🔥 大语言模型(LLM)入门全解:从定义到训练的完整路径
发布于:2025年9月15日
关键词:LLM、大模型、预训练、SFT、RLHF、ChatGPT
2022年11月,OpenAI 发布了 ChatGPT,一夜之间,全球为之震动。
人们惊讶地发现,这个"聊天机器人"不仅能写诗、编程、批改作文,还能推理数学题、模仿名人风格写作,甚至能"一本正经地胡说八道"------这正是我们今天所熟知的"大语言模型(Large Language Model, LLM)"。
从那以后,BERT、T5 等传统预训练模型逐渐退居幕后,LLM 成为 NLP 的新主角。国内外科技巨头纷纷下场:阿里推出通义千问,百度发布文心一言,Meta 发布 LLaMA,Google 推出 Gemini......一场"大模型军备竞赛"正式打响。
但问题是:到底什么是 LLM?它和之前的语言模型有什么区别?它是如何被训练出来的?
本文将带你从零开始,系统梳理 LLM 的定义、能力、特点与三阶段训练流程,用通俗语言 + 真实案例 + 技术图解,帮你构建完整的 LLM 认知框架。
一、什么是 LLM?它不是"更大的 BERT"
1.1 LLM 的定义
简单来说,LLM 是参数量巨大、在海量语料上预训练的语言模型。
- "大":通常指参数量在 10亿以上,主流模型如 GPT-3(1750亿)、LLaMA-7B(70亿)、Qwen-72B(720亿)。
- "语言模型":本质仍是预测下一个词(token)的概率模型,与传统语言模型任务一致。
但 LLM 的"大",不仅仅是参数多,而是带来了质的飞跃 ------它具备了传统模型不具备的"涌现能力(Emergent Abilities)"。
📌 类比 :
小型语言模型像"背书的学生",只会机械复述;
而 LLM 像"博览群书的学者",能理解、推理、创造。
1.2 LLM 与传统 PLM 的核心差异
| 特性 | 传统预训练模型(如 BERT) | 大语言模型(如 GPT-4) |
|---|---|---|
| 架构 | Encoder-only | Decoder-only |
| 参数量 | 0.1B ~ 0.3B | 1B ~ 175B+ |
| 训练数据 | 数亿 token | 数千亿 ~ 数万亿 token |
| 下游任务 | 需要微调(Fine-tuning) | 可通过 Prompt 直接使用 |
| 核心能力 | 文本表示、分类 | 指令遵循、推理、生成 |
✅ 一句话总结 :
BERT 是"工具人",需要你教会它怎么做;
LLM 是"智能体",你只要告诉它"做什么"。
二、LLM 的四大核心能力:为什么它这么"聪明"?
LLM 的"智能感"并非偶然,而是源于四种关键能力的叠加。
2.1 涌现能力(Emergent Abilities)
"量变引起质变"
这是 LLM 最神秘也最吸引人的特性。当模型规模达到某个阈值后,某些能力会"突然出现"。
例如:
- 一个 10亿参数的模型可能连简单的加法都算错;
- 但一个 100亿参数的模型,突然就能解鸡兔同笼问题了。
📊 研究发现 :
数学推理、代码生成、逻辑判断等复杂任务,往往在模型参数超过 10B 后才显著提升。
这就像是水在 0°C 结冰、100°C 沸腾------模型能力随规模"相变"。
2.2 上下文学习(In-Context Learning)
"看例子就会做"
传统模型需要大量标注数据微调,而 LLM 只需在输入中给几个示例,就能学会新任务。
例子:
python
输入:
Q: 翻译成英文:今天天气真好
A: Today is a nice day!
Q: 翻译成英文:我很喜欢这本书
A: I really like this book.
Q: 翻译成英文:北京是中国的首都
A: LLM 会自动输出:Beijing is the capital of China.
✅ 优势:无需训练,节省成本,适合快速原型。
2.3 指令遵循(Instruction Following)
"听懂人话"
通过"指令微调(SFT)",LLM 学会理解人类指令并执行。
比如:
- "写一篇关于 AI 的科普文章"
- "用 Python 写一个冒泡排序"
- "总结这篇论文的核心观点"
这些指令在训练数据中出现过,但模型能泛化到从未见过的新指令。
🌟 ChatGPT 火爆的核心原因:它不再是"研究玩具",而是能直接服务用户的"智能助手"。
2.4 逐步推理(Step-by-Step Reasoning)
"会思考"
传统模型常在复杂推理任务上"翻车",而 LLM 可通过"思维链(Chain-of-Thought, CoT)"策略解决。
例子:
python
问题:小明有10个苹果,吃了3个,又买了5个,还剩几个?
