目录
[一、Spring Data Elasticsearch是什么?](#一、Spring Data Elasticsearch是什么?)
[1. 注解驱动的数据映射](#1. 注解驱动的数据映射)
[2. 自动创建索引与映射](#2. 自动创建索引与映射)
[3. 分页与排序支持](#3. 分页与排序支持)
[4. 动态查询与条件筛选](#4. 动态查询与条件筛选)
[5. 聚合分析](#5. 聚合分析)
[6. 高亮显示](#6. 高亮显示)
[7. 动态索引名](#7. 动态索引名)
[1. 与Elasticsearch原生API对比](#1. 与Elasticsearch原生API对比)
[2. 与Solr对比](#2. 与Solr对比)
[1. 环境准备与依赖配置](#1. 环境准备与依赖配置)
[2. 配置Elasticsearch连接](#2. 配置Elasticsearch连接)
[3. 定义实体类与索引映射](#3. 定义实体类与索引映射)
[4. 创建存储库接口](#4. 创建存储库接口)
[5. 实体类的高级映射](#5. 实体类的高级映射)
[6. 动态索引名实现](#6. 动态索引名实现)
[7. 高亮显示实现](#7. 高亮显示实现)
[8. 聚合查询实现](#8. 聚合查询实现)
[9. 批量操作与性能优化](#9. 批量操作与性能优化)
[10. 安全认证配置](#10. 安全认证配置)
Spring Data Elasticsearch是Spring框架对Elasticsearch搜索引擎的封装,为开发者提供了一种简单、高效的方式来集成Elasticsearch。作为Spring Data家族的一员,它通过POJO(普通Java对象)为中心的模型,与Elasticsearch文档交互,并轻松编写Repository样式的数据访问层,从而显著简化了Elasticsearch的使用。

一、Spring Data Elasticsearch是什么?
Spring Data Elasticsearch是Spring Data项目下的一个子模块,旨在为Java开发者提供一个与Elasticsearch交互的简化接口。它基于Spring框架的编程模型,通过Repository模式和注解驱动的方式,将Elasticsearch的复杂操作封装成简单的Java方法。核心功能包括文档的存储、查询、排序和统计,使开发者无需直接处理JSON格式和底层Elasticsearch API,即可实现高效的数据检索和分析。
在技术实现上,Spring Data Elasticsearch通过ElasticsearchRepository接口提供基本的CRUD操作,通过@Document和@Field注解定义索引和字段的映射关系,通过ElasticsearchTemplate类提供更底层的操作能力。它支持Elasticsearch的全文搜索、条件查询、范围查询、聚合分析等多种功能,并与Spring Boot无缝集成,简化了配置和部署过程。
二、诞生背景与演进历程
Spring Data Elasticsearch的诞生源于两个核心背景:一是Elasticsearch原生API的使用复杂性,二是Spring生态对统一数据访问模型的需求。
Elasticsearch原生API的痛点主要体现在三个方面:首先,开发者需要手动处理JSON字符串的拼接,这在Java中既繁琐又容易出错;其次,对象与Elasticsearch文档之间的序列化/反序列化需要自行实现;最后,Elasticsearch的分布式特性和分片机制增加了集成的复杂度。这些问题使得Elasticsearch在Java项目中的使用门槛较高,开发效率低下。
