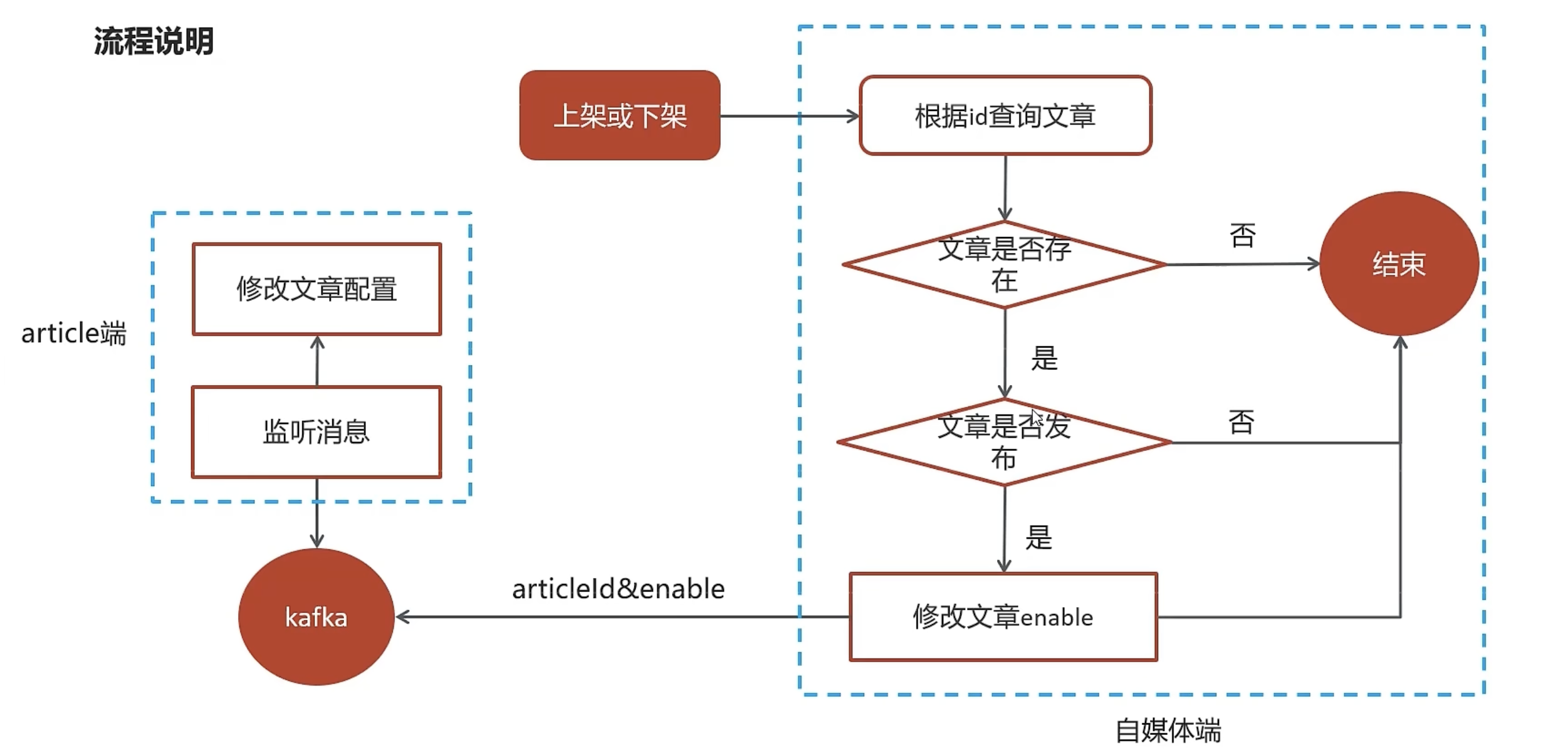
自媒体文章上下架流程图
说明:
- 自媒体端创建一个接口,传递文章的id和对应enable
- 根据状态修改news对象中的enable数据,当enable属性发生变化时,
- 调用kafka服务(会将new中的articleId值传递给kafka),它会同时将news修改的内容同步给article中。
定义自媒体端文章上下架接口
接口信息
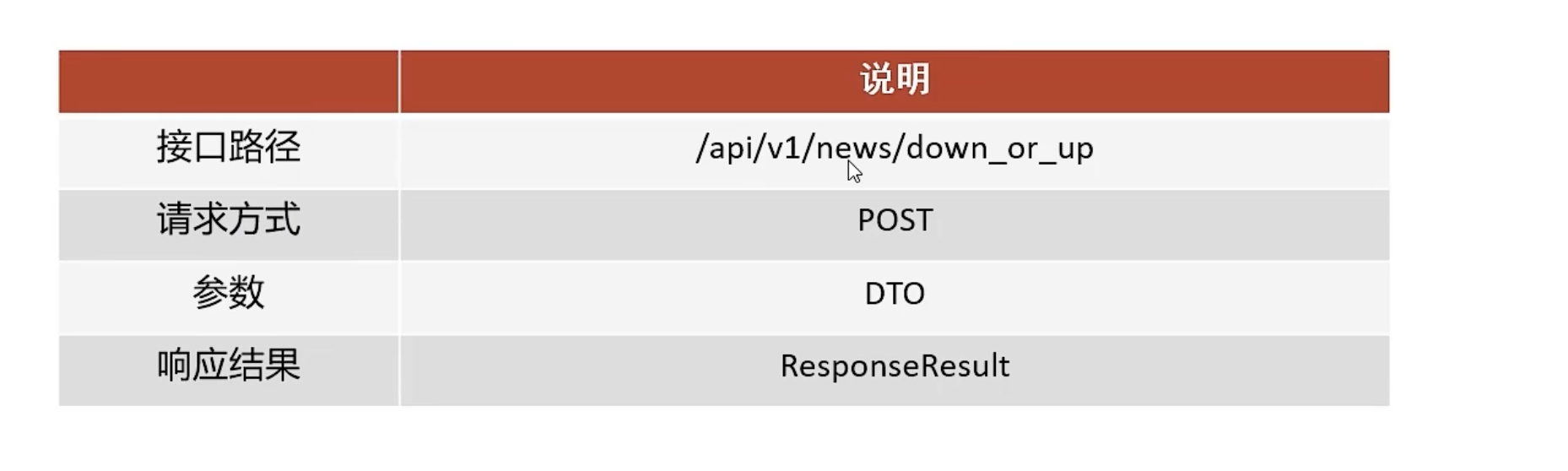
响应结果

kafka配置
nacos添加
java
spring:
kafka:
bootstrap-servers: varin.cn:9999
producer:
retries: 10
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer配置公用的kafka主题
java
package com.hei.common.constance;
public class WmNewsMessageConstants {
public static final String WM_NEWS_UP_OR_DOWN_TOPIC="wm.news.up.or.down.topic";
}配置接收前端dto
java
package com.heima.model.wemedia.dtos;
import io.swagger.models.auth.In;
import lombok.Data;
/**
* 用于判断自媒体文章上架下架
*/
@Data
public class WmNewsEnableDto {
private Integer id;
private Short enable;
}定义Controller接口
java
@PostMapping("down_or_up")
public ResponseResult downOrUp(@RequestBody WmNewsEnableDto dto){
return wmNewsService.down_or_up(dto);
}定义Service并实现Impl
java
package com.heima.wemedia.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.heima.model.common.dtos.ResponseResult;
import com.heima.model.wemedia.dtos.WmNewsDto;
import com.heima.model.wemedia.dtos.WmNewsEnableDto;
import com.heima.model.wemedia.dtos.WmNewsPageReqDto;
import com.heima.model.wemedia.pojos.WmNews;
import java.lang.reflect.InvocationTargetException;
public interface WmNewsService extends IService<WmNews> {
ResponseResult down_or_up(WmNewsEnableDto dto);
}Impl
java
@Autowired
private WmNewsMapper wmNewsMapper;
