本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发视频及资料,尽在聚客AI学院。
Embedding模型是大型语言模型(LLM)的核心,负责将文本转换为高维向量空间中的数值表示,从而使语义关系转化为可计算的数学关系。如果选错Embedding模型,RAG系统可能会检索到不相关或低质量的数据,导致答案不准确、成本增加以及用户体验下降。今天我将深入探讨Embedding的核心概念、重要性、选择策略,并结合实际场景做解析。
一、Embedding是什么?
Embedding是一种捕捉语言含义和模式的数字表示形式,通过Embedding模型将词、句子、文档甚至图像和声音转换为称为"向量"的数字序列。这些向量帮助系统基于语义关联(而不仅是关键词匹配)找到与问题或主题最相关的信息。
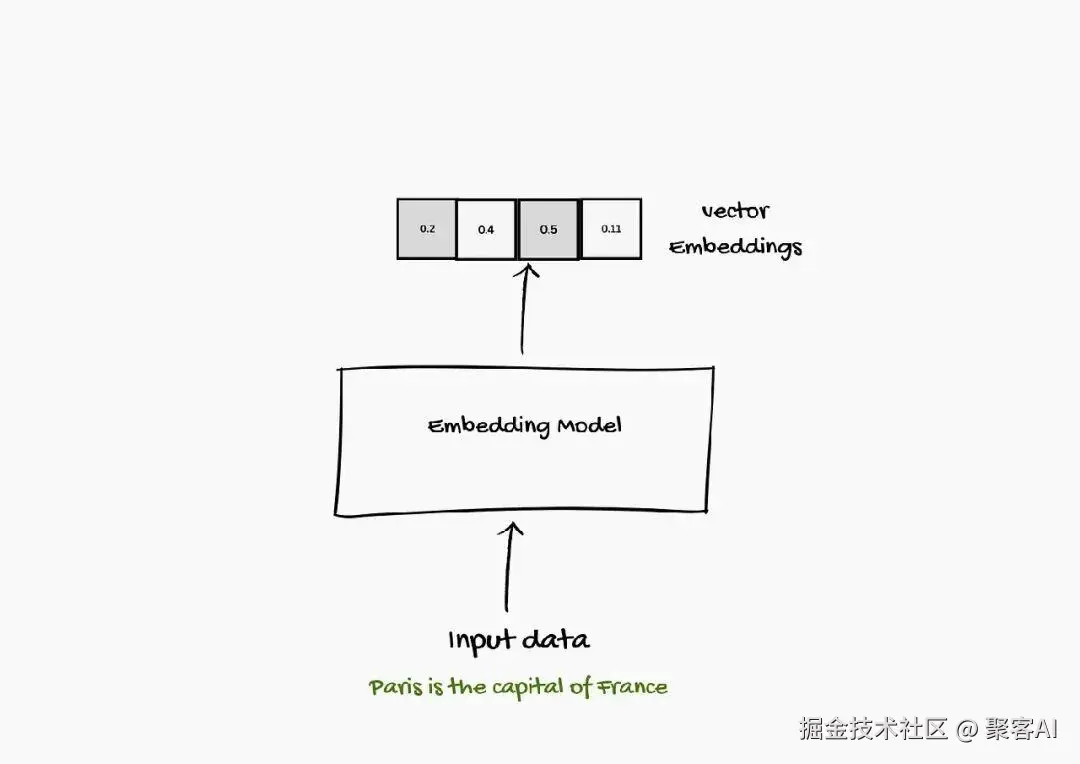
当前,大多数Embedding是通过语言模型生成的上下文化向量,而非静态词向量。例如,使用sentence-transformers这类工具库可以轻松生成文本Embedding:
ini
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("sentence-transformers/all-mpnet-base-v2")
vector = model.encode("Best movie ever!")生成的向量维度取决于所选模型,可通过vector.shape查看。
二、为什么Embedding在RAG中至关重要?