Spring生态的统一访问模型需求则是另一个关键因素。Spring Data项目旨在为各种数据存储提供一致的编程模型,包括关系型数据库、NoSQL数据库、搜索引擎等。通过统一的接口和方法命名规则,开发者可以快速上手不同数据存储的集成,而无需重新学习全新的API。
Spring Data Elasticsearch的演进历程反映了与Elasticsearch版本的紧密适配:
| Spring Data Elasticsearch版本 | Elasticsearch版本 | 主要特性 |
|---|---|---|
| 4.0.0 | 7.6.2+ | 弃用Transport Client,全面转向REST High-Level Client |
| 5.0.0 | 8.0+ | 完全适配Elasticsearch 8.x,支持Java 17+ |
| 6.0.0 | 8.11.1+ | 进一步优化与Elasticsearch 8.x的集成,简化配置流程 |
从早期版本支持Transport Client(通过TCP协议连接Elasticsearch的9300端口)到4.0版本后全面转向REST High-Level Client(通过HTTP协议连接9200端口),再到6.0版本对Elasticsearch 8.x的深度适配,Spring Data Elasticsearch不断演进,以保持与Elasticsearch最新特性的同步,同时降低开发者的使用门槛。
三、架构设计与核心组件
Spring Data Elasticsearch的架构设计遵循Spring Data的通用模式,主要包括以下几个核心组件:
-
客户端层 :使用Elasticsearch官方提供的REST High-Level Client(ES 7.x/8.x版本)或Java Client(ES 8.x推荐)。Spring Data Elasticsearch 4.0版本后彻底弃用了Transport Client,因为Elasticsearch 7.x开始弃用该客户端,8.x版本完全移除了对Transport Client的支持。
-
对象映射层 :负责将Java对象(POJO)与Elasticsearch文档之间的转换。从Spring Data Elasticsearch 4.0版本开始,移除了基于Jackson的映射器,改用Meta Model Object Mapping,这一变化解决了字段映射不一致的问题,提高了映射的准确性和灵活性。
-
Repository层 :提供数据访问接口,包括基本的CRUD操作和查询方法。这是Spring Data Elasticsearch最核心的部分,通过继承
ElasticsearchRepository接口,开发者可以快速获得一系列数据访问方法,如save()、findById()、findAll()等。 -
模板层 :
ElasticsearchTemplate和ElasticsearchRestTemplate提供更底层的操作能力,支持复杂的查询和聚合操作,同时保持与Spring生态的集成。 -
配置层:通过Spring的配置机制(如JavaConfig或XML配置)管理Elasticsearch客户端的生命周期和连接参数。
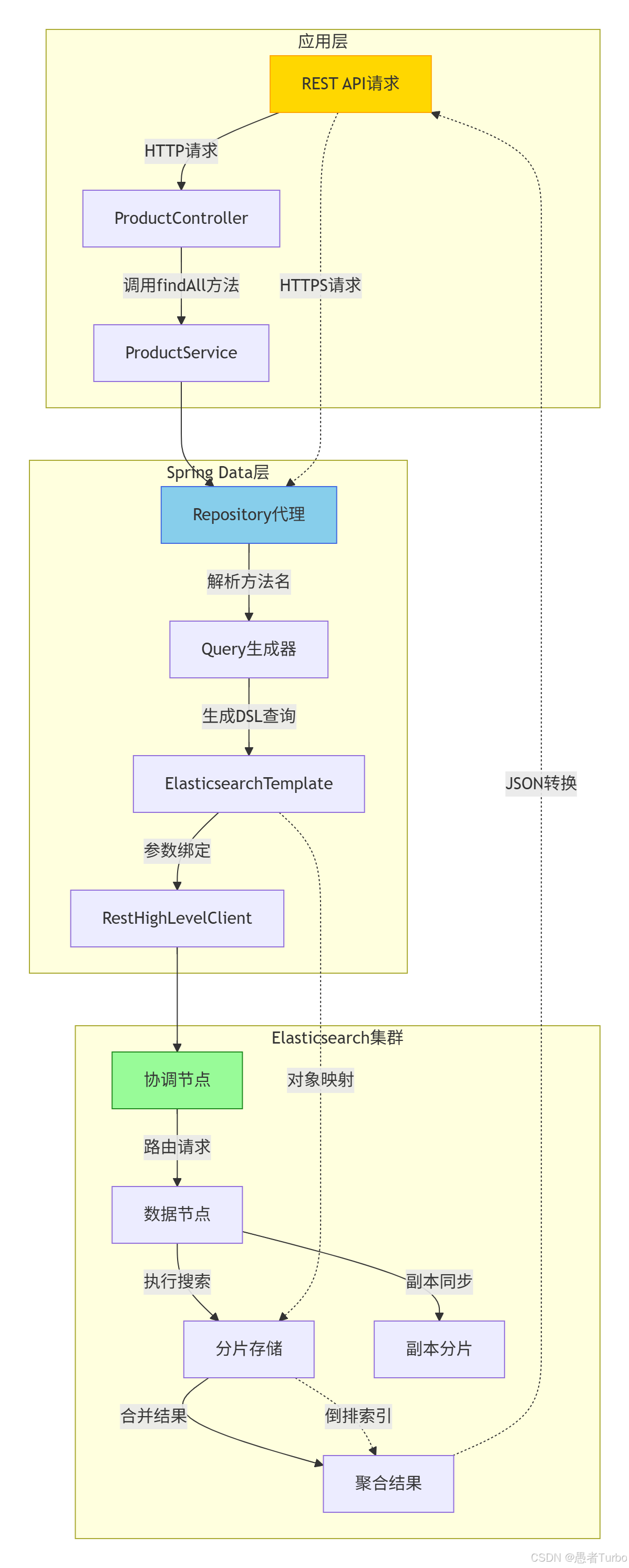
这种分层架构使得Spring Data Elasticsearch既保持了与Spring生态的一致性,又能够灵活适应Elasticsearch的版本变化和功能扩展。开发者可以根据需要选择使用高级的Repository接口,或更底层的模板类,实现不同程度的定制化操作。
四、解决的问题与核心价值
Spring Data Elasticsearch主要解决了以下问题,为开发者提供了显著的价值:
简化对象与文档的映射 :通过@Document和@Field注解,开发者可以轻松定义Java对象与Elasticsearch文档之间的映射关系,无需手动编写复杂的JSON转换代码。如,使用@Field(type = FieldType.Text)可以指定某个字段为全文文本类型,而@Field(type = FieldType Keyword)则指定为精确值类型。
统一的数据访问接口 :提供与Spring Data其他模块(如Spring Data JPA)一致的编程模型,包括Repository、CrudRepository和PagingAndSortingRepository等接口,使得开发者能够快速上手,减少学习成本。
自动索引管理 :根据实体类的注解自动创建Elasticsearch索引和映射,避免了手动维护索引定义的繁琐工作。如,使用@Document(indexName = "product")会自动创建名为"product"的索引。
简化复杂查询 :支持通过方法命名规则动态生成查询条件,如findByPriceBetween会自动生成基于价格范围的查询。同时,也支持通过@Query注解直接编写Elasticsearch的DSL查询,满足更复杂的查询需求。
分布式环境支持:简化了Elasticsearch集群的配置和连接管理,支持负载均衡和故障转移,使开发者能够专注于业务逻辑而非底层基础设施的维护。
安全认证集成:与Elasticsearch 8.x的安全认证机制无缝集成,支持HTTPS连接和用户密码认证,确保数据传输的安全性。
性能优化:提供分页、批量操作等特性,优化了Elasticsearch的使用效率,特别是在处理大量数据时。
通过解决这些问题,Spring Data Elasticsearch的核心价值在于降低了Elasticsearch的使用门槛,提高了开发效率,同时保持了Elasticsearch的高性能和分布式特性。它使得Java/Spring开发者能够快速集成Elasticsearch,实现高效的全文检索、日志分析、实时数据处理等功能,而无需深入理解Elasticsearch的底层API和配置细节。
五、关键特性与功能
Spring Data Elasticsearch提供了丰富的功能特性,主要包括以下几个方面:
1. 注解驱动的数据映射
通过@Document和@Field注解,开发者可以轻松定义索引和字段的映射关系:
@Document(indexName = "product", shards = 2, replicas = 1)
public class Product {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String name;
@Field(type = FieldType long, index = false)
private Double price;
// 省略getter和setter方法
}@Document注解定义了索引的基本属性,如名称、分片数和副本数;@Field注解则控制字段的类型、分词器等特性。这种注解驱动的方式大大简化了对象与文档之间的映射配置,提高了开发效率。
2. 自动创建索引与映射
Spring Data Elasticsearch可以根据实体类的注解自动创建Elasticsearch索引和映射,无需手动编写索引定义。例如,上述Product类会自动创建名为"product"的索引,并根据@Field注解定义字段类型和分词器。
3. 分页与排序支持
通过Pageable和Sort参数,开发者可以轻松实现分页和排序功能:
