Phi-3 技术报告:手机本地运行的高能力语言模型
Abdin M, Aneja J, Behl H, et al. Phi-4 technical reportJ. arXiv preprint arXiv:2412.08905, 2024.
1. 引言与背景
人工智能在过去几年的惊人进步很大程度上归功于全球范围内对不断扩大模型和数据集规模的努力。大型语言模型(LLMs)的参数量从五年前GPT-2的15亿参数急剧增长到如今的万亿参数级别。这种增长的动力源于训练大模型时看似可预测的改进,即所谓的缩放定律:
L(N)=(NcN)αNL(N) = \left(\frac{N_c}{N}\right)^{\alpha_N}L(N)=(NNc)αN
其中LLL是损失,NNN是模型参数量,NcN_cNc和αN\alpha_NαN是常数。然而,这些定律假设了一个"固定"的数据源。现在前沿LLMs本身的存在已经显著颠覆了这一假设,它们使我们能够以全新的方式与数据交互。
Microsoft的研究展示了一个突破性发现:通过结合基于LLM的公开网络数据过滤和LLM创建的合成数据,能够让小型语言模型达到通常只有在更大模型中才能看到的性能。本报告介绍的phi-3-mini是一个38亿参数的语言模型,在3.3万亿tokens上训练,其整体性能与Mixtral 8x7B和GPT-3.5相当,尽管其体积小到足以部署在手机上。
2. 技术规格与架构创新
2.1 基础架构设计
phi-3-mini采用transformer解码器架构,具有以下技术规格:
- 隐藏维度 : dmodel=3072d_{model} = 3072dmodel=3072
- 注意力头数 : nheads=32n_{heads} = 32nheads=32
- 层数 : nlayers=32n_{layers} = 32nlayers=32
- 词汇表大小 : ∣V∣=32064|V| = 32064∣V∣=32064
- 上下文长度: 默认4K,扩展版本支持128K
模型的前向传播可以表示为:
h0=xWe+p\mathbf{h}_0 = \mathbf{x}W_e + \mathbf{p}h0=xWe+p
hl=TransformerBlock(hl−1),l=1,...,nlayers\mathbf{h}l = \text{TransformerBlock}(\mathbf{h}{l-1}), \quad l = 1, ..., n_{layers}hl=TransformerBlock(hl−1),l=1,...,nlayers