Embedding在RAG系统中扮演以下关键角色:
- 语义理解:将文本转换为向量后,语义相近的内容在向量空间中位置接近,使系统能够理解上下文和含义,而不只是字面匹配。
- 高效检索:基于Embedding的向量检索(如k近邻算法)可以快速定位最相关的文档或段落,显著提升响应速度。
- 提高准确性:借助语义关联,即使查询与文档措辞不同,系统也能找到相关信息,从而提供更准确的答案。
ps:当然在优化RAG系统中,除了选对Embedding模型以外,还有索引优化等,我这里就不多说,之前有整理过一个三万字的技术文档,粉丝朋友自行领取:《检索增强生成(RAG)》
三、Embedding的主要类型
根据处理的信息类型,Embedding可分为多种形式:
1. 按信息类型分类
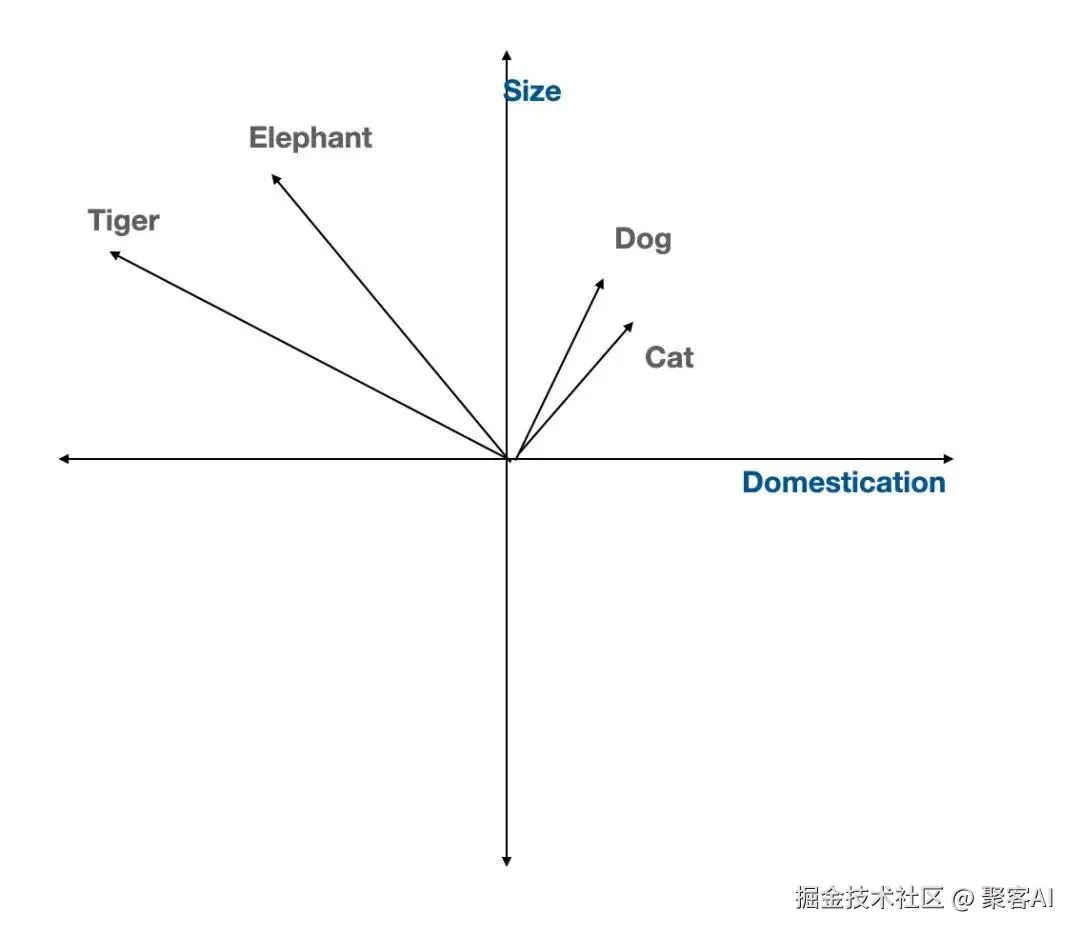
- 词嵌入(Word Embeddings):将单个词表示为向量,语义相似的词(如"dog"和"cat")在空间中靠近。常用模型包括Word2Vec、GloVe和FastText。
- 句子嵌入(Sentence Embeddings):捕捉整个句子的语义,适用于问答和语句分析。典型模型有Universal Sentence Encoder(USE)和SkipThought。
- 文档嵌入(Document Embeddings):将长文本(如段落或全书)转换为单个向量,便于大规模文档检索。代表模型包括Doc2Vec和Paragraph Vectors。
- 图像嵌入(Image Embeddings):将图像转换为描述颜色、形状等特征的向量,常用卷积神经网络(CNN)实现。