Pageable pageable = PageRequest.of(0, 10, Sort.by(Sort.Direction.ASC, "price"));
Page<Product> products = productRepository.findAll(pageable);这种分页支持特别适合处理大量数据的场景,如日志分析、商品搜索等,可以显著减少网络传输和内存消耗。
4. 动态查询与条件筛选
Spring Data Elasticsearch支持通过方法命名规则动态生成查询条件:
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
List<Product> findByPriceBetween AndCategoryIsNot(double minPrice, double maxPrice, String category);
}方法命名遵循Spring Data的规则,如"findBy"表示查询,"Between"表示范围查询,"IsNot"表示不等于条件,系统会自动解析这些关键字并生成相应的Elasticsearch查询。
5. 聚合分析
Spring Data Elasticsearch提供了对Elasticsearch聚合功能的支持:
AggregationBuilder aggregationBuilder = AggregationBuilders
.terms("categoryAgg")
.field("category")
.size(10);
SearchQuery searchQuery = new NativeSearchBuilder()
.withQuery matchAllQuery())
.withAggregation/aggregationBuilder)
.build();
SearchResponse response = elasticsearchTemplate.search/searchQuery, Product.class);
Terms terms = response.getAggregations().get("categoryAgg");
for (Terms.Bucket bucket : terms) {
System.out.println(bucket.getKey() + ": " + bucket.getDocCount());
}聚合分析是Elasticsearch的核心功能之一,通过Spring Data Elasticsearch可以简化聚合查询的实现,帮助开发者快速获取数据统计信息。
6. 高亮显示
Spring Data Elasticsearch支持搜索结果的高亮显示功能:
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
@Query("{" +
" \"query\": {\"match\": {\"name\": \"?0\"}}, " +
" \"highlight\": {" +
" \"fields\": {\"name\": {}} " +
" }" +
"}")
List<Product> findByNameWithHighlight(String name);
}高亮显示功能在搜索结果中特别有用,可以直观地显示用户查询的关键字在文档中的位置,提高搜索体验。
7. 动态索引名
Spring Data Elasticsearch支持动态索引名,便于在不同环境(如开发、测试、生产)中使用不同的索引:
@Document(indexName = "product-#{@env.active}")
public class Product {
// ...
