我们知道JVM划分为4个区域,分别为程序计数器,元数据区,栈和堆,这些区域都会占据一部分空间,所以要针对这些空间进行释放
对于程序计数器来说,等对应的线程执行完毕,对应的空间就会自然释放了
对于元数据区来说,因为元数据区里一般存的是类对象相关的一些信息,这部分空间一般不会释放
对于栈来说,等对应的方法执行结束,对应的空间也会自然释放
对于堆来说,主要是存储了new出来的那部分空间,所以主要是针对new出来的那部分空间进行回收,堆中可能既包含了刚刚创建好的对象,可能也包含了即将要回收的对象,所以回收堆中的内存,也可以是看做回收对象
而GC就是针对回收堆中的对象设计的
GC的工作过程主要是分为2步,首先是找到垃圾,也就是找到不在使用的对象,然后就是回收垃圾,也就是释放对应的内存
步骤一:找到垃圾
我了解到的垃圾回收的基本策略有两个,一个是引用计数,另一个就是可达性分析
1.引用计数
引用计数就是在每次new对象的时候,都会搭配一块小的内存空间来保存一个整数,这个整数代表有多少个对象指向了这部分空间,如下图,以new Test()为例
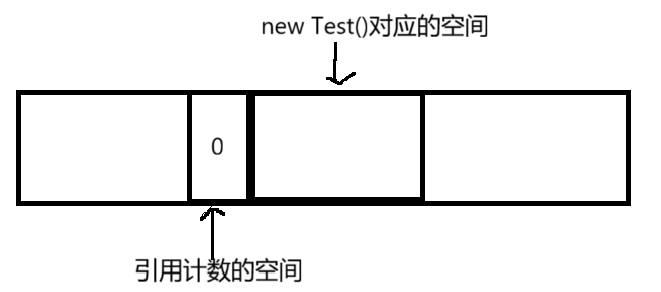
一开始引用空间里面的整数的值为0,表示当前没有对象指向new Test()的那部分空间
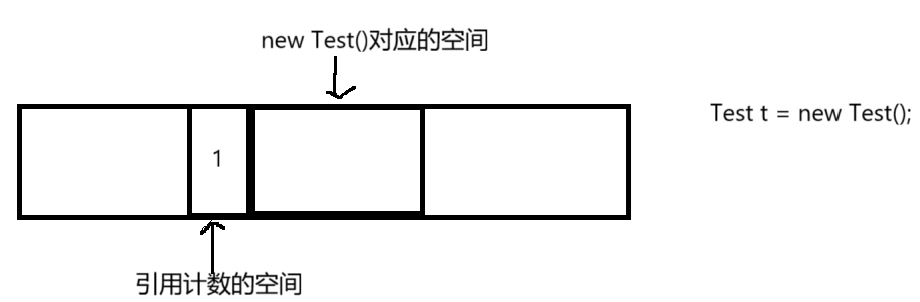
当我们在代码中创建了一个对象t,也就是写了Test t = new Test(),此时就有一个对象t指向了new Test那部分空间,此时引用计数空间里的那个整数就会变为1
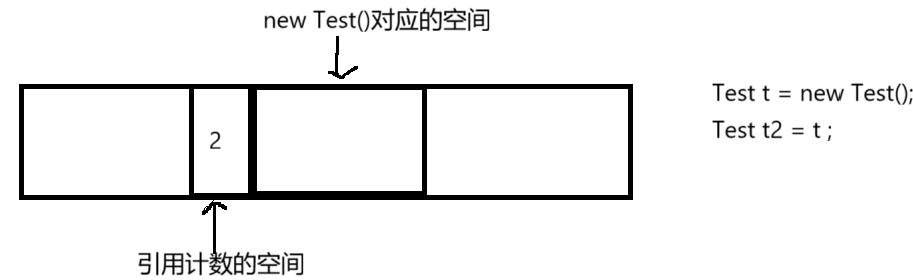
此时如果继续写了Test t2=t,此时引用空间里面的计数值就会变为2
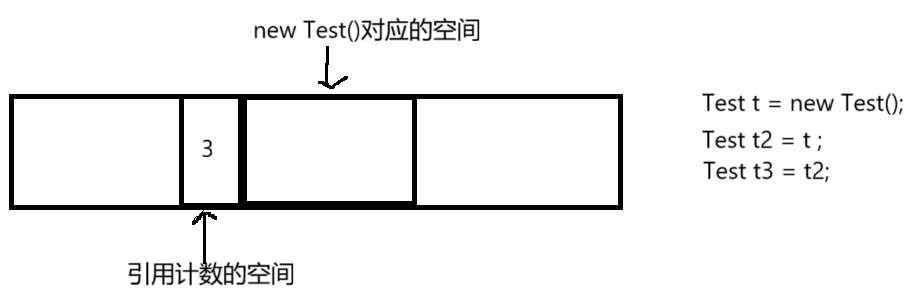
以此类推,写了Test t3 = t2
如果此时写了t==null,此时t就不指向new Test()那部分空间了,此时引用计数空间里面的值就会变为2,如下图
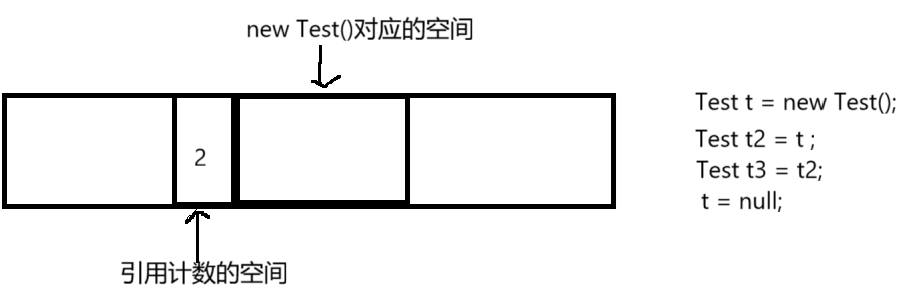
所以,当引用计数空间里面的值为0时,就代表没有对象指向new Test()这部分空间了,此时就可以回收这部分内存了
但是引用计数有两个缺点:
缺点一就是会消耗更多的内存,假设new的那部分空间大小只有8个字节,而引用计数使用的空间就却占了4个字节,这样一对比,如果使用了引用计数就会多出来50%的空间,这样就导致内存会消耗的更多的内存
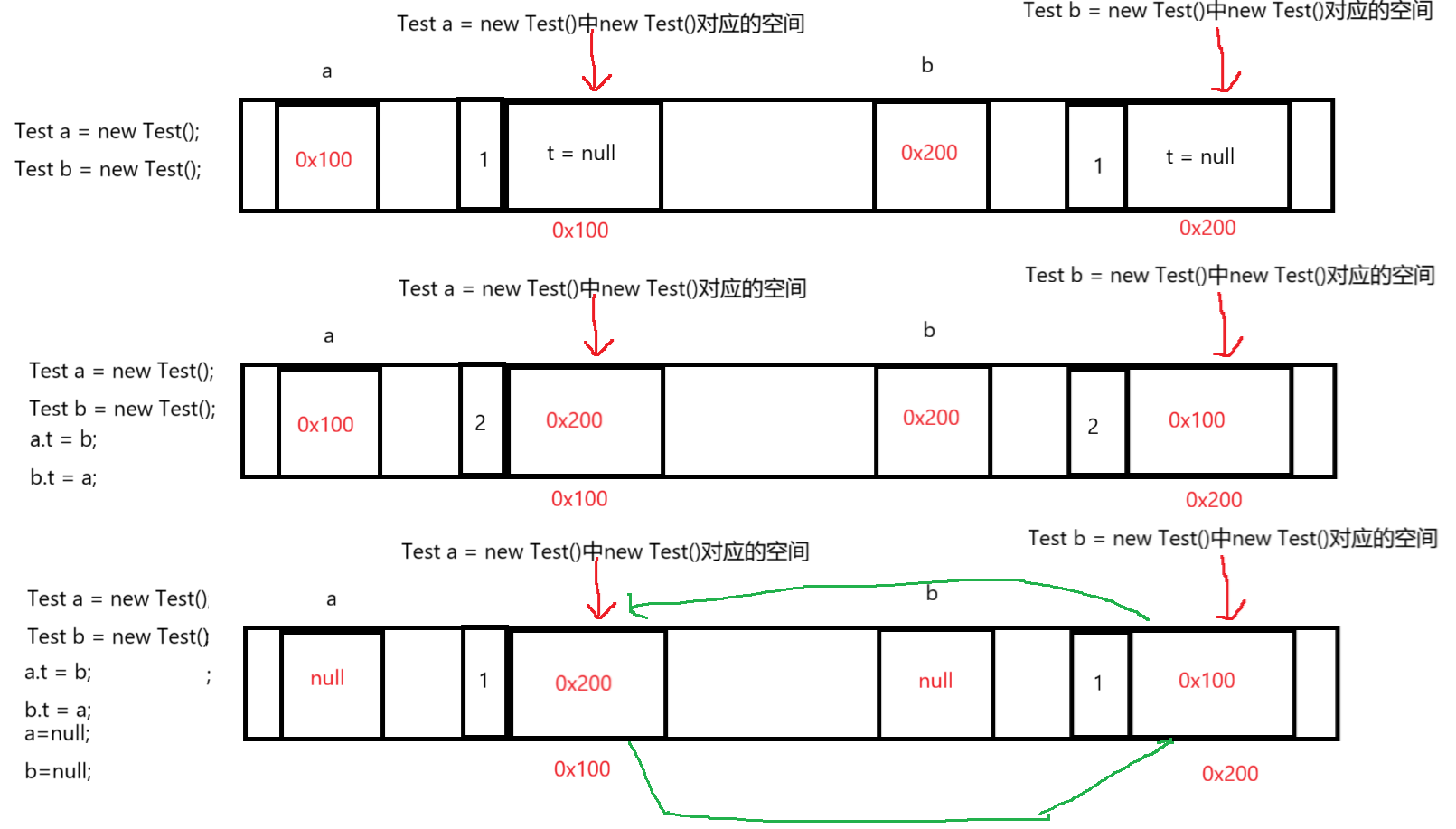
缺点二就是引用计数存在循环引用的问题,如下图,
发现最终因为a=null和b=null,导致连个引用计数的值都为1,虽然引用计数的值不为0了,但是发现如果我们想使用Test b = new Test()中的new Test()的那部分空间,首先就要找到指向0x200这个地址的引用,但是如果我们想找到指向0x200的这个引用,就必须要找到那个指向0x100的引用,这样就导致了类似于死锁的效果,结果就导致即使引用计数的值不为0,但是这部分空间还是使用不了,这就是循环引用的问题
2.可达性分析
可达性分析是Java采取的垃圾回收策略
可达性分析就是在Java代码中,会一些特定的变量为作为遍历的起点,这些特定的变量有栈上的局部变量 、常量池应用指向的对象和静态成员,以这个起点开始尽可能去遍历存在的对象,并判断该对象是否能够访问,每次访问到一个对象,都会将这个对象标记为可达,JVM中有多少个对象JVM本身是知道的,这样一轮遍历之后,就可以知道有多少个对象就被标记为可达,,也可以知道有多少个对象没有被标记为可达,那么这些没有被标记为可达的对象就会被视为垃圾被回收
步骤二:释放垃圾
找到垃圾之后,就要对垃圾进行释放,我了解到的释放垃圾的策略有3种,分别是标记清除,复制算法和标记整理
1.标记清除
标记清除就是直接将被视为垃圾的对象的内存直接释放掉,但是标记清除有一个会出现内存碎片的特点
什么是内存碎片呢?
假设有一段内存空间,这段内存空间中存在了一些垃圾对象,但是这些垃圾对象在这一段的内存中存在的位置是不连续的,此时如果直接将垃圾对象的内存直接释放掉,此时也会导致释放之后得到的空余的内存空间是不连续的。因为申请的内存空间是一定要连续的空间,此时因为直接将内存中不连续的垃圾对象的空间直接释放掉了,导致释放后得到的空间并不连续,这样可能就会导致假设我们要申请4G的内存空间,但是内存中有4G大小的空间,却因为这4G空间不连续导致无法成功申请对应的内存
2.复制算法
