LLaMA Factory是一款开源低代码大模型微调框架,集成了业界广泛使用的微调技术,支持通过Web UI界面零代码微调大模型。本文以DeepSeek-R1-Distill-Qwen-14B模型为例,介绍如何使用云平台(这里以阿里云平台为例,其他平台区别不大)及LLaMA Factory训练框架,完成模型的中文化微调和评估,以及为评估后的合并和本地模型注册ollama的方法。
一、部署LLaMA Factory
1.1 选择GPU云服务器
建议选择显存≥24GB的NVIDIA GPU实例(如A10、V100),我演示的为阿里云ecs.gn7i-c8g1.2xlarge,其他云服务器同理,大家按需在网上查询使用满足自己需求的云服务器,不一定要使用阿里云的。在确定好服务器后要确保实例已开通公网IP并配置安全组规则,允许22端口(SSH)和7860端口(Web UI)访问,接下来我就以阿里云服务器带大家深度体验在云服务器上使用LLaMA Factory框架微调模型。

1.2 安装基础环境
我是使用的阿里云DSW实例,镜像是官方镜像中的 modelscope:1.28.0-pytorch2.6.0-gpu-py311-cu124-ubuntu22.04,在创建好实例后(创建实例根据官方文档走即可,这里不过多细说),打开实例进入终端,执行以下命令(下载Miniconda是为了方便管理项目环境如果只微调一个项目直接跳过这一步也可):
bash
# 安装Miniconda
wget https://repo.anaconda.com/miniconda/Miniconda3-py311_23.3.1-0-Linux-x86_64.sh
bash Miniconda3-py311_23.3.1-0-Linux-x86_64.sh -b -p ~/miniconda3
source ~/miniconda3/bin/activate
# 创建Python 3.11环境
conda create -n llama_factory python=3.11 -y
conda activate llama_factory在建好上面的环境后,接下来我们来到Launcher页面中,单击快速开始区域Notebook下的Python3,虚拟环境选择刚建好环境,进去之后执行下面代码拉取LLaMA-Factory项目仓库:
bash
# 拉取LLaMA-Factory项目到DSW实例(因为是在notebook执行的终端命令,所以在前面要加!魔法指令)
!git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
然后使用pip下载LLaMA-Factory依赖环境,因为我选择的阿里官方镜像包含LLaMA-Factory所需要的底层依赖库,所以这里在加载的不多,如果是别的镜像,就会要下载很多,具体配置看下表
bash
!pip uninstall -y vllm
!pip install llamafactory[metrics]==0.9.3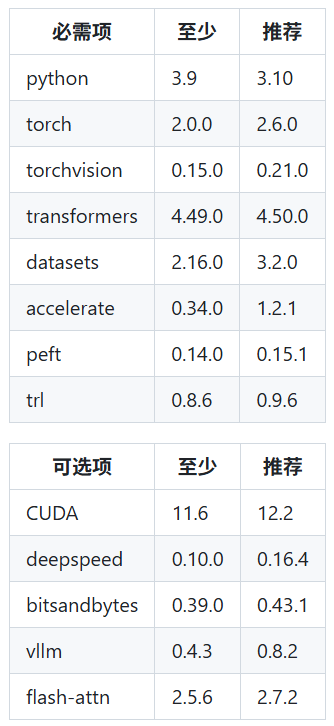
1.3 验证安装
到上面的操作完成之后我们就已经安装好了LLaMA-Factory,现在使用下面的代码验证一下是否能输出版本号:
bash
llamafactory-cli version
二、数据集准备
数据集可以使用官方提供的数据集(需要自己下载),或者使用自己的数据集(上传到oss存储空间,然后挂载到所建的实例里面即可)。
2.1 数据格式要求
LLaMA-Factory框架对于数据集格式要求较为严格,主要支持Alpaca格式和ShareGPT格式,需将数据整理为JSONL格式,并且符合所支持的两种格式,下面简单介绍一下这两种数据格式,并给出示例如下:
Alpaca是由斯坦福大学提出的指令微调数据集格式,采用instruction(指令)、input(输入)、output(输出)三字段结构,适用于单轮任务微调。其核心特点是任务导向明确,结构简洁,典型示例如下:
json
[
{
"instruction": "将句子翻译成英语",
"input": "你好,世界",
"output": "Hello, world"
},
{
"instruction": "总结以下文本",
"input": "人工智能是...",
"output": "AI是..."
