community|15 分钟阅读|2024 年 11 月 6 日
💡 本文为社区作者 Sankalp Shubham 投稿
引言
如果你用过 Cursor 编辑器的 @codebase 功能,你大概知道它在理解代码库时有多有用:不管是找相关文件、追踪执行流,还是理解类与方法的用法, @codebase 都能收集必要上下文来帮你。
我做了一个叫 CodeQA 的项目,能做上述事情。和 Cursor 的 @codebase 类似,CodeQA 能在整个代码库范围内回答你的问题,并给出相关片段、文件名与引用。它支持 Java、Python、Rust、JavaScript,也很容易拓展到其它语言。
- 实现见:CodeQA GitHub 链接
- 效果预览:CodeQA Demo 链接
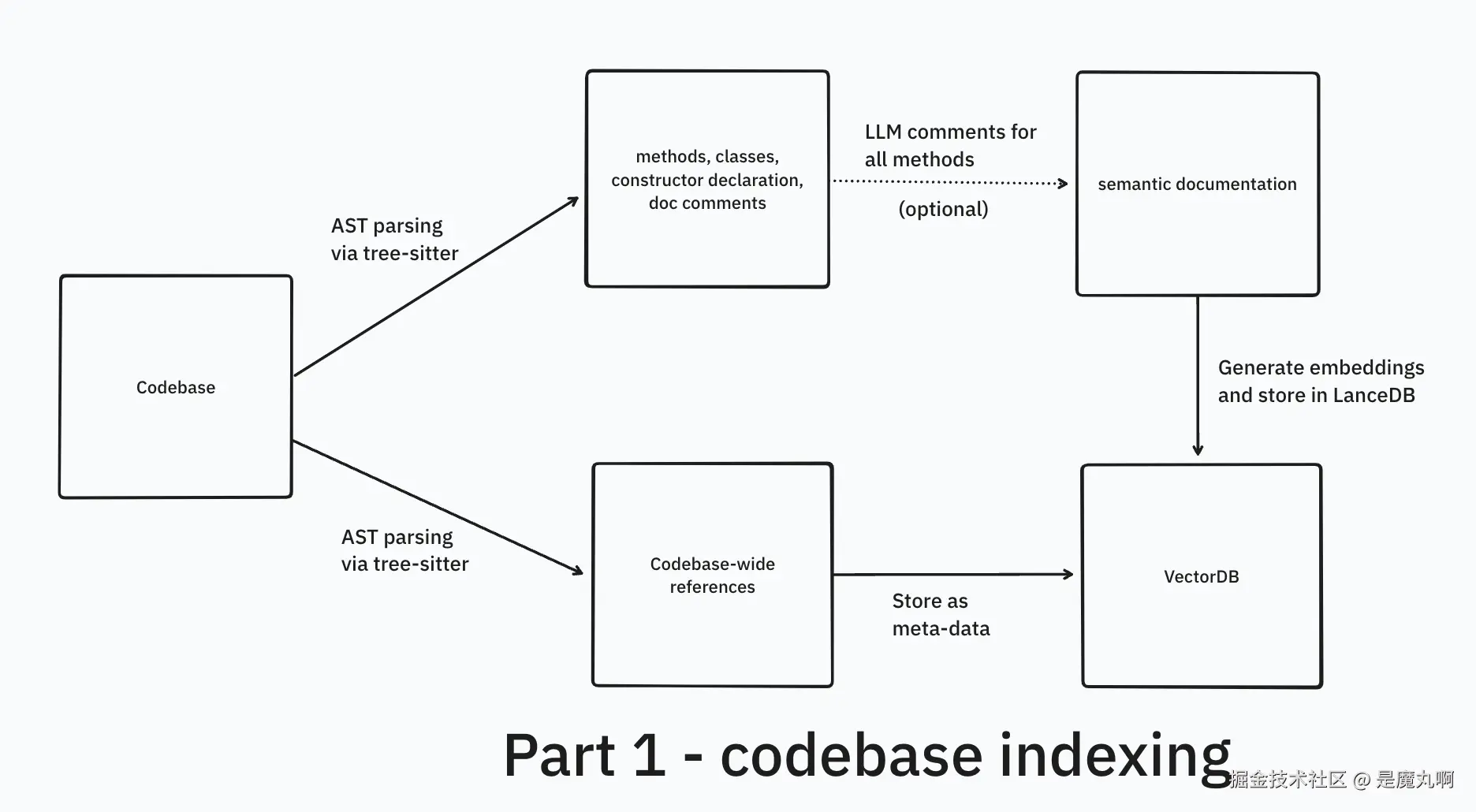
这个事情有两个关键部分:代码库索引(上篇) 和 检索管线(下篇) 。本文全部讨论:如何借助 tree-sitter 做代码库索引,以及用 LanceDB 做嵌入检索。
你会看到什么
本文更侧重概念与可选路径,而非大段具体代码(末尾有少量代码)。
重点包含:为什么"把上下文喂进模型"不是最佳解、朴素的语义代码搜索、分块类型,以及使用 tree-sitter 做语法级切分。
预备知识 :Python 编程、词向量/嵌入
术语说明 :query 指提问;LLM 指大语言模型;natural language 指自然语言(如英文)
问题定义
目标是做一个应用,帮助用户理解其代码库并生成更准确的代码,能力包括:
-
当用户输入关键字 @codebase 时,能以准确且相关的信息回答关于整个代码库的自然语言问题。
-
提供上下文代码片段 并分析代码的使用模式,包括:
- 某个类/方法是如何被使用的
- 类构造函数与实现的细节
-
跨代码库追踪并利用引用关系:
- 找出代码元素在全库内的使用处
- 为所有回答提供来源引用
-
利用收集到的上下文,辅助代码生成与建议
问题既可能是单跳 (单一来源即可回答),也可能是多跳(需聚合多个来源后作答)。
例子:
- "这个 git 仓库是做什么的?"
- "某个方法是怎么工作的?" → 你可能没写出精确的方法名
- "哪些方法在做 xyz 这样的事?" → 系统应能从你的提问中识别相关的方法/类名
- 更复杂的如:"EncoderClass 和 DecoderClass 之间有什么联系?" → 系统应跨多处收集上下文后回答(多跳问答)
既然问题清楚了,我们来想解法。我们允许使用 LLM。
为什么 GPT-4 不能直接回答我代码库里的问题?
虽然 GPT-4 训练过海量代码,但它并不了解你的代码库:不了解你定义的类、使用的方法,或项目整体目的。
它能回答通用编程问题(比如 "useEffect 怎么工作"),但对你的自定义代码问题(比如 "generateEmbeddings() 可能如何工作")就不行,因为它从没见过你这份实现/需求。
