本文在绿泡泡"狗哥琐话"首发于2025.9.25 <-关注不走丢。
大家好这里是狗哥。之前AutoMQ的代码讲解还算受欢迎啊,今天来加个餐,讲讲AutoMQ代码里的那些设计(选择代码分支1.5)。
里氏替换原则
那读过Kafka源码的同学知道啊,KafkaApis是Kafka Broker handle请求的入口。所有request都能在这里找到对应的hand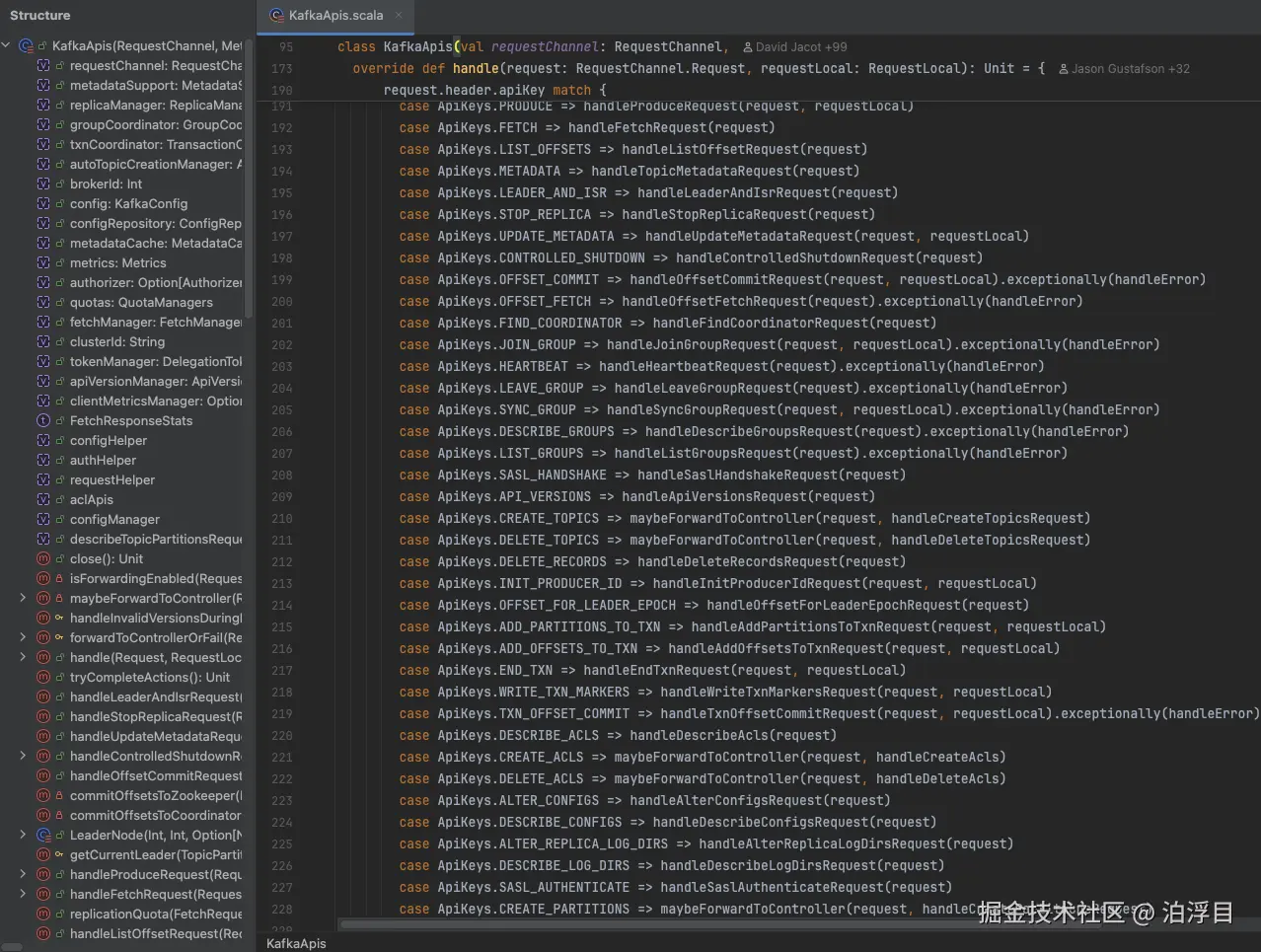 ler。
ler。
而AutoMQ的目的,是在兼容KafkaAPI的基础上,把存储放到S3上这种对象存储上。这块代码它是怎么设计的呢?