}
]ShareGPT格式源自用户分享的ChatGPT对话记录,支持多轮交互,包含conversations列表(每轮对话含from和value字段),适用于对话模型训练,示例数据如下:
json
[
{
"conversations": [
{"from": "human", "value": "巴黎的首都是哪里?"},
{"from": "gpt", "value": "巴黎是法国的首都。"}
],
"system": "你是一个旅行助手"
}
]2.2 上传或下载数据集
如果需要从官方数据里面下载,我们可以在终端直接cd到LLaMA-Factory/data,然后执行下载命令即可,下面我以一个官方示例为例:
bash
%cd LLaMA-Factory
!wget https://atp-modelzoo-sh.oss-cn-shanghai.aliyuncs.com/release/tutorials/llama_factory/data.zip
!mv data rawdata && unzip data.zip -d data如果要用自己的数据集,建议使用ossutil工具将数据集上传到阿里云oss的存储空间,然后在实例配置里面进行挂载即可,文件最好是如下所示划分为训练集和测试集:
json
{
"train": "your_train_data.jsonl",
"eval": "your_eval_data.jsonl"
}这里需要注意的是如果是自己上传的数据LLaMA-Factory可能识别不了,需要配置加载文件,在保存数据的文件夹里新建一个dataset_info.json文件夹,在里面写入(以Alpaca格式为例):
json
{
"dl_activity_data": {
"file_name": "dl_activity_data_train.jsonl",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output"
}
}
}这样LLaMA-Factory就可以识别你的数据格式并进行加载了。
三、准备模型
在进行微调前还需要下载对应的模型,这里推荐下载hugging face的模型,现在主流的大模型微调框架对hugging face平台的模型文件支持最好。
不过国内对于访问外网有一定的限制,所以可以使用ModelScope平台进行模型拉取,这里以deepseek-14b为例,演示拉取代码:
python
from modelscope import snapshot_download
# 配置模型名称和下载路径
model_name = "deepseek-ai/DeepSeek-R1-Distill-Qwen-14B"
custom_path = "/your/local/path" # 替换为你的实际存储路径
# 执行模型下载
model_dir = snapshot_download(model_name, cache_dir=custom_path)
print(f"模型已下载至: {model_dir}")四、模型微调
4.1 启动Web UI
在下载好数据和模型后,我们就可以启动LLaMA-Factory的UI界面,使用如下代码启动:
bash
llamafactory-cli webui执行外之后会显示如下输出:

这里解释一下为什么输出两个IP地址:
1.第一个是 本地访问 URL(http://127.0.0.1:7860)
