大家好,今天介绍一款实用工具。
长期以来,笔者的英文查词流程是:
查单词用欧路词典(Eudic),记忆单词用墨墨背单词(Maimemo)。
但这带来一个很现实的长期问题 --------- 欧路与墨墨之间并没有官方的词库同步功能。
桌面端每天查文献生词、收藏、加入词本等动作都在欧路里完成,可真正背词又是在移动端墨墨里进行,两个平台非常割裂。
为了让整个流程真正自动化、可托管,也为了避免笔者每隔一段时间就要"整理一次词库"这种重复劳动,遂开发本工具。
也希望这套方案能帮助到同样使用欧路 + 墨墨组合的朋友们,让单词管理真正做到"一次查词,多端同步"。
🧩 功能概述
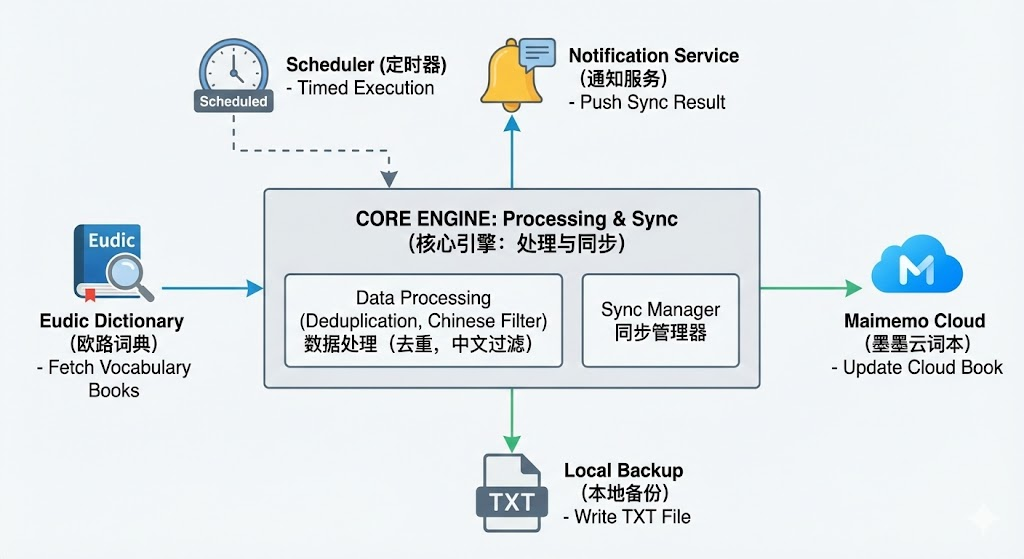
本工具支持:
- 自动抓取欧路全部生词本
- 自动去重、过滤中文
- 写入本地文本文件备份
- 调用墨墨 API 更新指定云词本
- 推送同步结果通知
- 定时自动执行
🪜 功能配置
(1)获取欧路词典 API Token
获取授权:https://my.eudic.net/OpenAPI/Authorization
登录 → 设置 → API → 复制 NISxxxx 开头的 Token
(2)获取墨墨背单词 API Token
参考文档:https://open.maimemo.com/document
墨墨移动端 → 我的 → 更多设置 → 实验功能 → 开放 API → 复制 Token
(3)获取墨墨 "云词本 ID"
使用墨墨查询云词本 API 获取云词本 ID
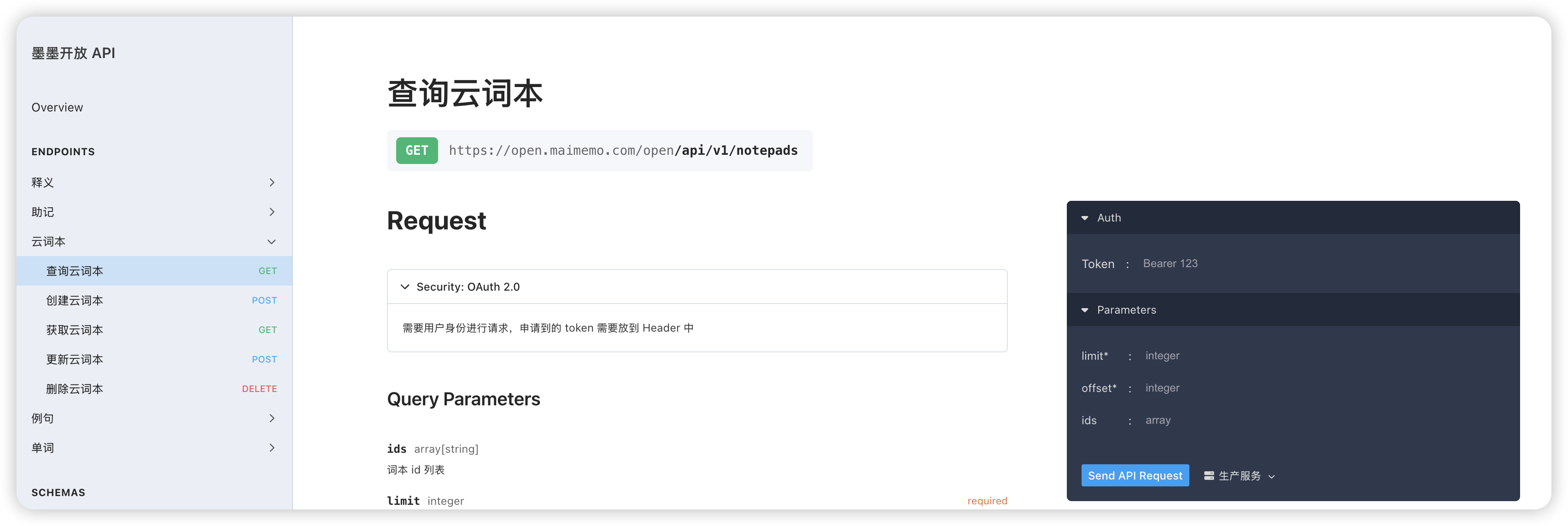
注意不是网页 URL 显示的编号,需要手动从开发者工具或 API 查看实际 ID
很多人搞错这个步骤,此处必须使用真实 notepad ID

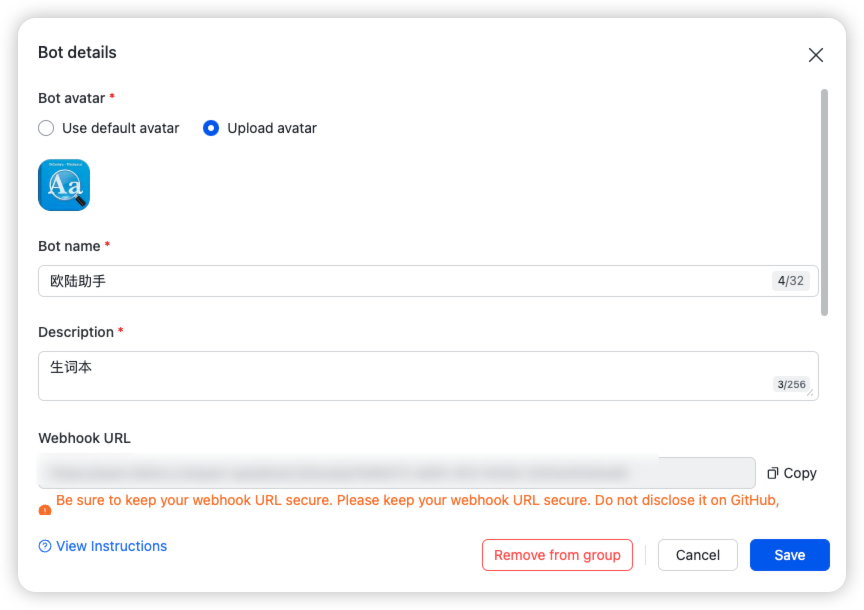
(4)创建飞书机器人 Webhook
飞书桌面端 → 新建群组 → 群设置 → 机器人 → 添加 Webhook
并复制 Webhook URL
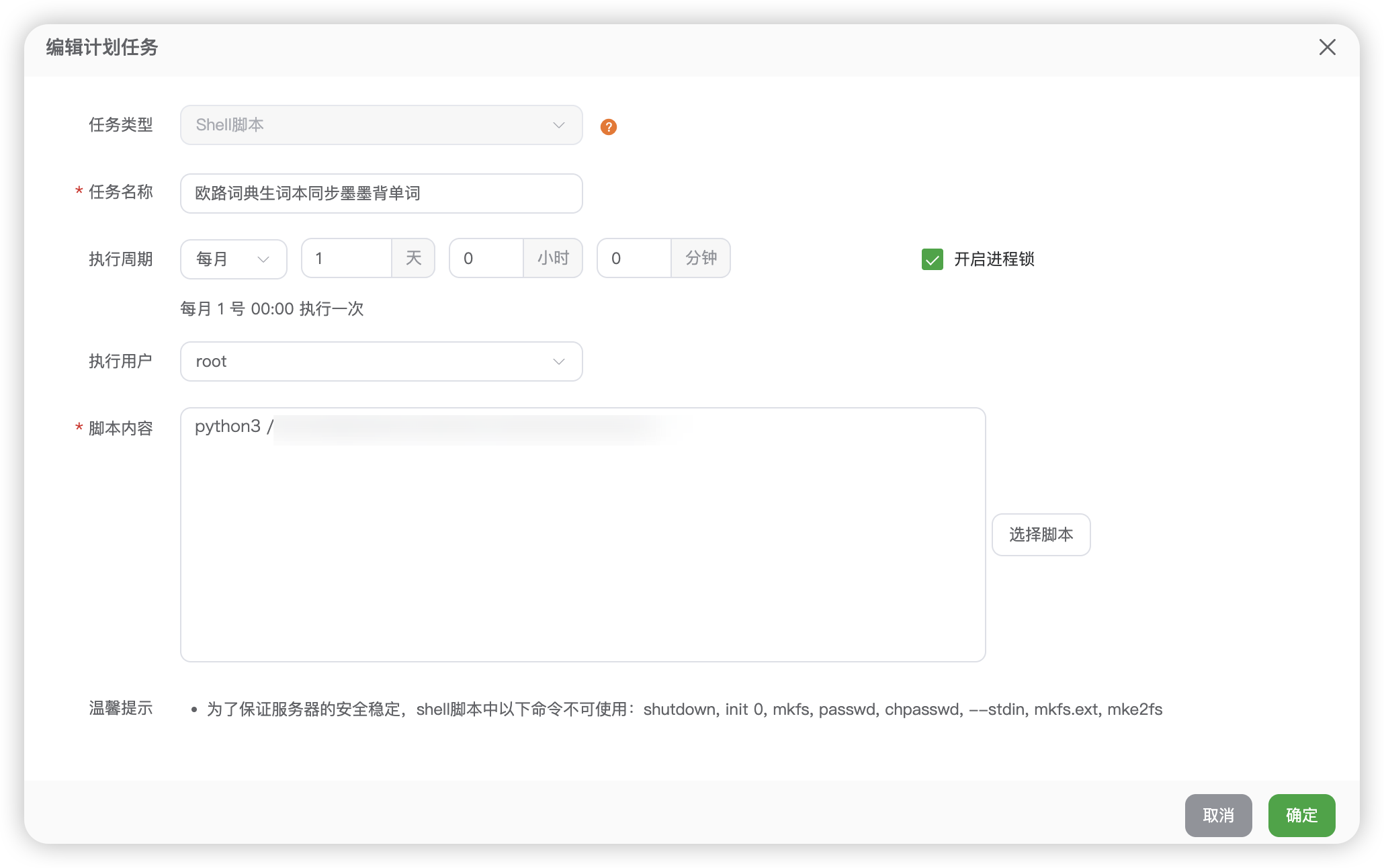
(5)服务器准备
- Python 环境
- 计划任务设置
🧩 关键代码拆解
以下是本项目的主要功能模块
① 安全 GET 请求
欧路分页有时候从 1 开始,为避免请求异常,必须支持自动检测
python
def safe_get(url, headers=HEADERS, timeout=10, retries=2, backoff=1.0):