}
@Configuration
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
@Value("${spring.profiles.active}")
private String active;
@Bean
public String env() {
return new IndexNameBean(active);
}
@Override
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.withBasicAuth("elastic", "your-password")
.build();
return RestClients.create(clientConfiguration).rest();
}
}动态索引名功能特别适合多环境部署和日志按时间分区的场景,如按天创建索引"logs-2025-09-26"。
六、与同类产品对比
1. 与Elasticsearch原生API对比
| 特性 | Spring Data Elasticsearch | Elasticsearch原生API |
|---|---|---|
| 学习曲线 | 低(基于Spring生态) | 高(需理解JSON和DSL) |
| 对象映射 | 自动映射(注解驱动) | 手动处理JSON转换 |
| 查询方式 | 方法命名或DSL | 手动构建JSON查询 |
| 分页支持 | 内置分页(Pageable) | 手动处理分页参数 |
| 客户端管理 | Spring管理生命周期 | 手动创建和销毁 |
| 事务支持 | 不支持 | 不支持 |
Spring Data Elasticsearch的主要优势在于简化了Elasticsearch的使用,特别是对于已经熟悉Spring生态的开发者来说,可以快速上手。而Elasticsearch原生API的优势在于提供了更底层的控制,可以实现更复杂的查询和更精细的性能调优。
2. 与Solr对比
| 特性 | Spring Data Elasticsearch | Spring Data Solr |
|---|---|---|
| 客户端类型 | REST High-Level Client | SolrJ |
| 分布式支持 | 天然分布式架构 | 依赖ZooKeeper |
| 实时性 | 高(近实时) | 低(需定期提交) |
| 文件格式支持 | JSON | JSON、XML、CSV、PDF、Office等 |
| 社区活跃度 | 高 | 中等 |
| 易用性 | 高(与Spring Boot无缝集成) | 中等 |
Elasticsearch在实时性和分布式支持方面具有优势 ,适合需要快速索引和查询的场景;而Solr在文件格式支持和稳定性方面表现更好,适合传统的搜索应用。Spring Data Elasticsearch作为Spring生态的一部分,与Spring Boot的集成更加紧密,配置更加简单,适合Java/Spring项目。
七、使用方法与最佳实践
1. 环境准备与依赖配置
首先需要安装Elasticsearch并启动服务:
docker run -d --name es8 -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e "ES_JAVA_OPTS=-Xms1g -Xmx1g" \
docker.elastic.co/elasticsearch/elasticsearch:8.11.1然后在Spring Boot项目中添加依赖:
<dependencies>
<!-- Spring Boot核心依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring Data Elasticsearch -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- Elasticsearch官方Java客户端 -->
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.11.1</version>
</dependency>
</dependencies>2. 配置Elasticsearch连接
在application.yml中配置Elasticsearch连接信息:
spring:
elasticsearch:
uris: https://localhost:9200
username: elastic
password: your-password
connect-timeout: 5000
socket-timeout: 30000
# 启用SSL验证(可选)
# ssl:
# truststore-path: path/to/truststore.jks
# truststore-password: password对于Elasticsearch 8.x版本,默认启用了安全认证和HTTPS协议,因此需要提供用户名和密码。如果不需要SSL验证,可以使用HTTP协议并省略SSL配置。
3. 定义实体类与索引映射
使用@Document和@Field注解定义实体类:
@Document(indexName = "product", shards = 2, replicas = 1)
public class Product {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String name;
@Field(type = FieldType长期, index = false)
private Double price;
@Field(type = FieldType long, name = "category_id")
private Long类别ID;
@Field(type = FieldType Text,fielddata = true)
private String description;
// 省略getter和setter方法
}@Document注解定义了索引的基本属性 ,如名称、分片数和副本数;@Field注解则控制字段的类型、名称和分词器等特性。fielddata = true表示为该文本字段创建正向索引,以便进行聚合操作,但需要注意这会增加内存消耗。
4. 创建存储库接口
定义一个继承自ElasticsearchRepository的接口:
public interface ProductRepository extends ElasticsearchRepository<Product, Long> {
List<Product> findByNameStartingWith(String prefix);
@Query("{" +
" \"query\": {\"match\": {\"name\": \"?0\"}}, " +
" \"highlight\": {" +
" \"fields\": {\"name\": {}} " +
" }" +
"}")
List<Product> findByNameWithHighlight(String name);
}存储库接口是Spring Data Elasticsearch的核心 ,通过继承ElasticsearchRepository,可以获得一系列基本的CRUD操作。同时,也可以通过方法命名规则或@Query注解定义自定义查询。
5. 实体类的高级映射
Spring Data Elasticsearch支持更复杂的映射场景,如嵌套对象和多字段映射:
@Document(indexName = "order")
public class Order {
@Id
private Long id;
@Field(type = FieldType long)
private Long userId;
@Nested
private User user;
@MultiField
private String description;
@MultiField mainField = @Field(type = FieldType Text),
otherFields = @Field(name = "description_keyword", type = FieldType keyword)
private String description;
}@Nested注解用于映射嵌套对象 ,适合处理复杂的数据结构;@MultiField注解则允许为一个字段定义多个子字段,如同时支持全文搜索和精确匹配。
6. 动态索引名实现
通过SpEL表达式和配置类实现动态索引名:
@Document(indexName = "product-#{@indexNameBean.active}")
public class Product {
// ...