如果你问它你的代码,GPT-4 要么承认不知道 ,要么幻觉------编出"看似合理但错误"的答案。
"把上下文放进提示里"(In-Context Learning)
(流程示意图略)
现代 LLM(如 Anthropic Claude、Google Gemini)有很大上下文窗口 ------从 Claude Sonnet 的 200K token 到 Gemini Pro 1.5 的 2M token。它们很擅长从上下文中学习 (ICL),在提示里给出示例即可让模型少样本学会模式与任务(来源)。
这意味着:把小到中型代码库 (你的 side-project 全部代码)塞进 Sonnet 3.5 里,甚至把大型代码库 塞进最新的 Gemini Pro 1.5,也能"用你自己的代码上下文"去问问题。我也经常用上面两款来理解代码库,尤其是 Gemini(效果出乎意料地好)。
一个小技巧:把 GitHub 仓库 URL 里的 github 改成 uithub (把 g 换成 u),可以更容易地整体复制贴进提示。
本地工具我有时用 code2prompt。
- Few-shot 学习:在 system prompt 或提示中放入信息/示例,用作参考或模式学习。
- In-context 学习 :在推理时把信息喂给 LLM,它能利用这些信息作答或学习新模式。最近的论文(In-Context Learning with Long-Context Models: An In-Depth Exploration)显示大上下文模型在给出成千上万示例时性能会提升。(有线程链接)
为什么 ICL 不是最佳方案
- 性能退化 :当上下文窗口被塞满时,代码生成/理解能力开始下降。尽量少而准的上下文更好。
- 成本低效:走 API 时,每次会话粘一大堆 token,很快就贵。
- 时间开销:把大量代码粘进 Gemini 可以,但初始化处理提示很耗时,窗口变大后响应也会变慢。自用还行。
- 用户体验:你不能让终端用户自己把整个代码库复制进 LLM(😅)。
- 相关性问题 :塞太多无关代码会伤害回答质量。模型可能被无关段落干扰,而不是聚焦真正需要的部分。
让上下文更相关
显然,我们要最小化无关内容 进入提示。RAG 的目的正是如此。
回忆一下,我们的 query 是自然语言,且可能不包含 精准的类/方法名,所以关键词/模糊检索 不灵。要把英文问题 映射到代码符号 (类名、方法名、代码块),我们可以利用向量嵌入的语义搜索。
下面讨论如何抽取并索引代码块 以生成高质量嵌入------也就是构建一个朴素的语义代码搜索系统。
嵌入 101 与"结构"的重要性(可跳过)
你可以看 Embeddings: What they are and why they matter 作为入门。
用例子理解"嵌入与分块"
先不用代码,看看为什么需要"分块",以及嵌入怎么工作。
比如我们想从 Paul Graham 的博客里找"关于野心(ambition)的引用"。
