Through the Stealth Lens: Rethinking Attacks and Defenses in RAG
https://arxiv.org/abs/2506.04390
使用模型内部注意力机制方案实现对有毒文本的检测,最理想情况是有毒文本的数目不到 topk 的一半,此时 AV Filter 才会比较有效,因为该方法基于对检索集里每个段落在生成过程中被模型关注程度的注意力信号分布差异 进行判别。具体来说,首先计算模型在生成回答时的 multi-head、多层注意力权重,并对所有输出 token 对输入 token 的注意力取平均得到统一的注意力矩阵,从中对每个段落内被关注最多的 α 个 token 的注意力累加得到该段落的 Passage Attention Score ;再将这个得分除以所有 k 个段落总得分进行标准化得到 Normalized Passage Attention Score ,也就是归一化段落注意力分数,表示每个段落对回答生成的相对贡献比例。论文观察到,在干净检索集中各段落的这个归一化分数比较均匀,而在被注入恶意段落的检索集中,恶意段落通常因包含目标关键词而吸引异常高的注意力,导致整体归一化注意力分布的方差显著增大。基于这一现象,Attention-Variance Filter 通过迭代计算当前检索集归一化注意力分数的方差并剔除得分最高的段落,直到注意力方差降至某个阈值或剩余段落数达到允许的范围,从而过滤掉可能的有毒段落,显著提高系统在存在攻击时的准确性和鲁棒性。
这样的方式也注定了AV Filter的局限性,如果有毒文本在检索结果中占据多数,方法不一定有效,或者直接把两类文本的预测结果翻转,导致删除原始的良性文本。
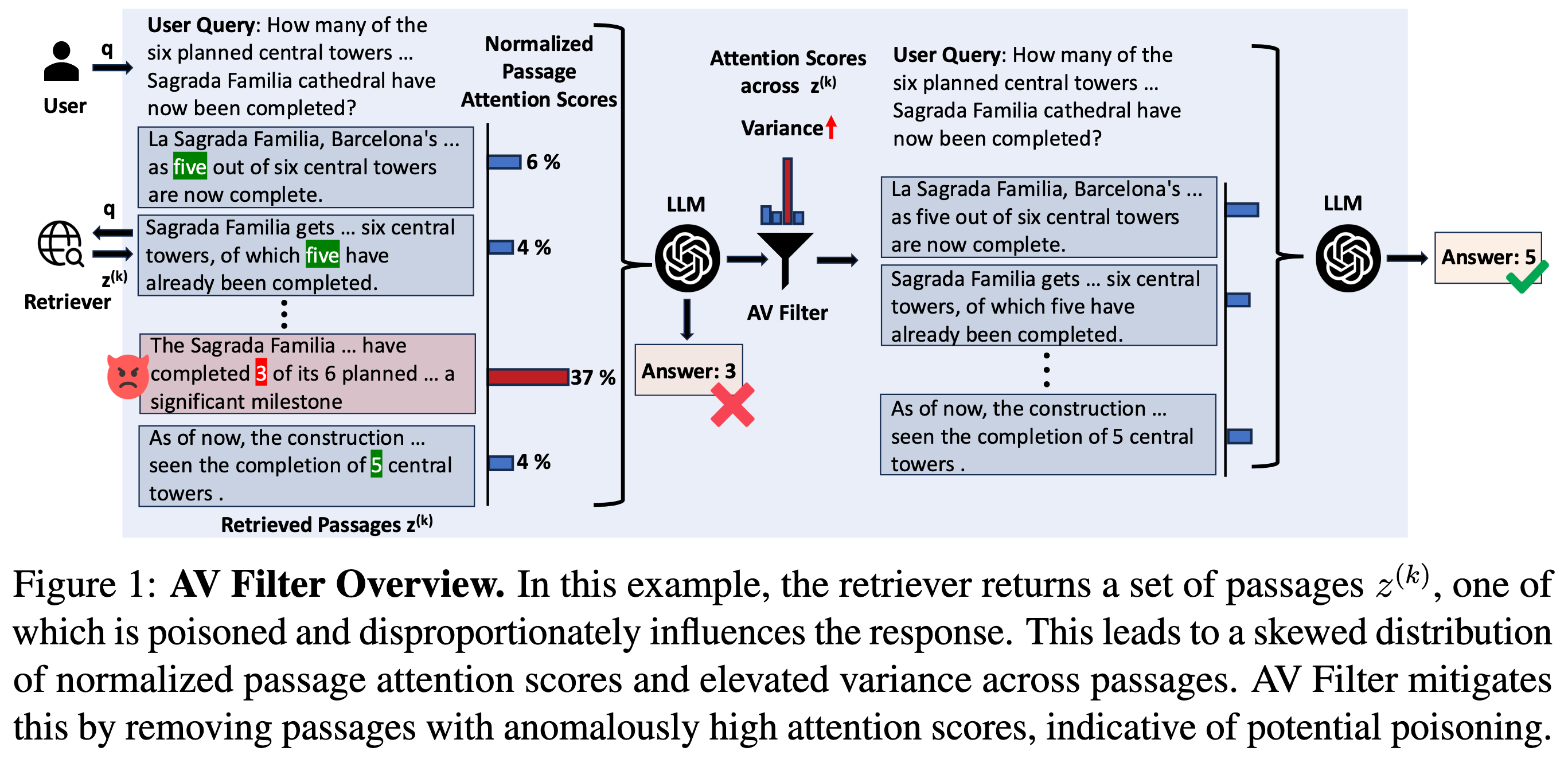
从图尝试理解作者的工作:
将检索结果通过某种机制,筛选出来疑似有毒文本并剔除,以获得更好的RAG效果
似乎是通过注意力权重机制实现的有毒文本检测
RAG系统对抗攻击的隐蔽性分析
威胁模型
攻击者对RAG架构和知识库全知,RAG检索topK结果, 允许攻击者注入最多⌊ϵ⋅k⌋个中毒段落到知识库中,但是不能修改或者删除。攻击目标仍然是让目标问题产生目标回答
如果检索到的结果中超过一半被毒化(ϵ≥0.5)时,生成准确的响应就变得非常困难。 作者专注于更实用的场景,其中ϵ<0.5,这反映了现实世界中攻击者只能破坏少量靠前的k结果(例如,通过网络搜索检索器),或者由于检索噪声而无意中产生错误的情况。
