Falcon-TST: A Large-Scale Time Series Foundation Model
Prediction过程:
① 输入长度大于固定长度2880 会截断,小于2880会进行前置padding
② RevIN 处理,并通过旋转位置编码嵌入相对位置信息
③ 选定专家路由
④ 共享专家
⑤ Patch Embedding , 输入 batch, patch_num, patch_size --> patch_num, batch_size, hidden_size, 输出 :hidden_states, attention_mask, input_mask
⑥ Transformer Layer : 没使用因果注意力机制,采用的Transfomer的Encoder架构
⑦ 共享专家输出+领域专家输出 ,其中前固定长度seq_length 为原始, 后面336为预测长度
⑧ 推理出混合专家的输出,根据自回归头预测,如果混合专家输出长度大于目标长度,截取目标部分即可。
FalconTST的预测模式:自回归式多步预测(分段式)
① FalconTST在推理时,每一次forward都预测一个固定的最长步长(max(multi_forecast_head_list));
② 在自回归滚动过程中,并不会每次都使用这96步全部结果,而是根据剩余预测长度,只截取其中前多少步做有效预测,并拼接回输入继续预测。
FalconTST采用N-BEATS方法进行迫使模型逐层剥离信号。
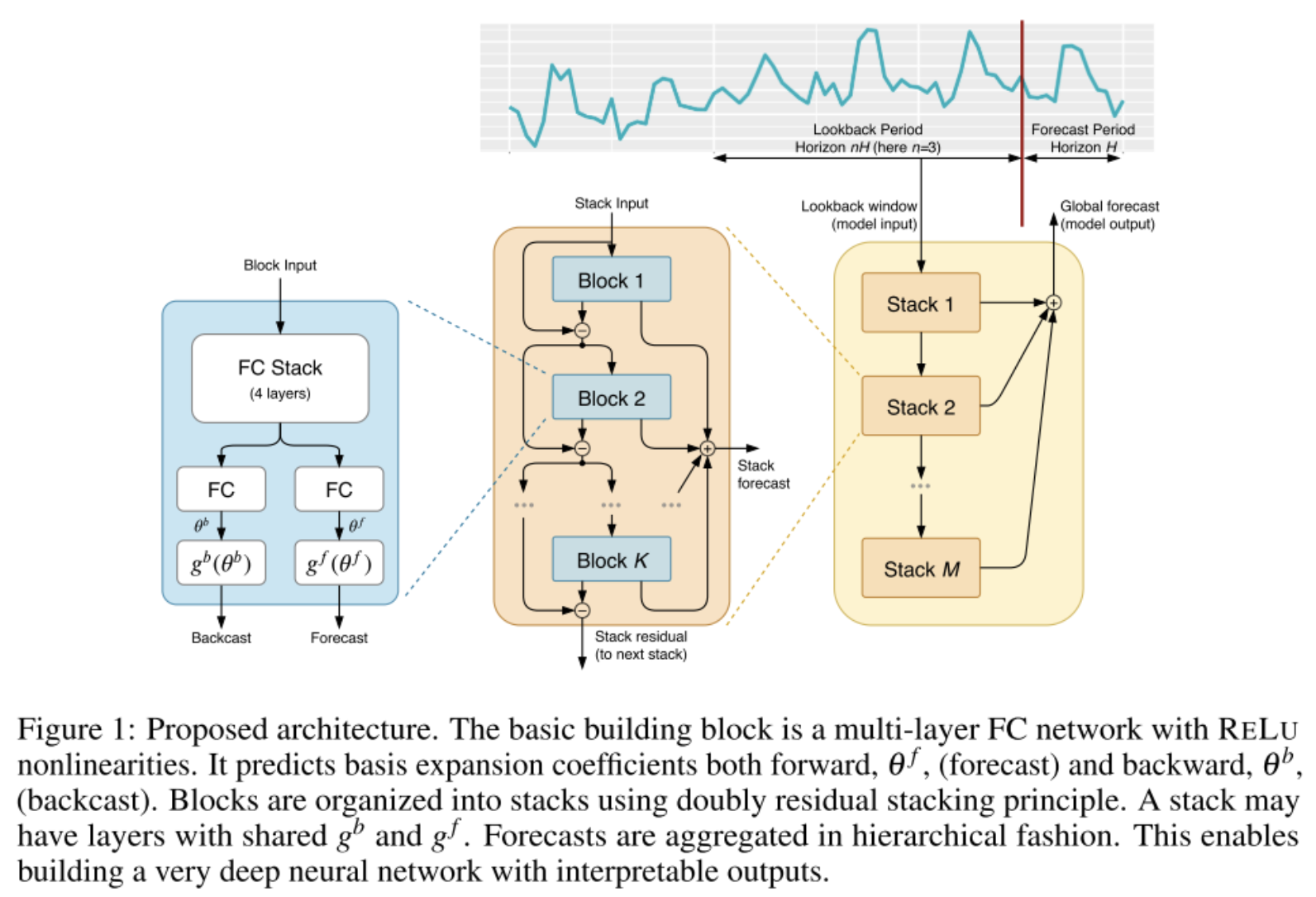
N-BEATS 模型由多个Stack模块组成 ,每个stack由多个block串联而成 ,其中第一个block的输入为原始输入序列,输出为两部分,一是对于未来窗口H的预测值 y ^ \hat{y} y^ , 二是对于block输入的重构值 x ^ \hat{x} x^。一方面,下一个block作为之前block的补充,不断地去拟合之前block没有拟合到的残差信息,另一方面,可以将该过程看作对时间序列的分解,不同的stack中block拟合时间序列某一部分的信息,最终NBEATS的输出为各个stack的输出。
因此,FalconTST 在使用时,使用FalconTSTMoELayer层替换FC层结构,其中FalconTST的共享专家和路由专家 都是由Transformer的Encoder层构建的,因此利用MOE中共享专家与路由专家的输出,合并之后分割成backcast和forecast,不断获取forecast,并求和,backcast不断缩减,直接最后为空。
差异点:共享专家和路由专家共同构建了是一个完整的基于Transformer架构的模型,它并没有采用两个FC分别建模Backcast和Forecast,而是每一个专家都建模Backcast与Forecast。要求每个专家同时完成:
① 解释过去(Backcast): "我认为过去这段序列发生了什么(比如是某个特定频率的波形)"。
② 预测未来(Forecast): "基于我对过去的这种理解,我认为未来会怎么走"。
FalconTST中,FalconTSTMoELayer充当一个N-BEATS Block的角色,Block的输入是上一层的残差,Block的输出一个是用于修正的Backcast和一个用于贡献预测的Forecast。
问题点:为什么FalconTST模型使用的是Transformer Encoder还要利用mask机制?
FalconTST使用Attention Mask不是为了因果性,主要是为了屏蔽完全被padding填充的无效Patch,确保模型不会关注到没有意义的填充区域,这是数据有效性的过滤。