2. 按特性分类
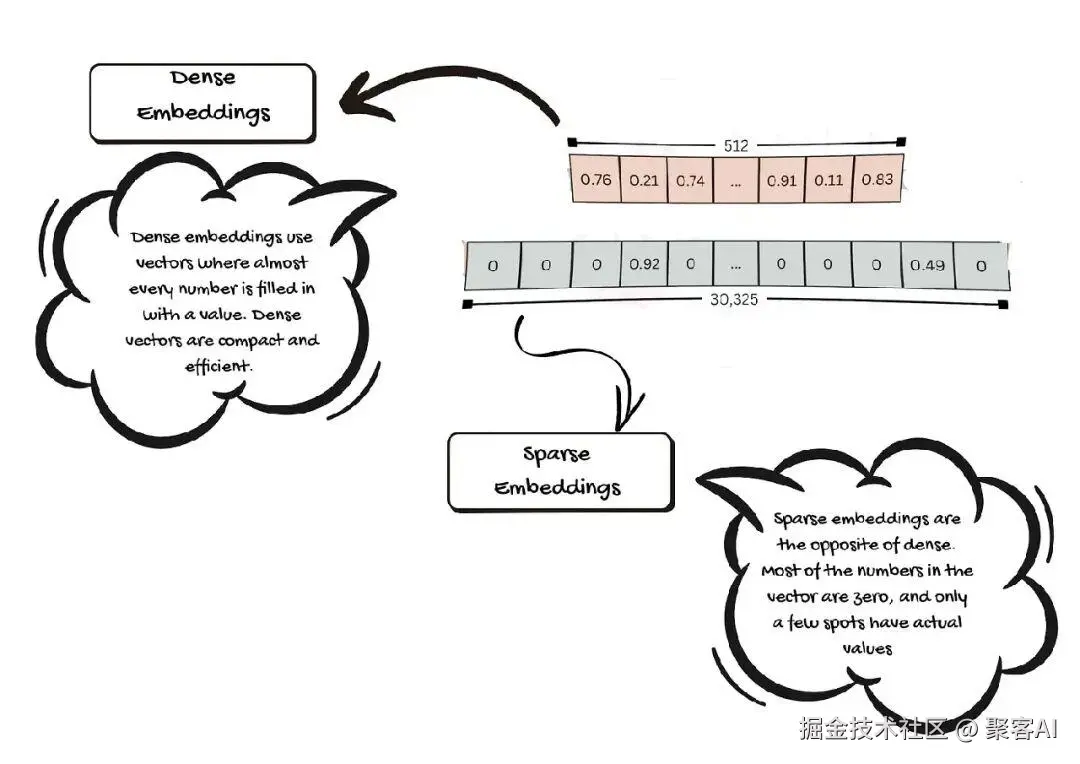
- 稠密嵌入(Dense Embeddings):向量中大多数维度都有数值,存储信息丰富,适合高效比较相似性。
- 稀疏嵌入(Sparse Embeddings):向量中多数值为零,仅少数维度有值,侧重于突出关键特征。
- 长上下文嵌入(Long Context Embeddings):专为处理长文本(如8,192 tokens)设计,避免因拆分文本丢失关键信息。例如BGE-M3模型。
- 多向量嵌入(Multi-Vector Embeddings):为同一对象生成多个向量,以捕捉不同方面的特征,提升细节丰富度。
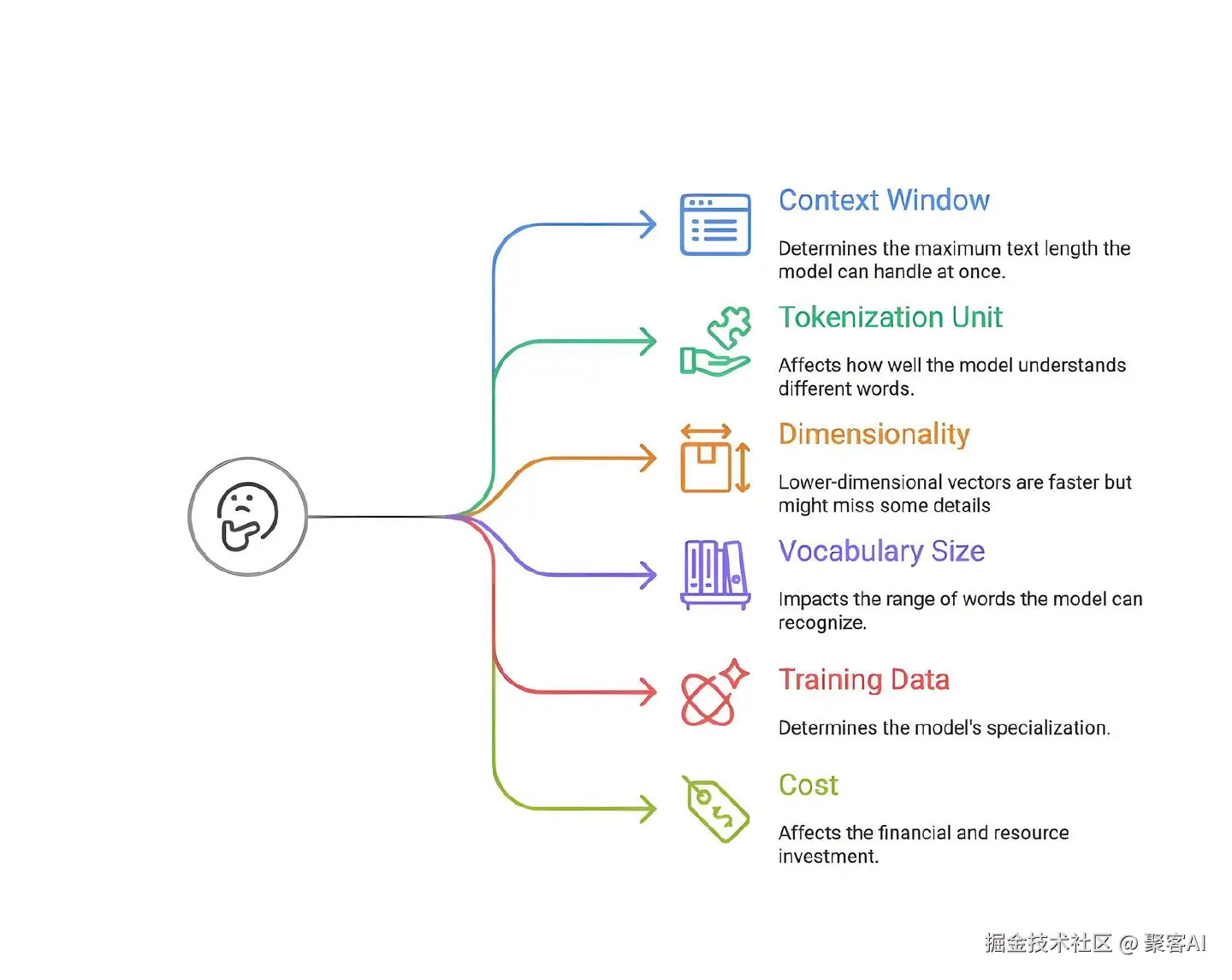
四、选择Embedding模型的关键参数
选择模型时需综合考虑以下因素:
- 上下文窗口(Context Window):模型单次能处理的最大文本量(如512或8,192 tokens)。窗口越大,越适合长文档检索。
- 分词单元(Tokenization Unit):模型如何拆分文本(如按词、子词)。现代模型多采用子词分词(如BPE),更好地处理罕见词。
- 向量维度(Dimensionality):向量大小(如768或1536维)。维度越高,细节越多,但计算成本也更高。
- 词汇表大小(Vocabulary Size):模型支持的唯一token数量。词汇表越大,处理多样文本能力越强,但资源占用更多。