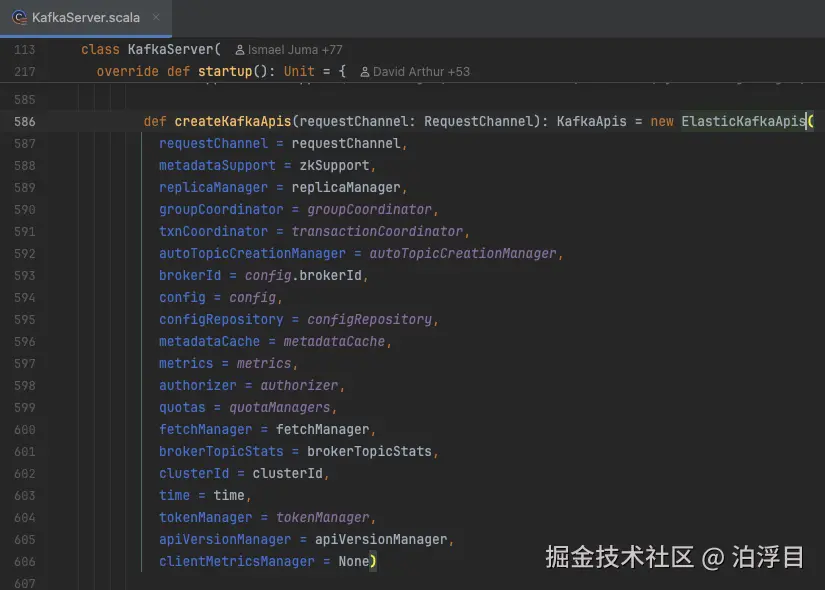
它直接做了一个继承------ElasticKafkaApis。它基于KafkaAPI扩展一些自己的API路由
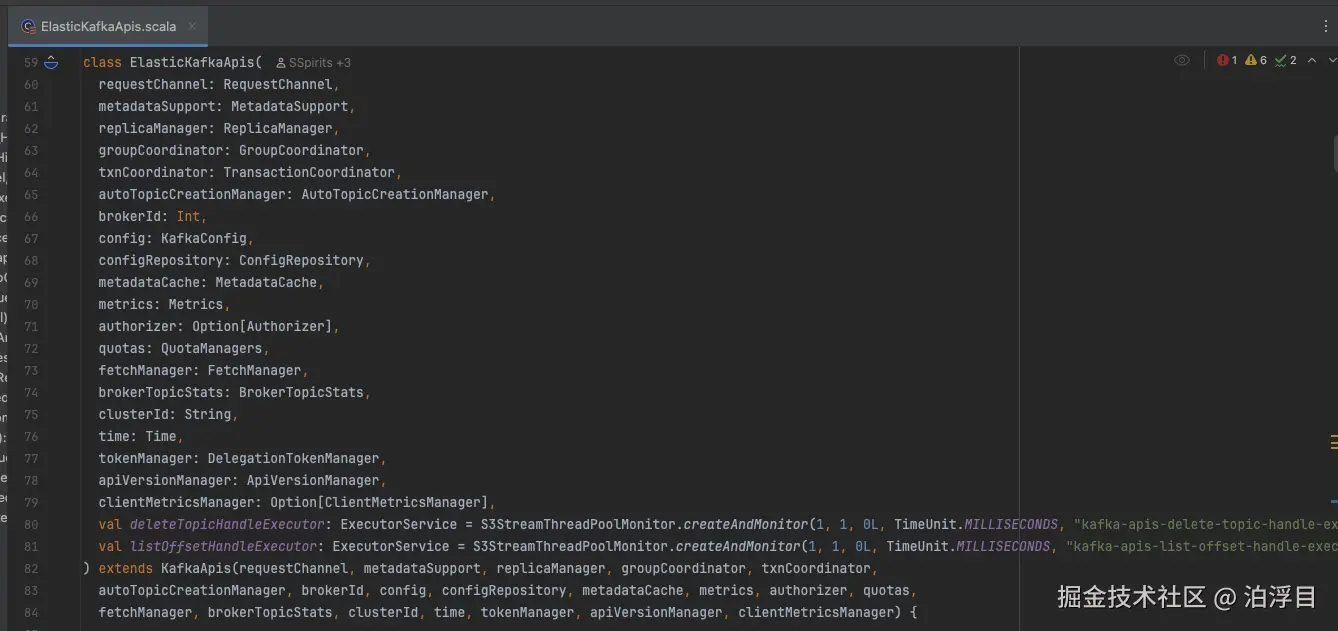
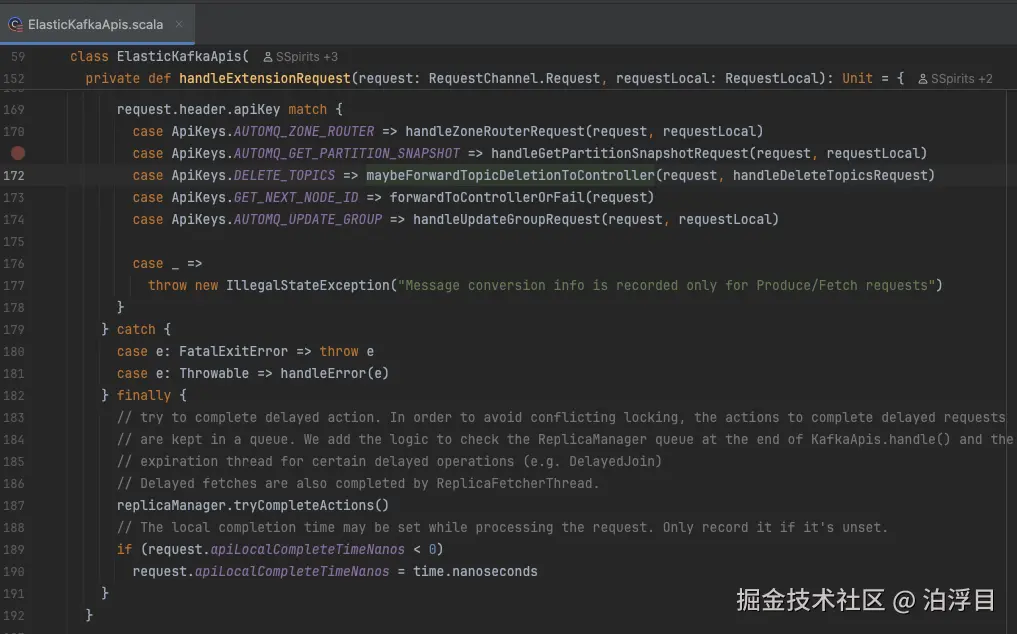
这样设计可以在上层代码以极小的代价来做替换。这就是一种里氏替换原则的体现。
Wrapper