}
@Configuration
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
@Value("${spring.profiles.active}")
private String active;
@Bean
public IndexNameBean indexNameBean() {
return new IndexNameBean(active);
}
@Override
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.withBasicAuth("elastic", "your-password")
.build();
return RestClients.create(clientConfiguration).rest();
}
}动态索引名特别适合多环境部署和按时间分区的场景,如开发环境使用"product-dev",生产环境使用"product-prod"。
7. 高亮显示实现
自定义SearchResultMapper处理高亮结果:
public class HighlightResultMapper implements SearchResultMapper {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse searchResponse, Class<T> clazz, Pageable pageable) {
long totalHits = searchResponse.getHits().getTotalHits();
List<T> list = new ArrayList<>();
SearchHits hits = searchResponse.getHits();
if (hits.getHits().length > 0) {
for (SearchHit searchHit : hits.getHits()) {
Map<String, HighlightField> highlightFields = searchHit.getHighlightFields();
T item = JSON.parseObject(searchHit.getSourceAsString(), clazz);
for (String highlightKey : highlightFields.keySet()) {
HighlightField highlightField = highlightFields.get(highlightKey);
if (highlightField != null) {
try {
Field field = clazz.getDeclaredField(highlightKey);
field.setAccessible(true);
field.set(item, highlightField.getFragments()[0].toString());
} catch (NoSuchFieldException | IllegalAccessException e) {
e.printStackTrace();
}
}
}
list.add(item);
}
}
return new AggregatedPageImpl<>(list, pageable, totalHits);
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> clazz) {
return null;
}
}
@RestController
public class ProductController {
@Autowired
private ProductRepository productRepository;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@GetMapping("/products")
public Page<Product> getProducts(@RequestParam String keyword, @RequestParam int page, @RequestParam int size) {
NativeSearchQuery searchQuery = new NativeSearchQuery(
QueryBuilders.matchQuery("name", keyword)
);
searchQuery.setHighlightBuilder(new HighlightBuilder()
.field("name")
.preTags("<em>")
.postTags "</em>")
);
return productRepository.search(searchQuery, PageRequest.of(page, size));
}
@GetMapping("/products/with-highlight")
public List<Product> getProductsWithHighlight(@RequestParam String keyword) {
SearchQuery searchQuery = new NativeSearchBuilder()
.withQuery(matchQuery("name", keyword))
.withHighlightBuilder(new HighlightBuilder()
.field("name")
.preTags "<em>")
.postTags "</em>")
)
.build();
return elasticsearchTemplate.search(
searchQuery, Product.class, new HighlightResultMapper()
);
}
}高亮显示功能在搜索结果中特别有用,可以直观地显示用户查询的关键字在文档中的位置,提高搜索体验。
8. 聚合查询实现
使用ElasticsearchTemplate执行聚合查询:
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Override
public Map<String, Long> countByCategory() {