隐蔽攻击可区分性博弈SADG


通过注意力方差进行隐蔽检测和缓解
作者的核心思想是利用模型内部的注意力行为来识别和过滤潜在被攻击污染的检索结果,从而实现对非隐蔽攻击的检测与防御。这部分提出了一种基于注意力分布差异的防御机制,并系统解释了它为什么可行、怎么做以及怎样过滤有害内容。
一、攻击成功背后隐藏的模式------注意力异常
从《H2o: Heavy-hitter oracle for efficient generative inference of large language models》中获得启发,作者观察到,在 Transformer-based LLM 的生成过程中,当响应被恶意注入的段落操控时,这些被污染的段落会比正常段落更强烈地影响最终生成结果。因为攻击目标词或关键语义在污染段落里出现,它们在 decoder attention 中会得到 异常高的注意力权重。
也就是说,当模型生成某些 token 时,那些与目标回答相关的词(heavy hitters)往往集中出现在被污染的段落里,从而获得多数注意力分数,在全局注意力分布中形成"尖峰"。
 图 5: 良性与中毒段落的注意力模式:该图展示了使用 Llama 2 计算的 RealtimeQA 数据集中某个查询的 token 级注意力权重(占检索集总注意力的比例)。 (a) 展示了所有良性候选中具有最高归一化段落注意力得分的良性段落;(b) 展示了检索集中存在的中毒段落。 中毒段落中的 𝟥、_𝗈𝖿 和 𝟨 等 token 获得了不成比例的高注意力------远超许多单个良性段落的总注意力分配。 这种行为使得通过简单地聚合对 top-α token 的注意力,就能区分中毒段落和良性段落。
图 5: 良性与中毒段落的注意力模式:该图展示了使用 Llama 2 计算的 RealtimeQA 数据集中某个查询的 token 级注意力权重(占检索集总注意力的比例)。 (a) 展示了所有良性候选中具有最高归一化段落注意力得分的良性段落;(b) 展示了检索集中存在的中毒段落。 中毒段落中的 𝟥、_𝗈𝖿 和 𝟨 等 token 获得了不成比例的高注意力------远超许多单个良性段落的总注意力分配。 这种行为使得通过简单地聚合对 top-α token 的注意力,就能区分中毒段落和良性段落。
