TL;DR
- 场景:用 Java(kudu-client 1.4.0)在本地多 Master 集群上完成 Kudu 表的建表、增删改查全流程。
- 结论:示例能跑通,但存在 flush 顺序、表名不一致、地址尾逗号等易踩坑点;生产与示例配置差异大。
- 产出:可直接复用的代码骨架 + 常见错误定位与修复清单 + 版本/模式选择指引。
版本矩阵
| 组合 | 已验证 | 说明 |
|---|---|---|
| JDK 8/11 + kudu-client 1.4.0 + 本地多Master(7051/7151/7251) + Hash分区=3 + 副本=1 | 是 | 文中示例跑通:建表/增删改查均可;仅适用于本地/学习环境 |
| kudu-client 1.4.0 + AUTO_FLUSH_SYNC | 是 | 适合逐条写入,apply同步返回;批量场景效率一般 |
| kudu-client 1.4.0 + MANUAL_FLUSH | 是 | 需先apply后flush并检查getPendingErrors();适合批量 |
| kudu-client 1.4.0 + AUTO_FLUSH_BACKGROUND | 否 | 文中未验证;并发写可能乱序,需评估一致性与背压 |
| 本地单Master | 否 | 文中未验证;不建议生产使用,容错性差 |
| 生产:副本≥3、与服务端版本对齐(≥1.10/1.15/1.16) | 否 | 文中未验证;建议按照集群实际版本对齐客户端以避免协议/特性差异 |

新建工程
由于重复了太多次,这里直接跳过了。
导入依赖
xml
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.4.0</version>
</dependency>创建新表
- 必须指定表连接到的Master节点主机名
- 必须定义Schema
- 必须指定副本数量、分区策略、数量
编写代码
java
package icu.wzk.kudu;
public class KuduCreateTable {