模型输出:
小明一开始有 10 个苹果。
吃了 3 个,剩下 10 - 3 = 7 个。
又买了 5 个,现在有 7 + 5 = 12 个。
所以,小明现在有 12 个苹果。🔍 关键:模型不仅输出答案,还展示"思考过程",这让它更可信、可调试。
三、LLM 的其他特点:能力与风险并存
除了四大核心能力,LLM 还有以下特点:
3.1 多语言支持
由于训练数据包含多语言网页,LLM 天生支持多语言处理。
- GPT-4 能处理 100+ 种语言
- 但英文 > 中文 > 小语种(数据量决定)
🇨🇳 国产模型优势:通义千问、ChatGLM 在中文场景表现更优。
3.2 长文本处理
传统模型(如 BERT)最多处理 512 个 token,而 LLM 支持数千甚至数万。
- LLaMA-2 支持 4K 上下文
- Claude 支持 100K+ 上下文
- 可"读完一本书"再回答问题
📚 应用场景:合同分析、论文阅读、长代码理解。
3.3 多模态扩展
LLM 正在"跨界":
- 图文理解:GPT-4V、Qwen-VL
- 语音生成:Whisper + LLM
- 视频理解:Gemini、通义千问-V
🎥 未来趋势:LLM 将成为"多模态大脑"。
3.4 幻觉(Hallucination)
"一本正经地胡说八道"
LLM 会编造虚假信息,比如:
- 生成不存在的论文
- 编造历史事件
- 给出错误的医学建议
⚠️ 风险提示:在医疗、金融等高风险领域,必须结合检索(RAG)、人工审核等手段。
四、如何训练一个 LLM?三阶段全解析
训练一个 LLM 不是"一键生成",而是分三个阶段的系统工程:
python
[ Pretrain ] → [ SFT ] → [ RLHF ]
↓ ↓ ↓