复制算法就是在使用内存时,将内存分为两半,一次只使用一半的内存空间,在回收垃圾时,先将不是垃圾的对象复制到另一半内存空间,此时再将原来一半的对象的内存空间直接释放掉,这样就保证了回收垃圾后得到的内存空间是连续的
但是复制算法有两个缺点,一个缺点就是由于复制算法一次只使用一半的内存空间,这样就会导致内存的空间利用率低,还有一个缺点就是在复制的时候,如果不是垃圾的对象很多且其中有占据的空间很大对象,就会导致复制的开销很大
3.标记整理
标记整理就是在一段存在垃圾对象的内存空间中,将不是垃圾的对象搬运到内存中前面的空间,最后直接将以内存中最后一个不是垃圾对象的地址为起点,将起点后面的空间全部释放掉,此时标记整理就不会导致内存碎片和避免了空间利用率低的问题
但是由于要搬运对象,如果要搬运的对象占据的内存空间很多,这也会导致搬运的开销会很大的问题
4.分代算法
分代算法是JVM中GC采取的回收垃圾的策略,在GC机制中,JVM的堆内存通常被划分为新生代和老年代这两块区域,新生代区域通常是保存年龄较小的对象,老年代区域通常保存的是年龄较大的对象,这里对象的年龄是指该对象被GC扫描的次数
在分代算法中,就是针对不同年龄的对象采取不同的策略,采取的策略是:对于新生代中的对象,GC的频率就较高,而针对老年代中的对象,GC的频率就较低
有了上面铺垫的知识,下面就来介绍一下分代算法的具体过程
其中被分为新生代的内存中会从中划分出一块内存作为伊甸区 ,也会划分分两块内存大小相同的区域作为幸存区
一般刚创建出来的对象都是保存在伊甸区的,伊甸区的对象的存活时间大部分都存活不过一轮GC,当伊甸区的中的有些对象经过多轮GC还存活的花,由于此时伊甸区大部分的对象都被GC回收了,此时就会通过复制算法将伊甸区存活的对象复制到幸存区,此时由于伊甸区的大部分对象都被销毁了,此时复制的规模就很小,所以复制的开销就不会那么大了
被复制到幸存区的对象,也会经过多轮GC,每一轮GC,也会消灭幸存区中的对象,每一轮GC存活的对象也会通过复制算法复制到另一个幸存区,如果幸存区的某些对象经过一定次数的GC和复制之后,还存活着,此时这些对象的年龄就大了,就晋升到老年代了
但是此时有一个特殊的情况:如果某个对象占据的内存非常大,此时该对象会直接进入老年代
新生代中的对象大部分会快速消亡,使得每次复制的开销都可控了,而老年代的大部分对象生命周期较长,使得整理的开销页都可控了