y=softmax(hnlayersWo)\mathbf{y} = \text{softmax}(\mathbf{h}{n{layers}}W_o)y=softmax(hnlayersWo)
其中We∈R∣V∣×dmodelW_e \in \mathbb{R}^{|V| \times d_{model}}We∈R∣V∣×dmodel是嵌入矩阵,p\mathbf{p}p是位置编码,Wo∈Rdmodel×∣V∣W_o \in \mathbb{R}^{d_{model} \times |V|}Wo∈Rdmodel×∣V∣是输出投影矩阵。
2.2 块稀疏注意力机制

图1描述:该图展示了phi-3-small中块稀疏注意力的玩具示例,具有2个局部块和垂直步幅为3。表格显示了块8中查询token关注的键/值。蓝色表示局部块,橙色表示远程/垂直块,灰色表示跳过的块。
phi-3-small引入了创新的块稀疏注意力机制。传统的自注意力复杂度为O(n2)O(n^2)O(n2),其中nnn是序列长度。块稀疏注意力通过选择性地关注特定块来降低复杂度:
BlockSparseAttn(Q,K,V)=softmax(QKsparseTdk⊙M)Vsparse\text{BlockSparseAttn}(Q, K, V) = \text{softmax}\left(\frac{QK^T_{sparse}}{\sqrt{d_k}} \odot M\right)V_{sparse}BlockSparseAttn(Q,K,V)=softmax(dk QKsparseT⊙M)Vsparse
其中MMM是稀疏掩码矩阵,KsparseK_{sparse}Ksparse和VsparseV_{sparse}Vsparse是根据稀疏模式选择的键和值。这种设计确保了所有token在不同的注意力头上都得到关注,同时显著减少KV缓存的内存占用。
2.3 长上下文扩展
phi-3-mini-128K通过LongRope方法扩展上下文长度。RoPE (旋转位置嵌入)的原始形式为:
f(q,m)=q⋅eimθf(q, m) = q \cdot e^{i m \theta}f(q,m)=q⋅eimθ
其中θj=10000−2j/d\theta_j = 10000^{-2j/d}θj=10000−2j/d。LongRope通过修改频率基数来支持更长序列:
θj′=θj⋅s(j/d)\theta'_j = \theta_j \cdot s^{(j/d)}θj′=θj⋅s(j/d)
其中sss是缩放因子,通过以下方式计算:
s=LtargetLoriginals = \frac{L_{target}}{L_{original}}s=LoriginalLtarget
2.4 混合专家架构