知识库 会听话 说人话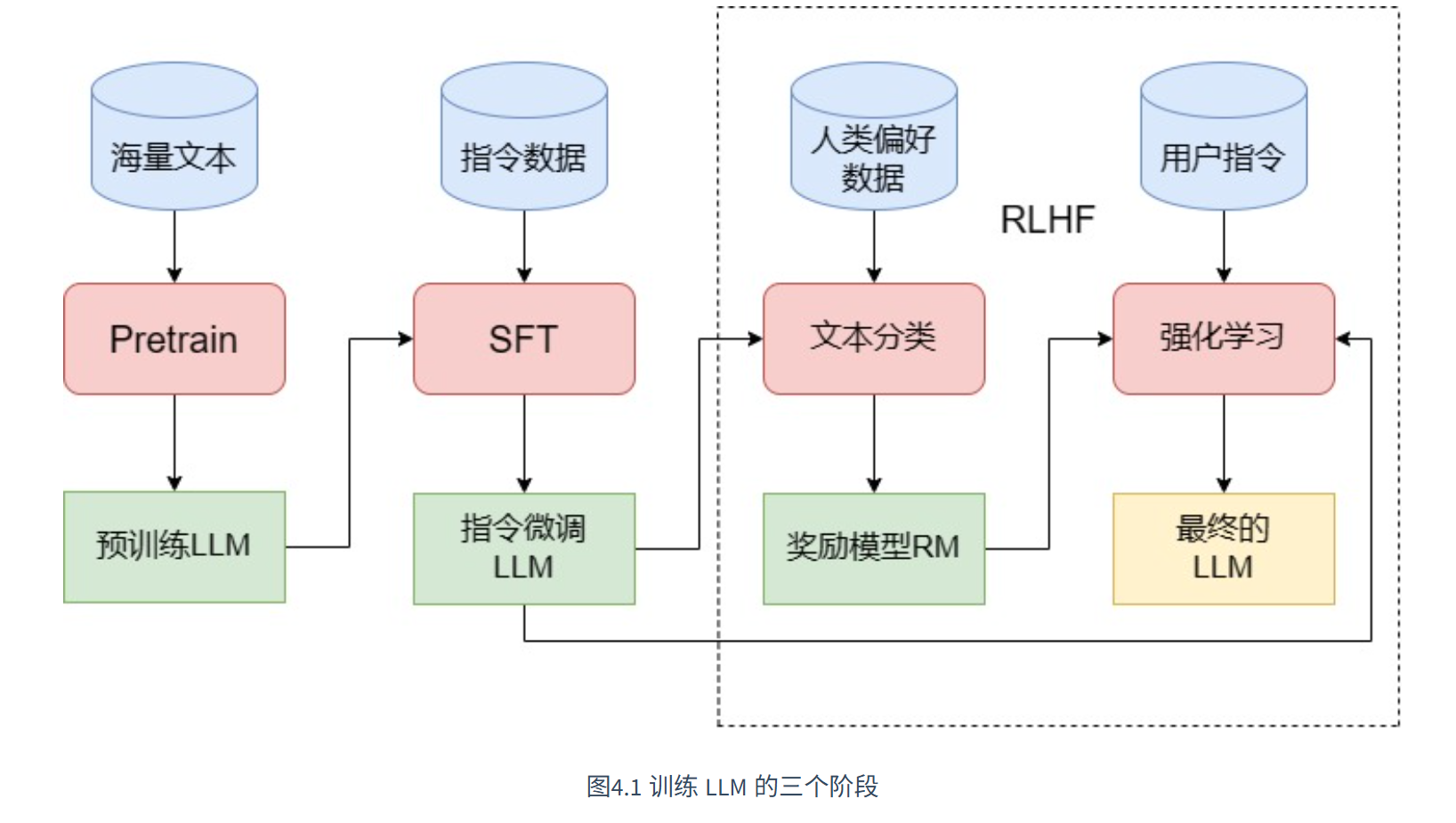 4.1 第一阶段:预训练(Pretrain)------ 打造"知识库"
4.1 第一阶段:预训练(Pretrain)------ 打造"知识库"
目标:让模型从海量文本中学习语言规律和世界知识。
- 架构:Decoder-only(如 GPT)
- 任务:因果语言模型(CLM)------ 预测下一个词
- 数据:CommonCrawl、Wikipedia、GitHub、ArXiv 等
- 资源:需要数百张 A100 GPU,训练数周
📊 数据配比示例(LLaMA):
- CommonCrawl: 67%
- C4: 15%
- GitHub: 4.5%
- Wikipedia: 4.5%
- 书籍、论文等:9%
💡 关键点 :数据质量 > 数据量。1T 垃圾数据 ≠ 600B 高质量数据。
4.2 第二阶段:监督微调(SFT)------ 教它"听话"
目标:让模型学会理解并执行人类指令。
- 数据格式:
python
{
"instruction": "翻译成英文",
"input": "今天天气真好",
"output": "Today is a nice day!"
}-
数据来源:
- 人工标注(成本高,质量高)
- 用 GPT-4 生成(如 Alpaca 数据集)
- 用户行为数据(如 API 调用记录)
-
多轮对话训练:让模型记住上下文,实现"连续对话"。
🌰 例子 : 用户:"我是 Datawhale 成员。"
用户:"你知道 Datawhale 吗?"
模型:"知道,是一个开源学习社区。"
4.3 第三阶段:人类反馈强化学习(RLHF)------ 让它"说人话"
目标:让模型输出更安全、有用、符合人类价值观。
流程分两步:
(1)训练奖励模型(Reward Model, RM)