为什么要分块? 因为嵌入模型有序列长度上限 (通常 1024--8192 tokens)。长文必须拆成更小且有意义的段落,便于更准确地匹配且不破坏语义。
常见做法:
- 把文本拆成模型可处理的小块,
- 读起来仍然通顺,
- 保留足够上下文。
分块方式:
- 定长分块(等长切)
- 智能分块 (如 RecursiveCharacterTextSplitter)
可用工具:langchain、llama-index------它们带有针对不同内容类型的分块器:
- 通用文本:RecursiveCharacterTextSplitter
- Markdown 专用分块器
- 语义分块(Semantic chunking)
关键点 :不同内容需要不同分块策略。博客、代码、技术文档都有自己的结构------我们需要保留结构,才能让嵌入模型表现好。
从头到尾流程:
-
按内容类型把原文分块
-
用模型(如 sentence-transformers/bge-en-v1.5 )把块转成嵌入
-
把嵌入存到数据库或 CSV
-
同时保存原文与必要元数据
-
检索时:
- 把用户搜索词转成嵌入
- 做相似度(点积/余弦)
- 返回匹配块
理解"分块与嵌入"很关键,下面我们会谈到代码专用分块策略------这时维护代码结构就更重要。
参考:Chunking / OpenAI Platform 等(略)
走向一个"朴素语义搜索"的解决方案
流程如下:
- 为整个代码库生成嵌入
- 用户输入查询
- 把查询转嵌入,计算余弦相似
- 语义代码检索完成
- 取 Top-5 匹配代码块
- 把实际代码(带元信息)作为上下文喂给 LLM
- LLM 生成答案
我们需要搞清楚:如何对代码库做嵌入以获得更好的语义搜索质量。
将检索 (向量或其它,如 SQL)得到的上下文 喂给 LLM 以辅助生成(并避免幻觉)就是 RAG 。建议阅读 Hrishi 的三部曲(从基础到进阶),本文是对其中 Part 1 与 Part 3 的应用。
插图:Retrieval-Augmented Generation for LLMs: A Survey(略)
给代码库"分块"
(截图略)
像处理普通文本那样"按定长/按段落"分块不适合代码 。代码有特定语法与明确结构(类、方法、函数)。为了有效处理与嵌入代码 ,必须保持其语义完整性。
直觉 :在潜在空间里,具有相似结构 的代码会彼此更相似。再者,嵌入模型往往训练过代码片段,更能捕捉代码间的关系。
检索时 ,返回完整的方法块或至少能引用完整块,会更有帮助,而不是零碎片段。
我们也希望提供引用信息 (references),无论在生成嵌入 时用,还是在把上下文送进 LLM时用。
方法/类级分块
可以做方法级 、类级 的朴素切分。参考:OpenAI cookbook (提取函数并做嵌入)。
但这不语言无关,而且一旦超出"类/方法",实现会变得很重。
语法级分块
代码的分块挑战在于:
- 如何处理层级结构?
