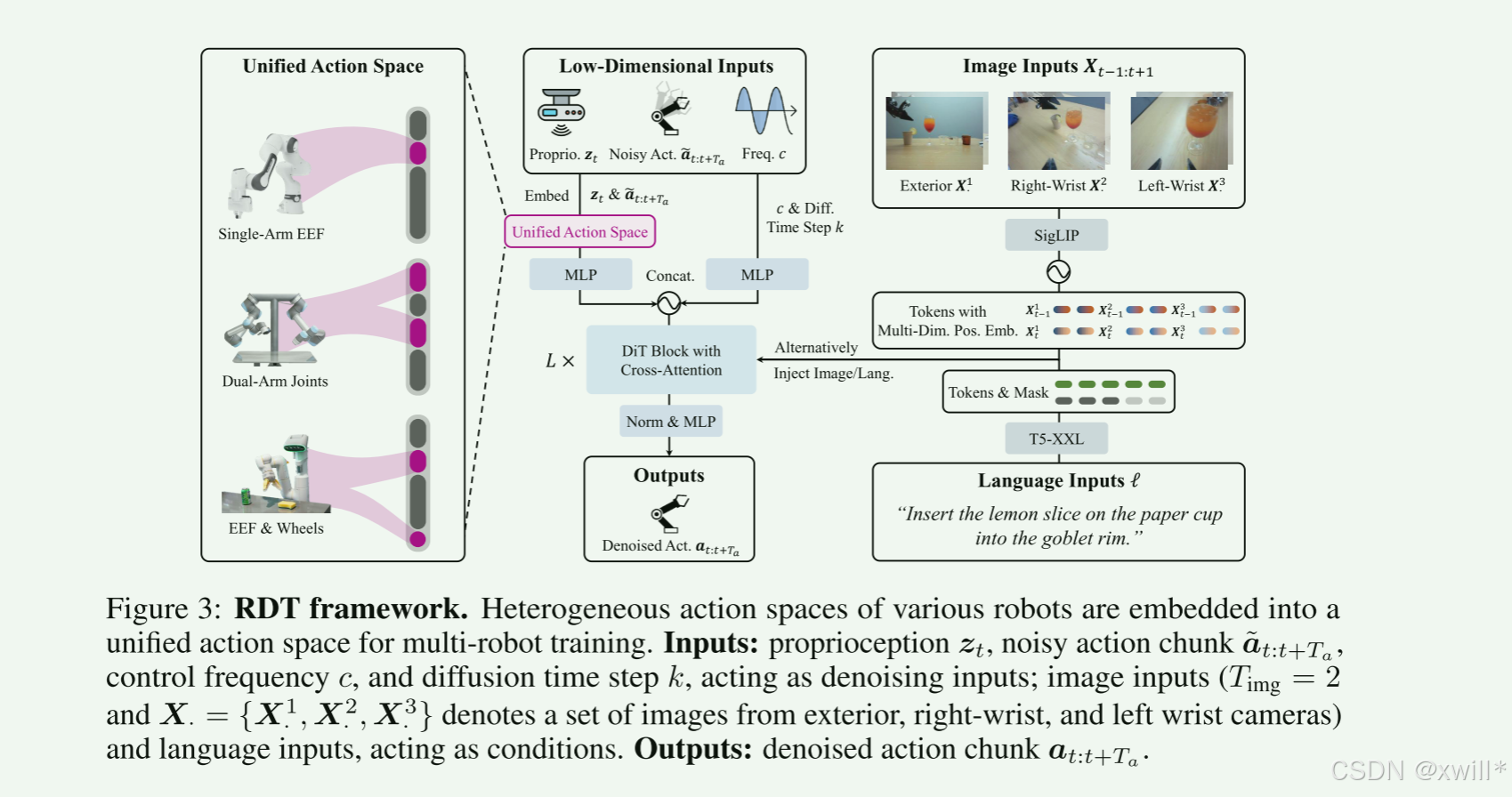
(1)RDT 模型
机器人动作不是单一的。面对"把杯子拿起来"这个指令,并没有唯一的"标准答案"。因此使用Diffusion策略是一个比较合适的解决方案。
-
Regression (回归): 试图找平均值。如果数据里有人左手拿,有人右手拿,回归模型会预测"双手各伸一半",导致任务失败。
-
Diffusion (扩散): 学习的是概率分布 p(action∣condition)。它能理解"有30%概率左手拿,70%概率右手拿",生成的动作是连贯的、合理的。
而动作生成采用动作块的方式,以保证生成动作的连续性(Action Chunking (动作块))。这是一个非常重要的工程技巧。模型不是预测"下一步动作",而是预测"未来 Ta 步的动作序列"。这样做可以使动作更平滑,且推理频率可以降低(比如推理一次管 0.5 秒),解决了扩散模型推理慢的问题。
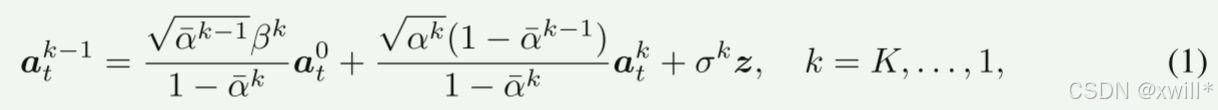
当使用扩散策略做决策时,首先采样一个完全噪声化的动作 atK∼N(0,I),然后执行 K∈N+步去噪步骤,将其去噪为来自p(at∣ℓ,ot)
的干净动作样本 at0。
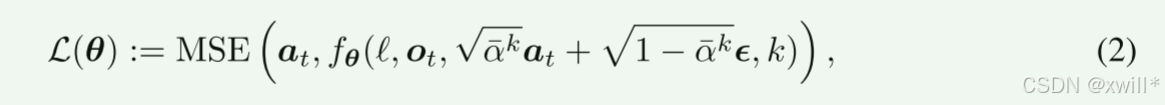
然而,在采样完成之前,at0是难以处理的。我们选择使用参数为 θ 的可学习去噪网络 fθ 从噪声样本中估计干净样本at0←fθ(ℓ,ot,atk,k)。为了训练这样一个网络,作者将最小化上边去噪均方误差 (MSE)
1.1针对模型训练,作者也并没有从头开始训练,而是基于已经预训练好的模型。
-
眼睛 (Vision): 用 SigLIP。这是一个比 CLIP 更强的视觉编码器,能理解图像语义。
-
大脑 (Language): 用 T5-XXL。这是一个超大的语言模型,能深刻理解复杂的自然语言指令。
-
身体 (Proprioception): 用简单的 MLP。因为关节角度这些数据虽然简单,但频率高、变化快,MLP 反而比大模型更敏感。
-
**防作弊机制 (Masking):**机器人可能发现"只看第三视角的相机就能猜到大概动作",于是就忽略了手腕上的相机。但在精细操作时,手腕相机至关重要。
- 解决: 训练时随机遮住某个相机的数据,强迫模型学会利用所有可用的传感器,不能偷懒。