public static void main(String[] args) throws KuduException {
String masterAddress = "localhost:7051,localhost:7151,localhost:7251";
KuduClient.KuduClientBuilder kuduClientBuilder = new KuduClient.KuduClientBuilder(masterAddress);
KuduClient kuduClient = kuduClientBuilder.build();
String tableName = "student";
List<ColumnSchema> columnSchemas = new ArrayList<>();
ColumnSchema id = new ColumnSchema
.ColumnSchemaBuilder("id", Type.INT32)
.key(true)
.build();
columnSchemas.add(id);
ColumnSchema name = new ColumnSchema
.ColumnSchemaBuilder("name", Type.STRING)
.key(false)
.build();
columnSchemas.add(name);
Schema schema = new Schema(columnSchemas);
CreateTableOptions options = new CreateTableOptions();
// 副本数量为1
options.setNumReplicas(1);
List<String> colrule = new ArrayList<>();
colrule.add("id");
options.addHashPartitions(colrule, 3);
kuduClient.createTable(tableName, schema, options);
kuduClient.close();
}
}测试运行
shell
控制台未输出内容运行结果如下图所示: 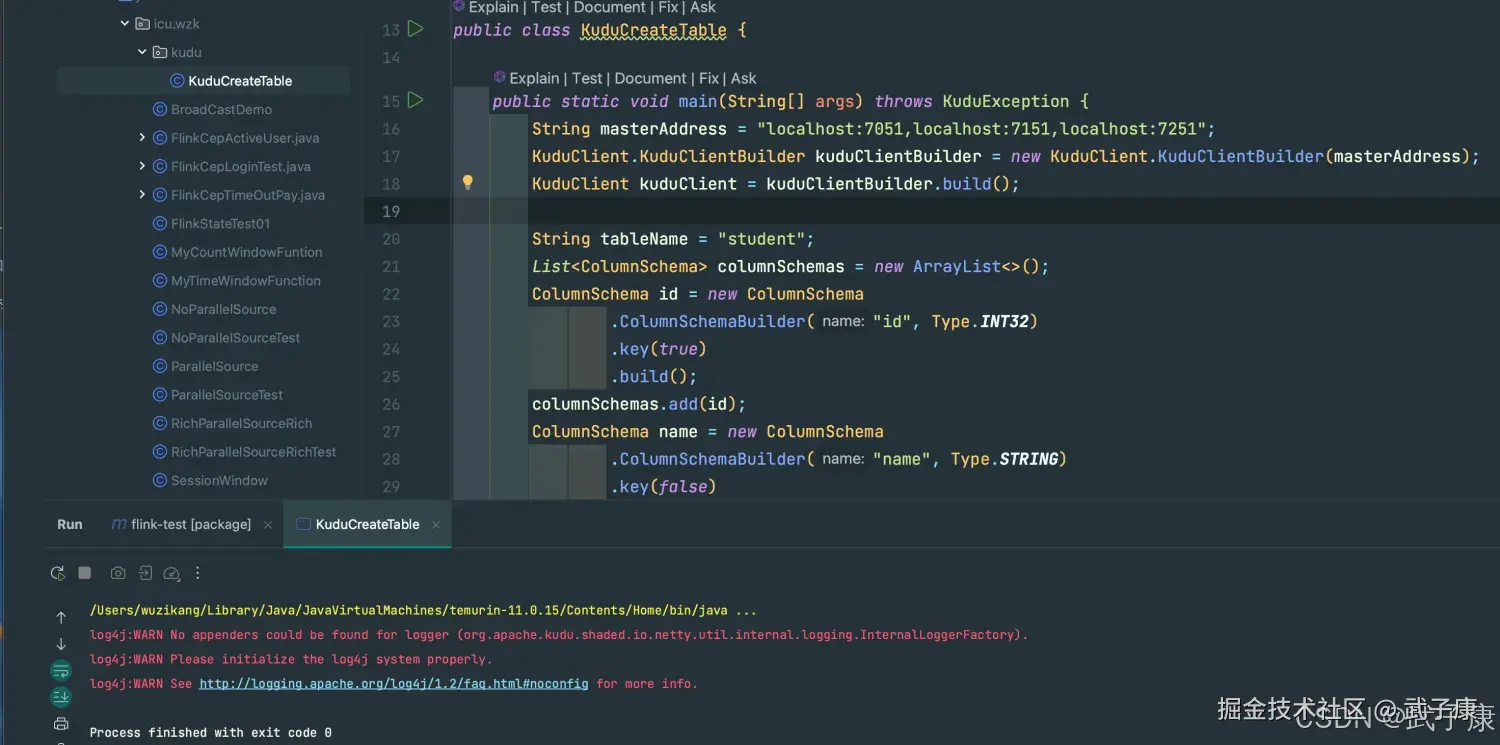
查看Kudu
我们查看Kudu的Tables,可以看到刚才创建的表如下: 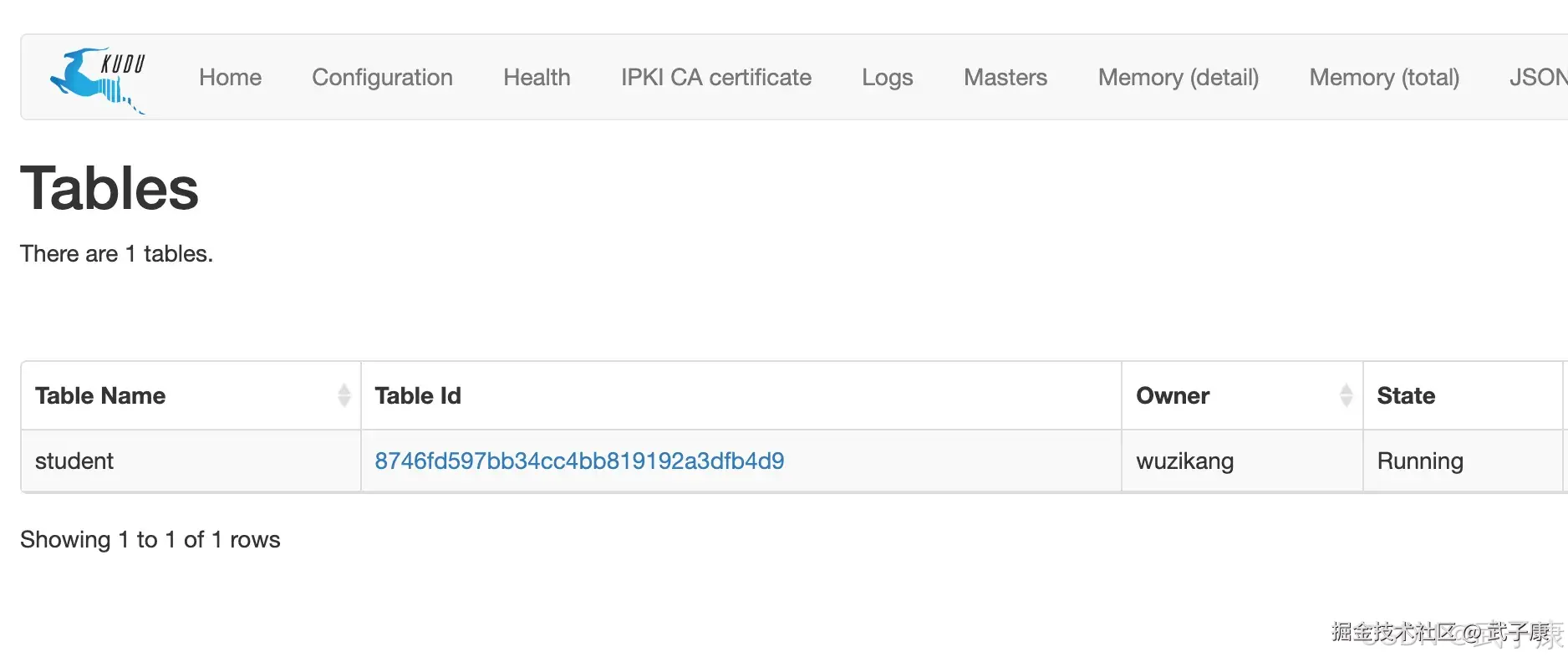
删除表
编写代码
java
package icu.wzk.kudu;
public class KuduDeleteTable {
public static void main(String[] args) throws KuduException {
String masterAddress = "localhost:7051,localhost:7151,localhost:7251,";
KuduClient client = new KuduClient.KuduClientBuilder(masterAddress)
.defaultAdminOperationTimeoutMs(5000)
.build();
client.deleteTable("student");
client.close();
}
}测试运行
控制台没有输出内容,这里运行截图如下: 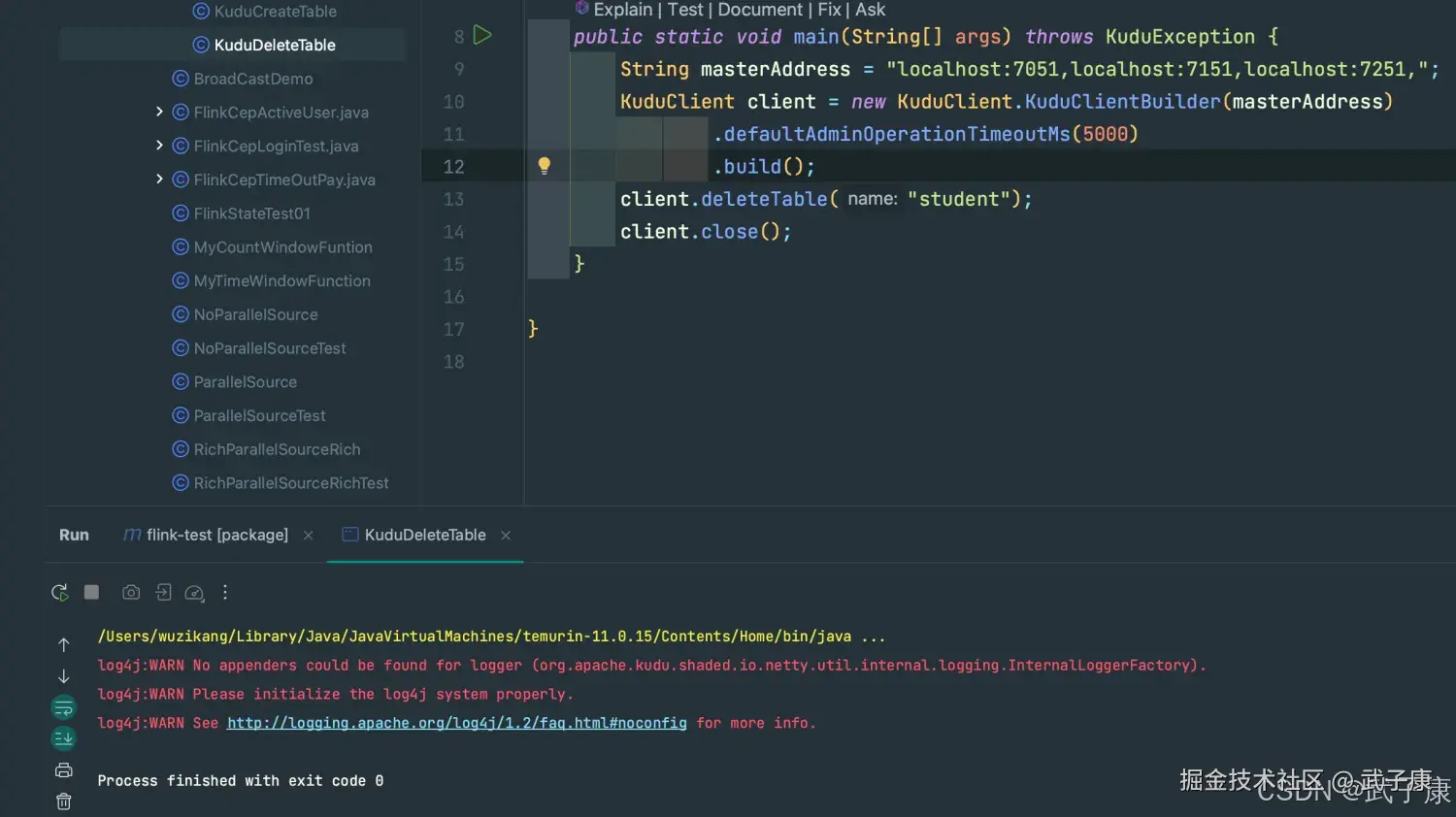
查看Kudu
查看Kudu服务的 Table 页,里边的数据表已经删除了。 
插入数据
- 获取客户端
- 打开一张表
- 创建会话
- 设置刷新模式
- 获取插入实例
- 声明带插入的数据
- 刷入数据
- 应用插入实例
- 关闭会话
创建新表
我们运行刚才的创建新表代码,把student表先生成出来,具体运行这里跳过了。
编写代码
java
package icu.wzk.kudu;
public class KuduInsert {
public static void main(String[] args) throws KuduException {
String masterAddr = "localhost:7051,localhost:7151,localhost:7251";