- 如何抽取语言特定结构(构造函数、class)?
- 如何语言无关?不同语言语法各异。
这就是语法级分块的意义。
- 我们把代码解析成 AST(抽象语法树)
- 沿 AST 遍历 ,抽取子树 或节点 作为块(如函数声明、类定义、整段类代码、构造函数调用 等),粒度可细到单个变量
- 也可以(通过一定实现)拿到全库范围的引用关系
- 借助 AST,可以捕捉代码的层级结构与关系
如何构建 AST?
Python 自带的 ast 库只适用于 Python。我们需要语言无关的方案。
我开始更深入地搜:看技术博客、逛 GitHub,与做开发者工具的朋友讨论。一个模式 渐渐冒出来:tree-sitter 频繁出现。
更有意思的是它在开发者工具生态里的广泛应用:
-
YC 背景的公司在用:
- **Buildt(YC'23)**在技术讨论里提过它(有截图)
-
现代编辑器基于它:
- Cursor.sh 用它做代码库索引
- 他们构建代码图的方法高度依赖 tree-sitter
-
开发者工具逐渐标准化:
- Aider.chat(AI 终端结对编程)使用 tree-sitter 做 AST 处理
- 他们关于用 tree-sitter 构建仓库地图的文章写得很好
什么是 tree-sitter?
tree-sitter 是一个语法分析器生成器 和增量解析库 。它能够为源码构建具体语法树(CST) ,并在源码编辑时高效增量更新语法树。目标:
- 通用:解析任意编程语言
- 够快:几乎每次敲键都能解析
- 健壮:即使有语法错误也能给出有用结果
- 零依赖:纯 C 运行库
它被用于 Atom、VSCode 等编辑器,实现语法高亮 、代码折叠 等。显然,neovim 社区对 tree-sitter 也很狂热。
关键特性是"增量解析" → 当代码变化时,能高效更新语法树,非常适合做编辑器特性(如高亮、自动缩进)。
沿着"编辑器内部实现"继续挖(朋友建议),我发现它们通常结合 AST 库 + LSP(语言服务器协议) 。虽然 LSIF (LSP 的知识格式)也可以用于代码嵌入 ,但因为多语言支持复杂,我暂时跳过了。
- Tree-sitter explainer:视频(略)
用 tree-sitter 深入语法
最快上手方式是 tree_sitter_languages 模块,内置了多语言的预编译解析器:
pip install tree-sitter-languages你也可以在 tree-sitter playground 上玩。
从 AST 抽取"方法与类"(或任意代码符号)
对应代码在 tutorial/sample_one_traversal.py。
看一段示例代码的 AST:
python
class Rectangle:
def __init__(self, width, height):
self.width = width
self.height = height
def calculate_area(self):
"""Calculate the area of the rectangle."""
return self.width * self.height
my_rectangle = Rectangle(5, 3)
area = my_rectangle.calculate_area()tree-sitter 的 AST(简化版) :
less
module [0, 0] - [12, 0]
class_definition [0, 0] - [7, 39] # Rectangle
name: identifier [0, 6] - [0, 15]
body: block [1, 4] - [7, 39]
function_definition [1, 4] - [3, 28] # __init__
name: identifier [1, 8] - [1, 16]
parameters: parameters [1, 16] - [1, 37]
// ...
body: block [2, 8] - [3, 28]
// ...
function_definition [5, 4] - [7, 39] # calculate_area
name: identifier [5, 8] - [5, 22]
parameters: parameters [5, 22] - [5, 28]
// ...
