同步更新至个人站点:长期以来我对 LLM 的误解
大家好,我是 mCell。
最近半年,我一直在折腾各种大语言模型(LLM),从 GPT 到 Gemini,再到国产的 DeepSeek、Qwen。我用它们当搜索引擎、写代码、甚至帮我完成期末作业的实验报告。作为一个开发者,我一直在思考一个问题:这东西的底层到底是怎么工作的?
一个朴素的疑问
我的疑问很简单:LLM 说到底只是一堆代码,它怎么就能"理解"我说的话呢?
按照我们传统程序员的思维,一个程序要实现特定功能,就需要明确的逻辑映射。比如,我们要写一个智能客服,代码可能是这样的:
python
def handle_query(query):
if "天气" in query and "今天" in query:
return get_todays_weather()
elif "你好" in query or "早上好" in query:
return "你好!有什么可以帮你的吗?"
else:
return "抱歉,我听不懂你在说什么。"这种基于关键词和规则的方式,简单直接,但死板得像个石板。我们必须为每一种可能性预设好程序的分支。很多年前的手机助手,大抵就是这个逻辑。
但是,现在的 LLM 完全不同。我可以直接对它说"早上好",它会像真人一样回复"早上好!今天又是元气满满的一天呢",甚至可能还会根据上下文,附上一句"今天有什么安排吗?"。
我查看了那些开源模型的代码,并没有找到类似 if query == "早上好" 这样的特殊处理。谁说计算机没有黑魔法,这不就是魔法吗?
Ollama、7GB 文件和代码仓库
我最开始接触本地化运行大模型,是从 ollama 开始的。它的确非常方便,一条命令就能把模型跑起来:
bash
ollama run qwen:7b执行这条命令后,最让我印象深刻的是下载过程。一个 qwen:7b 模型,下载的文件体积动辄 7GB、14GB。
这让我非常困惑。我去 GitHub 上看 Qwen 的官方仓库,把整个项目克隆下来,所有 Python 代码加起来也不过几十 MB。
7GB 的庞然大物,和几十 MB 的代码,这两者是什么关系?
一开始我以为,它是不是像传统软件一样,附带了一个巨大的数据库?运行的时候,代码从这个数据库里检索信息?但这个猜测很快被我自己推翻了,我逐渐了解到 LLM 的回答是生成式的,而不是检索式的。它可以创造出全新的、数据库里根本不存在的句子。
很长一段时间,我都错误地认为那些代码本身通过某种我无法理解的复杂算法实现了"智能"。直到最近,我才恍然大悟:我一直忽略了模型真正的核心------参数。
被下载的不是"数据",而是"大脑"
现在我可以回答我自己的问题了。
GitHub 上的代码,是 LLM 的 "骨架"或者说"引擎" 。它定义了一个叫做"Transformer"的神经网络结构,并规定了数据(也就是我们的文字)如何在其中流动和计算。它本身是"空"的,没有任何知识。
而我们通过 ollama 下载的那个 7GB 的文件,才是 LLM 的 "大脑"和"灵魂" 。它的官方名字叫做 模型参数(Parameters)或模型权重(Weights)。
这个文件里存储的是数十亿(7B 就是 70 亿)个经过训练优化的浮点数。这些数字,就是模型从数万亿单词的语料库中学习到的所有知识的浓缩和结晶。
这个学习过程被称为 "训练" 。你可以把它想象成一个极其复杂的拟合过程。模型看到"天空是"这句话,它被要求预测下一个词。它一开始会瞎猜,比如猜"绿色的"。然后我们告诉它,标准答案是"蓝色的"。它就会微调内部那 70 亿个参数,让自己下一次遇到类似情况时,猜出"蓝色的"概率高一点点。
这个过程重复数万亿次之后,模型内部的参数就形成了一种极其微妙的平衡。它不再是简单地记忆,而是学会了语法、逻辑、事实,甚至是某种程度上的"推理"能力。
所以,当我们输入"早上好"时,整个流程是这样的:
-
输入处理 :推理代码(骨架)首先将"早上好"这三个汉字,通过一个叫做 Tokenizer 的工具,转换成一串数字 ID(比如
[234, 567, 890])。 -
矩阵运算:这串数字被输入到模型网络中,与那 7GB 文件里的 70 亿个参数进行一系列大规模的矩阵乘法运算。
-
概率输出:运算的结果,是模型预测出的词汇表里每一个词在当前位置出现的概率。比如,"!"的概率可能是 30%,"今"的概率可能是 20%,"你"的概率可能是 15%......