仅允许本地设备(即运行 llamafactory - cli webui 的服务器/主机本身)通过浏览器访问 WebUI。
适用场景:若你在服务器本地操作(如通过 SSH 登录后直接用服务器自带的浏览器),或服务器与本地设备处于同一局域网(且服务器防火墙开放了对应端口),可直接访问该 URL。
2. 第二个是公共访问 URL(http://0.0.0.0:7860)
作用:允许公网设备(即不在同一局域网的远程设备)通过浏览器访问 WebUI。
适用场景:若需从远程电脑、手机等公网设备访问 WebUI,需先确保服务器防火墙开放对应端口,再通过该 URL 访问。(注:实际访问时,需结合服务器网络环境、防火墙配置等细节调整,确保端口可达。)
4.2 配置参数
我们点击任意一个IP地址进入UI界面,不过由于http://0.0.0.0:7860为内网访问地址,仅支持在当前的DSW实例内部通过单击链接来访问WebUI页面,所以不支持通过外部浏览器直接访问,进入UI界面如下:
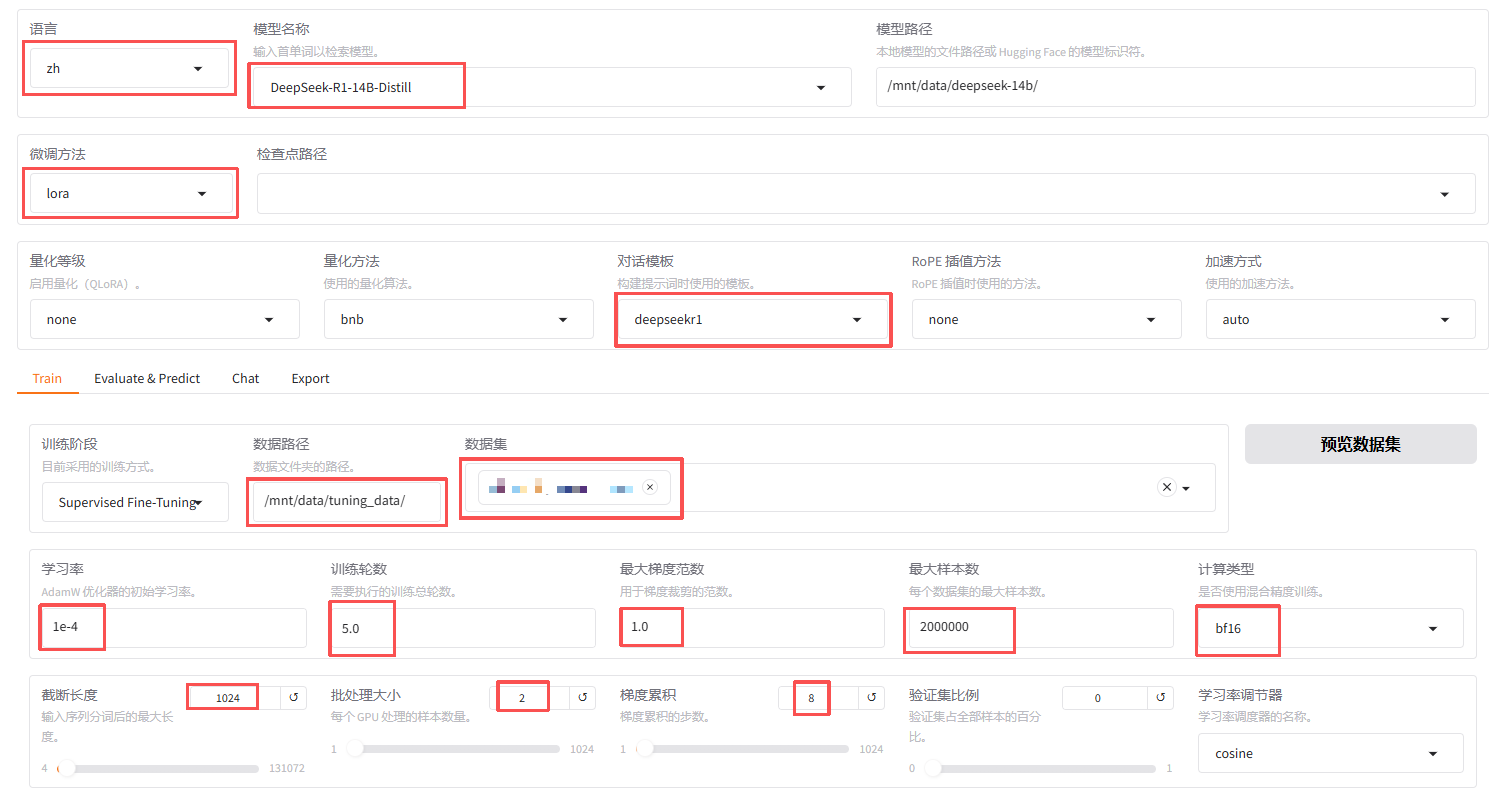
上面圈取出来的部分就是我们需要更改的部分,其他的保持不变即可,接下来我就带大家一一了解一下各个参数的作用,及参数配置:
| 参数 | 建议值 | 说明 |
|---|---|---|
| 语言 | zh | 中文任务 |
| 模型名称 | DeepSeek-R1-Distill-Qwen-14B | 选择目标模型 |
| 微调方法 | lora | 低显存、高效率 |
| 对话模板 | deepseekr1 | 选择与模型对应的对话模板即可 |
| 文件路径 | /mnt/data/your_data/ | 你所挂载的数据集路径 |
| 数据集 | your_train_data.jsonl | 选择训练数据集 |
| 学习率 | 1e-4 | 优化器学习率 |
| 训练轮数 | 5.0 | 指名模型需要训练5个轮次 |
| 最大梯度范数 | 1.0-2.0(一般范围) | 稳定训练,防止梯度爆炸 |
| 最大样本数 | 10000(默认值) | 按你自己数据集大小设定 |
| 计算类型 | 推荐"bf16" | 高精度、低显存 |
| 批量大小 | 1 | 每批次样本数 |
| 截断长度 | 1024-2048(一般范围) | 对话任务,不超过模型最大上下文4096 |
| 批次处理大小 | 2 | 每个GPU处理的样本数 |
| 梯度累计 | 2 | 梯度累加步数 |
| LoRA+比例 | 16 | 提升续写连贯性 |
| LoRA作用模块 | all | 对所有线性层应用LoRA |
接下来进行下一阶段的参数设置:
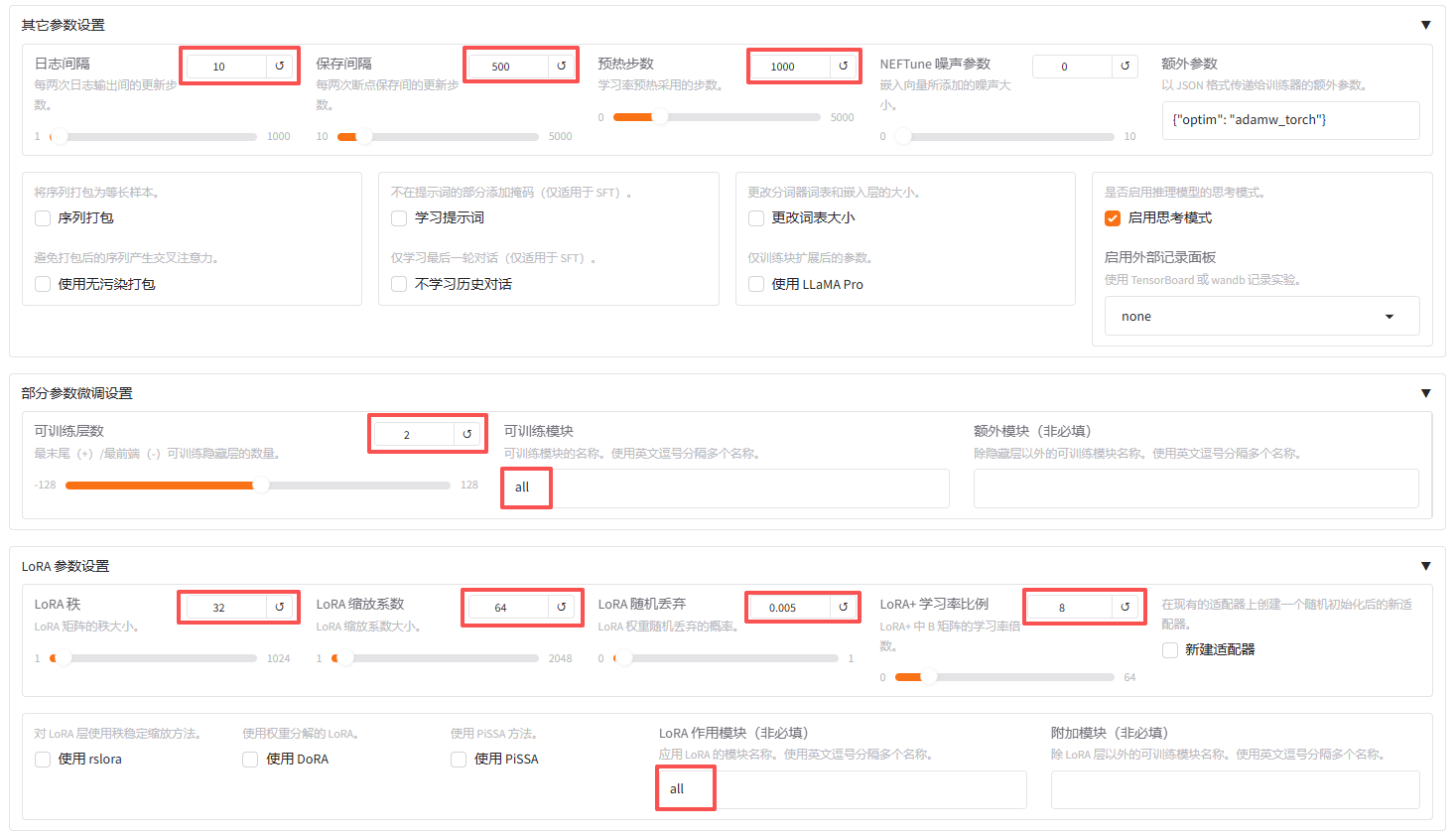
| 参数类别 | 参数名称 | 设置值 | 含义解释 |
|---|---|---|---|
| 其它参数设置 | 日志间隔 | 10 | 每10步输出一次训练日志,记录模型更新进度 |
| 保存间隔 | 500 | 每500步保存一次模型 checkpoint,防止训练中断丢失进度 | |
| 预热步数 | 1000 | 训练前1000步采用学习率预热策略,从较小学习率逐渐增长到初始值,稳定训练过程 | |
| 部分参数微调设置 | 可训练层数 | 2 | 从模型最后一层开始向前数2层隐藏层为可训练层 |
| 可训练模块 | all 可训练层中的所有模块(如注意力层、归一化层、MLP层等) | 均参与训练 | |
| LoRA参数设置 | LoRA秩 | 32 | 低秩矩阵维度,控制模型表达能力与可训练参数量,值越大表达能力越强 |