KuduClient client = new KuduClient
.KuduClientBuilder(masterAddr)
.defaultAdminOperationTimeoutMs(5000)
.build();
KuduTable stuTable = client.openTable("student");
KuduSession kuduSession = client.newSession();
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
Insert insert = stuTable.newInsert();
insert.getRow().addInt("id", 1);
insert.getRow().addString("name", "wzk");
kuduSession.flush();
kuduSession.apply(insert);
kuduSession.close();
client.close();
}
}在代码中,有一个叫:kuduSession.setFlushMode:
- AUTO_FLUSH_SYNC(默认):意思是调用KuduSession apply方法后,客户端会在当前刷新到服务器后再返回,这种情况不能够批量插入数据,调用 flush 方法不会起作用,应为此时缓冲区已经被刷新到了服务器。
- AUTO_FLUSH_BACKGROUD:意思是调用apply方法后,客户端会立即返回,但是写入将在后台发送,可能与来自同一会话的其他写入一起进行批处理。如果没有足够的缓冲空间,KuduSession apply会阻塞,缓冲空间不可用。因为写入操作是在后台进行的,因此任何一个错误都将存储在一个会话本地缓冲区中。注意:这个模式可能会导致插入是乱序的,这是因为在这种模式下,多个写操作可以并发的发送到服务器。且这是一个Kudu的BUG,详细请看:issues.apache.org/jira/browse...