1.2Key Modifications:为了更好的适应于机器人任务,本文做了如下的改进:
一:RMSNorm & QKNorm (为了稳定)
机器人传感器的数据范围很乱(有的传感器是 0.001,有的是 1000),直接训练会导致梯度爆炸(NaN Loss)。而且,标准 LayerNorm 会把数据减去均值(Centering),但这对于物理数据来说,可能改变了它的物理意义(比如把"速度10"归一化成了"速度0")。
解决方案:
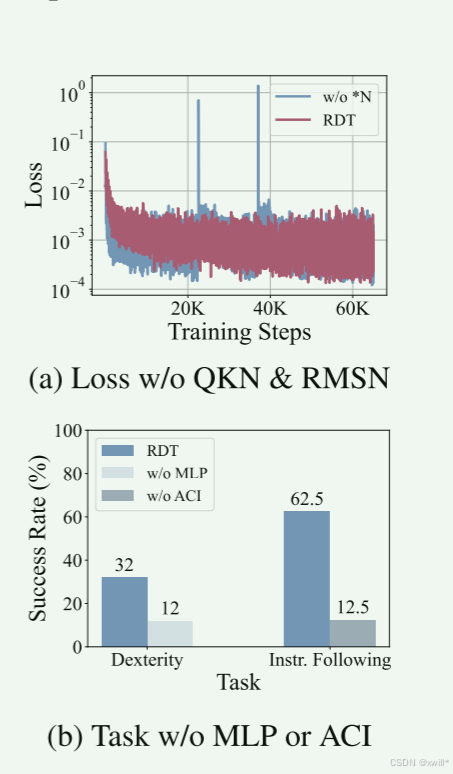
二:MLP Decoder (为了非线性)
标准 DiT 最后输出层通常是一个线性层(Linear)。但机器人的动力学是非常复杂的非线性关系(想象一下手臂挥动时的惯性和摩擦力)。线性层拟合不了。
解决方案: 把最后一层换成多层感知机(MLP),增加非线性表达能力。
三:交替条件注入 (ACI - 为了听懂人话)
图像的信息量太大了(几百个 Token),文本的信息量太小了(一句话也就十几个 Token)。如果把它们混在一起丢进 Attention 层,文本的声音会被图像淹没。结果就是机器人"看见了东西,但忘了你要它干什么"。
解决方案: 轮流发言。
-
第 1 层 Transformer Block:只听图像的(看环境)。
-
第 2 层 Transformer Block:只听文本的(想指令)。
-
第 3 层 ... 循环。
这样保证了语言指令始终占有一席之地,不会被忽略。
2 数据
为了实现在异构多机器人数据上的训练,我们需要一个在各种机器人之间共享的统一动作空间 (Unified Action Space) ,以便为多机器人动作提供统一的格式。从机器人原始动作空间到这个统一动作空间的映射必须是物理可解释的 (Physically Interpretable),且该空间的每一维都应具有明确的物理含义。这可以鼓励模型从不同的机器人数据中学习共享的物理定律,从而提高从不同机器人数据中学习的效率。
总的来说,目前机器人训练数据存在的痛点问题是:
-
机器人 A(比如 Franka)说:"我要向前移动 10cm" -> 数据是 10, 0, 0(笛卡尔空间)。
-
机器人 B(比如 UR5)说:"我要把 1 号关节转 5 度" -> 数据是 5, ...(关节空间)。
-
如果直接把这些数字丢给模型,模型会疯掉:为什么同样的数字 10,一会代表距离,一会代表角度?
