1.🚀 Scikit-learn入门与线性回归实战指南
流程图:
python
flowchart TD
A[Scikit-learn入门与线性回归实战] --> B[环境准备与安装]
A --> C[机器学习核心流程理解]
A --> D[线性回归模型实战]
A --> E[模型评估与结果解读]
B --> B1["安装Scikit-learn库<br>pip install scikit-learn"]
B --> B2["验证安装<br>import sklearn"]
C --> C1["数据加载与预处理"]
C --> C2["数据集划分"]
C --> C3["模型训练与评估"]
D --> D1["选择线性回归算法"]
D --> D2["训练模型"]
D --> D3["进行预测"]
E --> E1["计算MSE均方误差"]
E --> E2["计算R²决定系数"]
E --> E3["结果可视化"]📦 1.1 环境准备与Scikit-learn安装
核心目标:成功安装Scikit-learn库并验证安装。
1.1.1 安装Scikit-learn
- 确保你的Conda虚拟环境(如
ai_env)是激活状态。 - 在终端中运行以下命令使用pip安装
bash
# 使用pip安装,国内用户可添加清华源加速下载
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
# 或者使用conda安装(如果你更习惯conda)
# conda install scikit-learn1.1.2 验证安装
安装完成后,在终端中启动Python解释器,输入以下命令
python
import sklearn
print(sklearn.__version__) # 输出安装的scikit-learn版本号1.1.3 验收标准
- ✅ 终端执行安装命令无报错。
- ✅ 能成功导入
sklearn库并打印出版本号。
🔄 1.2 理解机器学习流程与数据准备
核心目标:理解机器学习的基本流程,并为线性回归模型准备数据。
1.2.1 机器学习基本流程
Scikit-learn中的机器学习工作流通常遵循以下步骤,理解它们对你后续的学习至关重要:
- 数据加载与预处理:获取数据,并进行清洗、归一化、编码等操作。
- 划分训练集/测试集:将数据集分为两部分,一部分用于训练模型,另一部分用于测试模型性能。
- 选择模型:根据任务选择合适的算法。
- 训练模型:使用训练数据来拟合模型。
- 评估模型:使用测试数据评估模型的性能
1.2.2 加载与准备数据
创建一个新的Python脚本(如linear_regression_demo.py),使用Scikit-learn内置的数据集进行练习:
python
# 导入必要的库
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# 加载内置的糖尿病数据集(这是一个常用的回归数据集)
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