- MANUAL_FLUSH:调用apply后,会非常快的返回,但是写操作不会发送,直到用户使用flush函数,如果缓冲区超过了限制大小,apply就会返回一个错误。
测试运行
控制台无输出内容,运行的截图如下图所示: 
查询数据
编写代码
Kudu的查询数据用Scanner
java
package icu.wzk.kudu;
public class KuduSelect {
public static void main(String[] args) throws KuduException {
String masterAddr = "localhost:7051,localhost:7151,localhost:7251";
KuduClient client = new KuduClient
.KuduClientBuilder(masterAddr)
.build();
KuduTable kuduTable = client.openTable("user");
KuduScanner kuduScanner = client.newScannerBuilder(kuduTable).build();
while (kuduScanner.hasMoreRows()) {
for (RowResult result : kuduScanner.nextRows()) {
int id = result.getInt("id");
String name = result.getString("name");
int age = result.getInt("age");
System.out.println("id: " + id + ", name: " + name + ", age: " + age);
}
}
client.close();
}
}测试运行
运行结果如下图所示: 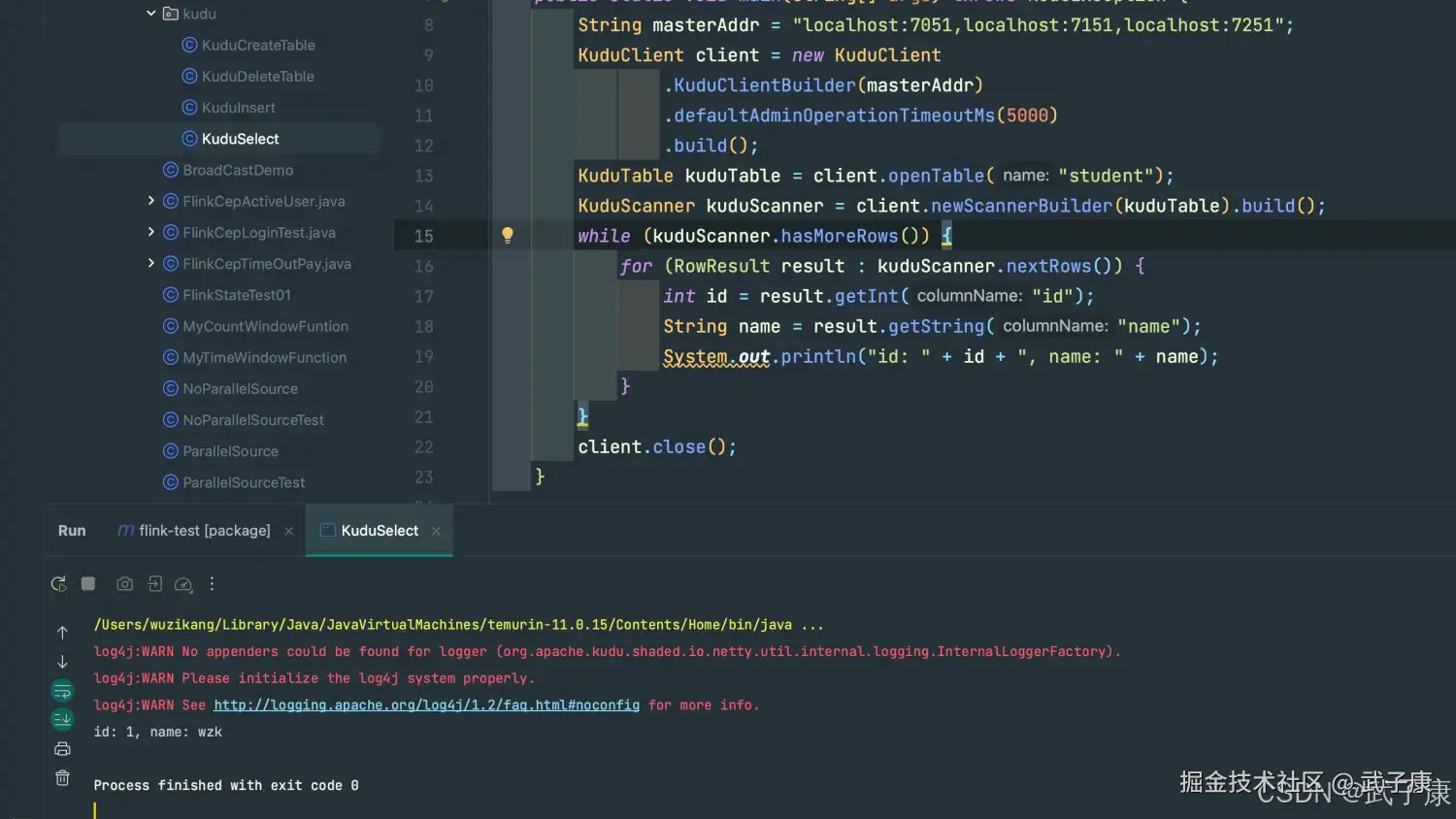
更改数据
编写代码
java
package icu.wzk.kudu;
public class KuduUpdate {
public static void main(String[] args) throws KuduException {
String masterAddress = "localhost:7051,localhost:7151,localhost:7251";
KuduClient client = new KuduClient
.KuduClientBuilder(masterAddress)
.build();
KuduTable stuTable = client.openTable("student");
KuduSession kuduSession = client.newSession();
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
Update update = stuTable.newUpdate();
update.getRow().addInt("id", 1);
update.getRow().addString("name", "wzk_icu");
kuduSession.apply(update);
kuduSession.close();
client.close();
}
}删除指定行
编写代码
java
package icu.wzk.kudu;
public class KuduDelete {
public static void main(String[] args) throws KuduException {
String masterAddress = "localhost:7051,localhost:7151,localhost:7251";