@Autowired
private KafkaTemplate<String,String> kafkaTemplate;
@Override
public ResponseResult down_or_up(WmNewsEnableDto dto) {
// 判断参数
if (dto.getId()==null) {
return ResponseResult.errorResult(AppHttpCodeEnum.PARAM_REQUIRE,"文章id不可缺少");
}
// 查询文章
WmNews wmNews = wmNewsMapper.selectById(dto.getId());
if (wmNews==null) {
return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"文章不存在");
}
if (!wmNews.getStatus().equals(WmNews.Status.PUBLISHED.getCode())) {
return ResponseResult.errorResult(AppHttpCodeEnum.DATA_NOT_EXIST,"当前文章不是发布状态");
}
// 判断上架下架的范围
if (wmNews.getEnable()!=null && wmNews.getEnable()>-1 &&wmNews.getEnable()<2) {
wmNews.setEnable(dto.getEnable());
updateById(wmNews);
// 卡夫卡生产者发送消息
if (wmNews.getArticleId()!=null) {
Map<String, Object> map = new HashMap<>();
map.put("articleId", wmNews.getArticleId());
map.put("enable", dto.getEnable());
kafkaTemplate.send(WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC,JSON.toJSONString(map));
}
}
return ResponseResult.okResult(AppHttpCodeEnum.SUCCESS);
}app端定义Kafka监停上下状态
配置
nacos设置
java
spring:
kafka:
bootstrap-servers: varin.cn:9999
consumer:
group-id: ${spring.application.name}
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer实现监听事件
java
package com.heima.article.listener;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import com.hei.common.constance.WmNewsMessageConstants;
import com.heima.article.service.ArticleConfigService;
import com.heima.model.wemedia.pojos.WmNews;