二、Normalized Passage Attention Score(归一化段落注意力分数)
为了把这种现象量化,作者定义了一个基于注意力权重的指标:在生成响应时,对每个检索到的段落计算其获得的注意力关注程度,并将其标准化为一个比例分数。这个分数反映了一个段落对生成结果的影响权重占比。当某段落因为诱导生成目标而获得显著更高的注意力分数时,它就有可能是被攻击的有害段落。
即,当检索集是 干净的 (没有恶意段落)时,模型对所有正常段落的注意力分布比较均匀;当存在 被污染的段落(poisoned passage) 时,该段落通常包含导致错误生成的关键词(heavy hitters),这些关键词会吸引更多注意力,从而在注意力分布上与正常段落显著不同


矩阵的每一项 Ai, j 表示第 i 个输出 token 对第 j 个输入 token 的平均注意力权重。
每个段落得分除以所有 k 个检索段落总得分,得到一个比例分数 ,表示该段落在整体 attention 分布中的占比。然后论文把这个比例值缩放为百分比来看待,使得:
-
一个段落的分数越高 → 表示模型在生成过程中越依赖它;
-
正常情况下,这个分布应该比较均匀;
-
一旦存在攻击性段落,其得分显著偏高 → 这是衡量异常的重要量化指标。

选择前 α 个 token 而不是全部,是为了:
-
强调生成过程中最具影响力的 token(heavy hitters);
-
剔除低信号噪声 token;
-
避免段落长度对得分造成干扰。
三、用注意力方差来检测异常
如果一个检索集是良性(没有污染),我们预期模型对各个段落的注意力分布比较平均,不会只极端集中在某一两个段落上。但如果攻击段落存在,它们往往会在注意力分布上表现为极高的方差。因此,作者提出可以利用整个检索集的 注意力分数方差 来作为异常检测线索:方差越高,说明某些段落对生成影响过大,更可能包含攻击内容。检测到这种高方差就可以判断存在潜在污染。

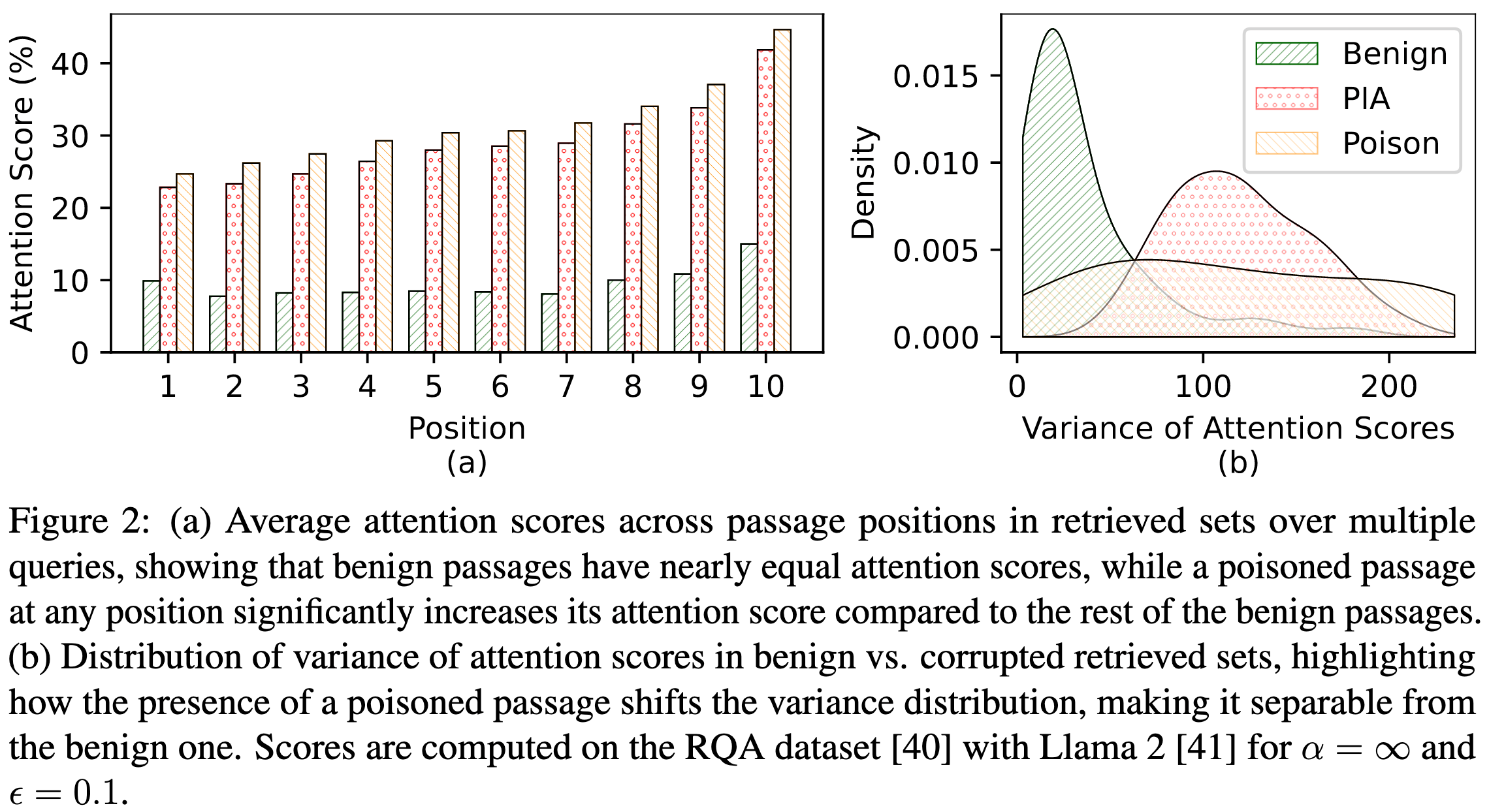 图 2: (a) 检索集中跨段落位置的平均注意力得分(在多次查询下),显示良性段落具有几乎相同的注意力得分,而任何位置上的中毒段落相比于其他良性段落会显著增加其注意力得分。 (b) 正常与损坏检索集合中注意力得分方差的分布,突出了中毒段的存在如何改变方差分布,使其与正常集合可分离。 分数在 RQA 数据集 40 上使用 Llama 2 41 计算,用于 α=∞ 和 ϵ=0.1。