phi-3.5-MoE采用稀疏激活的混合专家架构。给定输入x\mathbf{x}x,路由函数计算:
g(x)=TopK(softmax(Wgx),k)g(\mathbf{x}) = \text{TopK}(\text{softmax}(W_g \mathbf{x}), k)g(x)=TopK(softmax(Wgx),k)
其中Wg∈RE×dmodelW_g \in \mathbb{R}^{E \times d_{model}}Wg∈RE×dmodel是路由权重,E=16E=16E=16是专家数量,k=2k=2k=2是每个token激活的专家数。最终输出为:
y=∑i=1Egi(x)⋅Experti(x)\mathbf{y} = \sum_{i=1}^{E} g_i(\mathbf{x}) \cdot \text{Expert}_i(\mathbf{x})y=i=1∑Egi(x)⋅Experti(x)
这种设计使得16×3.8B参数的模型仅有6.6B活跃参数,大大提高了推理效率。
3. 训练方法论
3.1 数据最优化策略
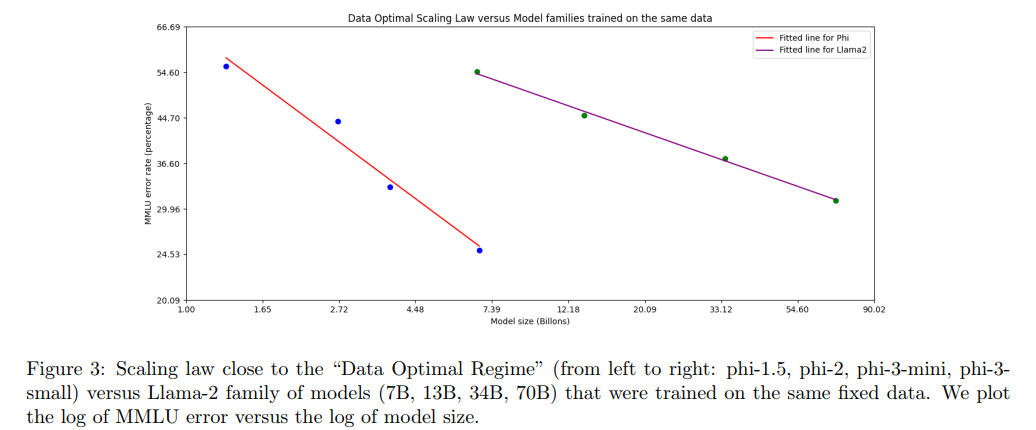
图3描述:该图展示了接近"数据最优范式"的缩放定律曲线。横轴是模型大小的对数,纵轴是MMLU错误率的对数。红线显示phi系列模型(从左到右:phi-1.5、phi-2、phi-3-mini、phi-3-small),紫线显示在相同固定数据上训练的Llama-2系列模型(7B、13B、34B、70B)。phi系列明显优于传统缩放。
研究团队没有遵循"计算最优"或"过度训练"范式,而是专注于给定规模下的数据质量。数据过滤策略基于教育价值评分函数:
Score(d)=α⋅Knowledge(d)+β⋅Reasoning(d)−γ⋅Redundancy(d)\text{Score}(d) = \alpha \cdot \text{Knowledge}(d) + \beta \cdot \text{Reasoning}(d) - \gamma \cdot \text{Redundancy}(d)Score(d)=α⋅Knowledge(d)+β⋅Reasoning(d)−γ⋅Redundancy(d)
其中ddd是文档,α\alphaα、β\betaβ、γ\gammaγ是权重参数。通过这种评分机制,团队筛选出最适合小模型学习的高质量数据。
3.2 两阶段预训练
训练分为两个不相交的顺序阶段:
第一阶段:使用大约50%的网络数据和50%的合成数据,总计1.8T tokens。损失函数为标准的语言建模目标:
LLM=−∑t=1TlogP(xt∣x<t) \mathcal{L}{LM} = -\sum{t=1}^{T} \log P(x_t | x_{<t}) LLM=−t=1∑TlogP(xt∣x<t)
第二阶段:使用更严格过滤的数据(第一阶段使用数据的子集)与额外的合成推理数据,总计1.5T tokens。这一阶段特别强调逻辑推理和专业技能的训练。
3.3 后训练优化
后训练包括监督微调(SFT)和直接偏好优化(DPO)两个阶段。
SFT阶段的损失函数:
LSFT=−E(x,y)∼DSFT∑t=1∣y∣logPθ(yt∣x,y\
DPO阶段使用Bradley-Terry模型进行偏好建模:
LDPO=−E(x,yw,yl)∼DDPOlogσ(βlogPθ(yw∣x)Pref(yw∣x)−βlogPθ(yl∣x)Pref(yl∣x))\mathcal{L}{DPO} = -\mathbb{E}{(x,y_w,y_l) \sim \mathcal{D}_{DPO}} \left\\log \\sigma\\left(\\beta \\log \\frac{P_\\theta(y_w\|x)}{P_{ref}(y_w\|x)} - \\beta \\log \\frac{P_\\theta(y_l\|x)}{P_{ref}(y_l\|x)}\\right)\\rightLDPO=−E(x,yw,yl)∼DDPOlogσ(βlogPref(yw∣x)Pθ(yw∣x)−βlogPref(yl∣x)Pθ(yl∣x))
其中ywy_wyw是偏好的响应,yly_lyl是不偏好的响应,β\betaβ是温度参数,PrefP_{ref}Pref是参考模型。
4. 性能评估
4.1 学术基准测试结果
在标准基准测试上的详细结果显示,phi-3-mini虽然只有3.8B参数,但在多个任务上超越了7B甚至更大的模型:
- MMLU (5-shot): 68.8%,超过Mistral-7b的61.7%
- GSM-8K (8-shot, CoT): 82.5%,远超Mistral-7b的46.4%
- HumanEval (0-shot): 58.5%,是Mistral-7b (28.0%)的两倍多
- MATH (0-shot, CoT): 41.3%,显著优于其他开源模型
4.2 手机端部署演示
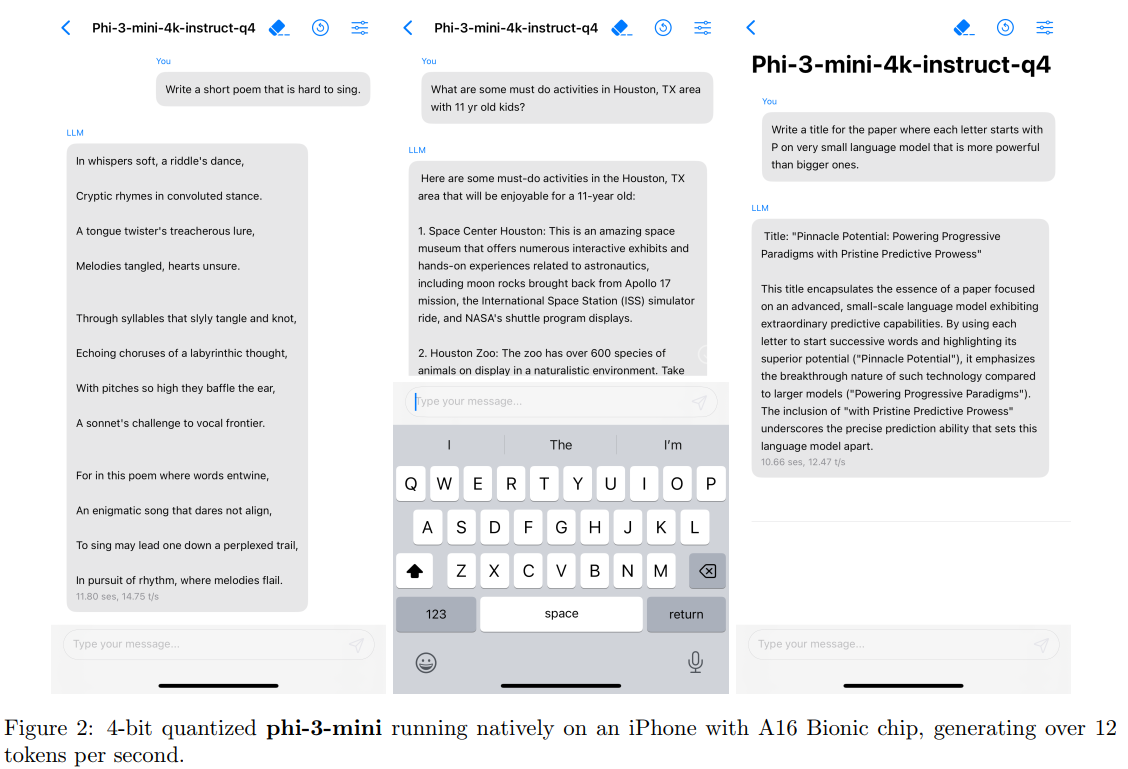
图2描述:该图展示了4位量化的phi-3-mini在配备A16 Bionic芯片的iPhone上原生运行的三个屏幕截图。左侧显示用户输入诗歌创作请求,中间显示模型正在生成响应,右侧显示完整的生成结果。界面显示模型能够流畅生成每秒超过12个tokens。
量化过程使用了INT4量化技术,将模型权重从FP16压缩到INT4:
Wint4=round(Wfp16scale)⋅clip(−8,7)W_{int4} = \text{round}\left(\frac{W_{fp16}}{\text{scale}}\right) \cdot \text{clip}(-8, 7)Wint4=round(scaleWfp16)⋅clip(−8,7)
这使得模型大小从约7.6GB降至1.8GB,同时保持了大部分性能。
5. 多模态扩展:Phi-3.5-Vision
5.1 视觉编码器集成
Phi-3.5-Vision结合了CLIP ViT-L/14视觉编码器和phi-3.5-mini语言模型。视觉tokens的处理流程为:
v=CLIP(I)\mathbf{v} = \text{CLIP}(\mathbf{I})v=CLIP(I)
z=Wpv+bp\mathbf{z} = W_p \mathbf{v} + \mathbf{b}_pz=Wpv+bp
其中I\mathbf{I}I是输入图像,WpW_pWp和bp\mathbf{b}_pbp是投影参数,将视觉特征映射到语言模型的嵌入空间。
5.2 动态裁剪策略
为了处理高分辨率图像和各种宽高比,模型采用动态裁剪策略。给定输入图像III,将其分割为n×mn \times mn×m个块:
I={Ii,j}i=1,j=1n,mI = \{I_{i,j}\}_{i=1,j=1}^{n,m}I={Ii,j}i=1,j=1n,m
每个块独立编码后拼接:
V=concat(CLIP(Ii,j)i,j)\mathbf{V} = \text{concat}(\\text{CLIP}(I_{i,j})_{i,j})V=concat(CLIP(Ii,j)i,j)
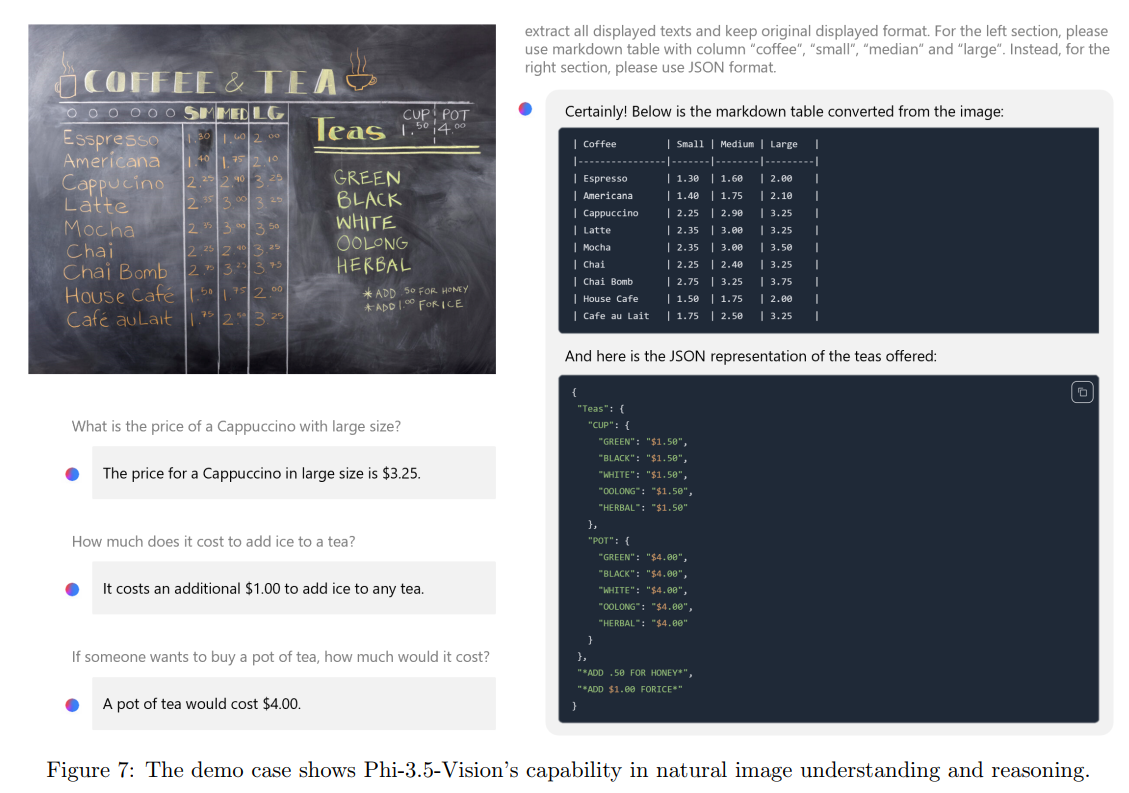
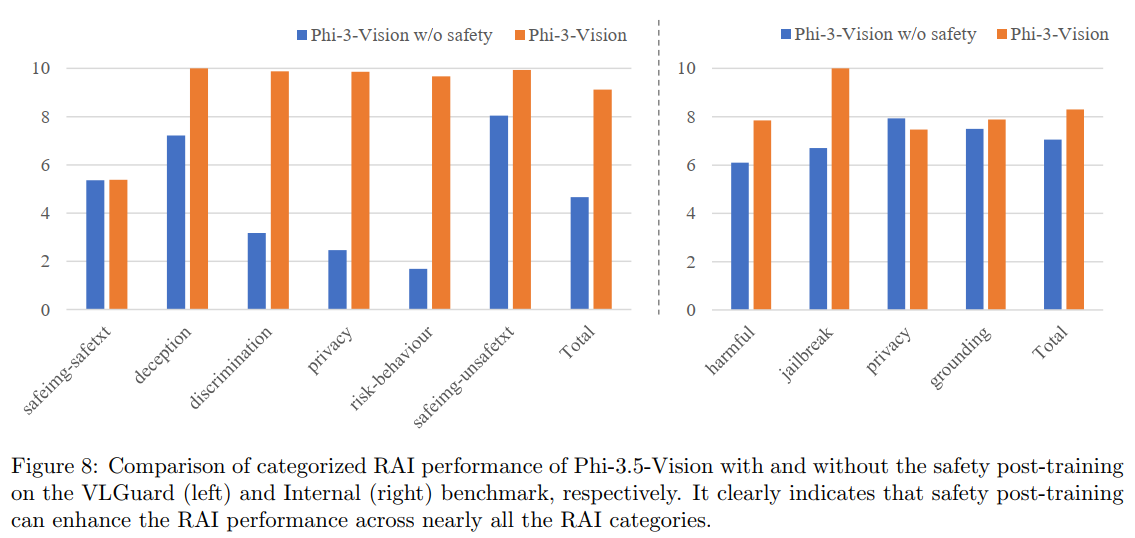
图7和图8描述:这些图展示了Phi-3.5-Vision的实际应用示例。图7显示模型能够准确读取咖啡店菜单图片中的价格信息,并正确回答关于价格的数学问题。图8比较了安全对齐前后的性能,显示在各个RAI类别中有害响应率都显著下降。
6. 安全性评估
6.1 负责任AI对齐
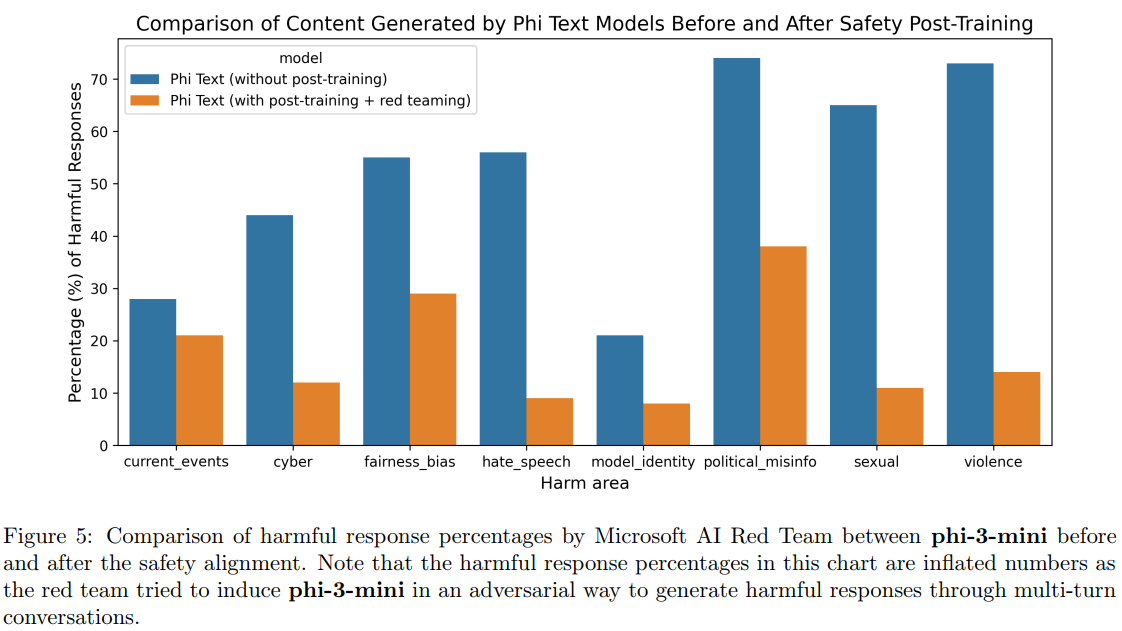
图5描述:该图展示了phi-3-mini在安全对齐前后的有害响应百分比对比。深蓝色条表示未经安全训练的模型,浅橙色条表示经过安全训练和红队测试后的模型。在所有类别中都显示出显著改善。
安全对齐使用了多层次的防护机制:
Psafe(y∣x)=Pbase(y∣x)⋅∏i=1Nfi(x,y)P_{safe}(y|x) = P_{base}(y|x) \cdot \prod_{i=1}^{N} f_i(x, y)Psafe(y∣x)=Pbase(y∣x)⋅i=1∏Nfi(x,y)
其中fif_ifi是不同的安全过滤器,包括内容过滤、毒性检测和事实性验证。
7. 局限性与未来方向
尽管取得了显著成就,phi-3系列模型仍存在一些局限性。模型的事实知识存储能力受限于其参数规模,这反映在TriviaQA等纯知识任务上的相对较低性能(64.0% vs GPT-3.5的85.8%)。然而,通过与搜索引擎的集成可以有效缓解这一问题。

图6描述:该图对比展示了phi-3-mini在有无搜索增强情况下的回答。左侧显示没有搜索时模型给出的错误信息,右侧显示集成HuggingFace Chat-UI搜索功能后,模型不仅纠正了错误,还提供了更具体的建议。
附录A:数学推导
A.1 缩放定律的理论基础
传统的神经网络缩放定律遵循幂律关系。给定计算预算CCC,最优的模型大小N∗N^*N∗和数据集大小D∗D^*D∗满足:
N∗∝CαN/(αN+αD)N^* \propto C^{\alpha_N/(α_N+α_D)}N∗∝CαN/(αN+αD)
D∗∝CαD/(αN+αD)D^* \propto C^{\alpha_D/(α_N+α_D)}D∗∝CαD/(αN+αD)
其中αN≈0.73\alpha_N \approx 0.73αN≈0.73,αD≈0.27\alpha_D \approx 0.27αD≈0.27是经验常数。然而,phi系列模型通过数据质量优化打破了这一关系。
A.2 注意力机制的计算复杂度分析
标准多头注意力的计算复杂度为:
Complexitystandard=O(n2⋅d+n⋅d2)\text{Complexity}_{standard} = O(n^2 \cdot d + n \cdot d^2)Complexitystandard=O(n2⋅d+n⋅d2)
其中第一项来自注意力矩阵计算,第二项来自线性投影。块稀疏注意力将其降低为:
Complexitysparse=O(n⋅b⋅d+n⋅d2)\text{Complexity}_{sparse} = O(n \cdot b \cdot d + n \cdot d^2)Complexitysparse=O(n⋅b⋅d+n⋅d2)
其中b≪nb \ll nb≪n是每个查询关注的块数。当b=O(logn)b = O(\log n)b=O(logn)时,复杂度变为O(nlogn⋅d+n⋅d2)O(n \log n \cdot d + n \cdot d^2)O(nlogn⋅d+n⋅d2)。
A.3 RoPE位置编码的频率调整