- 给同一个问题生成多个回答
- 人工标注哪个更好(chosen vs rejected)
- 训练一个"打分器"来学习人类偏好
📊 训练数据示例:
(2)PPO 强化学习训练
- 使用 PPO(近端策略优化) 算法
- 模型生成回答 → RM 打分 → 模型优化
- 目标:最大化人类偏好得分
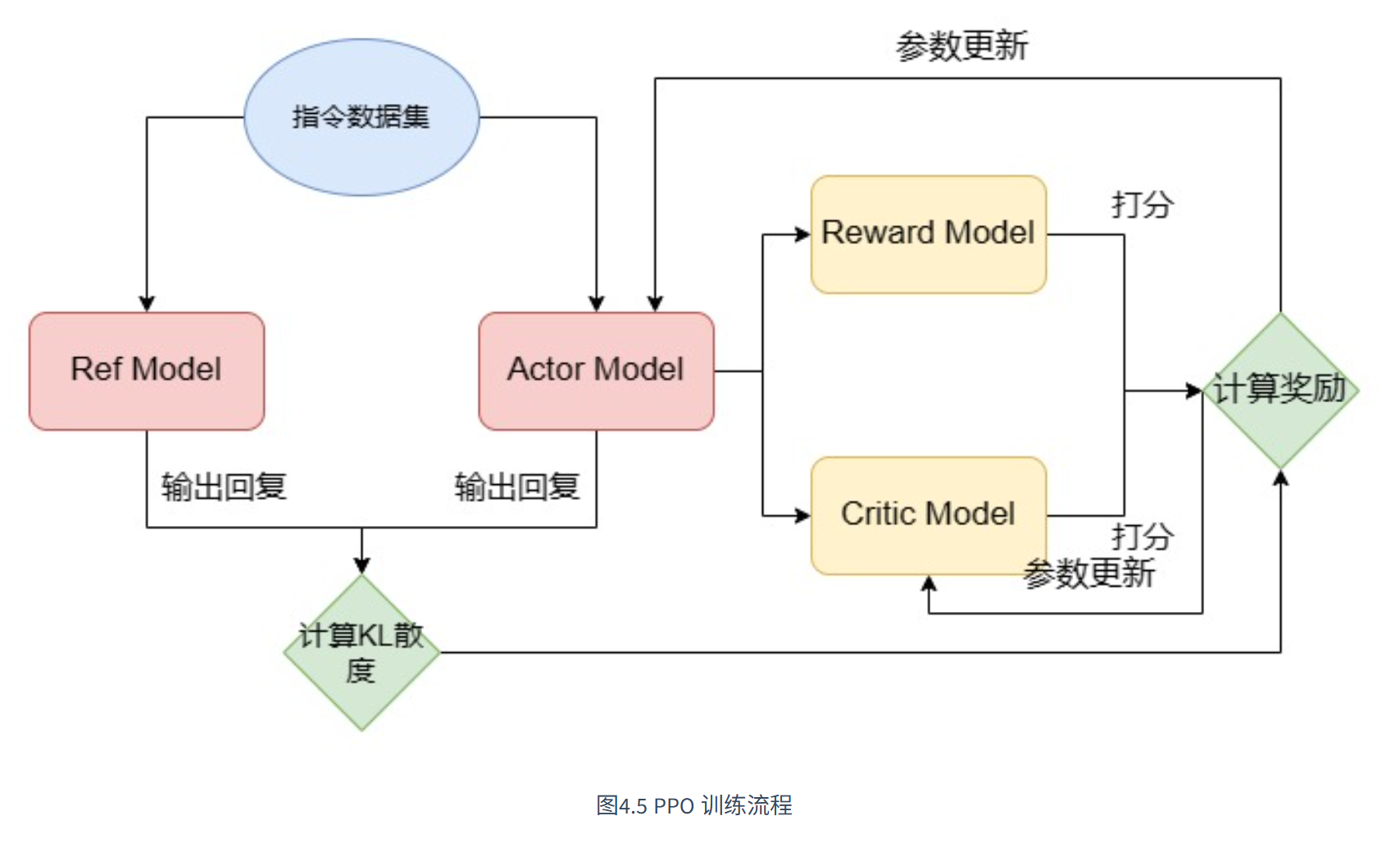
⚠️ 挑战:资源消耗大,需要 4 个模型并行(Actor、Ref、Critic、RM),显存需求翻倍。
4.4 替代方案:DPO(Direct Preference Optimization)
由于 RLHF 太复杂,DPO 提出了一种更简单的替代方案:
- 不训练 RM
- 不用强化学习
- 直接用偏好数据做监督学习
✅ 优势 :简单、高效、效果接近 RLHF
🔗 代表工作:Stanford 的 DPO 论文
五、结语:LLM 是工具,更是未来
LLM 不是魔法,它的"智能"源于:
- 海量数据
- 巨大模型
- 巧妙训练
但它仍有局限:
- 会幻觉
- 成本高
- 难控制
未来方向:
- 更小、更高效的模型(如 Qwen-1.8B)
- 更安全的对齐技术
- Agent、多模态、自主系统
📚 延伸阅读
- 《Attention Is All You Need》(Transformer 原始论文)
- 《Training Language Models to Follow Instructions》(InstructGPT)
- 《Direct Preference Optimization》(DPO 论文)
- HuggingFace LLM Course
作者有话说 :
如果你觉得这篇文章有帮助,欢迎点赞、收藏、转发。
想深入学习 LLM?