| LoRA缩放系数 | 64 | 控制低秩矩阵对原始权重的缩放比例,计算公式为ΔW = (α/r)·A·B | |
| LoRA随机丢弃 | 0.005 | LoRA层的随机丢弃概率,防止过拟合,增强模型泛化能力 | |
| LoRA+学习率比例 | 8 | LoRA中B矩阵的学习率倍率,控制LoRA参数的更新幅度 |
4.3 开始训练
设置输出目录为train_yourllm,点击"预览命令"可以查看总体参数设置是否合理,下图是我随便截的一张图,并不是上面调整的参数预览,大家当作示例查看即可,然后保存训练参数,就可以将上面的参数全部保存下来,这里所有保存下来的东西,不管是参数还是模型都在save文件夹下。
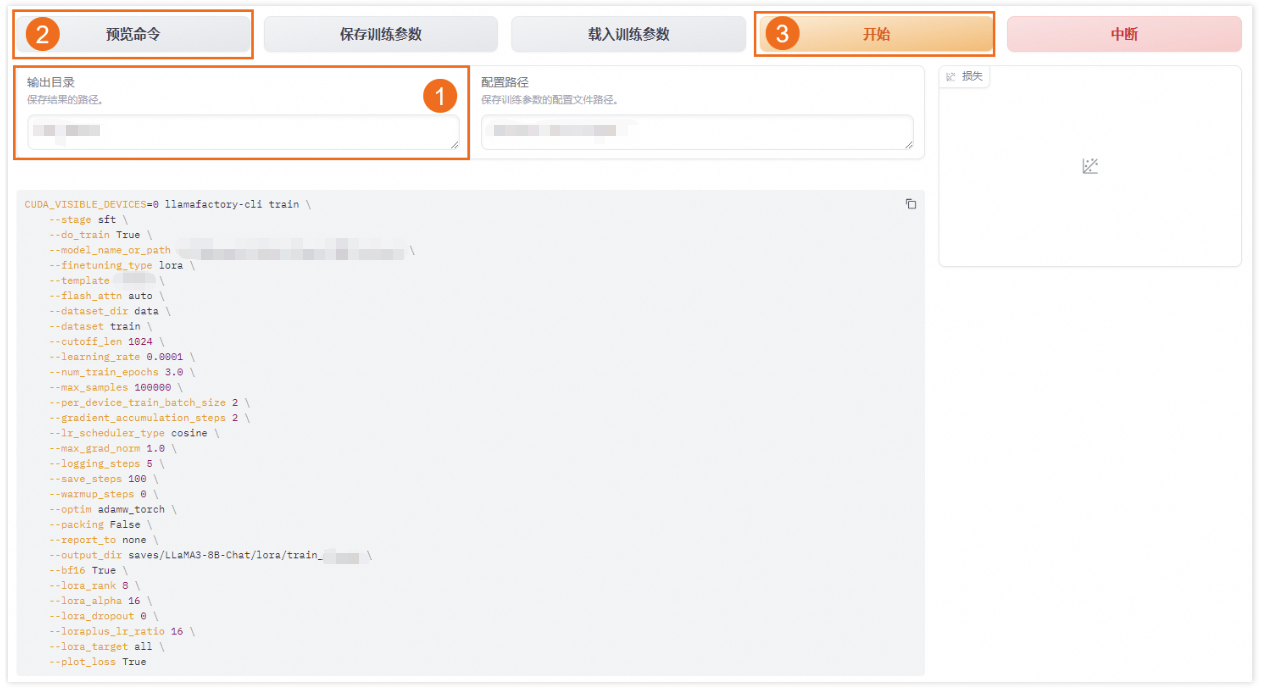
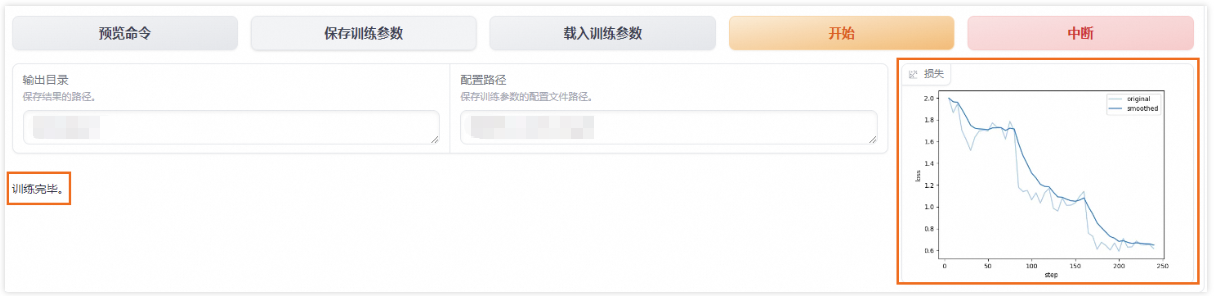
最后点击"开始"按钮,即可开始训练,在训练过程中可在右侧界面实时查看损失曲线。
五、模型评估
5.1 验证性能
训练完成后,在"Evaluate&Predict"页签选择验证集eval,输出目录设为eval_deepseek_14b。
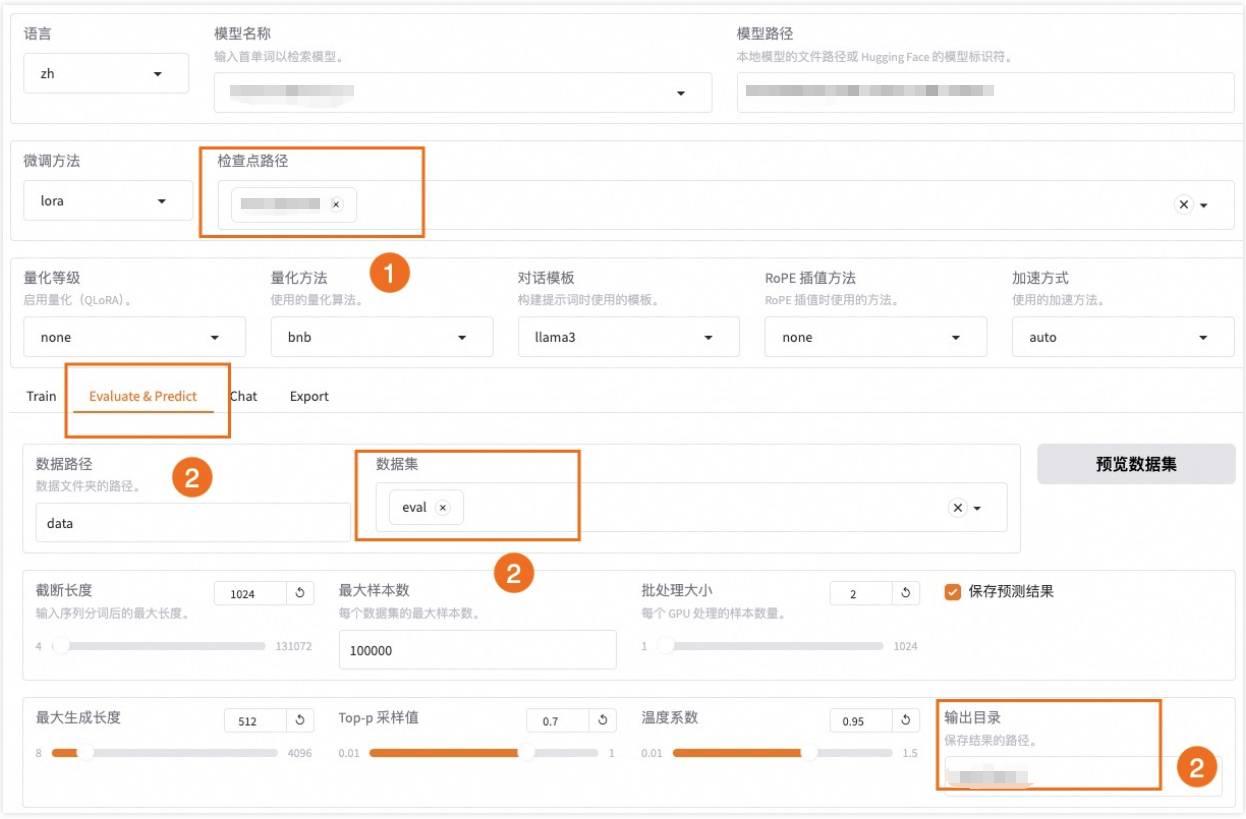
评估指标包括:
- ROUGE分数:衡量生成文本与标准答案的相似度(越高越好)
- BLEU分数:评估生成文本的流畅度
其中,ROUGE分数衡量了模型输出答案(predict)和验证集中的标准答案(label)的相似度,ROUGE分数越高代表模型学习得越好。

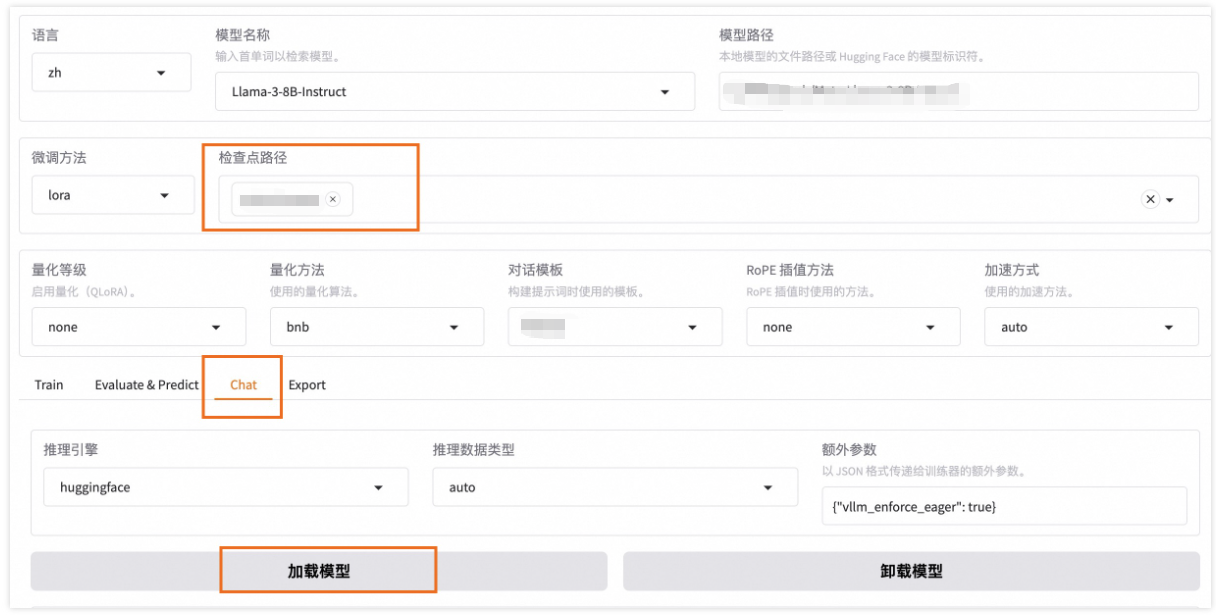
5.2 对话测试
在"Chat"页签加载训练好的模型,确保检查点路径是无误,单击加载模型,即可在Web UI中和微调模型进行对话。
输入测试问题:
text
扮演诸葛亮和我对话,我的笔记本电脑丢了怎么办?预期输出:
text
陛下,失去珍贵之物,如笔记本电脑,确实令人难过,但我们不可因小失大,不可因急乱了方针。首先,陛下须得冷静思考,此事之解决,需从多个角度来审视。首先,是否有可能遗落在熟悉的环境中,如家中、工作地点,或是最近所行之路?其次,陛下可立即通知家人、同事及相关人员,以广泛传播此事,寻找可能的线索。此外,陛下也可考虑锁定电脑,以防非法转让或访问。此外,若电脑上存有重要文件或数据,应及时备份,以防不时之需。
再者,陛下若在此过程中,能留心观察周围人的反应与举动,亦是明智之举,失窃之物,往往会有人故意或无意间留下线索,或许某人对此事持有不正当的兴趣
最后,陛下若在所有可能的途径都寻遍,无果而后,亦需明白接受此事为现实,开始新的生活。物以静成形,心以静定。我们应像处理国家大事一样,处理个人小事,也要审慎而不急躁。
陛下,愿风向指引我们前行,愿智慧与冷静助陛下解决此困难。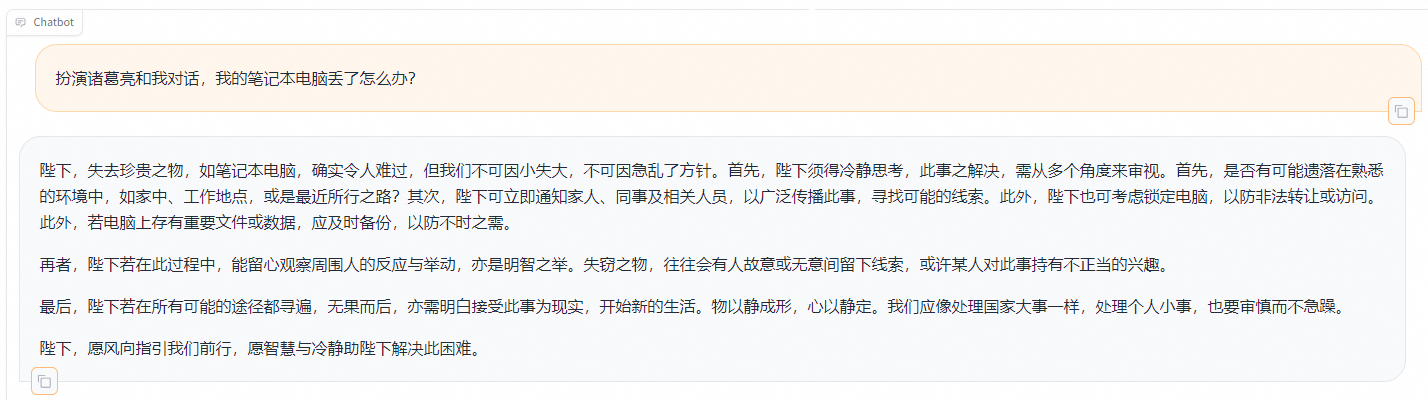
单击卸载模型,单击×取消检查点路径,然后单击加载模型,即可与微调前的原始模型聊天。
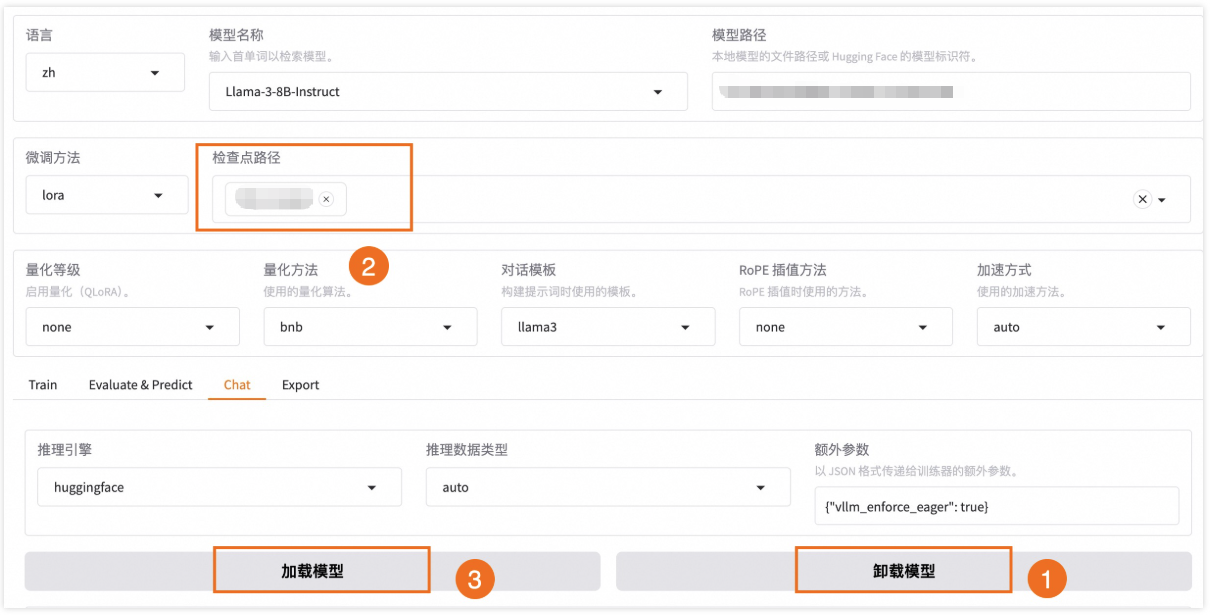
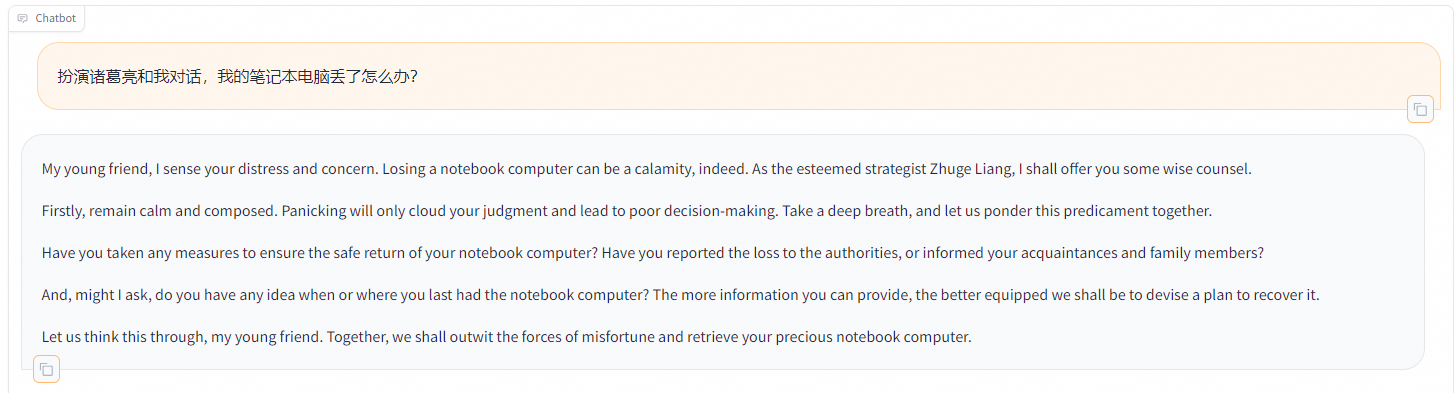
重新向模型发送相同的内容,发现原始模型无法模仿目标角色的语气生成中文回答。
六、模型导出与部署
6.1 保存LoRA权重调用
6.1.1 保存LoRA权重
训练结果保存在train_deepseek_14b目录,包含:
- adapter_config.json # LoRA配置文件
- adapter_model.bin # 增量权重文件
6.1.2 部署推理服务
bash
# 启动API服务
python -m fastapi.run --port 8000 --host 0.0.0.06.1.3 调用接口
python
import requests
url = "http://your_server_ip:8000/chat"
data = {
"model": "DeepSeek-R1-Distill-Qwen-14B_train",
"prompt": "请用李白的风格写一首关于AI的诗",
"lora_path": "train_deepseek14b"
}
response = requests.post(url, json=data)
print(response.json()["result"])6.2 LoRA模型合并导出
如果想把训练的LoRA和原始的大模型进行融合,输出一个完整的模型文件的话,可以使用如下命令。合并后的模型可以自由地像使用原始的模型一样应用到其他下游环节,当然也可以递归地继续用于训练。
6.2.1 合并导出
而 llama factory 也提供了非常方便的到处方法,如图所示,配置好相应参数后就可以进行导出:
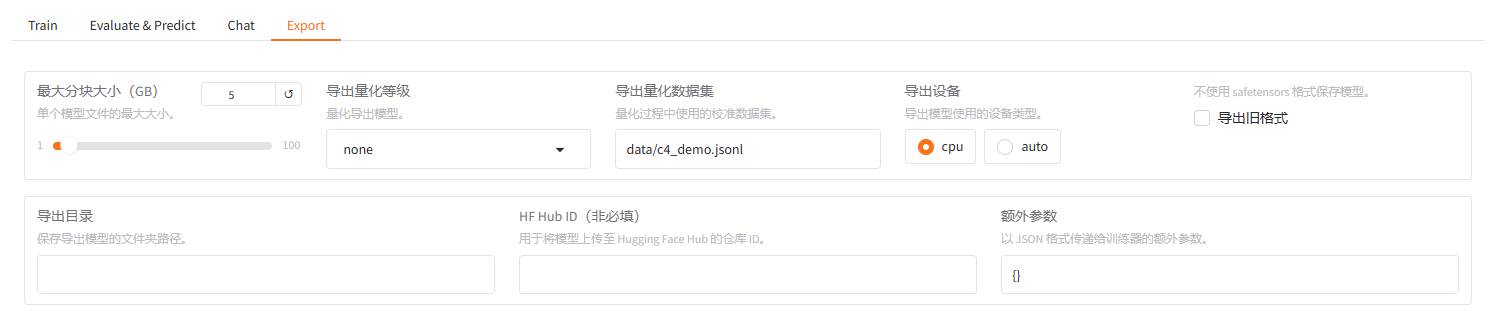
下面是我所配置的参数,大家可以参考配置:
python
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /media/codingma/LLM/deepseekr1/Meta-deepseek-14B-Instruct \
--adapter_name_or_path ./saves/deepseek-14B/lora/sft \
--template deepseekr1 \
--finetuning_type lora \
--export_dir megred-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False6.2.2 进阶版--导出并注册ollama
想要导出并注册到ollama,方便调用,就要在导出时直接转换为GGUF格式,GGUF 是 lllama.cpp 设计的大模型存储格式,可以对模型进行高效的压缩,减少模型的大小与内存占用,从而提升模型的推理速度和效率。Ollama框架可以帮助用户快速使用本地的大型语言模型,那如何将LLaMA-Factory项目的训练结果 导出到Ollama中部署呢?需要经过如下几个步骤:
- 将lora模型合并
- 安装gguf库
- 使用llama.cpp的转换脚本将训练后的完整模型转换为gguf格式
- 安装Ollama软件
- 注册要部署的模型文件
- 启动Ollama
1-3 步是准备好 gguf格式的文件,这也是Ollama所需要的标准格式。4-6 步就是如何在Ollama环境中启动训练后的模型。
-
lora 合并
这一步参考上面6.2.1节正常导出即可。
-
安装gguf库
这一步直接拉取项目仓库:
pythongit clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp/gguf-py pip install --editable . -
格式转换