body: block [6, 8] - [7, 39]
// ...
expression_statement [9, 0] - [9, 30] # my_rectangle = Rectangle(5, 3)
...
expression_statement [10, 0] - [10, 36] # area = my_rectangle.calculate_area()
...递归遍历 AST 抽取"类与方法" (节选):
ini
from tree_sitter_languages import get_parser
parser = get_parser("python")
code = """ ... """
tree = parser.parse(bytes(code, "utf8"))
def extract_classes_and_methods(node):
results = {'classes': [], 'methods': []}
def traverse_tree(node):
if node.type == "class_definition":
class_name = node.child_by_field_name("name").text.decode('utf8')
class_code = node.text.decode('utf8')
results['classes'].append({'name': class_name, 'code': class_code})
elif node.type == "function_definition":
method_name = node.child_by_field_name("name").text.decode('utf8')
method_code = node.text.decode('utf8')
results['methods'].append({'name': method_name, 'code': method_code})
for child in node.children:
traverse_tree(child)
traverse_tree(node)
return results使用 tree-sitter Query
见 tutorial/sample_two_queries.py。定义查询并用来抽取类/方法(节选):
less
class_query = language.query("""
(class_definition
name: (identifier) @class.name
) @class.def
""")
method_query = language.query("""
(function_definition
name: (identifier) @method.name
) @method.def
""")你可以在文档里了解 Queries 与 tagged captures 。项目里常把查询以 .scm 文件保存(如 aider、locify)。
我的 CodeQA 实现相似(见 treesitter.py),并为不同语言定义了查询。
全库范围的"引用关系"
对全库引用 ,我主要找函数调用 与类实例化/对象创建 。下面是 preprocessing.py 的相关代码(节选):
ini
def find_references(file_list, class_names, method_names):
references = {'class': defaultdict(list), 'method': defaultdict(list)}