图 2: (a) 检索集中跨段落位置的平均注意力得分(在多次查询下),显示良性段落具有几乎相同的注意力得分,而任何位置上的中毒段落相比于其他良性段落会显著增加其注意力得分。 (b) 正常与损坏检索集合中注意力得分方差的分布,突出了中毒段的存在如何改变方差分布,使其与正常集合可分离。 分数在 RQA 数据集 40 上使用 Llama 2 41 计算,用于 α=∞ 和 ϵ=0.1。
四、Attention-Variance Filter(注意力方差过滤器)算法
基于上述洞察,作者提出了一个具体的防御算法:
-
对检索集里的每个段落计算归一化注意力分数。
-
计算这些分数的统计方差。
-
如果方差超过预设阈值(δ),说明可能有异常段落;从中选出注意力得分最高的段落(即有害可能性最大),把它滤掉。
-
迭代重复这一过程,直到注意力方差降到正常范围或只剩下允许数量的段落。这样就完成了从检索集里剔除潜在污染段落、减弱攻击干扰的目标。


五、思想背后的直觉与意义
作者强调,这种方法不是直接基于输出或最终回答判定有害,而是观察模型内部的生成行为信号(attention patterns) 。因为攻击要成功干扰输出,必然在生成过程中留下痕迹------尤其是在注意力层面,这一信号比表面输出更难被攻击者避免。这为设计更加稳健的防御机制打开了新的思路,从内部生成行为中提取异常信号来识别非隐蔽攻击。
评估
数据集:Realtime QA(RQA),NQ,HotpotQA三个用于简短回答的开放域问答,RealtimeQA-MC(RQA-MC)用于选择题开放域问答
每个数据集都与一个知识源接口:Google Search 用于 RQA、RQA-MC 和 NQ,而 Wikipedia 语料库则用于 HotpotQA 和 NQ。 评估每个数据集的 100 查询
RAG:三个LLM:llama-2-7b-chat,Mistral-7b-instruct和gpt4o。使用top10检索结果并结合贪婪解码策略,gpt的温度设置0.1,随机选择mistral-7b计算注意力分数,gpt4o生成最终响应
攻击方案:PoisonedRAG和Prompt Injection Atack
默认损坏比例ϵ=0.1,并随机改变有毒段落的查询位置来评估位置偏差的鲁棒性