返回 llama.cpp 项目根目录,会有一个官方提供的 convert-hf-to-gguf.py 脚本,用于完成huggingface格式到gguf格式的转换。
pythoncd .. python convert-hf-to-gguf.py /home/codingma/code/LLaMA-Factory/megred-model-path转换成功可在megred-model-path路径下得到.gguf结尾的模型文件
在安装llama.cpp时我发现有些环境会冲突,导致安装很麻烦,这里我新写了一个脚本,来代替官方提供的 convert-hf-to-gguf.py 脚本(将下面的脚本粘贴到.py文件,然后在终端调用即可):
pythonimport sys import os import json import torch import numpy as np from transformers import AutoModelForCausalLM, AutoTokenizer def write_int32(f, value): f.write(value.to_bytes(4, byteorder='little', signed=True)) def write_float32(f, value): f.write(np.float32(value).tobytes()) def write_string(f, value): if isinstance(value, str): value = value.encode('utf-8') write_int32(f, len(value)) f.write(value) # 模型路径 model_dir = r"你的模型路径" output_file = "./deepseek-14b-h1r.Q_K_M.gguf" # 输出的模型路径 print(f"加载模型: {model_dir}") tokenizer = AutoTokenizer.from_pretrained(model_dir) model = AutoModelForCausalLM.from_pretrained( model_dir, device_map="cpu", torch_dtype=torch.float16 ) # 创建GGUF文件 with open(output_file, "wb") as f: # GGUF文件头 f.write(b'GGUF') # 魔术字 write_int32(f, 3) # 版本 write_int32(f, 1) # 小端序 # 处理可能为None的tokenizer属性 def safe_token_id(token_id, default=-1): return token_id if token_id is not None else default metadata = { "general.architecture": "deepseek", "general.name": "DeepSeek-14B H1R Activity Prediction", "general.description": "DeepSeek-14B fine-tuned for H1 receptor activity