import org.apache.commons.lang3.StringUtils;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.stereotype.Component;
import java.util.Map;
@Component
public class ArticleDownOrRpListener {
@Autowired
private ArticleConfigService articleConfigService;
@KafkaListener(topics = WmNewsMessageConstants.WM_NEWS_UP_OR_DOWN_TOPIC)
public void articleDownOrRp(String message){
if (StringUtils.isNotBlank(message)) {
Map jsonObject = JSON.parseObject(message, Map.class);
articleConfigService.updatetoMap(jsonObject);
}
}
}定义service并实现Impl
java
package com.heima.article.service;
import com.baomidou.mybatisplus.extension.service.IService;
import com.heima.model.article.pojos.ApArticleConfig;
import java.util.Map;
public interface ArticleConfigService extends IService<ApArticleConfig> {
void updatetoMap(Map map);
}Impl
java
package com.heima.article.service.impl;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;
import com.heima.article.mapper.ApArticleConfigMapper;
import com.heima.article.service.ArticleConfigService;
import com.heima.model.article.pojos.ApArticleConfig;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import org.springframework.transaction.annotation.Transactional;
import java.util.Map;
@Service
@Transactional
@Slf4j
public class ArticleConfigServiceImpl extends ServiceImpl<ApArticleConfigMapper, ApArticleConfig> implements ArticleConfigService {
@Override
public void updatetoMap(Map map) {
Object o = map.get("enable");
Boolean enable = o.equals(1)?false:true;
// 更新
