
1.摘要
background
现有的多模态大语言模型(MLLMs)在处理视频时,对于精细化、细微的运动(fine-grained motion)理解能力严重不足。它们倾向于平均化或忽略视频帧之间的细微视觉差异,导致无法准确捕捉物体微妙的动作或复杂的相机移动等时序动态信息。
innovation
为了解决上述问题,论文提出了两大核心创新:
1.MotionSight 方法 : 一种新颖的、无需额外训练的(zero-shot)推理方法,旨在解锁并增强MLLM固有的运动感知能力。其创新点在于:
运动解耦 : 根据用户问题,将复杂的视频运动分解为"物体运动"和"相机运动"两个独立的子问题进行处理。
目标为中心的视觉聚光灯 (Object-centric visual spotlight) : 针对物体运动,该方法首先利用现有的检测和跟踪模型定位运动物体,然后通过算法调暗背景、高亮运动物体,形成"聚光灯"效果。这能强制模型将注意力集中在关键的动态元素上。
运动模糊合成 (Motion blur synthesis) : 针对相机运动,通过对连续的视频帧进行时间维度的加权融合,人为地创造出"运动模糊"效果。这种模糊可以有效放大场景的全局变化,帮助模型感知到原本不明显的相机平移、缩放或旋转。
2.MotionVid-QA 数据集 : 为了将上述能力转化为可用的数据资产并推动社区发展,作者构建了首个专注于精细化视频运动理解的大规模、高质量数据集。该数据集包含40K个视频片段和约87K个问答对,并提供了可用于监督微调(SFT)和偏好优化(DPO)的层级化标注。
- 方法 Method
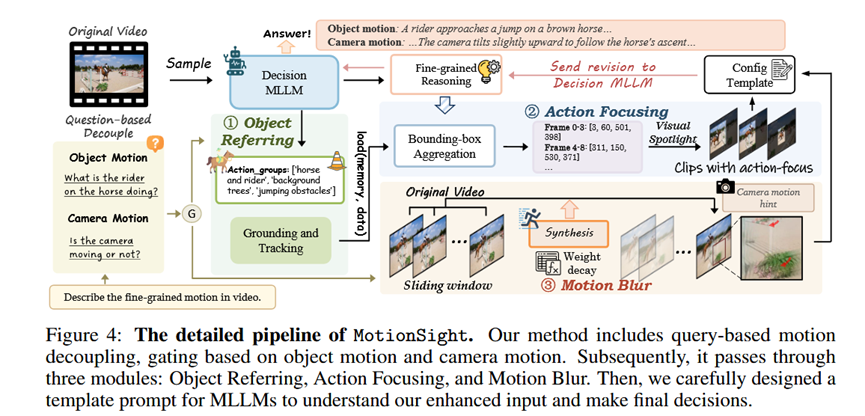
总体 Pipeline
MotionSight的流程是一个基于查询的推理增强管道。它接收一段视频和用户的提问,首先判断问题是关于"物体运动"还是"相机运动"。随后,它通过三个核心模块(物体指代、动作聚焦、运动模糊)对视频进行预处理,生成一个"增强版"的视频输入。最后,将这个增强后的视频与精心设计的提示模板(prompt template)相结合,送入MLLM生成最终的详细描述。
各部分细节 (输入与输出)
模块一:物体指代 (Object Referring)
输入: 原始视频采样帧、用户问题。
处理: 利用MLLM自身的理解能力,根据问题解析出需要关注的关键物体类别。接着,调用GroundingDINO模型在初始帧上检测这些物体,并使用SAM2模型在整个视频序列中对它们进行跟踪。
输出: 一组包含物体在视频每一帧中位置(边界框)的运动轨迹。
模块二:动作聚焦 (Action Focusing) - (用于物体运动)
输入: 上一步生成的物体运动轨迹。
处理: 该模块通过动态时间聚合算法稳定并合并轨迹中的边界框,然后应用"视觉聚光灯"技术,即保留边界框内的原始像素,同时将框外的背景区域调暗。
输出: 经过"聚光灯"高亮处理后的视频帧,其中关键运动物体非常突出。
模块三:运动模糊 (Motion Blur) - (用于相机运动)
输入: 原始的、完整的视频序列。
处理: 对视频中的每一帧,通过一个时间滑动窗口,将其与之前的N个帧进行加权平均。这种时序聚合操作会自然地产生运动模糊效果。
输出: 带有全局运动模糊效果的视频帧。
- 实验 Experimental Results
实验数据集
MotionBench: 一个大规模、精细化运动级别的基准测试,涵盖运动识别(MR)、位置相关运动(LM)、相机运动(CM)等六种任务。
FAVOR-Bench: 一个专注于精细化视频动作理解的基准测试,涵盖动作序列(AS)、相机运动(CM)、非主体运动(NSM)等六类问答。
实验结论及目的
1.与SOTA方法对比:
实验目的: 验证MotionSight方法的整体有效性及其在当前技术水平下的竞争力。
实验结论: 无论是在MotionBench还是FAVOR-Bench上,MotionSight都能一致地、显著地提升多种基础MLLM的性能。搭载了MotionSight的InternVL3-78B模型在所有开源模型中取得了最佳成绩,证明了该方法的强大能力。
2.消融实验:
实验目的: 验证MotionSight中各个核心组件(特别是"视觉聚光灯"和"运动模糊")的必要性和有效性。
实验结论 : 对于物体运动 理解,"视觉聚光灯"策略带来的提升最大;而直接从图像任务迁移的"背景模糊"方法效果最差,甚至会产生负面影响。对于相机运动理解,"全局运动模糊"策略带来了超过14%的巨大性能提升,效果显著。
- 总结 Conclusion
本文的核心信息是:通过巧妙且无需训练的视觉预处理技术(如模拟"聚光灯"和"运动模糊"),可以有效"解锁"并增强现有MLLMs对视频中复杂、细微动态信息的感知和理解能力。此外,高质量、大规模的领域专用数据集是推动相关技术发展的关键基石。