for i in range(retries + 1):
try:
r = requests.get(url, headers=headers, timeout=timeout)
return r
except Exception as e:
if i < retries:
time.sleep(backoff * (i + 1))
else:
raise② 获取欧路全部生词本
python
def get_books():
"""获取生词本列表"""
r = safe_get(CATS_URL)
if r.status_code != 200:
raise RuntimeError(f"获取生词本失败: status={r.status_code} body={r.text[:200]}")
return r.json().get("data", [])③ 自动判断分页起始位置
欧路 API 的坑,有些生词本 page=0,另一些 page=1
所以必须自动探测:
python
def detect_page_start(category_id, page_size=500):
url0 = f"{BASE}?language={EUDIC_LANGUAGE}&category_id={category_id}&page=0&page_size={page_size}"
url1 = f"{BASE}?language={EUDIC_LANGUAGE}&category_id={category_id}&page=1&page_size={page_size}"
r0, r1 = safe_get(url0), safe_get(url1)
try:
ok0 = bool(r0.json().get("data") if r0.status_code == 200 else None)
except Exception:
ok0 = False
try:
ok1 = bool(r1.json().get("data") if r1.status_code == 200 else None)
except Exception:
ok1 = False
if ok0: return 0
if ok1: return 1
return 1④ 抓取全部单词并去重
python
def get_all_words_for_category(category_id, page_size=500):
start_page = detect_page_start(category_id, page_size)
