实战中的 Merkle 树
Engineer's Codex · 2025年5月11日
导言
Cursor,这个流行的 AI IDE(最近宣布 ARR 达到 3 亿美元),使用 Merkle 树 来实现代码的快速索引。本文将详细解释其工作方式。
在进入 Cursor 的实现之前,我们先理解什么是 Merkle 树。
Merkle 树的简明解释
Merkle 树是一种树形结构:
- 每个叶子节点存储一个数据块的加密哈希值;
- 每个非叶子节点存储其子节点哈希值的哈希。
这种层级结构的好处在于:只要任意一个底层数据块发生改变,其对应的哈希就会变化,从而逐级传递到上层,最终导致根哈希改变。
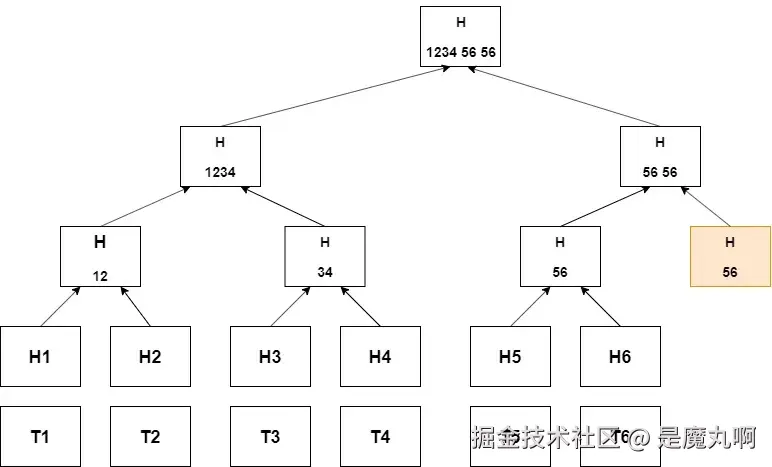
它像是一种数据"指纹系统":
- 每份数据(比如一个文件)都有唯一指纹(哈希);
- 指纹成对组合生成新指纹;
- 一直递归上去,最终得到一个"主指纹"(根哈希)。
根哈希可以看作整个数据集的加密承诺。只要某个部分变了,根哈希也会跟着变。
Cursor 如何用 Merkle 树做代码库索引
根据 Cursor 创始人和其安全文档,流程如下:
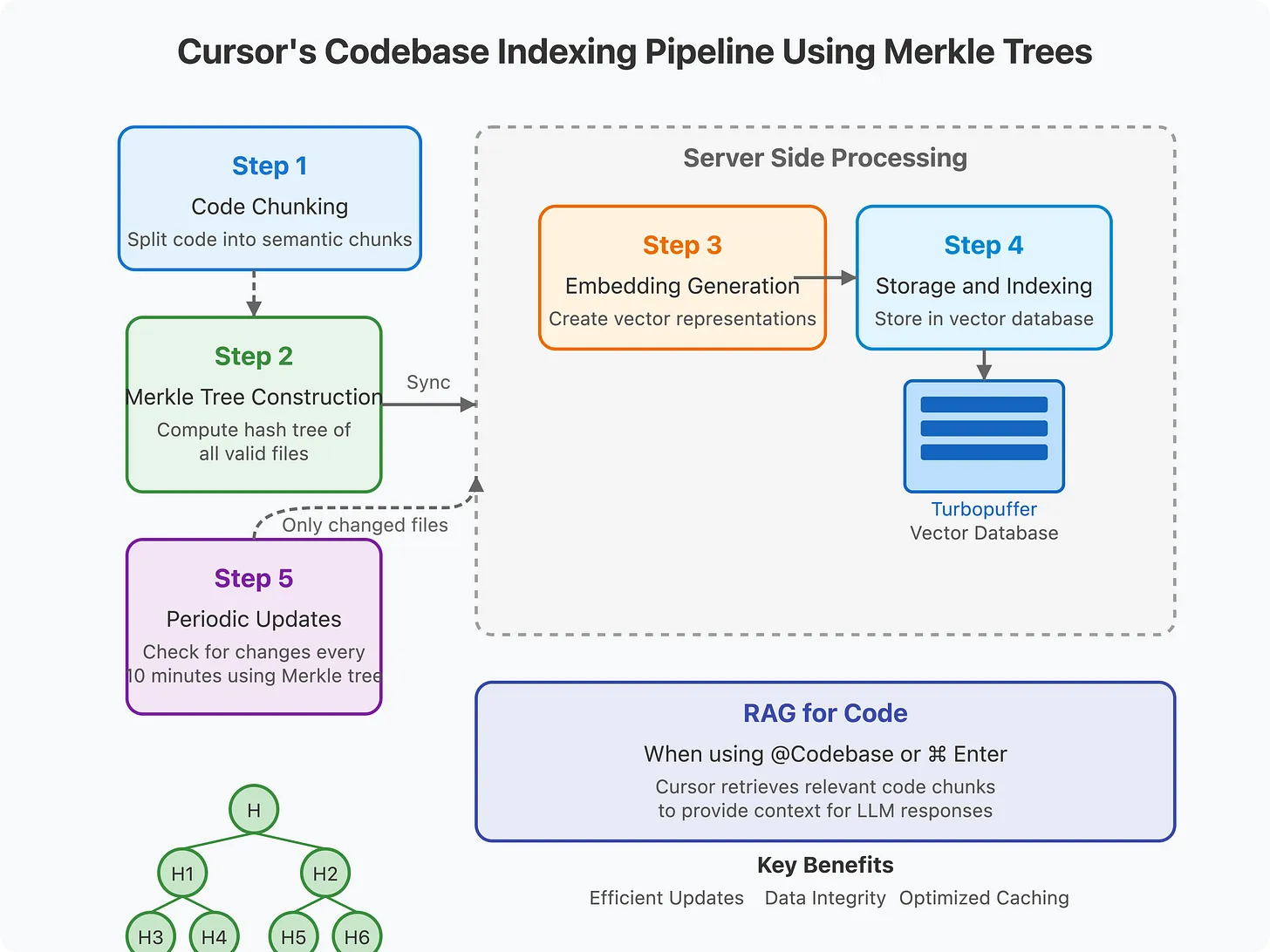
步骤1:代码切分与预处理
Cursor 首先在本地切分文件,把代码拆成有语义意义的片段,然后再进入后续处理。
步骤2:Merkle 树构建与同步
开启代码库索引后,Cursor 会扫描编辑器中打开的文件夹,为所有有效文件计算 Merkle 树哈希。这个树随后与 Cursor 服务器同步。
步骤3:嵌入生成
切分好的片段会传到服务器,由 OpenAI 的 embedding API 或定制模型生成向量嵌入。
步骤4:存储与索引
嵌入连同元数据(起止行号、文件路径)存储在远程向量数据库(Turbopuffer)中。为保护隐私,Cursor 只存储加密后的相对路径。创始人强调:代码本身不会存储在数据库,生命周期结束即删除。
步骤5:定期增量更新
每隔 10 分钟,Cursor 会检查 Merkle 树哈希,找出变更的文件,仅上传变化部分。这样能极大降低带宽开销。
代码切分策略
索引效果在很大程度上取决于如何切分代码:
- 简单方法:按字符、单词、行切割 → 语义断裂严重。
- 定长 tokens 切分:避免超长,但容易切断函数/类。
- 递归文本切分:使用语义边界(函数/类定义)作为分割点,更自然。
- AST(抽象语法树)切分:最优方案。通过遍历 AST,把子树作为片段,合并小块保持 token 不超限。工具如 tree-sitter 支持多语言。
嵌入在推理阶段的使用
生成嵌入后,Cursor 在实际使用中这样调用:
- 查询嵌入:对你的问题或上下文生成嵌入。
- 向量相似搜索:在 Turbopuffer 中检索最相似的代码片段。
- 本地文件读取:客户端根据返回的文件路径和行号读取本地代码。
- 上下文组装:相关代码片段作为上下文,和问题一起发给 LLM。
- 响应生成:模型在上下文支持下生成回答或补全。
这支持了:
- 上下文感知的代码生成
- 代码库问答
- 更智能的补全
- 智能化重构
为什么用 Merkle 树
- 高效增量更新:快速定位变更文件,只上传修改部分。
- 数据完整性校验:层级哈希能检测传输错误或不一致。
- 缓存优化:基于 chunk 哈希的缓存,使得二次索引更快。
- 隐私保护:路径加密处理,隐藏敏感信息。
- Git 历史集成:索引 Git commit 信息,团队共享更方便。
嵌入模型与挑战
- 模型选择会显著影响检索质量。Cursor 可能用 OpenAI 的模型,或调优过的专用代码模型(如 unixcoder、Voyage Code)。
- 嵌入模型受 token 限制,需通过合理切分来适配。
握手流程
初始化索引时,Cursor 会创建"merkle client",并把根哈希发给服务器。服务器据此判断需要同步的部分。这一过程在 GitHub issue (#2209, #981) 的日志中可见。
技术实现挑战
- 负载问题:索引时请求量大,导致失败和重试,网络流量增加。
- 嵌入安全风险:学术研究表明嵌入可能被部分反推,虽然目前风险有限,但若数据库泄漏仍存在隐患。
总结
Cursor 使用 Merkle 树 + 嵌入向量 实现了大规模代码库的高效索引:
- 增量更新快;
- 隐私保护好;
- 能支撑语义检索、跨文件跳转、智能补全与问答。
同时,这种方案也存在实现复杂度高、索引负载大、嵌入安全等挑战。