// 创建聚合
AggregationBuilder aggregationBuilder = AggregationBuilders
.terms("categoryAgg")
.field("category_id")
.size(10);
// 构建搜索查询
SearchQuery searchQuery = new NativeSearchBuilder()
.withQuery(matchAllQuery())
.withAggregation/aggregationBuilder)
.build();
// 执行查询
SearchResponse response = elasticsearchTemplate.search/searchQuery, Product.class);
// 解析聚合结果
Terms terms = response.getAggregations().get("categoryAgg");
Map<String, Long> result = new HashMap<>();
for (Terms.Bucket bucket : terms) {
result.put桶的关键(), bucket.getDocCount());
}
return result;
}
}聚合查询是Elasticsearch的核心功能之一,通过Spring Data Elasticsearch可以简化聚合查询的实现,帮助开发者快速获取数据统计信息。
9. 批量操作与性能优化
批量操作可以显著提高数据写入效率:
@Service
public class ProductServiceImpl implements ProductService {
@Autowired
private ProductRepository productRepository;
@Override
public void batchSave(List<Product> products) {
// 分批次保存
IntStream.range(0, products.size()).boxed()
.collect(Collectors.groupingBy(
i -> i / 1000,
Collectors mapping(i -> products.get(i), Collectors.toList())
))
.values()
.forEach(productRepository::saveAll);
}
@Override
public void deleteAll() {
productRepository.deleteAllInBatch();
}
}批量操作是处理大量数据的关键,可以显著提高写入和删除效率。建议根据Elasticsearch集群的性能调整批次大小,通常在1000到5000之间。
10. 安全认证配置
对于Elasticsearch 8.x版本,需要配置安全认证:
@Configuration
public class ElasticsearchConfig extends AbstractElasticsearchConfiguration {
@Value("${elasticsearch uris}")
private String uris;
@Value("${elasticsearch username}")
private String username;
@Value("${elasticsearch password}")
private String password;
@Override
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo this.uris)
.withBasicAuth this.username, this.password)
.build();
return RestClients.create(clientConfiguration).rest();
}
}安全认证是Elasticsearch 8.x版本的默认配置,必须在连接时提供用户名和密码。对于测试环境,可以使用Elasticsearch提供的默认用户"elastic"和启动时生成的密码。
八、总结与未来展望
Spring Data Elasticsearch作为Spring框架对Elasticsearch的封装,显著降低了Elasticsearch的使用门槛,提高了开发效率,同时保持了Elasticsearch的高性能和分布式特性。它通过注解驱动的数据映射、统一的Repository接口、自动索引管理等功能,简化了Elasticsearch的集成过程,使得Java/Spring开发者能够快速构建高效的搜索和分析应用。
未来,随着Elasticsearch的持续演进,Spring Data Elasticsearch也将不断更新,以支持Elasticsearch的新特性,如更强大的聚合功能、更灵活的查询语法等。同时,随着Spring生态的扩展,Spring Data Elasticsearch可能会与更多Spring组件(如Spring Cloud、Spring Batch等)深度集成,提供更全面的解决方案。
对于开发者来说,掌握Spring Data Elasticsearch的使用方法,将能够更高效地集成Elasticsearch,构建高性能的搜索和分析应用。同时,了解Elasticsearch的底层原理和优化技巧,也能够更好地利用Spring Data Elasticsearch的优势,避免其局限性。
总之,Spring Data Elasticsearch是Java/Spring开发者集成Elasticsearch的理想选择,它通过简化复杂的API和配置,使开发者能够专注于业务逻辑的实现,而非底层技术细节。
参考资料:
本博客专注于分享开源技术、微服务架构、职场晋升以及个人生活随笔,这里有:
📌 技术决策深度文(从选型到落地的全链路分析)
💭 开发者成长思考(职业规划/团队管理/认知升级)
🎯 行业趋势观察(AI对开发的影响/云原生下一站)
关注我,每周日与你聊"技术内外的那些事",让你的代码之外,更有"技术眼光"。
日更专刊:
🥇 《Thinking in Java》 🌀 java、spring、微服务的序列晋升之路!
🏆 《Technology and Architecture》 🌀 大数据相关技术原理与架构,帮你构建完整知识体系!