page = start_page
all_items = []
while True:
url = f"{BASE}?language={EUDIC_LANGUAGE}&category_id={category_id}&page={page}&page_size={page_size}"
r = safe_get(url)
if r.status_code != 200:
raise RuntimeError(f"请求失败: {url} 状态码 {r.status_code} 返回:{r.text[:200]}")
try:
data = r.json().get("data", [])
except Exception as e:
raise RuntimeError(f"解析 JSON 出错: {e} body={r.text[:200]}")
if not data:
break
all_items.extend(data)
if len(data) < page_size:
break
page += 1
# 去重
seen = OrderedDict()
for it in all_items:
w = it.get("word")
if w and w not in seen:
seen[w] = None
return list(seen.keys())⑤ 写入 TXT 文件
建议使用绝对路径避免文件生成在奇怪的目录
格式为一行一个单词,供备份和更新墨墨云词本使用
python
def write_words_to_txt(words, path):
"""将英文单词写入 TXT"""
with open(path, "w", encoding="utf-8") as f:
for w in words:
f.write(w + "\n")⑥ 更新墨墨云词本
注意请求头必须加:Authorization: Bearer your_token,否则返回无权限
python
def update_memo_notepad(content):
"""日志行为"""
url = f"https://open.maimemo.com/open/api/v1/notepads/{MEMO_NOTEPAD_ID}"
payload = {
"notepad": {
"status": "UNPUBLISHED",
"content": content,
"title": "欧路词典生词本",