- 训练数据(Training Data):通用模型(如基于网页数据)适用于广泛任务,领域特定模型(如医学、法律)在专业场景中表现更佳。
- 成本(Cost):包括API调用费用(如OpenAI按token收费)或自托管开源模型所需的硬件与维护成本。
五、实战指南:如何选择Embedding模型?
1. 分析数据领域
- 通用领域(如FAQ、知识库):选择通用模型(如OpenAI的text-embedding-3-small)。
- 专业领域(如医疗、法律):采用领域特定模型(如BioBERT、Legal-BERT)。
- 多模态数据(如图像、语音):使用多模态Embedding模型(如CLIP)。
2. 权衡模型复杂度与效率
- 高维向量(如1536维)准确性更高,但资源消耗大;低维向量(如384维)更轻量,适合大规模应用。
- 实时性要求高的场景优选轻量模型(如DistilBERT、MiniLM)。
3. 评估上下文理解能力
- 长文档处理需选择大上下文窗口模型(如支持8,192 tokens的模型)。
4. 确保集成兼容性
- 优先选择与现有基础设施(如TensorFlow、PyTorch、Hugging Face)兼容的模型。
5. 成本优化
- 高频调用场景下,开源自托管模型(如Jina Embeddings)可能更经济;低频率需求时,API模型(如OpenAI)更便捷。
结论
选择合适的Embedding模型是优化RAG应用的核心环节。需综合考虑领域特性、上下文长度、成本与性能平衡,并参考基准数据而非盲目追求高分模型。好了,今天的分享就到这里,点个小红心,我们下期见。