# 查看数据集描述(可选,但有助于理解数据)
# print(diabetes.DESCR)
# 指定特征(X)和目标变量(y)
X = diabetes.data # 所有特征
y = diabetes.target # 目标变量:糖尿病指数
# 将数据划分为训练集和测试集[7,8](@ref)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# test_size=0.2 表示20%的数据作为测试集
# random_state 确保每次分割的结果一致,便于复现结果1.2.3 验收标准
- ✅ 能清晰描述机器学习流程中的关键步骤。
- ✅ 成功加载数据集并将其划分为训练集和测试集。
🤖 1.3 模型训练、评估与实战
核心目标:训练你的第一个线性回归模型,并进行预测和评估。
1.3.1 训练线性回归模型
在同一个脚本中继续添加以下代码:
python
# 创建线性回归模型对象
model = LinearRegression()
# 使用训练数据训练模型[6,8](@ref)
model.fit(X_train, y_train)
# 使用训练好的模型对测试集进行预测[6,8](@ref)
y_pred = model.predict(X_test)1.3.2 评估模型性能
继续添加评估代码:
python
# 计算均方误差(MSE)[9,11](@ref)
mse = mean_squared_error(y_test, y_pred)
print(f"均方误差(MSE): {mse:.2f}")
# 计算决定系数(R²分数)[9,11](@ref)
r2 = r2_score(y_test, y_pred)
print(f"决定系数(R²分数): {r2:.4f}")
# (可选)输出模型系数和截距,理解模型
print(f"模型系数: {model.coef_}")
print(f"模型截距: {model.intercept_}")1.3.3 结果可视化
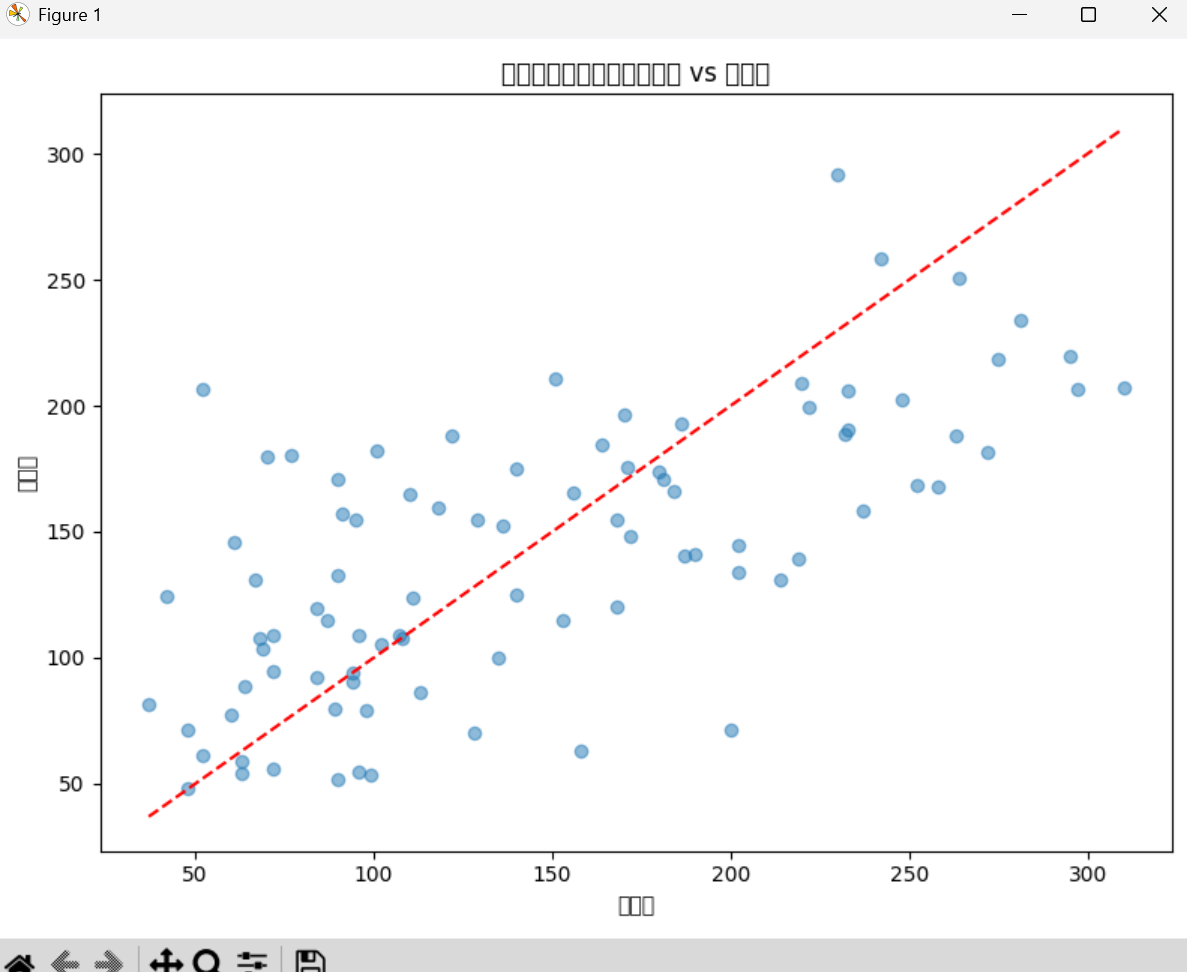
为了更直观地理解预测结果,可以绘制真实值与预测值的散点图:
python
# 绘制真实值与预测值的散点图
plt.figure(figsize=(8, 6))
plt.scatter(y_test, y_pred, alpha=0.5)
plt.xlabel("真实值")
plt.ylabel("预测值")
plt.title("线性回归预测结果:真实值 vs 预测值")
# 添加理想拟合线(y=x)
min_val = min(y_test.min(), y_pred.min())
max_val = max(y_test.max(), y_pred.max())
plt.plot([min_val, max_val], [min_val, max_val], color='red', linestyle='--')
plt.tight_layout()
plt.show()1.3.4验收标准
- ✅ 成功训练线性回归模型并对测试集进行预测。
- ✅ 计算并输出了MSE和R²分数。对于糖尿病数据集,R²分数通常在0.3到0.5之间,这属于正常范围。
- ✅ (可选)成功绘制了真实值与预测值的对比图。