"brief": "欧路词典生词,API 自动每月抓取后导入",
"tags": ["词典"]
}
}
headers = {
"Authorization": f"Bearer {MEMO_API_TOKEN}",
"Accept": "application/json",
"Content-Type": "application/json"
}
print("\n开始提交到墨墨云词本...")
try:
r = requests.post(url, json=payload, headers=headers, timeout=15)
if r.status_code in (200, 201):
print("✅ 墨墨云词本更新成功")
else:
print(f"❌ 墨墨提交失败: status={r.status_code}")
print("返回内容:", r.text[:500])
except Exception as e:
print("❌ 墨墨提交异常:", e)⑦ 飞书通知
同步完成后可选发送飞书消息提醒功能
python
def send_feishu_notification(webhook_url, title, message):
card_content = f"{message}"
payload = {
"msg_type": "interactive",
"card": {
"config": {"wide_screen_mode": True},
"header": {"title": {"tag": "plain_text", "content": title}},
"elements": [
{
"tag": "div",
"text": {
"tag": "lark_md",
"content": card_content
}
}
]
}
}
try:
resp = requests.post(webhook_url, json=payload, timeout=10)
if resp.status_code == 200:
print("✅ 飞书通知发送成功")
else:
print(f"❌ 飞书通知失败,状态码: {resp.status_code}, 响应: {resp.text}")
except Exception as e:
print(f"❌ 飞书通知异常: {e}")🧩 主流程
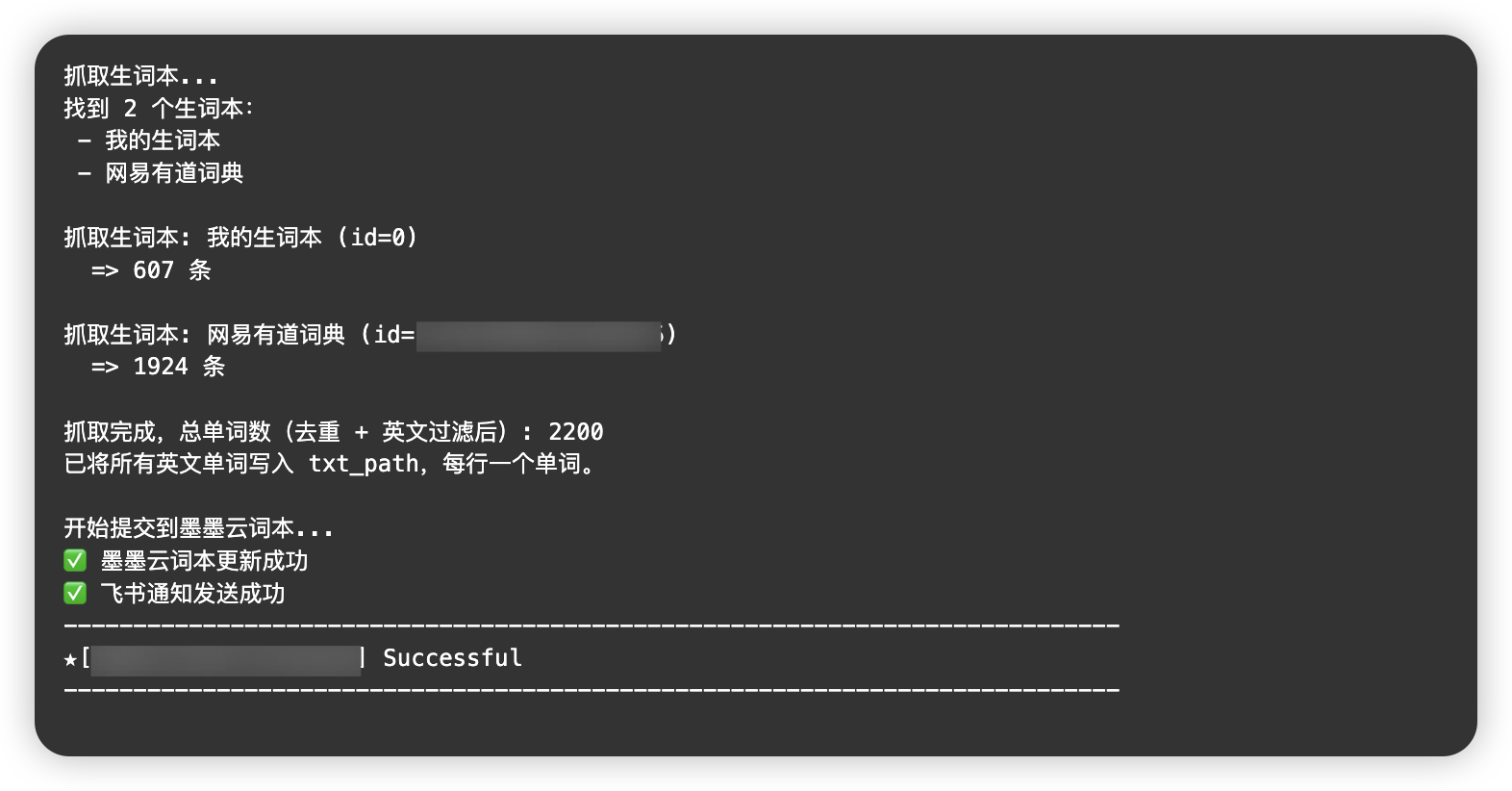
抓取 → 过滤 → 写入 → 墨墨更新 → 飞书通知