然后我们再来介绍一个设计啊。在此之前,我们要知道一些基础知识:Kafka的底层存储其实是日志,然后把日志组织起来的是一个个LogSgement。
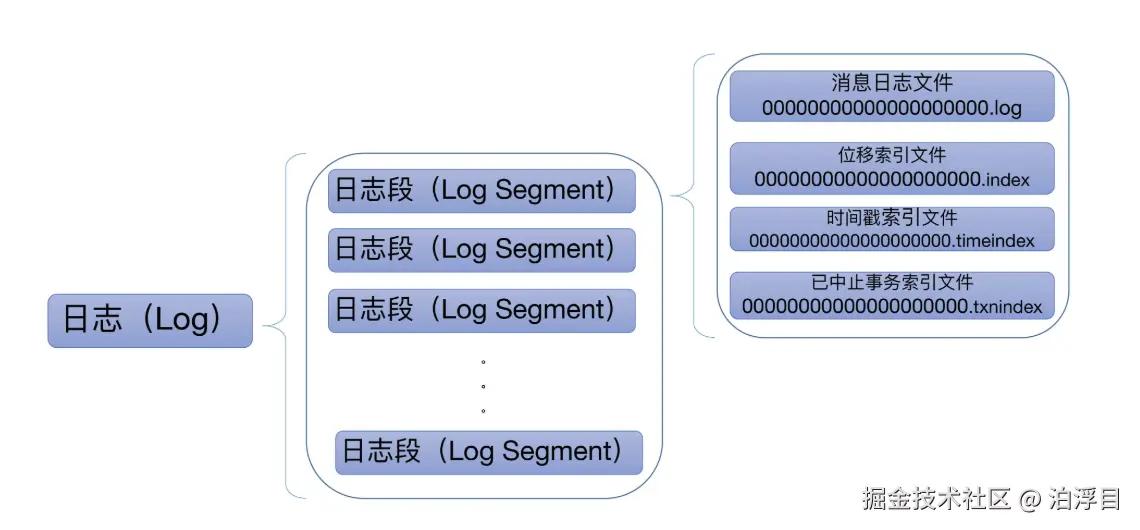
那每个Log Segement对象会在磁盘上创建一组文件,包括消息日志文件(.log)、位移索引文件(.index)、时间戳索引文件(.timeindex)以及已中止(Aborted)事务的索引文件(.txnindex)。
这个类在Kafka里的时候,主要做了日志和索引管理、消息追加与读取、日志滚动判断、恢复还有截断清理。