机器学习:编码方式
- 编码概念
- 编码分类及实现
-
- 1.无序编码-one-hot编码
-
- [1.1 one-hot编码](#1.1 one-hot编码)
- [1.2 one-hot编码的实现](#1.2 one-hot编码的实现)
-
- [1.2.1 get_dummies](#1.2.1 get_dummies)
- [1.2.2 onehotEncoder](#1.2.2 onehotEncoder)
- 2.无序编码-目标编码
-
- [2.1 目标编码](#2.1 目标编码)
- [2.2 目标编码的实现](#2.2 目标编码的实现)
- 3.有序编码-标签编码
- 4.有序编码-序数编码
-
- [4.1 序数编码](#4.1 序数编码)
- [4.2 序数编码的实现](#4.2 序数编码的实现)
- 总结
编码概念
在对分类任务进行预测的时候,通常需要对目标类别进行编码(Encode),这里主要介绍在机器学习中常用的几种编码方式。包括:one-hot编码(独热编码)、标签编码、目标编码、序数编码。
编码分类及实现
1.无序编码-one-hot编码
1.1 one-hot编码
one-hot编码又称作独热编码,简称独热码。其主要是对无序的分类变量 进行编码,核心思想是创造一个二进制列(0/1),每一类中仅有一位为1,设有n个类别,则生成的one-hot编码中每个类别有n位,其中1位为1,(n-1)位为0。
例如:categories = '北京','上海','北京','江苏','浙江'
处理过程如下:
①会先对categories进行去重,得到{'上海', '北京', '江苏', '浙江'}
②排序,得到'上海', '北京', '江苏', '浙江'
③索引分配,上海---0,北京---1,江苏---2,浙江---3
④转换为独热码
| 类别 | 独热码 |
|---|---|
| 上海 | 1000 |
| 北京 | 0100 |
| 江苏 | 0010 |
| 浙江 | 0001 |
根据上表可以发现,对于独热码,如果类别很多,会引入类别内存较大,在使用神经网络时如果输入到全连接层,则容易导致梯度爆炸的问题。
1.2 one-hot编码的实现
1.2.1 get_dummies
python
# 1.使用pandas实现one-hot编码
import pandas as pd
a = pd.DataFrame({'color':['red','green','blue','red','black']})
category = pd.get_dummies(a.color,prefix='color')
print(category.astype('int'))①首先进行去重,得到:{'red','green','blue','black'}
②按照字符串排序规则得到:'black','blue','green','red'
③索引分配,black---0,blue---1,green---2,red---3
④转换为独热码

1.2.2 onehotEncoder
python
# 2.使用sklearn实现one-hot编码
from sklearn.preprocessing import OneHotEncoder
import pandas as pd
a = pd.DataFrame({'color':['red','green','blue','red','black']})
encoder = OneHotEncoder(sparse_output=False) # 是否显示为稀疏矩阵
category = encoder.fit_transform(a)
print(category.astype('int'))实现结果如下:

2.无序编码-目标编码
2.1 目标编码
目标编码是一种将分类变量转化为具体数值特征的办法,其核心思想是用目标变量的均值作为该类别的编码。
例如:对于以下变量
| 类别 | 目标 |
|---|---|
| A | 1 |
| A | 0 |
| B | 1 |
| B | 1 |
| C | 0 |
则目标编码的结果为
类别A:(1+0)÷2=0.5
类别B:(1+1)÷2=1
类别C:0÷1=0
这种方式有一种弊端,即类别过多的时候,可能存在类别是相同均值的两个或多个类。此时会导致模型学习困难
2.2 目标编码的实现
python
# 使用category_encoders实现目标编码
from category_encoders import TargetEncoder
cities = ['A','A','B','B','C']
price = [1,0,1,1,0]
encoder = TargetEncoder()
category = encoder.fit_transform(cities,price)
print(category)结果如下:

和案例分析不一致,主要是在category_encoder中引入了平滑处理。
3.有序编码-标签编码
3.1标签编码
在处理有顺序的类别的时候,此时编码需要按照一定的顺序进行排序。此时可以使用标签编码(默认使用字母顺序排序)
例如:'A','B','C','D','A'
则排序后类别如下:0,1,2,3,0
3.2标签编码的实现
python
# 使用sklearn实现标签编码
from sklearn.preprocessing import LabelEncoder
category = ['A','B','C','D','A','C']
encoder = LabelEncoder()
category = encoder.fit_transform(category)
print(category) # [0,1,2,3,0,2]输出结果为:
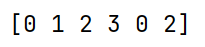
4.有序编码-序数编码
4.1 序数编码
从第3节中可知,标签编码按照字母顺序排序,而现实中大部分排序都不是利用按照字母进行排序 ,例如在学历中,是'小学','初中','高中','本科','硕士','博士',此时可以使用序数编码自定义排序规则。
例如:设置规则为:'小学','初中','高中','本科','硕士','博士'
如果输入的类别列为'初中','本科','小学','初中','硕士','初中','博士'
则输出为1,3,0,1,4,1,5
4.2 序数编码的实现
python
# 使用sklearn实现序数编码
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
education_order = [['小学','初中','高中','本科','硕士','博士']]
order_list = ['初中','本科','小学','初中','硕士','初中','博士']
encoder = OrdinalEncoder(categories=education_order)
category = encoder.fit_transform(np.array(order_list).reshape(-1,1))
print(np.array(category).astype('int').flatten()) # [1,3,0,1,4,1,5]输出结果如下:
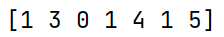
总结
下面将常用的编码方式比较如下
| 编码方式 | 适用情况 | 缺点 | 概念 |
|---|---|---|---|
| one-hot编码 | 分类变量且无序变量 | 类别多容易导致梯度爆炸 | n-1位0,1位为1的二进制编码 |
| 目标编码 | 使用与分类变量和连续变量 | 数据泄露,均值重合导致类别重合 | 类别的目标均值 |
| 标签编码 | 有序变量,按字母排序 | 不能适配大部分有序情况 | 按字母排序,从0开始 |
| 序数编码 | 有序变量,可以自定义排序规则 | -------------- | 按照传入的顺序进行排序,从0开始 |