如果在欧路中打开"查词后自动加入生词本",有时查询中文翻译也会直接加入,故进行过滤,只保留英文单词供同步
python
def run_sync():
print("抓取生词本...")
books = get_books()
if not books:
print("未获取到生词本,请检查 API_TOKEN 或网络。")
return
print(f"找到 {len(books)} 个生词本:")
for b in books:
print(" -", b.get("name"))
all_words = OrderedDict()
for b in books:
name = b.get("name")
cid = b.get("id")
print(f"\n抓取生词本: {name} (id={cid})")
words = get_all_words_for_category(cid)
print(f" => {len(words)} 条")
for w in words:
all_words[w] = None
# 过滤只保留英文单词
english_words = [w for w in all_words.keys() if EN_WORD_RE.match(w)]
print(f"\n抓取完成,总单词数(去重 + 英文过滤后): {len(english_words)}")
# 写入 txt
try:
txt_path = TXT_OUTPUT_PATH
write_words_to_txt(english_words, txt_path)
print("已将所有英文单词写入 txt_path,每行一个单词。")
try:
with open(txt_path, "r", encoding="utf-8") as f:
memo_text = f.read().strip()
update_memo_notepad(memo_text)
except Exception as e:
print("读取 txt_path 失败:", e)
except Exception as e:
print("写文件失败:", e)
# 发送飞书通知
send_feishu_notification(
FEISHU_WEBHOOK,
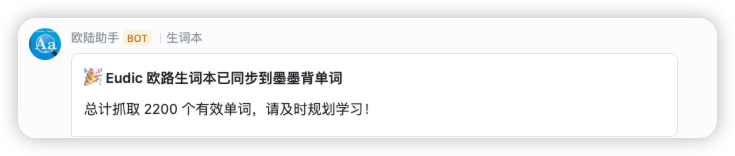
title="🎉 Eudic 欧路生词本已同步到墨墨背单词",
message=f"总计抓取 {len(english_words)} 个有效单词,请及时规划学习!"