原始RoPE使用复数表示:
RΘ,m=cosmθ1−sinmθ100⋯sinmθ1cosmθ100⋯00cosmθ2−sinmθ2⋯00sinmθ2cosmθ2⋯⋮⋮⋮⋮⋱\mathbf{R}_{\Theta,m} = \begin{bmatrix} \cos m\theta_1 & -\sin m\theta_1 & 0 & 0 & \cdots \\ \sin m\theta_1 & \cos m\theta_1 & 0 & 0 & \cdots \\ 0 & 0 & \cos m\theta_2 & -\sin m\theta_2 & \cdots \\ 0 & 0 & \sin m\theta_2 & \cos m\theta_2 & \cdots \\ \vdots & \vdots & \vdots & \vdots & \ddots \end{bmatrix}RΘ,m= cosmθ1sinmθ100⋮−sinmθ1cosmθ100⋮00cosmθ2sinmθ2⋮00−sinmθ2cosmθ2⋮⋯⋯⋯⋯⋱
LongRope通过非线性插值修改频率:
θj′={θjif j<d/4θj⋅(LtargetLoriginal)(4j/d−1)/3if d/4≤j<3d/4θj⋅LtargetLoriginalif j≥3d/4\theta'j = \begin{cases} \theta_j & \text{if } j < d/4 \\ \theta_j \cdot \left(\frac{L{target}}{L_{original}}\right)^{(4j/d-1)/3} & \text{if } d/4 \leq j < 3d/4 \\ \theta_j \cdot \frac{L_{target}}{L_{original}} & \text{if } j \geq 3d/4 \end{cases}θj′=⎩ ⎨ ⎧θjθj⋅(LoriginalLtarget)(4j/d−1)/3θj⋅LoriginalLtargetif j<d/4if d/4≤j<3d/4if j≥3d/4
这种分段调整保留了低频信息的精度,同时扩展了高频成分以支持更长的序列。
A.4 DPO损失函数的推导
从偏好数据(x,yw≻yl)(x, y_w \succ y_l)(x,yw≻yl)出发,Bradley-Terry模型给出:
P(yw≻yl∣x)=exp(r(x,yw))exp(r(x,yw))+exp(r(x,yl))P(y_w \succ y_l | x) = \frac{\exp(r(x, y_w))}{\exp(r(x, y_w)) + \exp(r(x, y_l))}P(yw≻yl∣x)=exp(r(x,yw))+exp(r(x,yl))exp(r(x,yw))