以前的笨办法:
-
只用一种数据(放弃其他机器人)。
-
用 AutoEncoder 强行压缩成一个没有意义的 Latent Vector(潜变量)。但这会丢失物理意义,模型很难学到通用的物理规律(比如"重力是向下的")。
RDT 的方案(统一物理空间):
设计一个超级表格: 这个表格有几百列,每一列都有固定的物理意义。
-
第 1-7 列:左臂关节角度。
-
第 8-14 列:右臂关节角度。
-
第 15-17 列:左手末端位置 (x,y,z)。
-
...
-
第 N 列:夹爪力度。
填空题:
-
如果数据来自机器人 A(只有位置控制):填入第 15-17 列,其他列填 0(Padding)。
-
如果数据来自机器人 B(只有关节控制):填入第 1-7 列,其他列填 0。
为什么叫"物理可解释"? 因为每一列都对应真实的物理量。模型在训练时会发现:"哦,只要第 15 列(x轴位置)发生变化,图像里的手就会横向移动。"这种规律在任何机器人上都是通用的。 这样一来,不管你是什么机器人,只要你有夹爪,你的数据我就能用。这就是为什么作者能凑出 21TB 数据的秘诀。
2.1 "预训练 + 微调"的数据策略
光靠海量杂乱数据(预训练)是不够的,还需要精细的微调。
1: 预训练 (Pre-training)
-
数据来源: 46 个公开数据集,100万条轨迹。
-
**目的:**让模型学会通用的物理常识(比如东西松手会掉、两个物体不能穿模)。
-
问题: 这些机器人大多是单臂的,而且身体构造和 ALOHA 不一样(具身差异)。
2: 微调 (Fine-tuning)
-
数据来源: 自己采集的 ALOHA 机器人数据。
-
关键指标:
-
6K+ 轨迹: 别小看这个数字。在学术界,双手双臂数据非常难采(通常只有几百条)。6000 条已经是巨量了。
-
任务: "插电缆"(需要极高精度)、"写公式"(需要轨迹平滑)、"非刚体"(布料、绳子,这是物理模拟器最难搞定的)。
-
-
GPT-4 的作用:
-
人类标注员只会说:"把苹果拿起来"。
-
GPT-4 可以扩写成:"用右手抓起那个红色的水果"、"请拾取苹果"等。--让命令丰富化,多样化。
-
这让机器人能听懂各种花式指令,而不仅仅是死记硬背那一句话。
-
总的来说,统一空间 让我们能利用全世界的机器人数据(解决数据量问题)。保留物理意义 让模型能学到通用的物理规律(解决迁移学习问题)。高质量微调数据 弥补了从通用模型到特定机器人的最后"一公里"差距(解决落地问题)。
三:实验
-
Q1: RDT 能否零样本 (Zero-shot) 泛化到未见过的物体和场景?
-
Q2: RDT 对未见过模态(Modalities,指指令的具体描述方式)的零样本指令遵循能力有多有效?
-
Q3: RDT 能否促进对以前未见过的新技能 的少样本 (Few-shot) 学习?
-
Q4: RDT 是否有能力完成需要精细操作 (Delicate Operations) 的任务?
-
Q5: 大模型尺寸 、海量数据 以及扩散建模(Diffusion Modeling)对 RDT 的性能真的有帮助吗?

四:总结
文章构建了一个基础模型,验证了更大的模型 + 更多的数据 + 更好的架构(Diffusion)= 更强的智能在机器人领域也是适用的。作者提出了物理可解释的统一动作空间,解决了一个长期痛点:如何利用这就世界上现存的、乱七八糟的机器人数据?通过实验也证明了,只要保留数据的物理意义,不同构造的机器人(Franka, UR5, ALOHA)是可以互相"交流经验"的。
RDT 优于现有的方法,不仅在灵巧双手操作能力 和指令遵循 方面表现出显著的提升,而且在少样本学习 (Few-shot learning) 和针对未见物体与场景的零样本泛化 (Zero-shot generalization) 方面也取得了卓越的性能。