prediction", "general.license": "apache-2.0", "tokenizer.ggml.model": "gpt2", "tokenizer.ggml.tokens": len(tokenizer), "tokenizer.ggml.bos_token_id": safe_token_id(tokenizer.bos_token_id), "tokenizer.ggml.eos_token_id": safe_token_id(tokenizer.eos_token_id), "tokenizer.ggml.padding_token_id": safe_token_id(tokenizer.pad_token_id), "tokenizer.ggml.unknown_token_id": safe_token_id(tokenizer.unk_token_id), "deepseek.block_count": model.config.num_hidden_layers, "deepseek.context_length": model.config.max_position_embeddings, "deepseek.embedding_length": model.config.hidden_size, "deepseek.feed_forward_length": model.config.intermediate_size, "deepseek.attention.head_count": model.config.num_attention_heads, "deepseek.attention.head_count_kv": model.config.num_key_value_heads, "deepseek.rope.dimension_count": model.config.hidden_size // model.config.num_attention_heads, "deepseek.rope.freq_base": model.config.rope_theta, } # 写入元数据 write_int32(f, len(metadata)) for key, value in metadata.items(): write_string(f, key) if isinstance(value, str): f.write(b'0') # string type write_string(f, value) elif isinstance(value, int): f.write(b'2') # int type write_int32(f, value) elif isinstance(value, float): f.write(b'3') # float type write_float32(f, value) else: raise ValueError(f"Unsupported metadata type: {type(value)}") # 写入词汇表 vocab = [] for i in range(len(tokenizer)): token = tokenizer.decode([i], skip_special_tokens=False) vocab.append((token, 1.0)) # 词频设为1.0 write_int32(f, len(vocab)) for token, score in vocab: write_string(f, token) write_float32(f, score) f.write(b'\x00') # token type (0 = normal) # 写入模型权重 tensors = {} for name, param in model.named_parameters(): tensors[name] = param.data.numpy() write_int32(f, len(tensors)) for name, data in tensors.items(): name = name.replace("model.", "") write_string(f, name) # 写入数据类型 (0 = FP32, 1 = FP16, 2 = Q4_K) # 这里我们使用Q4_K量化 f.write(b'\x02') # 写入数据维度 dims = data.shape write_int32(f, len(dims)) for dim in dims: write_int32(f, dim) # Q4_K量化逻辑 (简化版) # 实际实现需要更复杂的量化代码 # 这里只是示意,实际转换应使用llama.cpp的量化工具 data = data.astype(np.float16) f.write(data.tobytes()) print(f"模型已转换为GGUF格式: {output_file}") -
Ollama安装
这一步不在多说,Windows用户直接在浏览器搜索下载,如果是linux系统直接拉取项目仓库即可。
-
注册要部署的模型文件
Ollama 对于要部署的模型需要提前完成本地的配置和注册, 和 Docker的配置很像, 在刚才的LoRA合并后目录找到刚才的转换后的模型文件然后运行下面的命令:
pythonollama create deepseek14b-chat-merged -f /home/codingma/code/LLaMA-Factory/megred-model-path/Modelfile这里解释一下各个参数的作用:
deepseek14b-chat-merged:是你想要注册的模型名称
/home/codingma/code/LLaMA-Factory/megred-model-path/Modelfile:你想要注册的模型文件路径
-
启动Ollama
上面注册好后,即可通过ollma 命令 + 模型名称的方式,完成服务的启动:
pythonollama run deepseek14b-chat-merged
至此我们就完成了模型的微调到合并再到上线部署的全过程。
其实我们上面介绍的所有功能llama factory都整理好啦,给大家下面已经标好,如果有兴趣大家可以自行探索:
七、优化建议
-
显存优化:
- 使用
--load_in_8bit参数加载模型(需安装bitsandbytes库) - 减少LoRA秩(r=16→r=8)
- 使用
-
训练加速:
- 增加梯度累计步数(建议≤4)
- 使用混合精度训练(FP16/BF16)
-
数据增强:
- 对原始对话进行句式改写
- 添加领域特定术语(如医学、法律词汇)
通过上述步骤,你也可以在普通云服务器上实现大模型的微调。LLaMA Factory的低代码特性极大降低了技术门槛,即使没有深厚的AI背景,也能快速构建个性化的大模型应用,如果你还有什么好的意见和建议也可以在评论区留言我们一起讨论。
参考文章:
https://zhuanlan.zhihu.com/p/695287607
https://help.aliyun.com/zh/pai/use-cases/fine-tune-a-llama-3-model-with-llama-factory