KuduClient client = new KuduClient
.KuduClientBuilder(masterAddress)
.build();
KuduSession kuduSession = client.newSession();
KuduTable stuTable = client.openTable("student");
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
Delete delete = stuTable.newDelete();
PartialRow row = delete.getRow();
row.addInt("id", 1);
kuduSession.flush();
kuduSession.apply(delete);
kuduSession.close();
client.close();
}
}测试运行
控制台没有输出任何内容,运行过程截图如下: 
错误速查
| 症状 | 根因定位 | 修复 |
|---|---|---|
| 控制台无报错但表中无数据 | MANUAL_FLUSH 先 flush 再 apply,顺序反了 | 开启 RPC/客户端日志;查 session.getPendingErrors() 改为 先 apply 后 flush;批量写统一 flush,并检查错误 |
| UnknownHostException/连接异常 | Master 地址末尾多了逗号(如 ...,) | 观察异常栈与传入的地址列表 移除尾逗号,确保主机:端口列表正确 |
| Not found: table user | 查询表名与创建不一致(创建 student,查询 user) | 服务端/客户端日志,异常信息清晰可见 统一表名:改为同一张表或先创建目标表 |
| 读取列时报错(如 age) | Schema 不含该列 | 查看建表 Schema 与 RowResult.get*() 列名 补齐 Schema 后重建表,或移除无效列 |
| 读取更新/删除无效 | MANUAL_FLUSH 模式下未 flush 即 close | 观察无效变更与会话关闭顺序 apply 后显式 flush;或使用 AUTO_FLUSH_SYNC 简化写入 |
| 乱序/批次不可预期 | AUTO_FLUSH_BACKGROUND 并发发送 | 日志对比主键顺序与服务端接收顺序 对顺序敏感改用同步/手动批处理;必要时在上层做幂等 |
| 无法连接 Leader Master | Master 未启动/端口错误/选主未完成 | Master Web UI 与日志(master.I) 启动所有 Master,校验端口,等待选主完成 |
| 协议/特性不兼容 | 客户端 1.4.0 与服务端版本差距大 | 日志出现协议/特性相关错误 对齐客户端与服务端版本;评估升级至集群当前版本 |
| 插入/更新看似成功但丢写 | 未检错或异步错误积压 | session.getPendingErrors() 有堆积 每次 flush 后检查并处理返回错误 |
| 扫描资源未释放 | 未关闭 KuduScanner/客户端 | 监控连接与句柄 用 try-with-resources 或确保显式 close() |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI-调查研究-108-具身智能 机器人模型训练全流程详解:从预训练到强化学习与人类反馈
💻 Java篇持续更新中(长期更新)
Java-154 深入浅出 MongoDB 用Java访问 MongoDB 数据库 从环境搭建到CRUD完整示例 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解