update(Wrappers.<ApArticleConfig>lambdaUpdate(). eq(ApArticleConfig::getArticleId,map.get("articleId")).set(ApArticleConfig::getIsDown,enable));
}
}app端文章搜索需求分析
- 用户输入关键可搜索文章列表
- 关键词高亮显示
- 文章列表展示与home展示一样,当用户点击某一篇文章,可查看文章详情
- 为了加快检索的效率,在查询的时候不会直接从数据库中查询文章,需要在**elasticsearch**中进行高速检索。
ElasticSearch介绍
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。

docker搭建ElasticSearch环境
拉取镜像
拉取镜像并指定版本
shell
docker pull elasticsearch:7.4.0运行容器
shell
docker run -id --name elasticsearch -d --restart=always -p 9200:9200 -p 9300:9300 -v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins -e "discovery.type=single-node" elasticsearch:7.4.0以下是该 docker run 命令各参数的详细解释,以表格形式呈现:
| 参数 | 说明 |
|---|---|
docker run |
Docker 的基础命令,用于创建并启动一个新的容器 |
-i |
以交互式模式运行容器,保持标准输入(STDIN)打开,即使没有连接 |
-d |
以守护进程(后台)模式运行容器,容器启动后会返回容器 ID,不在前台阻塞终端 |
--name elasticsearch |
为容器指定一个自定义名称(elasticsearch),方便后续通过名称操作容器(如启动、停止、删除等) |
--restart=always |
设置容器的重启策略为 always:无论容器因何种原因退出(包括正常退出、异常崩溃等),Docker 都会自动重启该容器 |
-p 9200:9200 |
端口映射:将主机的 9200 端口映射到容器内的 9200 端口。Elasticsearch 的 HTTP 服务默认使用 9200 端口,外部可通过主机的 9200 端口访问容器内的 Elasticsearch 服务 |
-p 9300:9300 |
另一组端口映射:将主机的 9300 端口映射到容器内的 9300 端口。9300 是 Elasticsearch 节点间通信的默认端口(用于集群内节点发现和数据同步) |
-v /usr/share/elasticsearch/plugins:/usr/share/elasticsearch/plugins |
数据卷挂载:将主机的 /usr/share/elasticsearch/plugins 目录挂载到容器内的同名目录。作用是持久化 Elasticsearch 的插件(容器重启或重建后,插件不会丢失) |
-e "discovery.type=single-node" |
设置环境变量:向容器内传递 discovery.type=single-node 参数,指定 Elasticsearch 以单节点模式运行(无需配置集群,适合开发或测试环境) |
elasticsearch:7.4.0 |