...
for language, files in files_by_language.items():
treesitter_parser = Treesitter.create_treesitter(language)
for file_path in files:
...
tree = treesitter_parser.parser.parse(file_bytes)
stack = [(tree.root_node, None)]
while stack:
node, parent = stack.pop()
if node.type == 'identifier':
name = node.text.decode()
if name in class_names and parent and parent.type in ['type','class_type','object_creation_expression']:
references['class'][name].append({...})
if name in method_names and parent and parent.type in ['call_expression','method_invocation']:
references['method'][name].append({...})
stack.extend((child, node) for child in node.children)
return references这是一个基于栈的树遍历 来找引用。我用了比 query/tag 更简单的办法:
- 如果标识符名字命中类名集合 ,且父节点属于类型注解/对象创建 等,就记录为类引用;
- 方法同理(调用表达式 / 方法调用)。
这些引用作为每个代码块的元数据 存储。当向量库返回最终文档 时取出,用作最终输出的增强信息。
结语
本篇讨论了一个朴素语义代码搜索 方案,以及如何用 tree-sitter 做语法级分块 。到这里我们几乎完成了预处理 。下篇 会讲:如何生成嵌入、提升嵌入检索的技巧,以及一些后处理方法。
在上篇,我讲了面向代码库的问答系统 :为什么 GPT-4 无法"天然"回答代码问题、ICL 的局限、用嵌入做语义代码搜索 的重要性,以及用 tree-sitter 做语法级分块 ,抽取方法、类、构造函数 与跨库引用。
本篇涵盖
- 代码库索引的最后一步 ------给方法加 LLM 注释
- 选择嵌入模型与向量库的注意点
- 提升检索 的技巧:HyDE、BM25、重排序
- 重排序 的选择与深入解释(双塔 vs 交叉编码器)
如果你用过嵌入就会知道:仅靠嵌入搜索 往往不够,需要在管线里加 HyDE / 混合检索 / 重排序 等步骤。
(代码检索管线图略)
接下来逐一讲述,并给出实现要点。
给方法添加 LLM 注释(可选)
严格说这也属于"索引"的一部分,但更贴近本篇主题。
更新 :我在 CodeQA 的当前版本里移除了 LLM 注释,因为它会拖慢索引 。相关文件 llm_comments.py 仍在仓库里。
由于用户的提问是自然语言 ,我决定为每个方法 添加2--3 行的自然语言文档 。这样代码库就被"注释化"了:每条 LLM 生成的注释给出简要概述。它能提升关键词 与语义搜索 的效果------你既能按"代码做什么 ",也能按"代码是什么"来搜。
后来我找到了篇博客验证了这个想法(Cosine:三招让嵌入检索准确率提升 37% ),其中谈到:
元特征搜索 (Meta-characteristic)很重要:用户可能想搜"所有泛型的递归函数 "。纯字符串匹配/正则难以搞定,简单嵌入实现也不灵。我们的解法(以 Buildt 为例):对每个代码元素/片段,嵌入自然语言描述 以获得"元特征",而这份描述由微调过的 LLM 生成。把描述 与代码本身 一起嵌入,就可以同时按"代码是啥"与"代码做啥"来搜。没有这一步,功能性问题的检索很难准确。代价是成本与延迟上升,但对我们而言非常值得。
嵌入与向量数据库(VectorDB)
我默认用 OpenAI text-embedding-3-large (表现好,大家也都有 OpenAI key)。也提供 jina-embeddings-v3 选项,在一些基准上优于 text-embedding-3-large。
关于 OpenAI 嵌入:便宜、8191 token 序列长度、MTEB 第 35 名、多语言、API 好用。序列长度很重要,因为能覆盖更长的依赖与上下文。
选择嵌入时要考虑
- 基准 :看 MTEB 排名、分数、序列长度、支持语言。开源模型需考虑参数量/显存。
- 延迟 :API-based 会有网络往返;要速度且有算力可选本地。
- 成本 :尝试/免费可用 sentence-transformers (如 bge-en-v1.5、nomic-embed-v1);闭源大多也不贵。
- 用例匹配 :嵌入是否含代码预训练。
- 微调:可显著提升效果。LlamaIndex 提供对 HF 嵌入的微调 API;Jina 也出了微调 API(我还没试)。
- 隐私:对很多人和公司很关键。我的项目以性能优先,选择了 OpenAI,未优先考虑隐私。
这里引用 Sourcegraph 的一段博文,说明他们为什么不再使用嵌入 (为多仓场景带来的数据传输、维护与规模复杂度等成本)。可参考 《Cody 如何理解你的代码库》 一文。
向量库(VDB)
我用 LanceDB :快、易用 ,pip install 即用,无需 API key。对 Hugging Face 上几乎所有嵌入/主流服务(OpenAI、Jina 等)都有集成;也支持重排序器、算法、嵌入、第三方 RAG 库等。
选择 VDB 时考虑:
- 是否支持你需要的集成(LLMs、不同厂商)
- 召回与延迟
- 成本
- 易用性
- 开源/闭源
实现细节 :嵌入代码库与建表的代码在 create_tables.py 。我维护两个表 :一个放方法 ,一个放类与其它 (如 README)。分开有利于分别查询元数据 与分别做向量检索(比如先找最近的类,再找最近的方法)。
在实现里,你会看到我没有手动生成嵌入 。这部分由 LanceDB 托管:我只需要写入分块 ,LanceDB 在后台做批量嵌入生成 与重试。
检索
表准备好后,就能把查询交给向量库。它会用暴力搜索 (余弦/点积)返回最相似文档。这些结果相关 但不总是够准;顺序也可能不理想。附了个推特线程展示这些短板。
提升嵌入检索
BM25 是第一步:把语义检索 与关键词检索 结合。我在 semantweet search 里这么做过。很多向量库都内置了混合检索 。那次我用 LanceDB,配合 tantivy 建全文检索索引即可。LanceDB 官网也有一些基准来展示不同方法对结果的影响。
召回(Recall) :检索到的相关文档数 / 实际相关文档总数 ------ 衡量搜索性能。
用元数据做过滤 :如果数据带有日期/关键词/指标 ,可先用 SQL 预过滤 再做语义搜索,能显著提升质量与性能。因为嵌入是"空间中的点",先缩窄候选空间很有帮助。
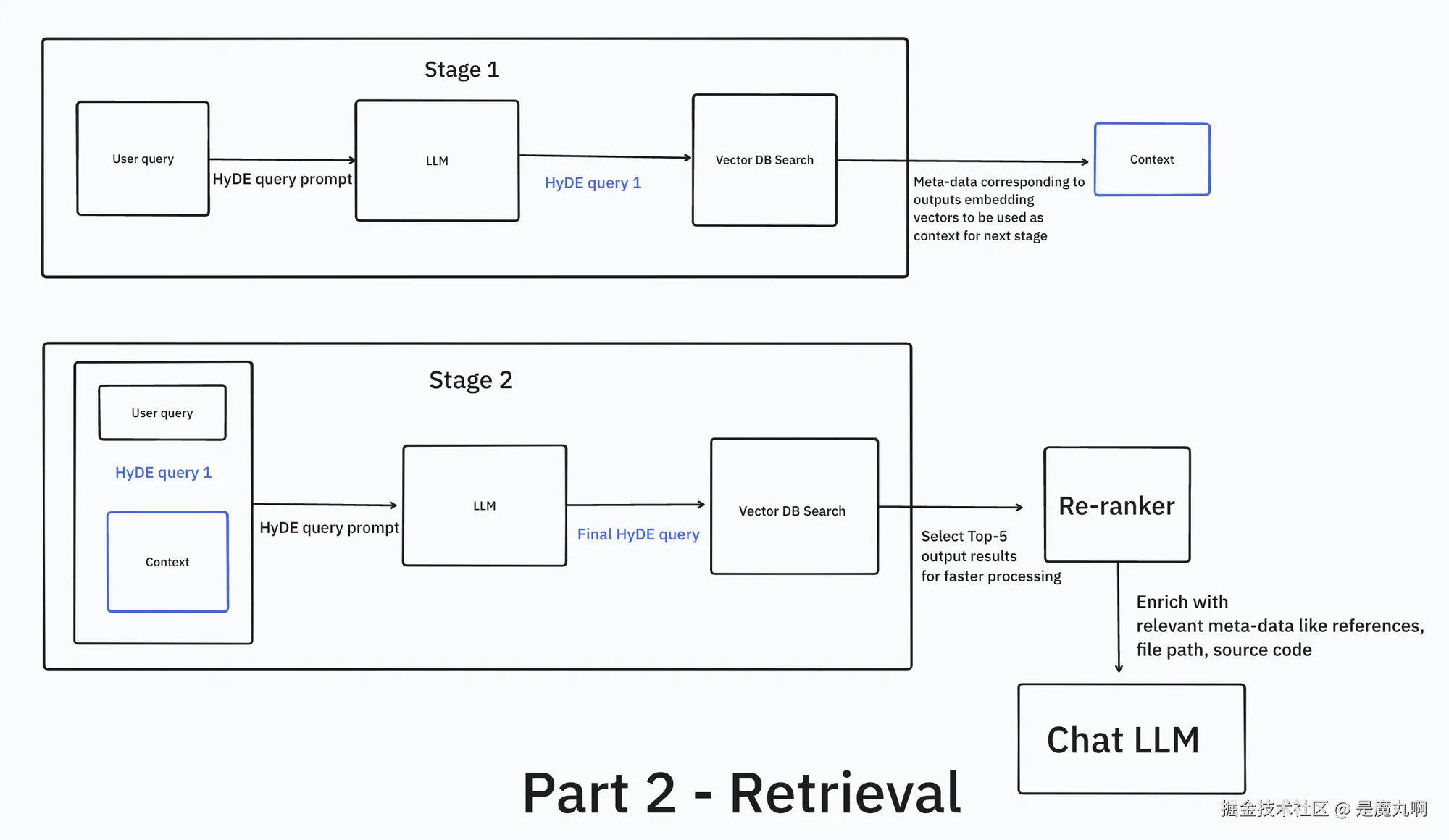
重排序(Reranking)
在向量检索后加重排序 非常容易且收益显著。简言之,重排序器对"查询 token 与 候选文档 token "做交互(cross-attention) 。
