目录
[在 WSL2 Ubuntu 安装必备环境](#在 WSL2 Ubuntu 安装必备环境)
[下载并配置 Hadoop](#下载并配置 Hadoop)
[启动 / 停止 Hadoop](#启动 / 停止 Hadoop)
[Spring Boot 空项目](#Spring Boot 空项目)
本文目标:在 WSL2 的 Ubuntu 里跑起单机版 Hadoop(伪分布式),并建好 Spring Boot 空工程
在 WSL2 Ubuntu 安装必备环境
安装 JDK 17
bash
sudo apt install openjdk-17-jdk -y验证:
bash
java -version安装 Maven 和 Git
bash
sudo apt install maven git -y验证:
bash
mvn -v
git --version安装 SSH
Hadoop 的伪分布式需要本机 SSH:
bash
sudo apt install openssh-server -y生成免密钥:
bash
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys测试:
bash
ssh localhost应该能直接登录,不再要密码。
下载并配置 Hadoop
创建用户并加权限
bash
# 创建 hadoop 用户
sudo adduser hadoop
# 给 hadoop 用户 sudo 权限
sudo usermod -aG sudo hadoop切换用户
bash
su - hadoop进入工作目录
bash
mkdir -p ~/bigdata-labs && cd ~/bigdata-labs下载 Hadoop(3.3.x 为稳定版)
在浏览器打开https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
下载好后放到 /home/hadoop/bigdata-labs 下
解压并更名
bash
tar -xvzf hadoop-3.3.6.tar.gz
mv hadoop-3.3.6 hadoop配置环境变量(hadoop 用户)
编辑:
bash
nano ~/.bashrc加入:
bash
export HADOOP_HOME=/home/hadoop/bigdata-labs/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin添加之后按ctrl + o 保存,然后按enter确认修改,最后按ctrl + x 退出
刷新:
bash
source ~/.bashrc继续配置环境变量:
bash
echo 'export HADOOP_HOME=~/bigdata-labs/hadoop' >> ~/.bashrc
echo 'export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin' >> ~/.bashrc
source ~/.bashrc修改 hadoop-env.sh,指向 JDK17:
bash
nano ~/bigdata-labs/hadoop/etc/hadoop/hadoop-env.sh在最末尾添加:
bash
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64配置 NameNode 地址
在文件夹中找这个路径,\home\hadoop\bigdata-labs\hadoop\etc\hadoop
找到之后有一个 core-site.xml 文件,加入:
bash
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>这里的 localhost:9000 就是 NameNode 的 RPC 服务地址
然后找 hdfs-site.xml 文件
加入:
bash
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/bigdata-labs/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/bigdata-labs/hadoop/dfs/data</value>
</property>
</configuration>dfs.namenode.name.dir 存储 NameNode 的元数据(namespace、FSImage、EditLog 等)
dfs.datanode.data.dir 存储 DataNode 的实际数据块
继续找 yarn-site.xml 文件
加入:
bash
<configuration>
<!-- ResourceManager 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
<!-- NodeManager 管理容器时用的执行器 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>找到 mapred-site.xml 文件
加入:
bash
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>然后由于JDK 17 的模块限制在卡 Guice/cglib(YARN 的 Web/注入框架),默认不允许用反射访问 java.lang 里的受限方法。所以需要给 YARN(以及 Hadoop/MapReduce 守护进程)加上 --add-opens 启动参数
bash
nano $HADOOP_HOME/etc/hadoop/yarn-env.sh在文件末尾追加一行
bash
export YARN_OPTS="$YARN_OPTS \
--add-opens=java.base/java.lang=ALL-UNNAMED \
--add-opens=java.base/java.lang.reflect=ALL-UNNAMED \
--add-opens=java.base/java.io=ALL-UNNAMED"
bash
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh在文件末尾追加一行
bash
export HADOOP_OPTS="$HADOOP_OPTS \
--add-opens=java.base/java.lang=ALL-UNNAMED \
--add-opens=java.base/java.lang.reflect=ALL-UNNAMED \
--add-opens=java.base/java.io=ALL-UNNAMED"
bash
nano $HADOOP_HOME/etc/hadoop/mapred-env.sh在文件末尾追加一行
bash
export MAPRED_OPTS="$MAPRED_OPTS \
--add-opens=java.base/java.lang=ALL-UNNAMED \
--add-opens=java.base/java.lang.reflect=ALL-UNNAMED \
--add-opens=java.base/java.io=ALL-UNNAMED"启动 / 停止 Hadoop
格式化 HDFS(首次需要)
bash
hdfs namenode -format启动
bash
start-dfs.sh
start-yarn.sh验证
bash
# 看进程
jps可以看到以下五个内容
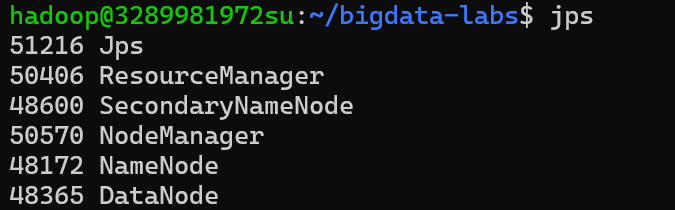
检查 Web UI
NameNode: http://localhost:9870
ResourceManager: http://localhost:8088 (应能看到 1 个活跃的 Node)
停止
bash
stop-yarn.sh
stop-dfs.shSpring Boot 空项目
在 IDEA 里新建 Maven 项目 spring-hadoop-playground,依赖:
XML
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.3.6</version>
</dependency>测试启动类:
java
@SpringBootApplication
public class HadoopPlaygroundApp {
public static void main(String[] args) {
SpringApplication.run(HadoopPlaygroundApp.class, args);
}
}运行后控制台输出 Started HadoopPlaygroundApp 即成功
一键脚本(WSL)
平常如果不写脚本,需要手动敲两条命令:
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh
这样才能同时启动 HDFS(NameNode、DataNode、SecondaryNameNode) 和 YARN(ResourceManager、NodeManager)
脚本的作用:自动化
把这两条命令放进一个 start-hadoop.sh 脚本文件里,下次只要敲:
bash
./start-hadoop.sh就能一键启动全部服务。
具体操作:
bash
nano start-hadoop.sh加入:
bash
#!/bin/bash
$HADOOP_HOME/sbin/start-dfs.sh
$HADOOP_HOME/sbin/start-yarn.sh然后保存退出
赋权
bash
chmod +x start-hadoop.sh给脚本执行权限
运行
bash
./start-hadoop.sh一键执行,省得每次都手动输入两条命令