指定启动容器所使用的镜像:elasticsearch 是镜像名称,7.4.0 是镜像的版本标签 |
配置中文分词器 ik
因为在创建elasticsearch容器的时候,映射了目录,所以可以在宿主机上进行配置ik中文分词器
在去选择ik分词器的时候,需要与elasticsearch的版本好对应上
把
elasticsearch-analysis-ik-7.4.0.zip上传到服务器上,放到对应目录(plugins)解压
shell
#切换目录
cd /usr/share/elasticsearch/plugins
#新建目录
mkdir analysis-ik
cd analysis-ik
#root根目录中拷贝文件
mv elasticsearch-analysis-ik-7.4.0.zip /usr/share/elasticsearch/plugins/analysis-ik
#解压文件
cd /usr/share/elasticsearch/plugins/analysis-ik
unzip elasticsearch-analysis-ik-7.4.0.zip重启docker容器服务
shell
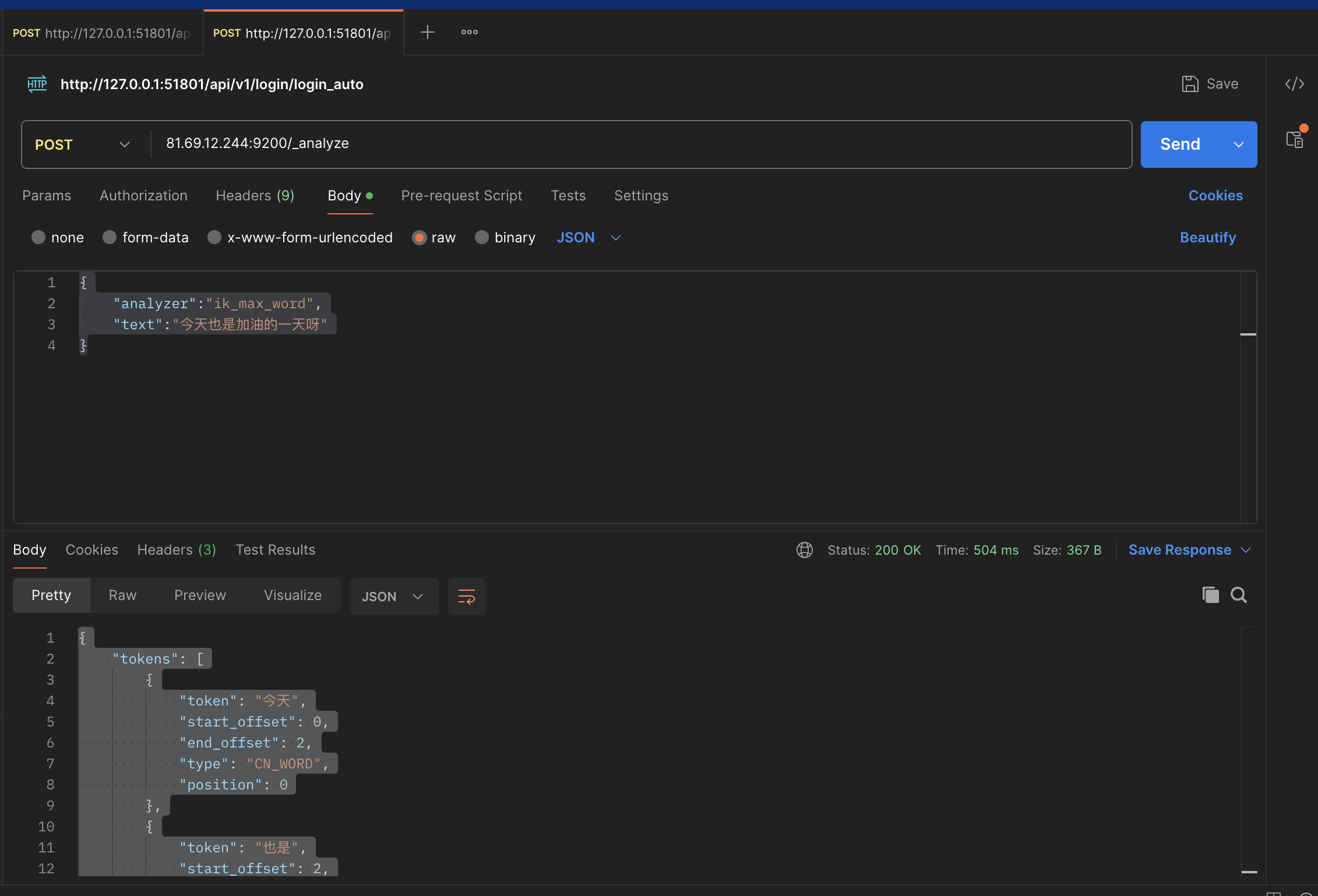
sudo docker restart elasticsearch使用postman测试
Post请求
URL:81.69.12.244:9200/_analyze
shell
# body
{
"analyzer":"ik_max_word",
"text":"今天也是加油的一天呀"
}响应结果
shell
{
"tokens": [
{
"token": "今天",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
},
{
"token": "也是",
"start_offset": 2,
"end_offset": 4,
"type": "CN_WORD",
"position": 1
},
{
"token": "加油",
"start_offset": 4,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "的",
"start_offset": 6,
"end_offset": 7,
"type": "CN_CHAR",
"position": 3
},
{
"token": "一天",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 4
},
{
"token": "一",
"start_offset": 7,
"end_offset": 8,
"type": "TYPE_CNUM",
"position": 5
},
{
"token": "天呀",
"start_offset": 8,
"end_offset": 10,
"type": "CN_WORD",
"position": 6
},
{
"token": "天",
"start_offset": 8,
"end_offset": 9,
"type": "COUNT",
"position": 7
},
{
"token": "呀",
"start_offset": 9,
"end_offset": 10,
"type": "CN_CHAR",
"position": 8
}
]
}
加油呀~