-
文本生成:代码根据这些概率,选择一个词(通常是概率最高的那个)作为输出,然后把这个新生成的词再作为新的输入,重复上述过程,直到生成完整的句子。
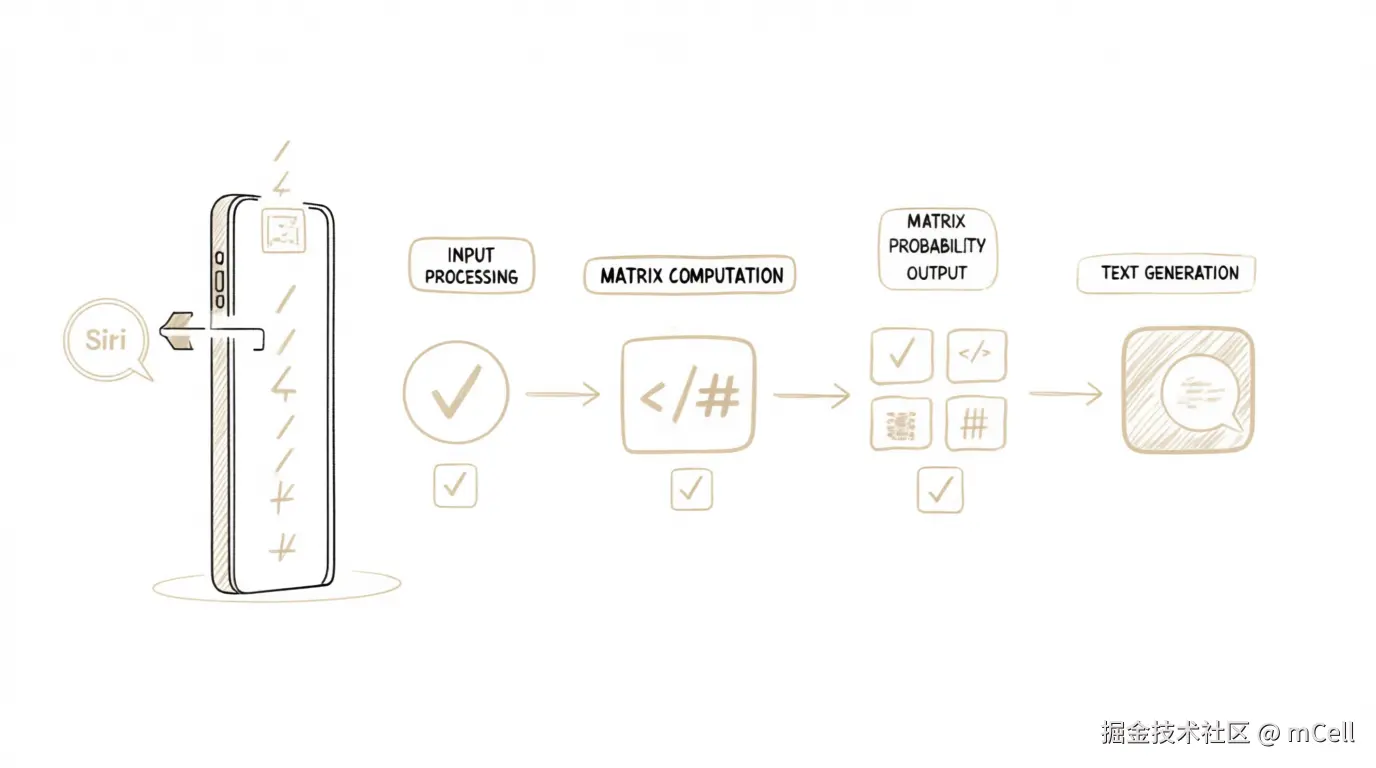
整个过程,没有一行 if-else 来判断用户意图,全都是冰冷的、确定性的数学计算。所谓的"智能"和"理解",就蕴含在那 70 亿个参数构成的复杂函数之中。
从规则到概率的飞跃
想通了这一点,我有一种豁然开朗的感觉。
我们正处在一个范式转换的时代。传统的编程思维是基于规则的、确定性的 。我们告诉计算机每一步该做什么。而 LLM 的思维是基于概率的、涌现性的。我们构建一个能够学习的框架,然后用海量数据"喂养"它,让"智能"从中自然"涌现"出来。
这或许就是为什么 LLM 能处理如此复杂和模糊的人类语言的原因。因为语言本身,在很多时候就不是一个严格的逻辑系统,而是一个充满了习惯、文化和上下文的概率系统。
所以,LLM 不是一个装满了数据的"超级数据库",它是一个学会了语言规律的"概率计算引擎"。它的代码是骨架,而巨大的参数文件,才是它智慧的真正载体。
参考链接:
- The Illustrated Transformer (一篇非常经典的图解 Transformer 的文章)
- Ollama 官方网站
- Qwen (通义千问) GitHub 仓库
(完)