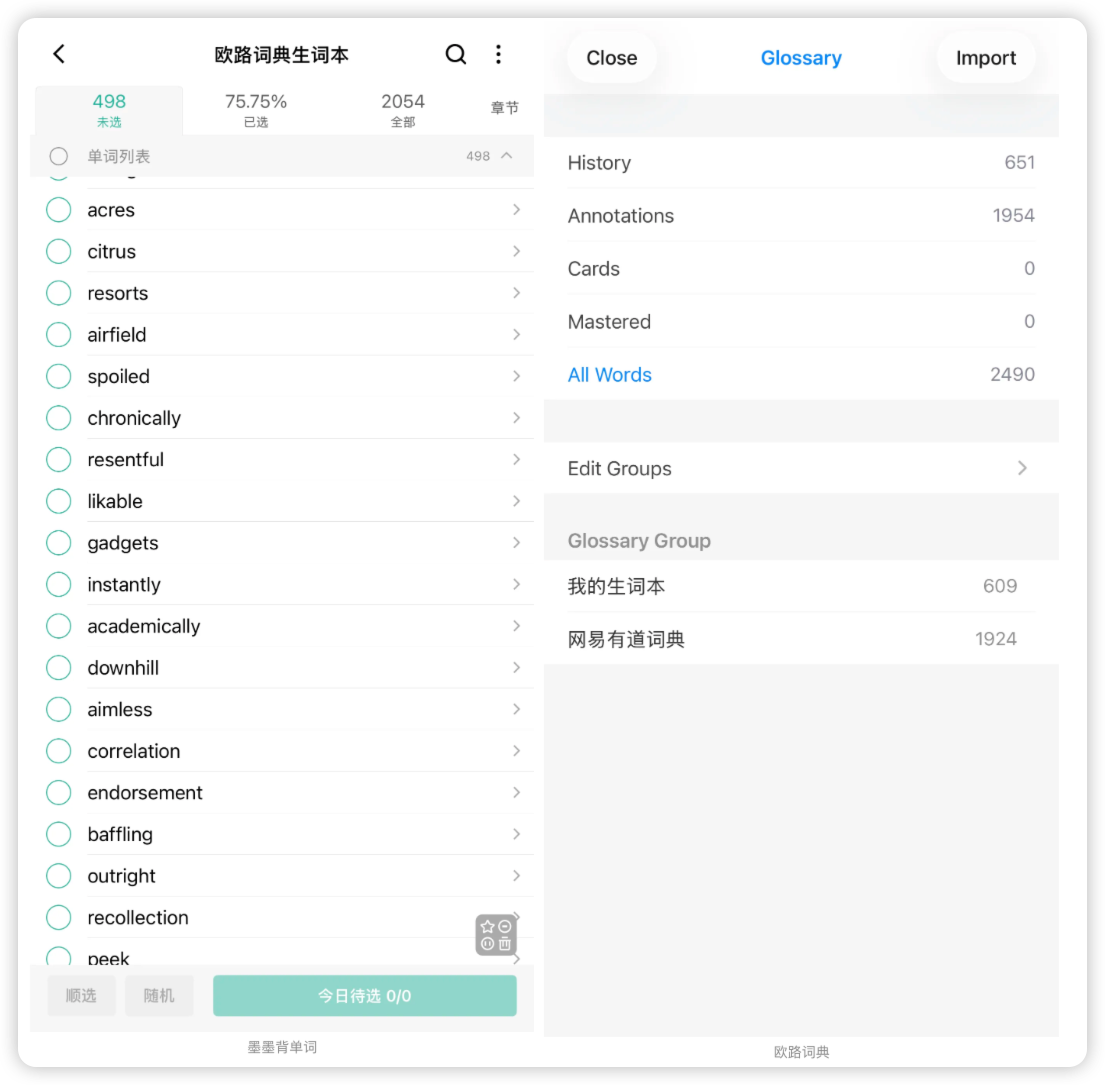
)🧩 实现效果
源码获取方式
开源地址:https://github.com/pdpeng/eudic-maimomo-words-sync
公粽浩:攻城狮杰森,后台回复"墨墨"