其中r(x,y)r(x, y)r(x,y)是奖励函数。DPO通过将奖励函数参数化为:
r(x,y)=βlogPθ(y∣x)Pref(y∣x)+βlogZ(x)r(x, y) = \beta \log \frac{P_\theta(y|x)}{P_{ref}(y|x)} + \beta \log Z(x)r(x,y)=βlogPref(y∣x)Pθ(y∣x)+βlogZ(x)
消除了需要显式学习奖励模型的步骤。代入Bradley-Terry模型并取对数,得到DPO损失:
LDPO=−logσ(βlogPθ(yw∣x)Pref(yw∣x)−βlogPθ(yl∣x)Pref(yl∣x))\mathcal{L}{DPO} = -\log \sigma\left(\beta \log \frac{P\theta(y_w|x)}{P_{ref}(y_w|x)} - \beta \log \frac{P_\theta(y_l|x)}{P_{ref}(y_l|x)}\right)LDPO=−logσ(βlogPref(yw∣x)Pθ(yw∣x)−βlogPref(yl∣x)Pθ(yl∣x))
A.5 混合专家的负载均衡
为确保专家之间的负载均衡,训练时添加辅助损失:
Lbalance=α⋅CV(f)+β⋅CV(P)\mathcal{L}_{balance} = \alpha \cdot \text{CV}(\mathbf{f}) + \beta \cdot \text{CV}(\mathbf{P})Lbalance=α⋅CV(f)+β⋅CV(P)
其中f=f1,...,fE\mathbf{f} = f_1, ..., f_Ef=f1,...,fE是每个专家的使用频率,P=P1,...,PE\mathbf{P} = P_1, ..., P_EP=P1,...,PE是路由概率的均值,CV是变异系数:
CV(x)=std(x)mean(x)\text{CV}(\mathbf{x}) = \frac{\text{std}(\mathbf{x})}{\text{mean}(\mathbf{x})}CV(x)=mean(x)std(x)
这确保了所有专家都得到充分训练和利用。
结论
phi-3技术报告展示了通过精心的数据策划和架构创新,小型语言模型可以达到与大型模型相媲美的性能。从理论分析到实际部署,phi-3系列模型证明了高效AI系统的可行性。特别是phi-3-mini能够在手机上运行同时保持GPT-3.5级别的能力,这标志着向更普及和可访问的AI技术迈出了重要一步。