然后AutoMQ还自己添加了一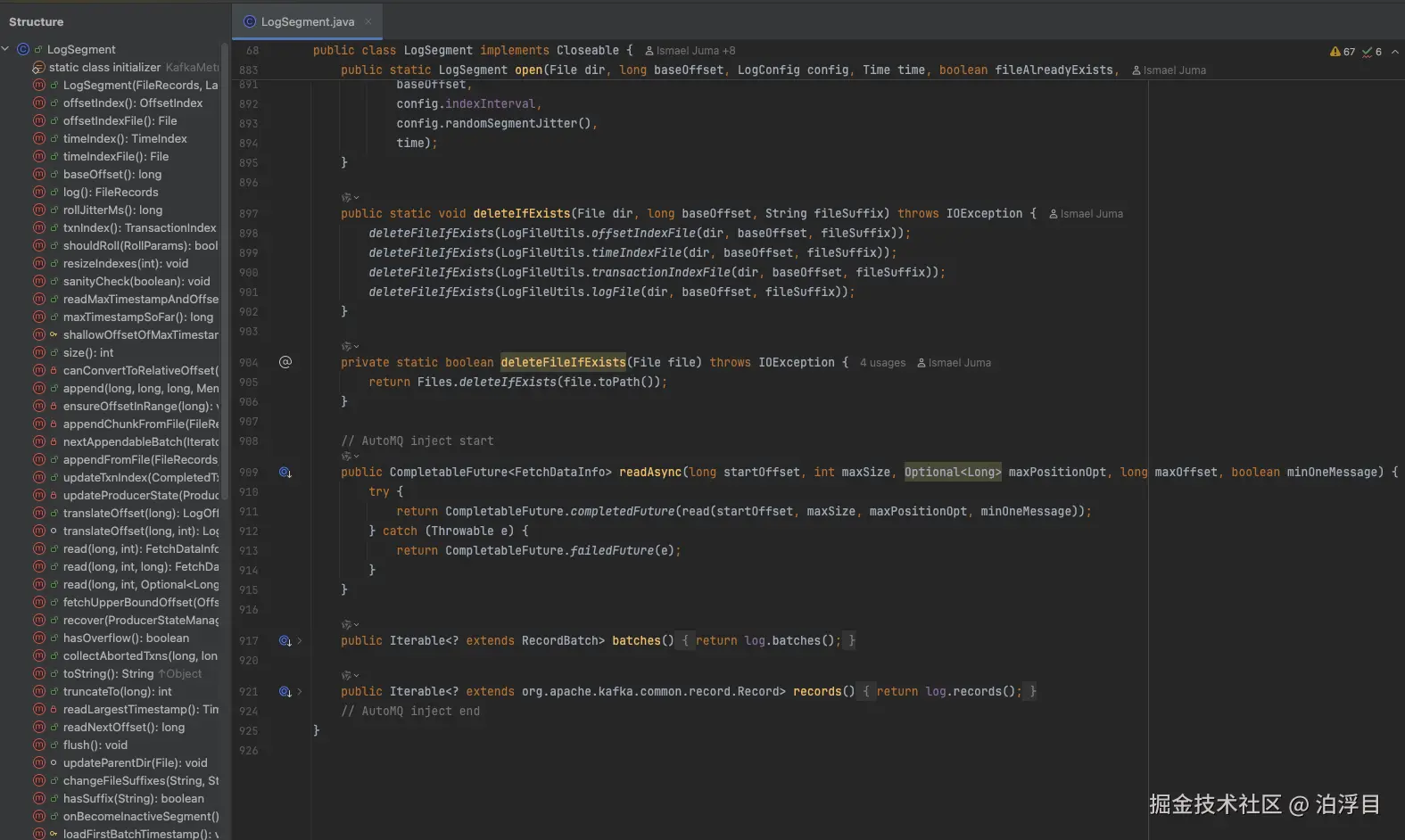 些方法
些方法
分别是异步读取、batches:返回当前日志段中的所有记录批次(RecordBatch)的可迭代对象、records:返回当前日志段中所有记录(Record)的可迭代对象。
那基于这个类呢,AutoMQ设计了一个类叫做ElasticLogSegment,就是继承于LogSegment
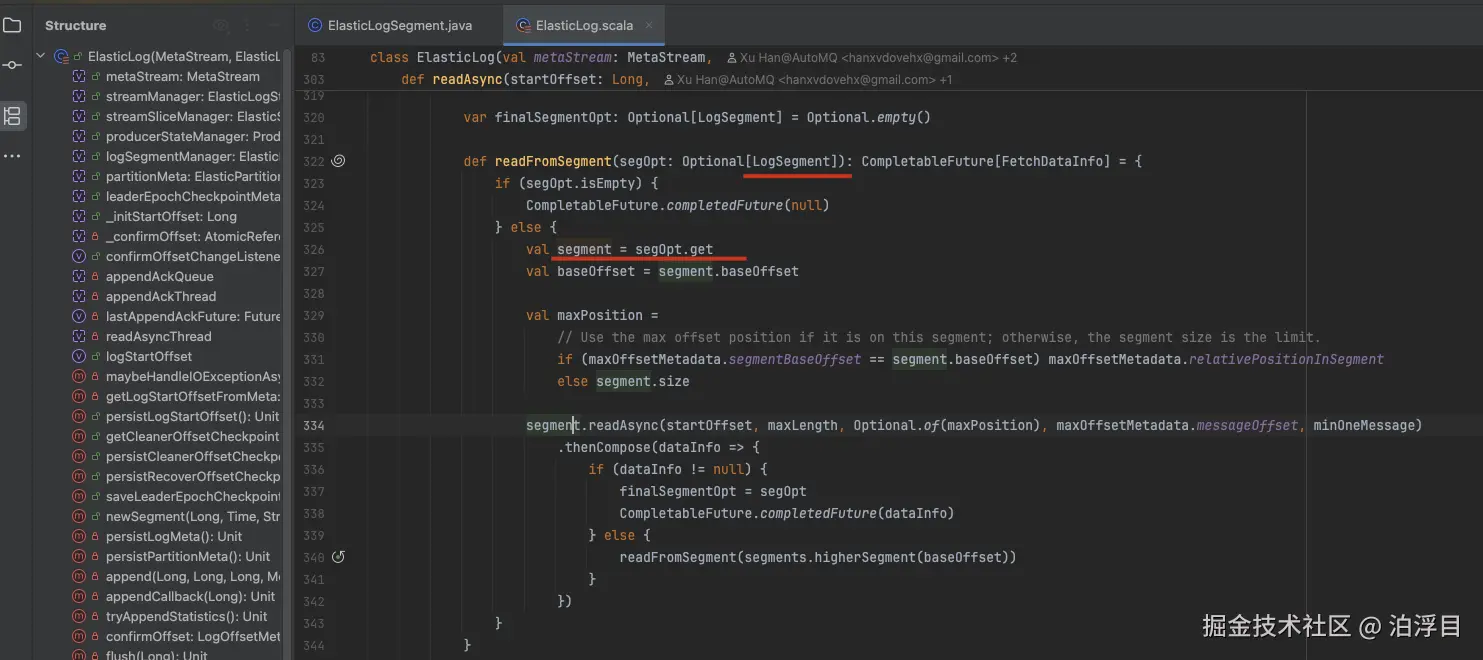
用于 AutoMQ 项目中替代 Kafka 原生的日志段管理机制。它是将日志段数据存储到对象存储的入口。那这很明显是个Wrapper模式的实现。
那机智的同学就会问了,为什么要在LogSegement添加一些方法呢?主要是AutoMQ在使用到相关类时,会用LogSegement的类型去做声明
ElasticLogSegment是new出来的具体类型。
小结
那今天的内容就到这里了啊。这个内容是来自于我星球里的,我的星球针对各种开源软件做了源码剖析,而且永久更新。那文字稿老规矩看简介。最后关注不走丢,我们下期见。