在 CodeQA v2 里我用 answerdotai/answerai-colbert-small-v1 (本地最强之一,接近 Cohere Re-ranker v3,我在 v1 用过它)。
交叉编码器(cross-encoder) vs. 双塔(bi-encoder)
嵌入来自像 GPT-3(decoder-only) 或 BERT(encoder-only) 这类模型。
两种工作方式:
- 交叉编码器 :把 query+doc 连接后一起编码 ,输出相关性分数。
- 双塔编码器 :分别 编码 query 与 doc,然后点积相似度。
交叉编码器里,所有 query token 与 doc token 两两交互 ,因此更准 ;但需要对每个候选 都跑一次模型,很慢 。双塔可以预计算 文档向量,在线只算点积,很快 但略逊精度 。
所以实践上常用"先双塔快召回,再交叉重排 Top-K"。
文中给了一个示例(略),展示了双塔把"How many people live in New Delhi? No idea. "错判为最相关,而交叉重排能把真正答案(含具体人口数的句子)排到第一。
HyDE(假设文档嵌入)
用户的 query 多是英文自然语言 ,而我们的嵌入主要由代码 组成。在潜在空间里,"代码更接近代码 ",而不是"英文接近代码 "。这就是 HyDE 的直觉:
- 先让 LLM 为你的问题生成一个"假想答案/文档" (可能是代码片段)。
- 用这个**"幻觉出来的文档"去做 首次向量检索**,因为它在嵌入空间里更贴近代码。
- 取回Top-5 结果组成临时上下文 ,再发起第二次 HyDE(此时模型已"知道语言/文件")。
- 第二次 HyDE 生成一个更具上下文意识的查询。
- 用它做向量检索 并重排序 ,然后取回代码与引用元数据拼上下文给聊天 LLM。
实现上我用 gpt-4o-mini 做两次 HyDE(便宜、快、对代码理解也还行),系统提示模板在文中已给出(略)。最终聊天用 gpt-4o(要更强的对话体验;有 OpenAI key 更方便,或者用 Claude 3.5 Sonnet)。
另外,如果用户没带 @codebase ,系统会回退到已有上下文 ;若模型不自信 ,会提示用户加上 @codebase(这在 system prompt 里约定)。
可能的改进
延迟 :还有很多可以优化的地方。目前带 @codebase 、不重排 是 10--20s ,开重排是 20--30s (有点慢)。为自我辩护一下:Cursor 也常在 15--20s 左右。
- 最容易的优化:用 Llama 3.1-70B ,并跑在 Groq/Cerebras 这类高吞吐推理服务,能把 HyDE 的延迟降 ≥10s。
- 尝试本地嵌入以消除网络延迟。
- 我们的瓶颈在 HyDE 。能否把两次 HyDE 减到一次,甚至去掉?也许借助仓库地图 上的 BM25 先做关键词预选,能减少 1 次 HyDE。
准确率:
- 低垂果实:换/微调更好的嵌入;
- 做评测 与反馈闭环来迭代优化。
结语
在这两篇文章里,我们探讨了一个实用的代码问答系统 应如何构建。上篇 奠定了基础:正确的代码分块 与语义代码搜索 ;下篇深入了提升检索质量的技巧:
- 用 LLM 注释 把"代码"与"自然语言查询"桥接;
- 选择嵌入与向量库的考量;
- 混合检索(语义 + 关键词) 、交叉重排的力量,以及
- 用 HyDE 缩小"自然语言 ↔ 代码"之间的语义鸿沟。
完整实现都在 GitHub,欢迎在自己的项目里试试这些方法。谢谢阅读!
参考(按出现顺序;与原文一致,略)